我们将讨论Linux多进程编程的以下内容:
1.复制进程映像的fork系统调用和替换进程映像的exec系列系统调用。
2.僵尸进程以及如何避免僵尸进程。
3.进程间通信(Inter Process Communication,IPC)最简单的方式:管道。
4.三种System V进程间通信方式:信号量、消息队列、共享内存。它们是由AT&T System V2版本的UNIX引入的,所以统称为System V IPC。
5.在进程间传递文件描述符的通用方法:通过UNIX本地域socket传递特殊的辅助数据。
Linux下创建新进程的系统调用是fork:

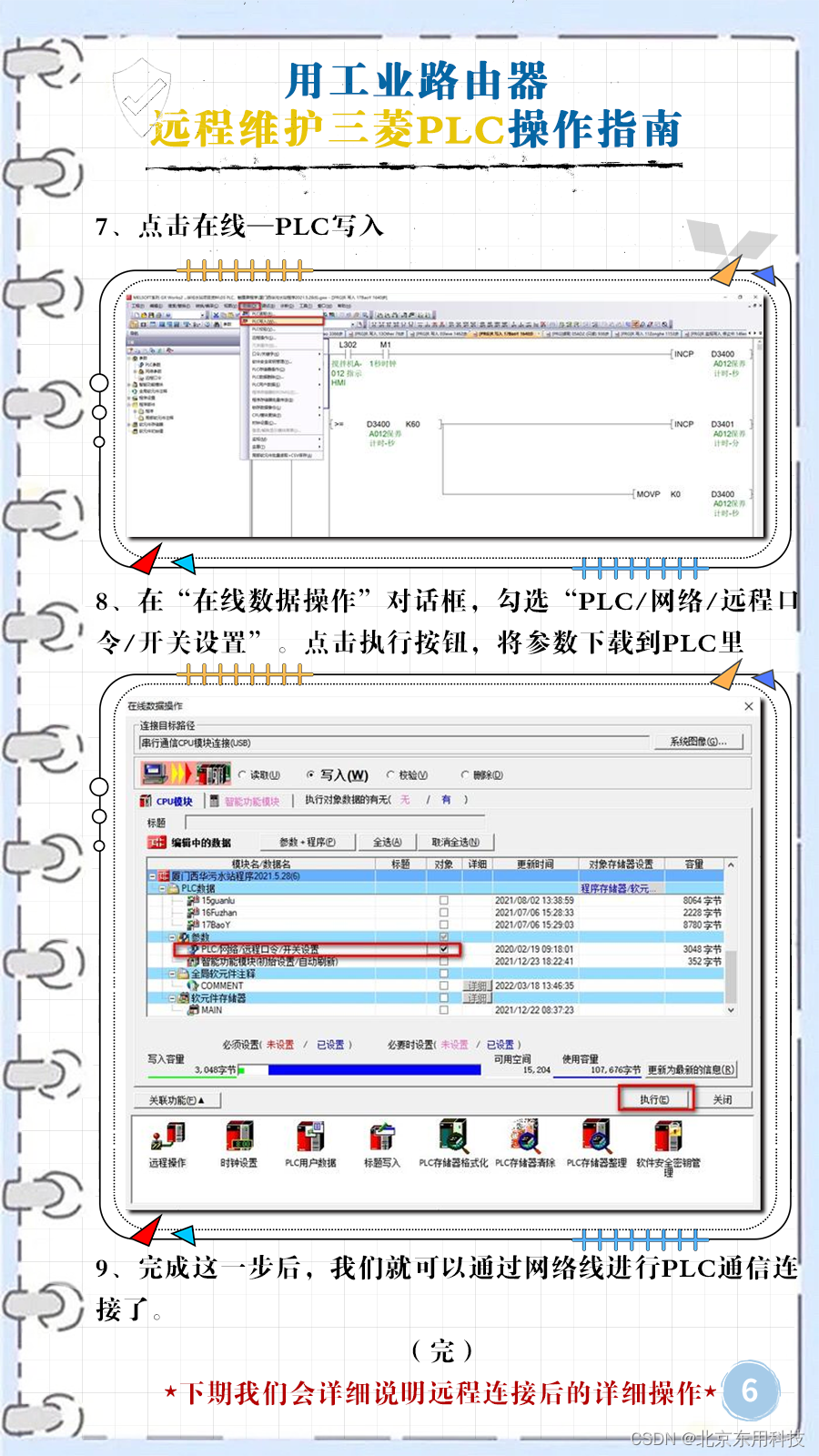
该函数的每次调用都返回两次,在父进程中返回的是子进程的PID,在子进程中则返回0,该返回值是后续代码判断当前进程是父进程还是子进程的依据。fork系统调用失败时返回-1,并设置errno。
fork函数复制当前进程,在内核进程表中创建一个新的进程表项,新的进程表项中很多属性和原进程相同,如堆指针、栈指针、标志寄存器的值,但也有很多属性被赋予了新值,如子进程的PPID被设置成原进程的PID,信号位图被清除(原进程设置的信号处理函数不再对新进程起作用)。
子进程的代码和父进程完全相同,同时它还会复制父进程的数据(堆数据、栈数据、静态数据),数据的复制采用的是写时复制(copy on write),即只有在任一进程(父进程或子进程)对数据执行了写操作时,复制才会发生(先是缺页中断,然后操作系统给子进程分配内存并复制父进程的数据),即便如此,如果我们在程序中分配了大量内存,那么使用fork函数时也应当谨慎,尽量避免没必要的内存分配和数据复制。
此外,创建子进程后,父进程中打开的文件描述符默认在子进程中也是打开的,且文件描述符的引用计数加1。
有时我们需要在子进程中执行其他程序,即替换当前进程映像,这就需要以下exec系列函数之一:

path参数指定可执行文件的完整路径;file参数是文件名,该文件的具体位置在环境变量PATH中搜寻。arg参数接受可变参数,argv参数则接受参数数组,它们都会被传递给新程序(path或file参数指定的程序)的main函数。envp参数用于设置新程序的环境变量,如果未设置它,则新程序将使用由全局变量environ指定的环境变量。
一般,exec函数是不返回的,除非出错,此时它返回-1,并设置errno。如果没出错,则原进程中exec调用之后的代码都不会执行,因为此时原程序已经被exec的参数指定的程序完全替换(包括代码和数据)。
exec函数不会关闭原进程打开的文件描述符,除非该文件描述符被设置了SOCK_CLOEXEC属性。
对多进程程序而言,父进程一般需要跟踪子进程的退出状态,因此,当子进程结束运行时,内核不会立即释放该进程的进程表表项,以满足父进程后续对该子进程退出信息的查询(如果父进程还在运行)。在子进程结束运行后,父进程读取其退出状态前,我们称该子进程处于僵尸态。父进程终止,而子进程继续运行时,子进程的PPID将被操作系统设置为1,即init进程,init进程接管了该子进程,并等待它结束。
如果父进程没有正确处理子进程的返回信息,子进程将停留在僵尸态,并占据着内核资源,这是不能容许的,因为内核资源有限,以下函数在父进程中调用,以等待子进程的结束,并获取子进程的返回信息,从而避免了僵尸进程的产生,或使子进程从僵尸态结束:

