1. 动态范围的常用计算方法
Max方法
之前的对称量化和非对称量化就是在用最大最小的办法做的
Histgram

直方图是一种用于可视化信号或数据分布的图形工具。计算动态范围的一种方法是通过查看直方图的范围。动态范围可以由直方图中的最高峰值和最低峰值之间的差异来估算。
Entropy
熵是一个信号的统计度量,用于衡量信号的不确定性或信息量。较高的熵表示信号具有更大的动态范围,因为它包含更多的信息。熵的计算可以通过对信号的分布进行统计来实现,通常使用信息论中的熵公式来计算。
2. 饱和量化和非饱和量化

Histgram 和 Entropy可以比较好的解决非饱和量化的误差
3. 直方图复现

下面这段代码返回的是我把x, 一个array, 分成了100分,hist是这100份的频率, bins是这100的区间的边界,因为第一个的右边界又是第二个hist的左边界,所以shape是101
hist, bins = np.histogram(x, 100)
print(hist.shape)
print(bins.shape)
(100,)
(101,)
import numpy as np
# 缩放
def scale_cal(x):
max_val = np.max(np.abs(x))
return max_val / 127
def histogram_bins(x):
hist, bins = np.histogram(x, 100)
print(hist)
print(bins)
total = len(x)
left = 0
right = len(hist) - 1
limit = 0.99
while True:
cover_percent = hist[left:right+1].sum() / total
if cover_percent <= limit:
break
if hist[left] < hist[right]:
left += 1
else:
right -= 1
left_val = bins[left]
right_val = bins[right]
dynamic_range = max(abs(left_val), abs(right_val))
return dynamic_range / 127.
if __name__ == '__main__':
np.random.seed(1)
data_float32 = np.random.randn(1000).astype('float32')
scale = scale_cal(data_float32)
scale1 = histogram_bins(data_float32)
print(f"scale: {scale}")
print(f"Histragram scale: {scale1}")
4. Entropy的方法
KL散度,也称为相对熵,是概率论和信息论中用于描述两个概率分布P和Q之间差异的一种方法。它通常用于衡量两个分布之间的相似性或差异性。
KL散度的计算公式如下:
D_KL(P || Q) = ∑(i) [P(x_i) * log(P(x_i) / Q(x_i))]
其中,P和Q是两个概率分布,x_i表示分布中的元素。
计算KL散度的一般流程
-
统计直方图分布:首先,需要获得数据,并将其分成不同的区间,构建直方图分布。每个区间包含一定范围的数值,并统计每个区间内的数据点数量。
-
生成p分布:生成一个概率分布P,其中概率值取自直方图中各区间的频次。这样,P代表了数据的实际分布。
-
计算q分布:生成另一个概率分布Q,Q可以是某种参考分布或期望分布,用于与实际数据分布P进行比较。
-
归一化p和q分布:确保概率分布P和Q的概率总和均为1,以使它们在相同的尺度上进行比较。
-
计算p和q的KL散度:使用KL散度公式,逐个元素比较概率分布P和Q,计算它们之间的差异。最后,对所有元素的差异进行求和,得到KL散度的值。KL散度越大,表示P和Q之间的差异越大;KL散度越小,表示它们越相似。
这个过程展示了如何使用KL散度来度量两个概率分布之间的差异,通常在信息论、机器学习和统计学等领域用于分析数据分布的相似性或不同之处。通过将数据划分成不同区间,并比较实际分布P与参考分布Q之间的KL散度,我们可以更好地了解数据的特性和分布情况。
案例
-
统计直方图分布:首先,你有一个输入序列**[1, 0, 2, 3, 5, 3, 1, 7]**,并将其合并成四个区间的直方图分布,每个区间包含一定范围的数值。
-
生成p分布:生成一个概率分布P,该分布以直方图中各区间的频次作为概率值,即[1, 5, 8, 8]。
-
计算q分布:生成另一个概率分布Q,这可能是一个参考分布或期望分布。
-
归一化p和q分布:将概率分布P和Q进行归一化,确保它们的概率总和为1。
-
计算p和q的KL散度:使用KL散度公式计算概率分布P和Q之间的差异。KL散度的计算会涉及每个区间的概率值之间的比较和差异。
这个案例旨在展示如何使用KL散度来度量两个概率分布之间的差异,通常在信息论、机器学习和统计学中用于比较两个分布的相似性或差异性。KL散度越大,两个分布之间的差异越大,而KL散度越小,它们越相似。在这个案例中,你从输入数据开始,经过一系列步骤,最终计算出了P和Q之间的KL散度,以量化它们之间的差异。
5. PTQ and QAT流程
TensorRT 7.x之前只支持PTQ量化,
隐性量化: PTQ, 速度优先,这一层如果fp16快就是fp16. int8快就量化成int8
显性量化: 带QDQ的PTQ和QAT, 可以更好的控制精度,可以控制好每一层的精度

