在昇腾AI处理器上训练PyTorch框架模型时,可能由于算子在CPU上的下发速度、动态shape等问题,导致性能降低,那么本期就分享几个关于PyTorch模型调优的典型案例,给出调优思路及具体的调优方法:
1、NPU亲和优化器替换调优案例
2、动态shape(算子二进制)调优案例
01 NPU亲和优化器替换调优案例
问题背景
在PyTorch混合精度模式下,每次迭代执行一次参数更新时,在Loss乘/除以缩放系数的过程中都会包含连续多个小算子(如add、mul、sqrt等)下发,由于小算子在NPU上计算快,导致算子在CPU上的下发成为性能的主要瓶颈。本调优案例以MobileNetV1模型为例,进行梯度融合调优解决此性能问题。
总体思路
使用昇腾AI处理器亲和的融合优化器替换原始优化器,昇腾AI处理器亲和的融合优化器可以在梯度更新过程中将连续多个小算子融合后下发,提升模型计算性能,完整融合优化器替换表如下所示。
用户可在代码中搜索关键词optim以搜索当前模型的优化器函数名,对照下表查看是否有可替换的亲和优化器。本例中使用torch_npu.optim.NpuFusedSGD替换原始优化器torch.optim.SGD。
| 优化器名称 | 样例原代码 | 修改后代码 |
| sgd | optimizer = torch.optim.SGD(model.parameters(), lr=args.lr) | optimizer = torch_npu.optim.NpuFusedSGD(model.parameters(), lr=args.lr) |
| adadelta | optimizer = torch.optim.Adadelta(model.parameters(), lr=args.lr) | optimizer = torch_npu.optim.NpuFusedAdadelta(model.parameters(), lr=args.lr) |
| lamb | optimizer = torch.optim.Lamb(model.parameters(), lr=args.lr) | optimizer = torch_npu.optim.NpuFusedLamb(model.parameters(), lr=args.lr) |
| adam | optimizer = torch.optim.Adam(model.parameters(), lr=args.lr) | optimizer = torch_npu.optim.NpuFusedAdam(model.parameters(), lr=args.lr) |
| adamw | optimizer = torch.optim.AdamW(model.parameters(), lr=args.lr) | optimizer = torch_npu.optim.NpuFusedAdamW(model.parameters(), lr=args.lr) |