wait函数将阻塞进程,直到该进程的某个子进程结束运行,它返回结束运行的子进程的PID,并将该子进程的退出状态信息存储于stat_loc参数指向的内存中,sys/wait.h文件中定义了以下宏来帮助解释子进程的退出状态信息:
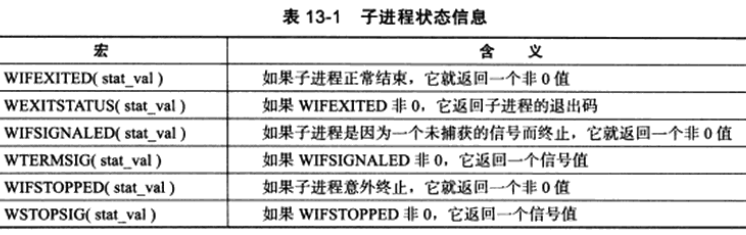
上图中有一个错误,WIFSTOPPED宏是用来判断子进程是否是被信号暂停。
wait函数是阻塞的,而waitpid函数解决了这个问题。waitpid函数只等待由pid参数指定的子进程,如果pid参数取值为-1,那么它就和wait函数相同,即等待任意一个子进程结束。waitpid函数的stat_loc参数的含义和wait函数的stat_loc参数的相同。options参数可以控制waitpid函数的行为,该参数最常用的取值为WNOHANG,此时waitpid函数是非阻塞的,如果pid指定的目标子进程尚未终止,则waitpid函数立即返回0,如果目标子进程确实正常退出了,则waitpid函数返回该子进程的PID。waitpid函数失败时返回-1并设置errno。
当一个进程结束时,它将给父进程发送一个SIGCHLD信号,我们可以在父进程中捕获SIGCHLD信号,并在信号处理函数中调用waitpid函数以“彻底结束”一个子进程:
static void handle_child(int sig) {
pid_t pid;
int stat;
while ((pid = waitpid(-1, &stat, WNOHANG)) > 0) {
// 对结束的子进程进行善后处理
}
}
可通过pipe系统调用创建管道,我们前面也利用它实现进程内部的通信,实际上,管道也是父子进程间通信的常用手段。
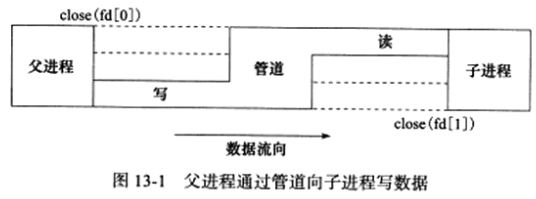
管道能在父子进程间传递数据,利用的是调用fork后两个管道文件描述符都保持打开,一对这样的文件描述符能保证父子进程间一个方向的数据传输,父进程和子进程必须有一个关闭fd[0],另一个关闭fd[1],下图使用管道实现从父进程向子进程写数据:
如果要实现父子进程之间的双向数据传输,可以使用两个管道。socket编程接口提供了一个创建全双工管道的系统调用socketpair,squid服务器(一个HTTP代理服务器)就是利用socketpair函数创建管道,以实现在父进程和日志服务子进程之间传递日志信息,下面我们简单分析之,我们在机器Kongming20上有如下环境:
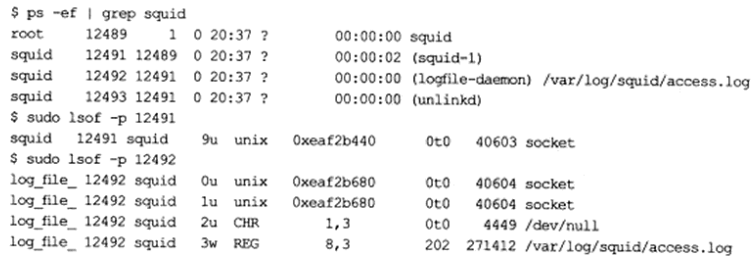
由上图,squid服务创建了几个子进程,子进程12492专门用于输出日志到/var/log/squid/access.log文件,父进程12491使用socketpair函数创建了一对UNIX域socket,然后关闭了其中的一个,剩下的那个socket的值是9,子进程12492从父进程12491继承了这对UNIX域socket,并关闭了其中另外一个,剩下的那个socket则被dup到标准输入和标准输出上。下面我们telnet到squid服务上,并向它发送部分数据,同时开启另外两个终端,分别运行strace命令以查看进程12491和12492在这个过程中交换的数据,具体操作如下:


由上图可见,进程12491接收到客户数据后将日志信息输出到管道(写文件描述符9),日志服务子进程使用阻塞读操作等待管道上有数据可读(读文件描述符0),然后将读取到的日志信息写到/var/log/squid/access.log文件(写文件描述符3)。
管道只能用于有关联的两个进程(如父子进程)间的通信,而以下要讨论的三种System V IPV能用于无关联的多个进程之间的通信,因为它们都使用一个全局唯一的键值来标识一条信道。有一种特殊的管道称为FIFO(First In First Out,先进先出),也叫命名管道,它也能用于无关联进程之间的通信,但FIFO管道在网络编程中用得不多,所以我们不讨论它。
当多个进程同时访问系统上某个资源时,如同时写一个数据库的某条记录,或同时修改某个文件,就需要考虑进程同步问题,以确保任一时刻只有一个进程可以拥有对资源的独占式访问。通常,进程对共享资源的访问的代码只是很短的一段,但这段代码引发了进程之间的竞态条件,我们称这段代码为关键代码区,或临界区,对进程同步,就是确保任一时刻只有一个进程能进入关键代码段。
Dekker算法和Peterson算法试图从语言本身(不需要内核支持)解决并发问题,但它们依赖于忙等待,即进程要持续不断地等待某个内存位置状态的改变,这种方式的CPU利用率太低,不可取。
Dijkstra提出的信号量(Semaphore)是一种特殊的变量,它只能取自然数值且只支持两种操作:等待(wait)和信号(signal)。但在Linux/UNIX中,等待和信号都已经具有特殊含义,所以对信号量的这两种操作更常用的称呼是P、V操作,这两个字母来自荷兰语单词passeren(传递,就好像进入临界区)和vrijgeven(释放,就好像退出临界区)。假设有信号量SV,对它的P、V操作含义如下:
1.P(SV),如果SV的值大于0,就将它减1,如果SV的值为0,则挂起进程的执行。
2.V(SV),如果有其他进程因为等待SV而挂起,则唤醒之,如果没有,则将SV加1。
信号量的取值可以是任何自然数,但最常用的、最简单的信号量是二进制信号量,它只能取0或1两个值,我们仅讨论二进制信号量。使用二进制信号量同步两个进程,以确保关键代码段的独占式访问的例子:
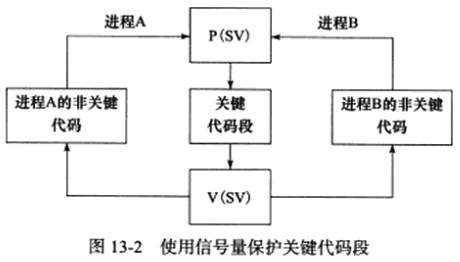
上图中,当关键代码段可用时,二进制信号量SV的值为1,进程A和B都有机会进入关键代码段,如果此时进程A执行了P(SV)操作将SV减1,则进程B再执行P(SV)操作就会被挂起,直到进程A离开关键代码段,并执行V(SV)操作将SV加1,关键代码段才重新变得可用。
不能使用普通变量来模拟二进制信号量,因为所有高级语言都没有一个原子操作可以同时完成以下两步操作:检测变量是否为true/false,如果是则将它设置为false/true。
Linux信号量的API定义在sys/sem.h头文件中,主要包括3个系统调用:semget、semop、semctl。它们被设计为操作一组信号量,即信号量集,而不是单个信号量。
semget系统调用创建一个新的信号量集,或获取一个已经存在的信号量集,其定义如下:

key参数是一个键值,用来标识一个全局唯一的信号量集,就像文件名全局唯一地标识一个文件一样,要通过信号量通信的进程需要使用相同的键值来创建/获取该信号量。
num_sems参数指定要创建/获取的信号量集中信号量的数目。如果是创建信号量,则该值必须被指定;如果是获取已存在的信号量,则可把它设为0。
sem_flags参数指定一组标志,它低端的9个比特是该信号量的权限,其格式和含义都与系统调用open的mode参数相同,此外,它还可以和IPC_CREAT标志做按位或运算以创建新的信号量集,此时即使信号量已存在,semget函数也不会产生错误,我们可以联合使用IPC_CREAT和IPC_EXCL标志来确保创建一组新的、唯一的信号量集,此时,如果信号量集已经存在,则semget函数返回错误并设置errno为EEXIST,这种创建信号量的行为与用O_CREAT和O_EXCL标志调用open来排他式地创建并打开一个文件相似(使用O_CREAT+O_EXCL标志可以确保文件只创建一次,如果文件已存在,则open函数将调用失败,从而避免多线程或多进程同时创建文件时导致的竞争条件)。
semget函数成功时返回一个正整数值,它是信号量集的标识符,semget函数失败时返回-1并设置errno。
如果semget函数用于创建信号量集,则与之关联的内核数据结构体semid_ds将被创建并初始化:

semget函数对semid_ds结构体的初始化包括:
1.将sem_perm.cuid和sem_perm.uid设为调用进程的有效用户ID。
2.将sem_perm.cgid和sem_perm.gid设为调用进程的有效组ID。
3.将sem_perm.mode的最低9位设为sem_flags参数的最低9位。
4.将sem_nsems设为num_sems参数。
5.将sem_otime设为0。
6.将sem_ctime设为当前系统时间。
semop系统调用改变信号量的值,即执行P、V操作,在讨论semop函数前,先介绍与每个信号量关联的一些重要的内核变量:
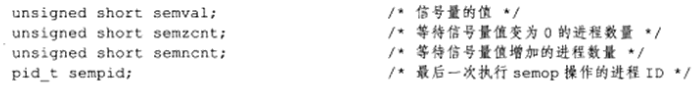
semop函数对信号量的操作实际就是改变上图中内核变量的操作,该函数定义如下:
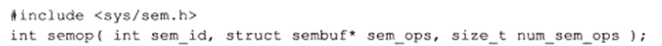
sem_id参数是由semget函数返回的信号量集标识符,用以指定被操作的目标信号量集。sem_ops参数指向一个sembuf结构体类型数组:

其中,sem_num成员是信号集中信号量的编号,0表示信号量集中的第一个信号量。sem_op成员指定操作类型,其可选值为正整数、0、负整数,操作的行为会受到sem_flg成员的影响。sem_flg成员的可选值:
1.IPC_NOWAIT:无论信号量操作是否成功,semop调用都立即返回,这类似于非阻塞IO操作。
2.SEM_UNDO:当进程退出时,取消正在进行的semop操作。
sem_op成员和sem_flg成员按以下方式影响semop函数的行为:
1.如果sem_op成员大于0,则semop将被操作的信号量的值semval增加sem_op成员值。该操作要求调用进程对被操作信号量集拥有写权限。此时若设置了SEM_UNDO标志,则系统将更新进程的semadj变量(用来跟踪进程对信号量的修改)。
2.如果sem_op成员等于0,则表示这是一个等待0(wait-for-zero)操作,该操作要求调用进程对被操作信号量集拥有读权限。如果此时信号量的值是0,则调用立即成功返回;如果信号量的值非0,则semop函数失败返回(当IPC_NOWAIT标志被指定)并将errno设为EAGAIN,或阻塞进程(没有指定IPC_NOWAIT标志)以等待信号量变为0。如果未指定IPC_NOWAIT标志,则信号量的semzcnt值加1,进程被投入睡眠,直到以下三个条件之一发生:
(1)信号量的值semval变为0,此时系统将该信号量的semzcnt值减1。
(2)被操作信号量所在的信号量集被进程移除,此时semop函数失败返回,errno被设为EIDRM。
(3)调用被信号中断,此时semop函数失败返回,errno被设为EINTR,同时系统将该信号量的semzcnt值减1。
3.如果sem_op成员小于0,表示对信号量值进行减操作,即期望获得信号量。该操作要求调用进程对被操作信号量拥有写权限。如果信号量的值semval大于等于sem_op成员的绝对值,则semop函数操作成功,调用进程立即获得信号量,且系统将该信号量的值semval减去sem_op成员的绝对值。如果设置了SEM_UNDO标志,则系统将更新进程的semadj变量。如果信号量的值semval小于sem_op成员的绝对值,则semop函数失败返回或阻塞进程以等待信号量可用,此时,当IPC_NOWAIT标志被指定时,semop函数立即返回一个错误,并设置errno为EAGAIN,如果未指定IPC_NOWAIT标志,则信号量的semncnt值加1,进程被投入睡眠直到以下三个条件之一发生:
(1)信号量的值semncnt变得大于等于sem_op成员额绝对值,此时系统将该信号量的semncnt值减1,并将semval减去sem_op成员的绝对值,同时,如果SEM_UNDO标志被设置,则系统更新semadj变量。
(2)被操作信号量所在的信号量集被进程移除,此时semop函数失败返回,errno被设为EIDRM。
(3)函数被信号终端,此时semop函数失败返回,errno被置为EINTR,同时系统将该信号量的semncnt值减1。
semop系统调用的第3个参数num_sem_ops指定要执行的操作个数,即sem_ops数组中元素的个数。semop函数对sem_ops数组参数中的每个成员按数组顺序依次执行操作,且该过程是原子操作,以避免别的进程在同一时刻按不同顺序对该信号集中的信号量执行semop函数导致的竞态条件。
semop函数成功时返回0,失败则返回-1并设置errno,失败时,sem_ops数组参数中指定的所有操作都不被执行。
semctl系统调用允许调用者对信号量进行直接控制:

sem_id参数是由semget函数返回的信号量集标识符,用来指定被操作的信号量集。sem_num参数指定被操作的信号量在信号量集中的编号。command参数指定要执行的命令,有的命令需要调用者传递第4个参数,第4个参数的类型由操作类型决定,可能是一个整数或一个指向semun联合的指针,该联合在sys/sem.h头文件中被提到,但并没有在该头文件中被定义,这意味着在程序中使用semun之前,需要自己在代码中显式地声明这个联合体:


semctl函数支持的命令如下:
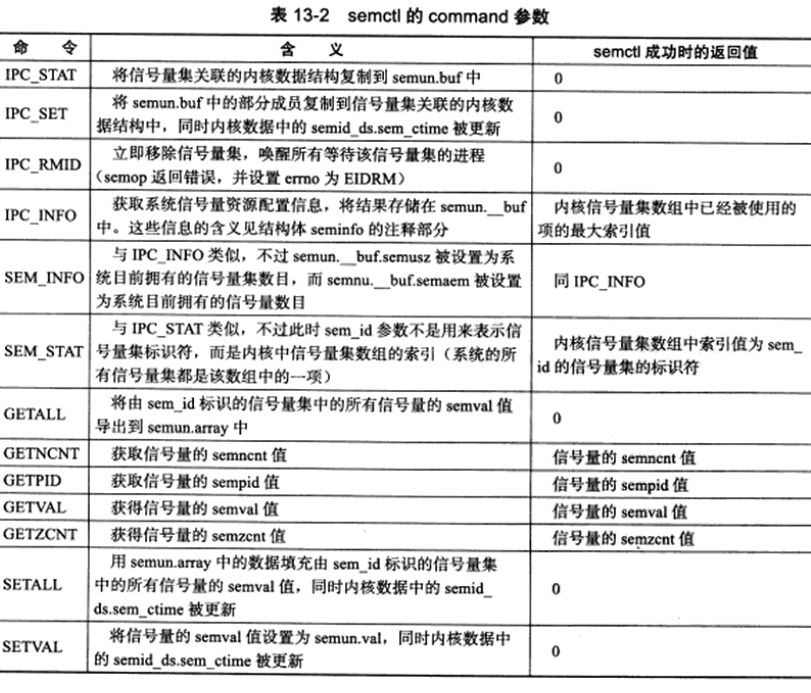
以上操作中,GETNCNT、GETPID、GETVAL、GETZCNT、SETVAL操作的是单个信号量,它是由sem_id标识符参数指定的信号量集中的第sem_num参数个信号量,而其他操作针对的是整个信号量集,此时semctl函数参数sem_num被忽略。
semctl函数成功时的返回值取决于command参数,如上表中最后一列所示。semctl函数失败时返回-1,并设置errno。
semget的调用者可以给其key参数传递一个特殊键值IPC_PRIVATE(其值为0),这样无论该信号量是否已存在,semget函数都将创建一个新信号量,使用该键值创建的信号量并非像它的名字声称的那样是进程私有的,其他进程,尤其是子进程,也有方法来访问这个信号量,所以semget函数的man手册的BUGS部分上说,使用名字IPC_PRIVATE有些误导(历史原因),应称为IPC_NEW。以下代码就在父子进程间使用一个IPC_PRIVATE信号量来同步:
#include <sys/sem.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
union semun {
int val;
struct semid_ds *buf;
unsigned short int *array;
struct seminfo *__buf;
};
// op参数为-1时执行P操作,为1时执行V操作
void pv(int sem_id, int op) {
struct sembuf sem_b;
sem_b.sem_num = 0;
sem_b.sem_op = op;
sem_b.sem_flg = SEM_UNDO;
semop(sem_id, &sem_b, 1);
}
int main(int argc, char *argv[]) {
int sem_id = semget(IPC_PRIVATE, 1, 0666);
union semun sem_un;
sem_un.val = 1;
semctl(sem_id, 0, SETVAL, sem_un);
pid_t id = fork();
if (id < 0) {
return 1;
} else if (id == 0) {
printf("child try to get binary sem\n");
// 在父子进程间共享IPC_PRIVATE信号量的关键在于两者都可以操作该信号量的标识符sem_id
pv(sem_id, -1);
printf("child get the sem and would release it after 5 seconds\n");
sleep(5);
pv(sem_id, 1);
exit(0);
} else {
printf("parent try to get binary sem\n");
pv(sem_id, -1);
printf("parent get the sem and would release it after 5 seconds\n");
sleep(5);
pv(sem_id, 1);
}
waitpid(id, NULL, 0);
semctl(sem_id, 0, IPC_RMID, sem_un);
return 0;
}
运行以上程序:

子进程是在父进程持有5秒并V操作后才获取到信号量。
另一个例子是:工作在prefork模式(prefork 模式是Apache服务器的一种多进程模型)下的httpd网页服务器程序使用1个IPC_PRIVATE信号量来同步各子进程对epoll_wait函数的调用权,在测试机器Kongming20上,使用strace命令依次查看httpd的各子进程是如何协调工作的:
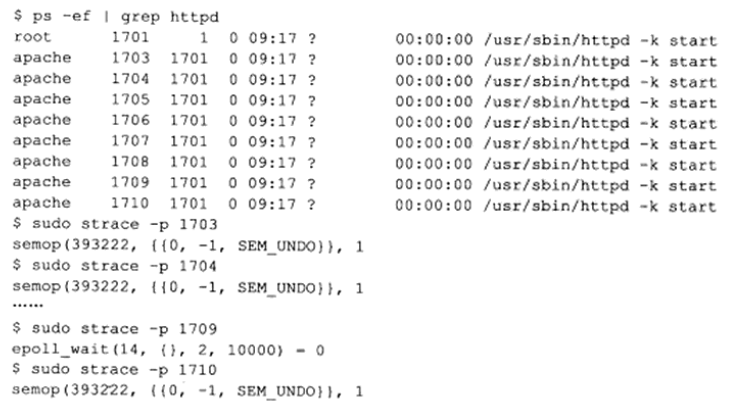
由上图,httpd子进程1703~1708和1710都在等待信号量393222(这是一个标识符)可用,只有进程1709暂时拥有该信号量,因为进程1709调用epoll_wait以等待新的客户连接。当有新连接到来时,进程1709将接受之,并对信号量执行V操作,此时将有另外一个子进程获得该信号量并调用epoll_wait来等待新的客户连接。
接下来讨论的另外两种IPC——共享内存和消息队列,也支持IPC_PRIVATE键值,其含义与信号量的IPC_PRIVATE键值完全相同。
共享内存是最高效的IPC机制,因为它不涉及进程之间的任何数据传输,这种高效率带来的问题是,我们必须用其他辅助手段来同步进程对共享内存的访问,否则会产生竞态条件,因此,共享内存通常和其他进程间通信方式一起使用。
Linux共享内存的API都定义在sys/shm.h头文件中,包括4个系统调用shmget、shmat、shmdt、shmctl。
shmget系统调用创建一段新的共享内存,或获取一段已经存在的共享内存,其定义为:
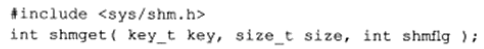
和semget系统调用一样,key参数是一个键值,用来标识一段全局唯一的共享内存。size参数指定共享内存的大小,单位是字节,如果是创建新的共享内存,则size参数必须被指定,如果是获取已经存在的共享内存,则可以把size参数设为0。
shmflg参数的使用和含义与semget系统调用的sem_flags参数相同,但shmget函数支持两个额外的标志:
1.SHM_HUGETLB:类似mmap函数的MAP_HUGETLB标志,系统将使用大页面来为共享内存分配空间。大页是一种更大的物理内存页面,相对于传统的小页(通常是4KB),大页的大小通常为2MB或更大,使用大页可以提高内存访问的性能,特别适用于需要大量内存的应用程序,如数据库和科学计算。
2.SHM_NORESERVE:类似于mmap函数的MAP_NORESERVE标志,不为共享内存保留交换分区(swap空间),这样,当物理内存不足时,对该共享内存执行写操作将触发SIGSEGV信号。
shmget函数成功时返回一个正整数值,它是共享内存的标识符。shmget函数失败时返回-1,并设置errno。
如果shmget函数用于创建共享内存,则这段共享内存的所有字节都被初始化为0,与之关联的内核数据结构shmid_ds将被创建并初始化:


shmget函数对shmid_ds结构体的初始化包括:
1.将shm_perm.cuid和shm_perm.uid设置为调用进程的有效用户ID。
2.将shm_perm.cgid和shm_perm.gid设置为调用进程的有效组ID。
3.将shm_perm_mode的最低9位设置为shmflg参数的最低9位。
4.将shm_segsz设置为size参数。
5.将shm_lpid、shm_nattach、shm_atime、shm_dtime设为0。
6.将shm_ctime设为当前时间。
共享内存被创建/获取后,我们不能立即访问它,而是需要先将它关联到进程的地址空间中,使用完共享内存后,我们也需要将它从进程地址空间中分离,这两项任务分别由以下两个系统调用实现:

shm_id参数是由shmget函数返回的共享内存标识符。shm_addr参数指定将共享内存关联到进程的哪块地址空间,最终效果还受到shmflg参数的可选标志SHM_RND的影响:
1.如果shm_addr参数为NULL,则被关联的地址由操作系统选择,这是推荐的做法,以确保代码的可移植性。
2.如果shm_addr参数非NULL,且SHM_RND标志未被设置,则共享内存被关联到addr参数指定的地址处。
3.如果shm_addr参数非NULL,且SHM_RND标志被设置,则被关联的地址是[shm_addr - (shm_addr % SHMLBA)],SHMLBA的含义是段低端边界地址倍数(Segment Low Boundary Address Multiple),它必须是内存页面大小(PAGE_SIZE)的整数倍,现在的Linux内核中,它等于一个内存页大小。SHM_RND标志的含义是圆整(round),即将共享内存被关联的地址向下圆整到离shm_addr参数最近的SHMLBA的整数倍地址处。
除了SHM_RND标志外,shmflg参数还支持以下标志:
1.SHM_RDONLY:进程仅能读取共享内存中的内容,若没有指定该标志,则进程可同时对共享内存进行读写操作(需要创建共享内存时指定其读写权限)。
2.SHM_REMAP:如果地址shmaddr参数已经被关联到一段共享内存,则重新关联。
3.SHM_EXEC:它指定对共享内存的执行权限,其作用是允许将共享内存段中的数据作为代码被执行。
shmat函数成功时返回共享内存被关联到的地址,失败则返回(void *)-1并设置errno,shmat函数成功时,将修改内核数据结构shmid_ds的以下字段:
1.将shm_nattach加1。
2.将shm_lpid设置为调用进程的PID。
3.将shm_atime设置为当前时间。
shmdt函数将关联到shm_addr参数处的共享内存从进程中分离,它成功时返回0,失败则返回-1并设置errno。shmdt函数在成功调用时将修改内核数据结构shmid_ds的部分字段:
1.将shm_nattach减1。
2.将shm_lpid设置为调用进程的PID。
3.将shm_dtime设置为当前时间。
shmctl系统调用控制共享内存的某些属性:

shm_id参数是由shmget函数返回的共享内存标识符。command参数指定要执行的命令:
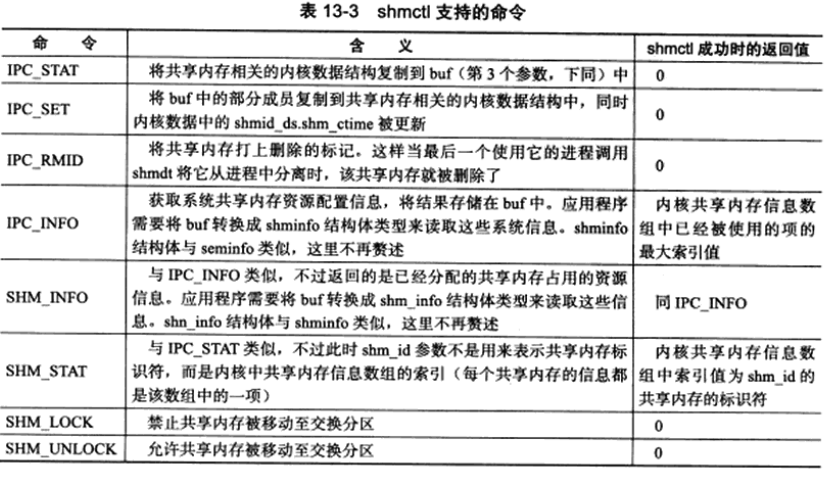
shmctl函数成功时的返回值取决于command参数,如上表中最后一列所示。shmctl函数失败时返回-1并设置errno。
我们可以利用mmap函数的MAP_ANONYMOUS标志实现父子进程间的匿名内存共享,通过打开同一个文件,mmap也可以实现无关进程之间的内存共享。Linux提供了另一种在无关进程间共享内存的方式,这种方式无须任何文件的支持,但它需要先用shm_open函数来创建或打开一个POSIX共享内存对象:

shm_open函数的使用方法与open系统调用完全相同。
name参数指定要创建或打开的共享内存对象,从可移植性角度考虑,该参数应使用/somename的格式,以/开始,后接多个不是/的字符,然后以\0结尾,长度不超过NAME_MAX(通常是255)。
oflag参数是以下标志的一个或多个按位或:
1.O_RDONLY:以只读方式打开共享内存对象。
2.O_RDWR:以可读、可写方式打开共享内存对象。
3.O_CREAT:如果共享内存对象不存在,则创建之,此时mode参数的最低9位将指定该共享内存对象的访问权限。共享内存对象被创建时,长度为0。
4.O_EXCL:和O_CREAT一起使用,如果由name参数指定的共享内存对象已存在,则shm_open函数返回错误,否则创建一个新的共享内存对象。
5.O_TRUNC:如果共享内存对象已存在,则将它截断,使其长度为0。
shm_open函数成功时返回一个文件描述符,该文件描述符可用于后续的mmap调用,从而将共享内存关联到调用进程。shm_open函数失败时返回-1,并设置errno。
和打开的文件最后需要关闭一样,由shm_open函数创建的共享内存对象用完后也需要删除,可通过shm_unlink函数实现:

shm_unlink函数将name参数指定的共享内存对象标记为等待删除,当所有使用该共享内存对象的进程都使用munmap函数将它从进程中分离后,系统将销毁这个共享内存对象所占据的资源。
如果代码中使用了以上POSIX共享内存函数,则编译时需要指定链接选项-lrt。
将第九章中的聊天室服务器程序改为一个多进程服务器,一个子进程处理一个客户连接,同时,将所有客户socket连接的读缓冲设计为一块共享内存:
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/ineth>
#include <assert.h>
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include <signal.h>
#include <sys/wait.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <libgen.h>
#define USER_LIMIT 5
#define BUFFER_SIZE 1024
#define FD_LIMIT 65535
#define MAX_EVENT_NUMBER 1024
#define PROCESS_LIMIT 65536
// 处理一个客户连接所必要的数据
struct client_data {
// 客户的socket地址
sockaddr_in address;
// socket文件描述符
int connfd;
// 处理这个连接的子进程PID
pid_t pid;
// 和父进程通信用的管道
int pipefd[2];
};
static const char *shm_name = "/my_shm";
int sig_pipefd[2];
int epollfd;
int listenfd;
int shmfd;
char *share_mem = 0;
// 客户连接数组,进程用客户连接的编号来索引这个数组,即可取得相关客户的连接数据
client_data *users = 0;
// 子进程和客户连接的映射关系表,用进程的PID来索引这个数组,即可取得该进程处理的客户连接的编号
int *sub_process = 0;
// 当前客户数量
int user_count = 0;
bool stop_child = false;
int setnonblocking(int fd) {
int old_option = fcntl(fd, F_GETFL);
int new_option = old_option | O_NONBLOCK;
fcntl(fd, F_SETFL, new_option);
return old_option;
}
void addfd(int epollfd, int fd) {
epoll_event event;
event.data.fd = fd;
event.events = EPOLLIN | EPOLLET;
epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event);
setnonblocking(fd);
}
void sig_handler(int sig) {
int save_errno = errno;
int msg = sig;
// bug,如果主机字节序是大端字节序,则传递的值为0
send(sig_pipefd[1], (char *)&msg, 1, 0);
errno = save_errno;
}
void addsig(int sig, void (*handler)(int), bool restart = true) {
struct sigaction sa;
memset(&sa, '\0', sizeof(sa));
sa.sa_handler = handler;
if (restart) {
sa.sa_flags |= SA_RESTART;
}
sigfillset(&sa.sa_mask);
assert(sigaction(sig, &sa, NULL) != -1);
}
void del_resource() {
close(sig_pipefd[0]);
close(sig_pipefd[1]);
close(listenfd);
close(epollfd);
shm_unlink(shm_name);
delete[] users;
delete[] sub_process;
}
// 停止一个子进程
void child_term_handler(int sig) {
stop_child = true;
}
// 子进程运行的函数,参数idx指出该子进程处理的客户连接的编号,users参数是保存所有客户连接数据的数组
// share_mem参数指出共享内存的起始地址
int run_child(int idx, client_data *users, char *share_mem) {
epoll_event events[MAX_EVENT_NUMBER];
// 子进程使用IO复用同时监听两个文件描述符:客户连接socket、与父进程通信的管道文件描述符
int child_epollfd = epoll_create(5);
assert(child_epollfd != -1);
int connfd = users[idx].connfd;
addfd(child_epollfd, connfd);
int pipefd = users[idx].pipefd[1];
addfd(child_epollfd, pipefd);
int ret;
// 设置子进程的SIGTERM信号的处理函数
addsig(SIGTERM, child_term_handler, false);
while (!stop_child) {
int number = epoll_wait(child_epollfd, events, MAX_EVENT_NUMBER, -1);
if ((number < 0) && (errno != EINTR)) {
printf("epoll failure\n");
break;
}
for (int i = 0; i < number; ++i) {
int sockfd = events[i].data.fd;
// 本子进程负责的客户连接有数据到达
if ((sockfd == connfd) && (event[i].events & EPOLLIN)) {
// 作者在此处每次读前初始化要读到的目标内存,效率较低
// 每次读完数据后,在读到的数据最后加一个空字符可能是个更好的方法
memset(share_mem + idx * BUFFER_SIZE, '\0', BUFFER_SIZE);
// 将客户数据读取到共享内存中的一段空间中,这段空间仅由本进程写
ret = recv(connfd, share_mem + idx * BUFFER_SIZE, BUFFER_SIZE - 1, 0);
if (ret < 0) {
if (errno != EAGAIN) {
stop_child = true;
}
} else if (ret == 0) {
stop_child = true;
} else {
// 成功读取客户数据后通过管道通知主进程来处理,将发送消息的客户连接的编号发给主进程
send(pipefd, (char *)&idx, sizeof(idx), 0);
}
// 主进程通过管道通知本进程将第client个客户(其他客户)的数据发送到本进程负责的客户端
// 即第client个客户发了消息,要将该客户发的消息发给其他客户
} else if ((sockfd == pipefd) && (events[i].events & EPOLLIN)) {
int client = 0;
// 接收主进程通过管道发来的发送消息的客户的编号,即client
ret = recv(sockfd, (char *)&client, sizeof(client), 0);
if (ret < 0) {
if (errno != EAGAIN) {
stop_child = true;
}
} else if (ret == 0) {
stop_child = true;
} else {
send(connfd, share_mem + client * BUFFER_SIZE, BUFFER_SIZE, 0);
}
} else {
continue;
}
}
}
close(connfd);
close(pipefd);
close(child_epollfd);
return 0;
}
int main(int argc, char *argv[]) {
if (argc != 3) {
printf("usage: %s ip_address port_number\n", basename(argv[0]));
return 1;
}
const char *ip = argv[1];
int port = atoi(argv[2]);
int ret = 0;
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
inet_pton(AF_NET, ip, &address.sin_addr);
address.sin_port = htons(port);
listenfd = socket(PF_INET, SOCK_STREAM, 0);
assert(listenfd >= 0);
ret = bind(listenfd, (struct sockaddr *)&address, sizeof(address));
assert(ret != -1);
ret = listen(listenfd, 5);
assert(ret != -1);
user_count = 0;
users = new client_data[USER_LIMIT + 1];
sub_process = new int[PROCESS_LIMIT];
for (int i = 0; i < PROCESS_LIMIT; ++i) {
sub_process[i] = -1;
}
epoll_event events[MAX_EVENT_NUMBER];
epollfd = epoll_create(5);
assert(epollfd != -1);
addfd(epollfd, listenfd);
ret = socketpair(PF_UNIX, SOCK_STREAM, 0, sig_pipefd);
assert(ret != -1);
setnonblocking(sig_pipefd[1]);
addfd(epollfd, sig_pipefd[0]);
addsig(SIGCHLD, sig_handler);
addsig(SIGTERM, sig_handler);
addsig(SIGINT, sig_handler);
addsig(SIGPIPE, SIG_IGN);
bool stop_server = false;
bool terminate = false;
// 创建共享内存
shmfd = shm_open(shm_name, O_CREAT | O_RDWR, 0666);
assert(shmfd != -1);
// ftruncate是用于修改文件大小的系统调用函数,也可用于修改共享内存大小
ret = ftruncate(shmfd, USER_LIMIT * BUFFER_SIZE);
assert(ret != -1);
// mmap函数的第1个参数为NULL,表示让内核自动选择映射地址
// 第4个参数是MAP_SHARED,表示共享内存可以被多个进程共享
// 第5个参数指定要映射的文件或共享内存对象
// 第6个参数指定要映射的文件或共享内存的起始位置
share_mem = (char *)mmap(NULL, USER_LIMIT * BUFFER_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED,
shmfd, 0);
assert(share_mem != MAP_FAILED);
close(shmfd);
while (!stop_server) {
int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1);
if ((number < 0) && (errno != EINTR)) {
printf("epoll failure\n");
break;
}
for (int i = 0; i < number; ++i) {
int sockfd = events[i].data.fd;
// 新的客户连接到来
if (sockfd == listenfd) {
struct sockaddr_in client_address;
socklen_t client_addrlength = sizeof(client_address);
int connfd = accept(listenfd, (struct sockaddr *)&client_address,
&client_addrlength);
if (connfd < 0) {
printf("errno is: %s\n", errno);
continue;
}
if (user_count >= USER_LIMIT) {
const char *info = "too many users\n";
printf("%s", info);
send(connfd, info, strlen(info), 0);
close(connfd);
continue;
}
// 保存第user_count个客户连接的相关数据
users[user_count].address = client_address;
users[user_count].connfd = connfd;
// socketpair函数的第3个协议参数为0表示将使用适合于第二个套接字类型参数的默认协议
// 在主进程和子进程之间建立管道,以传递必要的数据
ret = socketpair(PF_UNIX, SOCK_STREAM, 0, users[user_count].pipefd);
assert(ret != -1);
pid_t pid = fork();
if (pid < 0) {
// 此处子进程分配失败,关闭了已连接描述符
// 但socketpair创建的管道描述符仍未关闭,下次客户连接会创建新的管道
// 可能导致描述符达到进程能处理的上限
close(connfd);
continue;
} else if (pid == 0) {
close(epollfd);
close(listenfd);
close(users[user_count].pipefd[0]);
close(sig_pipefd[0]);
close(sig_pipefd[1]);
run_child(user_count, users, share_mem);
// 只有所有进程都调用munmap将共享内存从进程分离后,系统才销毁这个共享内存对象所占据的资源
munmap((void *)share_mem, USER_LIMIT * BUFFER_SIZE);
exit(0);
} else {
close(connfd);
close(users[user_count]pipefd[1]);
addfd(epollfd, users[user_count].pipefd[0]);
users[user_count].pid = pid;
// 记录新的客户连接在数组users中的索引值(即客户连接的编号)
// 此处是有问题的,pid_t的类型通常是int,而sub_process数组大小只有65536
// 此处sub_process用unordered_map类型可能是更好的选择
sub_process[pid] = user_count;
++user_count;
}
// 处理信号事件
} else if ((sockfd == sig_pipefd[0]) && (events[i].events & EPOLLIN)) {
int sig;
char signals[1024];
ret = recv(sig_pipefd[0], signals, sizeof(signals), 0);
if (ret == -1) {
continue;
} else if (ret == 0) {
continue;
} else {
for (int i = 0; i < ret; ++i) {
switch (signals[i]) {
// 子进程退出,某个客户关闭了连接
case SIGCHLD:
pid_t pid;
int stat;
while ((pid = waitpid(-1, &stat, WNOHANG)) > 0) {
// 用子进程的pid取得被关闭的客户连接的编号
int del_user = sub_process[pid];
sub_process[pid] = -1;
if (del_user < 0 || del_user > USER_LIMIT) {
continue;
}
// 清除第del_user个客户连接的相关数据
epoll_ctl(epollfd, EPOLL_CTL_DEL, users[del_user].pipefd[0], 0);
close(users[del_user].pipefd[0]);
// 此处有个bug,作者是想把最大的客户连接的编号改为刚关闭连接的编号
// 如果此时编号最大的客户连接有数据到达
// 实际读到的数据还是存在原编号最大的连接对应的内存
// 然后让主线程读原编号最大的连接对应的内存
// 如果后面有了新连接,占用了原来最大的编号
// 则会出现两个线程同时写同一块内存的情形
users[del_user] = users[--user_count];
sub_process[users[del_user].pid] = del_user;
}
if (terminate && user_count == 0) {
stop_server = true;
}
break;
case SIGTERM:
case SIGINT:
// 结束服务器程序
printf("kill all the child now\n");
if (user_count == 0) {
stop_server = true;
break;
}
for (int i = 0; i < user_count; ++i) {
int pid = users[i].pid;
kill(pid, SIGTERM);
}
terminate = true;
break;
default:
break;
}
}
}
// 某个子进程向父进程写入了数据
} else if (events[i].events & EPOLLIN) {
int child = 0;
// 读取管道数据,child变量记录了发送消息的客户的连接编号
ret = recv(sockfd, (char *)&child, sizeof(child), 0);
printf("read data from child across pipe\n");
if (ret == -1) {
continue;
} else if (ret == 0) {
continue;
} else {
// 向除了发送客户外的其他所有客户的子进程发消息,通知它们有客户数据要写
for (int j = 0; j < user_count; ++j) {
if (users[j].pipefd[0] != sockfd) {
printf("send data to child across pipe\n");
send(users[j].pipefd[0], (char *)&child, sizeof(child), 0);
}
}
}
}
}
}
del_resource();
return 0;
}
上面代码有两点需要注意:
1.虽然我们使用了共享内存,但每个子进程都只会往自己所处理的客户连接所对应的那部分内存中写数据,所以我们使用共享内存的目的只是为了共享读,因此,每个子进程在使用共享内存时都无须加锁。
2.我们的服务器启动时给users数组分配了足够多的空间,使得它可以存储所有可能的客户连接的相关数据,同样,我们给sub_process数组分配的空间也足以存储所有可能的子进程的相关数据,这是牺牲空间换取时间的例子。
消息队列是在两个进程间传递二进制数据块的方式,每个数据块都有一个特定类型,接收方可以根据类型来有选择地接收数据,而不一定像管道和命名管道那样必须以先进先出的方式接收数据。
Linux消息队列的API都定义在sys/msg.h头文件中,包括4个系统调用:msgget、msgsnd、msgrcv、msgctl。
msgget系统调用创建一个消息队列,或获取一个已有的消息队列:

key参数是一个键值,用来标识一个全局唯一的消息队列。
msgflg参数的使用和含义与semget系统调用的sem_flags参数相同。
msgget函数成功时返回一个正整数值,它是消息队列的标识符,失败时返回-1并设置errno。
如果msgget函数用于创建消息队列,则与之关联的内核数据结构msqid_ds将被创建并初始化:

msgsnd系统调用将一条消息添加到消息队列中:
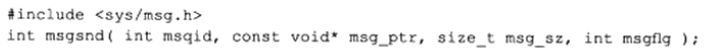
msqid参数是由msgget函数返回的消息队列标识符。
msg_ptr参数指向一个准备发送的消息,消息被定义为如下类型:
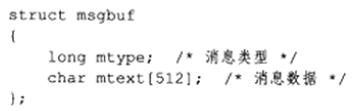
mtype成员指定消息的类型,它必须是一个正整数。mtext成员是消息数据。msg_sz参数是消息的数据部分(mtext成员)的长度,这个长度可以为0,表示没有消息数据。
msgflg参数控制msgsnd函数的行为,它通常仅支持IPC_NOWAIT标志,即以非阻塞方式发送消息。默认,发送消息时如果消息队列满,则msgsnd函数将阻塞,若指定了IPC_NOWAIT标志,则msgsnd函数将立即返回并设置errno为EAGAIN。
处于阻塞状态的msgsnd函数可能被以下两种异常情况所中断:
1.消息队列被移除,此时msgsnd函数将立即返回并设置errno为EIDRM。
2.进程接收到信号,此时msgsnd函数将立即返回并设置errno为EINTR。
msgsnd函数成功时返回0,失败则返回-1并设置errno。msgsnd函数成功时将修改内核数据结构msqid_ds的以下字段:
1.将msg_qnum加1。
2.将msg_lspid设置为调用进程的PID。
3.将msg_stime设置为当前系统时间。
msgrcv系统调用从消息队列中获取消息:

msqid参数是由msgget函数返回的消息队列标识符。
msg_ptr参数用于存储接收的消息。msg_sz参数是消息数据部分的长度。
msgtype参数指定接收何种类型的消息,它的取值含义如下:
1.等于0:读取消息队列中第一个消息。
2.大于0:读取消息队列中第一个类型为msgtype的消息(除非指定了标志MSG_EXCEPT)。
3.小于0:读取消息队列中第一个类型值比msgtype的绝对值小的消息。
参数msgflg控制msgrcv函数的行为,它是以下标志的按位或:
1.IPC_NOWAIT:如果消息队列中没有消息,则msgrcv函数立即返回并设置errno为ENOMSG。
2.MSG_EXCEPT:如果msgtype参数大于0,则接收消息队列中第一个非msgtype参数类型的消息。
3.MSG_NOERROR:如果消息数据部分的长度超过了msg_sz,则将它截断。
处于阻塞状态的msgrcv函数可能被以下异常情况中断:
1.消息队列被移除,此时msgrcv函数将立即返回并设置errno为EIDRM。
2.进程接收到信号,此时msgrcv函数将立即返回并设置errno为EINTR。
msgrcv函数成功时返回0,失败则返回-1并设置errno。msgrcv函数成功时将修改内核数据结构msqid_ds的以下字段:
1.将msg_qnum减1。
2.将msg_lrpid设为当前调用进程的PID。
3.将msg_rtime设为当前时间。
msgctl系统调用控制消息队列的某些属性:

msqid参数是由msgget函数返回的共享内存标识符。command参数是要执行的命令,可选命令如下:


msgctl函数成功时的返回值取决于command参数,见上表最后一列。msgctl函数失败时返回-1并设置errno。
以上3种System V IPC进程间通信方式都使用一个全局唯一的键值来描述一个共享资源,当程序调用semget、shmget、msgget时,就创建了这些共享资源的一个实例。Linux提供ipcs命令来观察当前系统上拥有哪些共享资源实例,如在Kongming20上执行ipcs命令:
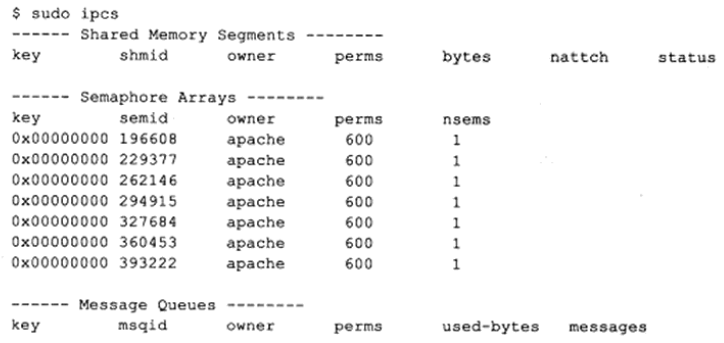
上图中的输出结果分段显示了系统拥有的共享内存、信号量、消息队列资源,可见,该系统目前尚未使用任何共享内存和消息队列,但分配了一组键值为0(IPC_PRIVATE)的信号量,这些信号量的所有者是apache,因此它们是由httpd服务器进程创建的。标识符为393222的信号量正是上面我们讨论httpd各个子进程间同步epoll_wait函数使用权的信号量。
我们可用ipcrm命令删除遗留在系统中的共享资源。
fork调用后,父进程中打开的文件描述符在子进程中仍然保持打开,所以文件描述符可以很方便地从父进程传递到子进程。传递一个文件描述符并不是传递一个文件描述符的值,而是在接收进程中创建一个新的文件描述符,且新文件描述符和发送进程中被传递的文件描述符指向内核中相同的文件表项。
在Linux下,可利用UNIX域socket在进程间传递特殊的辅助数据,以实现文件描述符的传递,下例代码中,子进程中打开一个文件描述符,然后将它传递给父进程,父进程则通过读取该文件描述符来获得文件内容:
#include <sys/socket.h>
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <assert.h>
#include <string.h>
static const int CONTROL_LEN = CMSG_LEN(sizeof(int));
// 发送文件描述符,fd参数是用来传递信息的UNIX域socket,fd_to_send参数是待发送的文件描述符
void send_fd(int fd, int fd_to_send) {
struct iovec iov[1];
struct msghdr msg;
// 没有数据要发送
char buf[0];
iov[0].iov_base = buf;
iov[0].iov_len = 1;
msg.msg_name = NULL;
msg.msg_namelen = 0;
msg.msg_iov = iov;
msg.msg_iovlen = 1;
cmsghdr cm;
cm.cmsg_len = CONTROL_LEN;
cm.cmsg_level = SOL_SOCKET;
cm.cmsg_type = SCM_RIGHTS;
*(int *)CMSG_DATA(&cm) = fd_to_send;
// 设置辅助数据
msg.msg_control = &cm;
msg.msg_controllen = CONTROL_LEN;
sendmsg(fd, &msg, 0);
}
// 接收目标文件描述符
int recv_fd(int fd) {
struct iovec iov[1];
struct msghdr msg;
char buf[0];
iov[0].iov_base = buf;
iov[0].iov_len = 1;
msg.msg_name = NULL;
msg.msg_namelen = 0;
msg.msg_iov = iov;
msg.msg_iovlen = 1;
cmsghdr cm;
msg.msg_control = &cm;
msg.msg_controllen = CONTROL_LEN;
recvmsg(fd, &msg, 0);
int fd_to_read = *(int *)CMSG_DATA(&cm);
return fd_to_read;
}
int main() {
int pipefd[2];
int fd_to_pass = 0;
// 创建父、子进程间的管道,文件描述符pipefd[0]和pipefd[1]都是UNIX域socket
int ret = socketpair(PF_UNIX, SOCK_DGRAM, 0, pipefd);
assert(ret != -1);
pid_t pid = fork();
assert(pid >= 0);
if (pid == 0) {
close(pipefd[0]);
fd_to_pass = open("test.txt", O_RDWR, 0666);
// 子进程通过管道将文件描述符发送到父进程,如果文件打开失败,则子进程将标准输入发送到父进程
send_fd(pipefd[1], (fd_to_pass > 0) ? fd_to_pass : 0);
close(fd_to_pass);
exit(0);
}
close(pipefd[1]);
// 父进程从管道接收目标文件描述符
fd_to_pass = recv_fd(pipefd[0]);
char buf[1024];
memset(buf, '\0', 1024);
// 读目标文件描述符,验证其有效性
read(fd_to_pass, buf, 1024);
printf("I got fd %d and data %s\n", fd_to_pass, buf);
close(fd_to_pass);
}










![命令执行绕过 [GXYCTF2019]Ping Ping Ping1](https://img-blog.csdnimg.cn/c4a9c1cb751347df8c54f0de26ebaeaf.png)