这张图简明地描绘了PTQ(Post-Training Quantization,后训练量化)和QAT(Quantization Aware Training,量化感知训练)的流程。以下是对这两种方法的解释:
-
PTQ (Post-Training Quantization):
- Calibration data: 在进行量化之前,需要先使用一组标定数据来确定量化参数。
- Pre-trained model: 开始时,你有一个已经训练好的模型。
- Gather layer statistics: 通过标定数据在模型上进行前向传播,收集每一层的数据统计信息。这些统计数据用于确定量化参数,以便尽量减少量化带来的精度损失。
- Compute q-params: 基于上一步收集的统计数据,计算每一层的量化参数。
- Quantize model: 使用上一步计算的量化参数来量化模型。量化后的模型将使用较小的数据类型(如int8),这可以降低模型大小和推理时间,但可能会损失一些精度。
-
QAT (Quantization Aware Training):
- Pre-trained model: 与PTQ类似,你从一个已经训练好的模型开始。
- Add QDQ nodes: 在模型的各层之间添加量化节点(Quantize)和反量化节点(Dequantize),使模型在训练过程中能够感知到量化带来的效果。
- Fine-tune with QDQ nodes: 对带有QDQ节点的模型进行微调,这样在训练过程中,模型就可以考虑到量化引起的误差,并相应地调整参数。
- Store q-params: 在微调过程中,保存量化参数,这些参数将用于量化模型。
- Quantize model: 最后,使用保存的量化参数来量化模型。
6. QAT核心思想
核心思想是适应误差,增加训练的时长, 这里的FQ 是把fp32转成int8再转成fp32传递过去,这个过程中也把量化的误差传递下去,通过训练让模型适应误差
更清晰的图

7. 用API自动导出带QDQ节点的onnx
针对输入的Tensor是共用一个scale, 针对权重用的是per_Channel或者Per_Layer的一个Scale, 先看下自动导出QDQ节点的onnx
import torch
import torchvision
from pytorch_quantization import tensor_quant, quant_modules
from pytorch_quantization import nn as quant_nn
quant_modules.initialize()
model = torchvision.models.resnet50()
model.cuda()
inputs = torch.randn(1, 3, 224, 224, device="cuda")
quant_nn.TensorQuantizer.use_fb_fake_quant = True # 这个设置为True才能正确的导出
torch.onnx.export(model, inputs, "quant_resnet50_1.onnx", opset_version=13)

