简单的爬虫
先举一个爬取图片网站图片保存到本地文件夹的例子
原博客:http://t.csdnimg.cn/Cjv3o
这是一个图片网站
https://pic.netbian.com/
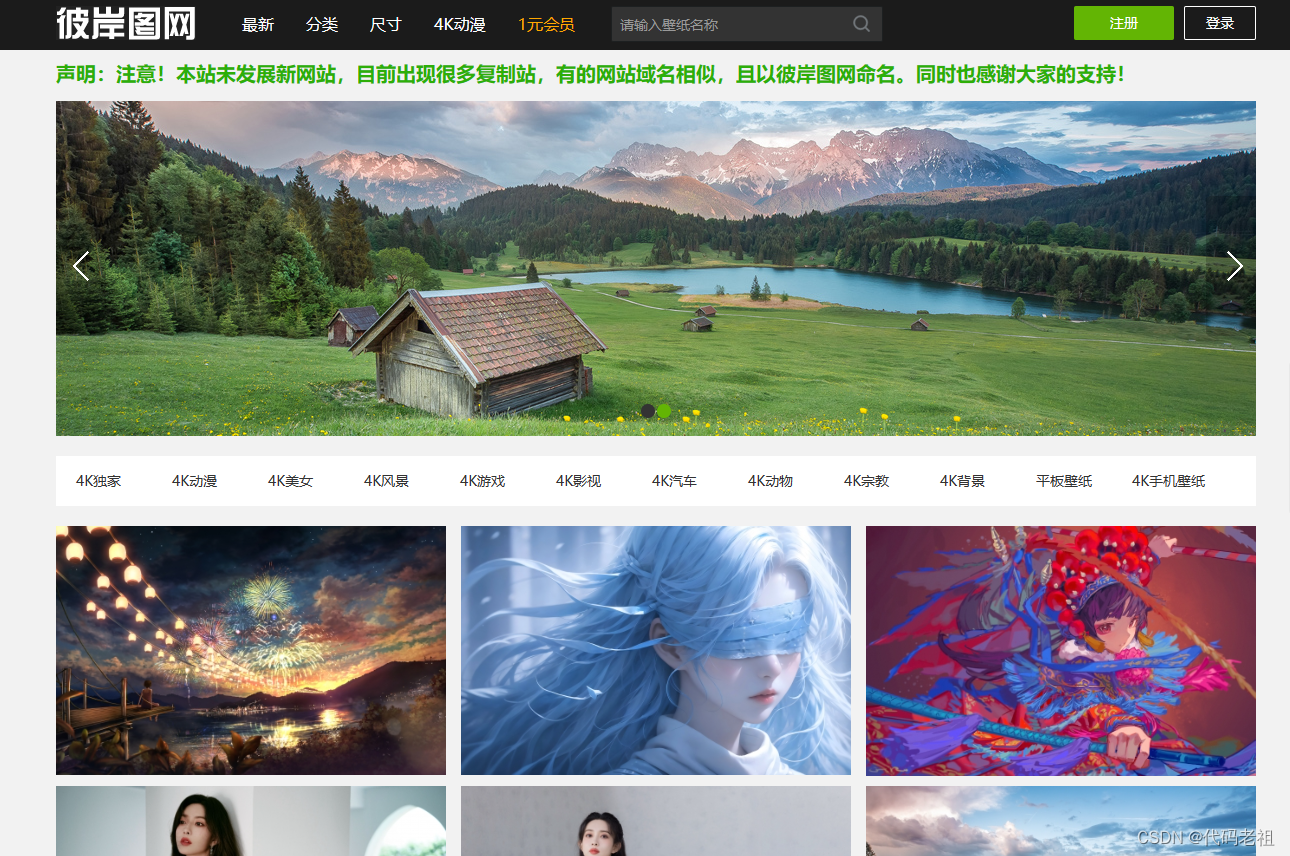
在空白处右键,查看页面源代码,我们发现有具体内容的