| adamp | optimizer = torch.optim.AdamP(model.parameters(), lr=args.lr) | optimizer = torch_npu.optim.NpuFusedAdamP(model.parameters(), lr=args.lr) |
| bert_adam | optimizer = torch.optim.BertAdam(model.parameters(), lr=args.lr) | optimizer = torch_npu.optim.NpuFusedBertAdam(model.parameters(), lr=args.lr) |
| rmsprop | optimizer = torch.optim.RMSprop(model.parameters(), lr=args.lr) | optimizer = torch_npu.optim.NpuFusedRMSprop(model.parameters(), lr=args.lr) |
| rmsprop_tf | optimizer = torch.optim.RMSpropTF(model.parameters(), lr=args.lr) | optimizer = torch_npu.optim.NpuFusedRMSpropTF(model.parameters(), lr=args.lr) |
环境准备
点击获取链接,获取MobileNetV1模型,并根据readme准备训练环境和数据集。
注意:从昇腾ModelZoo上获取的MobileNetV1模型脚本为已经进行了梯度融合优化的版本。若用户想使用该模型脚本体验本案例中的调优流程,可先将模型脚本main.py中的优化器定义代码改为原始优化器torch.optim.SGD,再执行以下流程。
瓶颈识别
- 修改训练脚本还原原生优化器函数,此操作在原生模型脚本中无需进行。
model = model.to(device) # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().to(device) optimizer = torch.optim.SGD(model.parameters(), args.lr, momentum=args.momentum, weight_decay=args.weight_decay) if args.apex: model, optimizer = amp.initialize(model, optimizer, opt_level=args.apex_opt_level, loss_scale=args.loss_scale_value, combine_grad=True)执行训练,记录耗时。
-
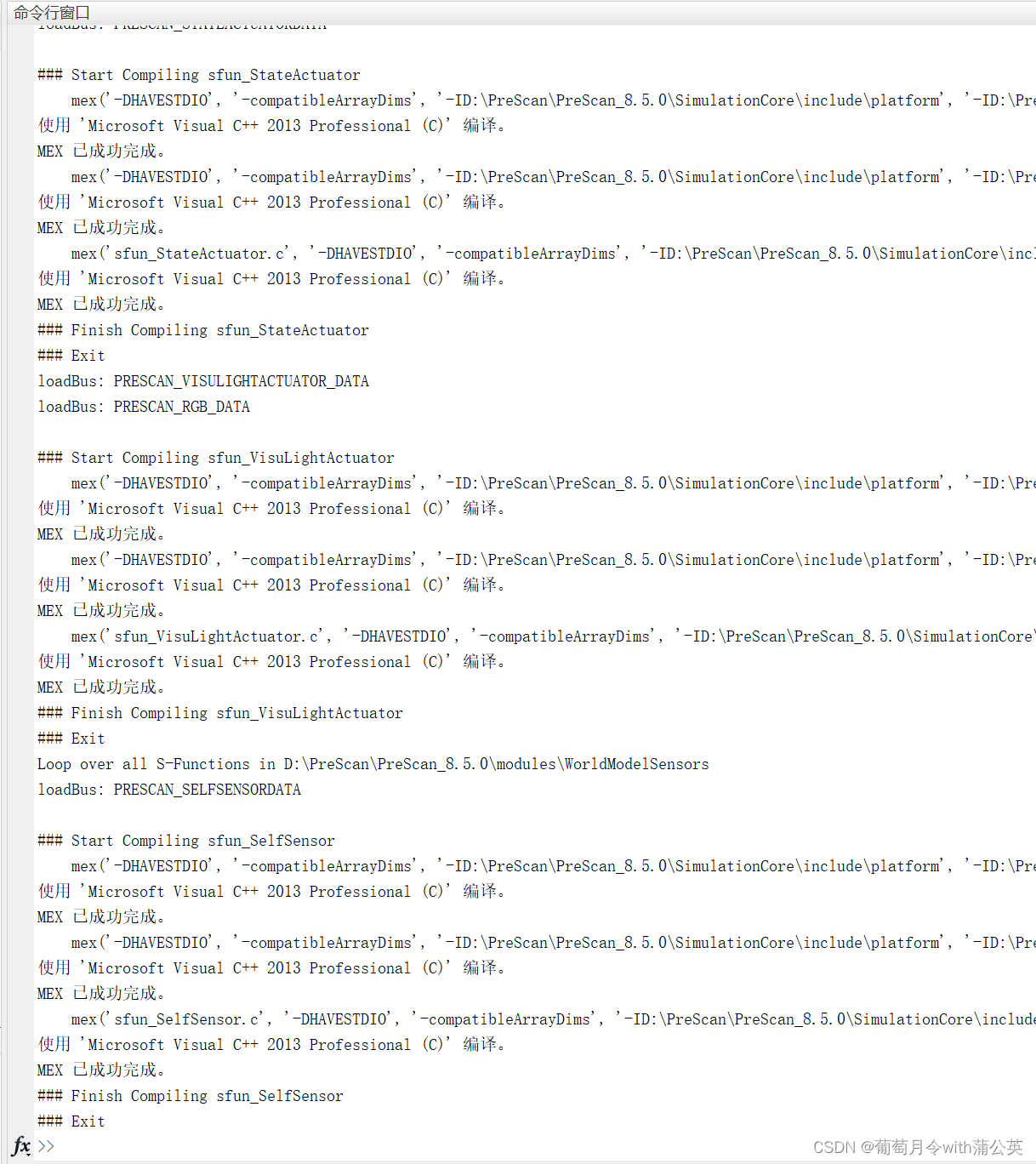
bash ./test/train_full_1p.sh --data_path=/data/path/ # 请根据实际情况更改data_path耗时数据如下图所示。