我们使用下面的代码可以爬取这个页面所有图片,并且保存在这个Python项目里面的文件夹中

import requests
import re
import osurl = "https://pic.netbian.com/"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"
}response = requests.get(url=url,headers=headers)
response.encoding = response.apparent_encoding"""
. 表示除空格外任意字符(除\n外)
* 表示匹配字符零次或多次
? 表示匹配字符零次或一次
.*? 非贪婪匹配
"""
parr = re.compile('src="(/u.*?)".alt="(.*?)"') # 匹配图片链接和图片名字
image = re.findall(parr,response.text)path = "彼岸图网图片获取"
if not os.path.isdir(path): # 判断是否存在该文件夹,若不存在则创建
os.mkdir(path) # 创建
# 对列表进行遍历
for i in image:
link = i[0] # 获取链接
name = i[1] # 获取名字
"""
在文件夹下创建一个空jpg文件,打开方式以 'wb' 二进制读写方式
@param res:图片请求的结果
"""
with open(path+"/{}.jpg".format(name),"wb") as img:
res = requests.get("https://pic.netbian.com"+link)
img.write(res.content) # 将图片请求的结果内容写到jpg文件中
img.close() # 关闭操作
print(name+".jpg 获取成功······")
回归正题,我们需要爬取iview和element网站的图标库中图标名称
首先我们知道iview的图标组件的网址是:http://v4.iviewui.com/components/icon
我们在空白处右键查看页面源代码,发现是空白的
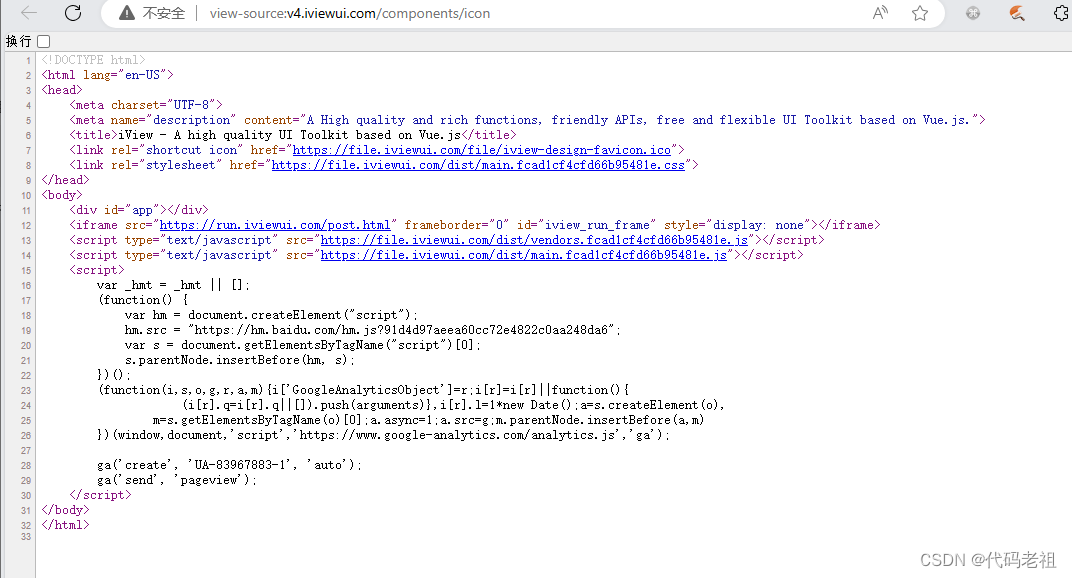
这是因为vue的渲染机制
动态生成内容:网页的内容是通过 JavaScript 动态生成的,而右键查看源代码只会显示初始加载的 HTML 结构,而不会显示后续通过 JavaScript 生成的内容。这可能是导致源代码为空白的原因。你可以尝试使用浏览器的开发者工具(通常通过按 F12 键打开)来查看动态生成的内容。
使用浏览器的开发者工具:打开浏览器的开发者工具(通常通过按 F12 键打开),切换到 "Elements" 或 "Elements" 选项卡,这里会显示页面的 DOM 结构和动态生成的内容。
那么我们怎么让爬虫执行操作看到dom结构呢?
可以使用 selenium
首先安装 pip install selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
# 初始化 Selenium WebDriver,选择适合的浏览器驱动,如 ChromeDriver
driver = webdriver.Chrome()
driver.maximize_window() #设置窗口最大化
driver.implicitly_wait(1) #设置等待3秒后打开目标网页
url="http://v4.iviewui.com/components/icon"
#使用get方法访问网站
driver.get(url)
# 找到所有的 .icons-item 元素
icon_items = driver.find_elements(By.CSS_SELECTOR, '.icons-item')
# 遍历打印每个元素的文本内容
for item in icon_items:
print(item.text)
#退出浏览器
driver.quit()
这个运行需要一点时间
控制台打印

icon_items = driver.find_elements(By.CSS_SELECTOR, '.icons-item')
为什么我们找icons-item ?
在f12元素中我们看到图标都在这里面

我们在iview的组件页复制图标是这个 <Icon type="ios-add" />
但是我们通常需要 icon="md-redo"
print的时候处理一下就行了