性能调优
以下调优步骤基于已完成模型向NPU的迁移。
- 模型脚本开头添加库代码。
import torch_npu import torch_npu.optim找到模型脚本main.py中的优化器定义代码,将原始优化器替换为对应的NPU亲和融合优化器。样例代码如下。
-
原代码:
optimizer = torch.optim.SGD(model.parameters(), args.lr, momentum=args.momentum, weight_decay=args.weight_decay)修改后代码:
optimizer = torch_npu.optim.NpuFusedSGD(model.parameters(), args.lr, momentum=args.momentum, weight_decay=args.weight_decay)或
optimizer = apex.optimizers.NpuFusedSGD(model.parameters(), args.lr, momentum=args.momentum, weight_decay=args.weight_decay)注意:当前昇腾适配的MobileNetV1模型使用的是apex组件包中的NpuFusedSGD,此处修改为torch_npu.optim.NpuFusedSGD可能会导致精度异常。
- 拉起模型训练,进行profiling,生成json文件。以下命令以单卡训练为例。
bash ./test/train_full_1p.sh --data_path=/data/path/ # 请根据实际情况更改data_path执行训练,对比未设置亲和优化器时的训练数据,每秒处理的图片数提升,性能有一定程度优化。
-
耗时数据如下图所示。

02 动态shape(算子二进制)调优案例
问题背景
有些模型在模型计算的过程中会存在动态shape场景,即在模型计算过程中,模型的输入和输出存在多种shape。这种情况下,由于编译时无法已知全部shape信息,每次调用算子进行计算时都需要进行编译,会增加编译开销和内存使用,降低性能。
总体思路
使用PyTorch Analyse工具的动态shape模式对于模型脚本进行分析,判断是否存在动态shape算子。
- 若不存在可进行其他内容调优。
- 若存在,请安装算子二进制包。PyTorch框架可调用算子二进制包中算子编译信息,可设置模型编译时是否优先在线编译,以此解决动态shape问题、优化模型训练性能。
环境准备
- 点击获取链接,获取Yolov5模型,并根据readme准备训练环境和数据集。
- 参考CANN软件安装指南中“常用操作 > 安装、升级和卸载二进制算子包”章节,安装算子二进制包。
瓶颈识别
使用PyTorch Analyse工具的动态shape模式对于模型脚本进行分析,生成动态shape的分析报告msft_dynamic_shape_analysis_report.csv。
- 进入分析工具所在路径。
cd Ascend-cann-toolkit安装目录/ascend-toolkit/latest/tools/ms_fmk_transplt/执行分析。
-
./pytorch_analyse.sh -i 待分析脚本路径 -o 分析结果输出路径 -v 待分析脚本框架版本 -m dynamic_shape命令中的参数说明如下表所示。
参数
参数说明
取值示例
-i
--input
- 待分析脚本文件或三方库套件源码所在文件夹路径。
- 必选。
/home/xxx/analysis
-o
--output
- 分析结果文件输出路径。
- 会在该路径下生成xxxx_analysis文件夹。
- 必选。
/home/xxx/analysis_output
-v
--version
- 待分析脚本或三方库套件源码的PyTorch版本。目前支持1.8.1、1.11.0、2.0.1、2.1.0。
- 必选。
- 1.8.1
- 1.11.0
- 2.0.1
- 2.1.0
-m
--mode
- 分析的模式。目前支持torch_apis(算子支持情况分析)、third_party(三方库套件分析)、affinity_apis(亲和API分析)和dynamic_shape(动态shape分析)模式。
- 可选。
- torch_apis(默认)
- third_party
- affinity_apis
- dynamic_shape
-env
--env-path
- 分析时需要增加的PYTHONPATH环境变量路径,仅安装jedi后该参数才生效。
- 可选。
/home/xxx/transformers/src /home/xxx/transformers/utils
多个文件路径使用空格隔开。
-api
--api-files
- 三方库不支持API的分析结果文件。
- 可选。
/home/xxx/mmcv_analysis/full_unsupported_results.csv /home/xxx/transformers_analysis/full_unsupported_results.csv
多个文件路径使用空格隔开。
-h
--help
显示帮助信息。
-
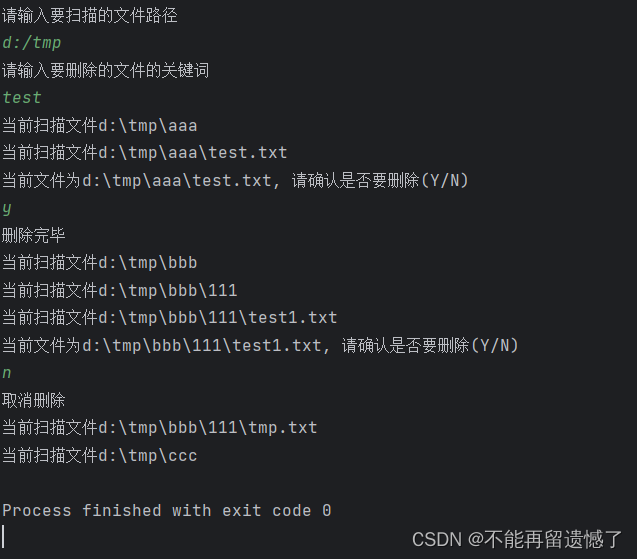
- 完成分析后,在分析结果输出路径下会生成一个完整的模型脚本文件夹,其中模型脚本代码都做了自动修改。在分析结果输出路径下,修改训练脚本文件中读取训练数据集的for循环,手动开启动态shape检测,请参考下方示例进行修改。
修改前:
for i, (ings, targets, paths, _) in pbar:修改后:
for i, (ings, targets, paths, _) in DETECTOR.start(pbar):在分析结果输出路径下,拉起修改过的训练脚本,运行一个epoch即可。完成后会在路径下生成动态shape的分析报告msft_dynamic_shape_analysis_report.csv。其中存储了函数名称、调用栈、所在文件、文件行号、输入和输出的shape范围,如下图样例所示。
-
样例动态shape分析报告如下:

性能调优
在代码中使能算子二进制即可完成性能调优。
1、打开训练脚本。
vi train.py2、在主函数中添加使能算子二进制的代码。
if __name__ == '__main__':
torch_npu.npu.set_compile_mode(jit_compile=False)
main()3、拉起训练。对比使能算子二进制前后的step训练耗时,发现性能数据获得提升即说明调优成功。如下图所示,未开启算子二进制时一个step训练总耗时(mTime)约为1.4s,开启后一个step训练总耗时(mTime)约为1.2s。
未开启算子二进制:

开启算子二进制:




![[小林coding]4.1TCP三次握手四次挥手笔记_1012](https://img-blog.csdnimg.cn/5bcbeaef2f7041a4b3928bc713f95dd8.png)



![2023年全球及中国光伏硅片行业产量、市场竞争格局及趋势分析[图]](https://img-blog.csdnimg.cn/img_convert/4e0c65914f143890ce35f0e62689848d.png)