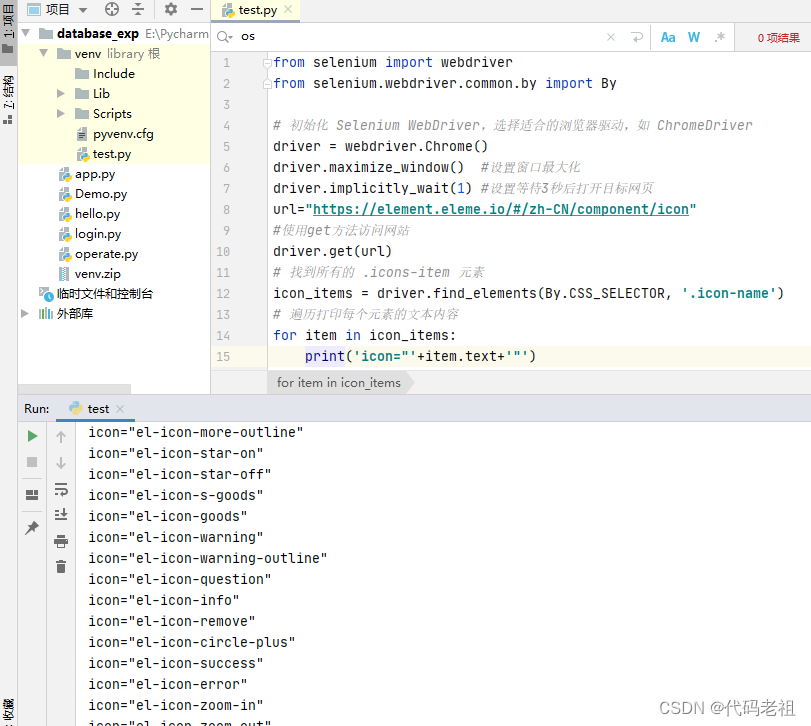
下面我们爬取element的
图标网页地址: https://element.eleme.io/#/zh-CN/component/icon
我们看 f 12元素

所以所有icon-name就行了
from selenium import webdriver
from selenium.webdriver.common.by import By
# 初始化 Selenium WebDriver,选择适合的浏览器驱动,如 ChromeDriver
driver = webdriver.Chrome()
driver.maximize_window() #设置窗口最大化
driver.implicitly_wait(1) #设置等待3秒后打开目标网页
url="https://element.eleme.io/#/zh-CN/component/icon"
#使用get方法访问网站
driver.get(url)
# 找到所有的 .icon-name 元素
icon_items = driver.find_elements(By.CSS_SELECTOR, '.icon-name')
# 遍历打印每个元素的文本内容
for item in icon_items:
print('icon="'+item.text+'"')
#退出浏览器
driver.quit()
在 Selenium 中,find_element 和 find_elements 是 WebDriver 对象的方法,用于查找网页中的元素。它们的区别如下:
find_element:该方法用于查找单个匹配的元素。如果找到多个匹配的元素,它只会返回第一个匹配的元素。find_elements:该方法用于查找所有匹配的元素,并返回一个元素列表。
选择器的使用方法取决于选择器的类型。以下是一些常见的选择器和使用方法:
-
By.ID:通过元素的 ID 属性进行选择。
例如:driver.find_element(By.ID, "my-element") -
By.CLASS_NAME:通过元素的 class 属性进行选择。
例如:driver.find_element(By.CLASS_NAME, "my-class") -
By.NAME:通过元素的 name 属性进行选择。
例如:driver.find_element(By.NAME, "my-name") -
By.CSS_SELECTOR:通过 CSS 选择器进行选择。
例如:driver.find_element(By.CSS_SELECTOR, ".my-selector") -
By.XPATH:通过 XPath 表达式进行选择。
例如:driver.find_element(By.XPATH, "//div[@class='my-class']")
这些选择器方法可以用于 find_element 和 find_elements。
关于调用的事件,你可以使用 driver 对象调用各种方法与元素进行交互和操作。以下是一些常见的可调用事件:
click():模拟单击元素。send_keys():向元素发送键盘输入。text:获取元素的文本内容。get_attribute():获取元素的某个属性值。clear():清空输入元素的内容。submit():提交表单元素。
这只是一些常见的事件和方法示例,Selenium 还提供了更多方法和事件,可以根据具体需求进行调用和使用。你可以参考 Selenium 文档或官方文档以获取更详细的信息。












![[小林coding]4.1TCP三次握手四次挥手笔记_1012](https://img-blog.csdnimg.cn/5bcbeaef2f7041a4b3928bc713f95dd8.png)