8. 手动添加QDQ节点
假设我第一个conv不想用自动插入QDQ, 代码如下, 这里的逻辑就是在两个类中传入的参数是模型的第一个conv1, 然后去遍历这两个节点的全部模块,如果是量化的就给他关了或者打开,通过下面代码是先关掉第一个conv的量化再打开第一个conv的量化。
这里面通过判断出模块是否属于quant_nn.TensorQuantizer来决定是否给他关掉或打开
import torch
import torchvision
from pytorch_quantization import tensor_quant
from pytorch_quantization import quant_modules
from pytorch_quantization import nn as quant_nn
from pytorch_quantization.nn.modules import _utils as quant_nn_utils
from pytorch_quantization import calib
from typing import List, Callable, Union, Dict
class disable_quantization:
def __init__(self, model):
self.model = model
def apply(self, disabled=True):
for name, module in self.model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
module._disabled = disabled
def __enter__(self):
self.apply(True)
def __exit__(self, *args, **kwargs):
self.apply(False)
class enable_quantization:
def __init__(self, model):
self.model = model
def apply(self, enabled=True):
for name, module in self.model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
module._disabled = not enabled
def __enter__(self):
self.apply(True)
return self
def __exit__(self, *args, **kwargs):
self.apply(False)
quant_modules.initialize() # 对整个模型进行量化
model = torchvision.models.resnet50()
model.cuda()
disable_quantization(model.conv1).apply() # 关闭某个节点的量化
# enable_quantization(model.conv1).apply() # 开启某个节点的量化
inputs = torch.randn(1, 3, 224, 224, device='cuda')
quant_nn.TensorQuantizer.use_fb_fake_quant = True
torch.onnx.export(model, inputs, 'quant_resnet50_disabelconv1.onnx', opset_version=13)
9. 更加灵活的一种写法
这种是遍历每一个层然后用量化的层替代,这种好处就是可以灵活写很多的过滤条件
def transfer_torch_to_quantization(nninstance : torch.nn.Module, quantmodule):
quant_instance = quantmodule.__new__(quantmodule)
for k, val in vars(nninstance).items():
setattr(quant_instance, k, val)
def __init__(self):
if isinstance(self, quant_nn_utils.QuantInputMixin):
quant_desc_input = quant_nn_utils.pop_quant_desc_in_kwargs(self.__class__,input_only=True)
self.init_quantizer(quant_desc_input)
# Turn on torch_hist to enable higher calibration speeds
if isinstance(self._input_quantizer._calibrator, calib.HistogramCalibrator):
self._input_quantizer._calibrator._torch_hist = True
else:
quant_desc_input, quant_desc_weight = quant_nn_utils.pop_quant_desc_in_kwargs(self.__class__)
self.init_quantizer(quant_desc_input, quant_desc_weight)
# Turn on torch_hist to enable higher calibration speeds
if isinstance(self._input_quantizer._calibrator, calib.HistogramCalibrator):
self._input_quantizer._calibrator._torch_hist = True
self._weight_quantizer._calibrator._torch_hist = True
__init__(quant_instance)
return quant_instance
def replace_to_quantization_module(model : torch.nn.Module, ignore_policy : Union[str, List[str], Callable] = None):
module_dict = {}
for entry in quant_modules._DEFAULT_QUANT_MAP:
module = getattr(entry.orig_mod, entry.mod_name)
module_dict[id(module)] = entry.replace_mod
def recursive_and_replace_module(module, prefix=""):
for name in module._modules:
submodule = module._modules[name]
path = name if prefix == "" else prefix + "." + name
recursive_and_replace_module(submodule, path)
submodule_id = id(type(submodule))
if submodule_id in module_dict:
module._modules[name] = transfer_torch_to_quantization(submodule, module_dict[submodule_id])
recursive_and_replace_module(model)
#quant_modules.initialize()
model = torchvision.models.resnet50()
model.cuda()
disable_quantization(model.conv1).apply()
quantizer_state(model)
replace_to_quantization_module(model)
inputs = torch.randn(1, 3, 224, 224, device='cuda')
quant_nn.TensorQuantizer.use_fb_fake_quant =True
torch.onnx.export(model, inputs, 'quant_resnet50_replace_to_quantization_conv1.onnx',opset_version=13)
10. 对特定层进行自定义方式的量化
下面先定义一个直方图校准的int8量化,然后对输入全部进行量化
import torch
from pytorch_quantization import nn as quant_nn
from pytorch_quantization.tensor_quant import QuantDescriptor
class QuantMultiAdd(torch.nn.Module):
def __init__(self):
super().__init__()
self._input_quantizer = quant_nn.TensorQuantizer(QuantDescriptor(num_bits=8, calib_method="histgoram"))
def forward(self, x, y, z):
return self._input_quantizer(x) + self._input_quantizer(y) + self._input_quantizer(z)
model = QuantMultiAdd()
model.cuda()
input_a = torch.randn(1, 3, 224, 224, device='cuda')
input_b = torch.randn(1, 3, 224, 224, device='cuda')
input_c = torch.randn(1, 3, 224, 224, device='cuda')
quant_nn.TensorQuantizer.use_fb_fake_quant = True
torch.onnx.export(model, (input_a, input_b, input_c), 'quantMultiAdd.onnx', opset_version=13)
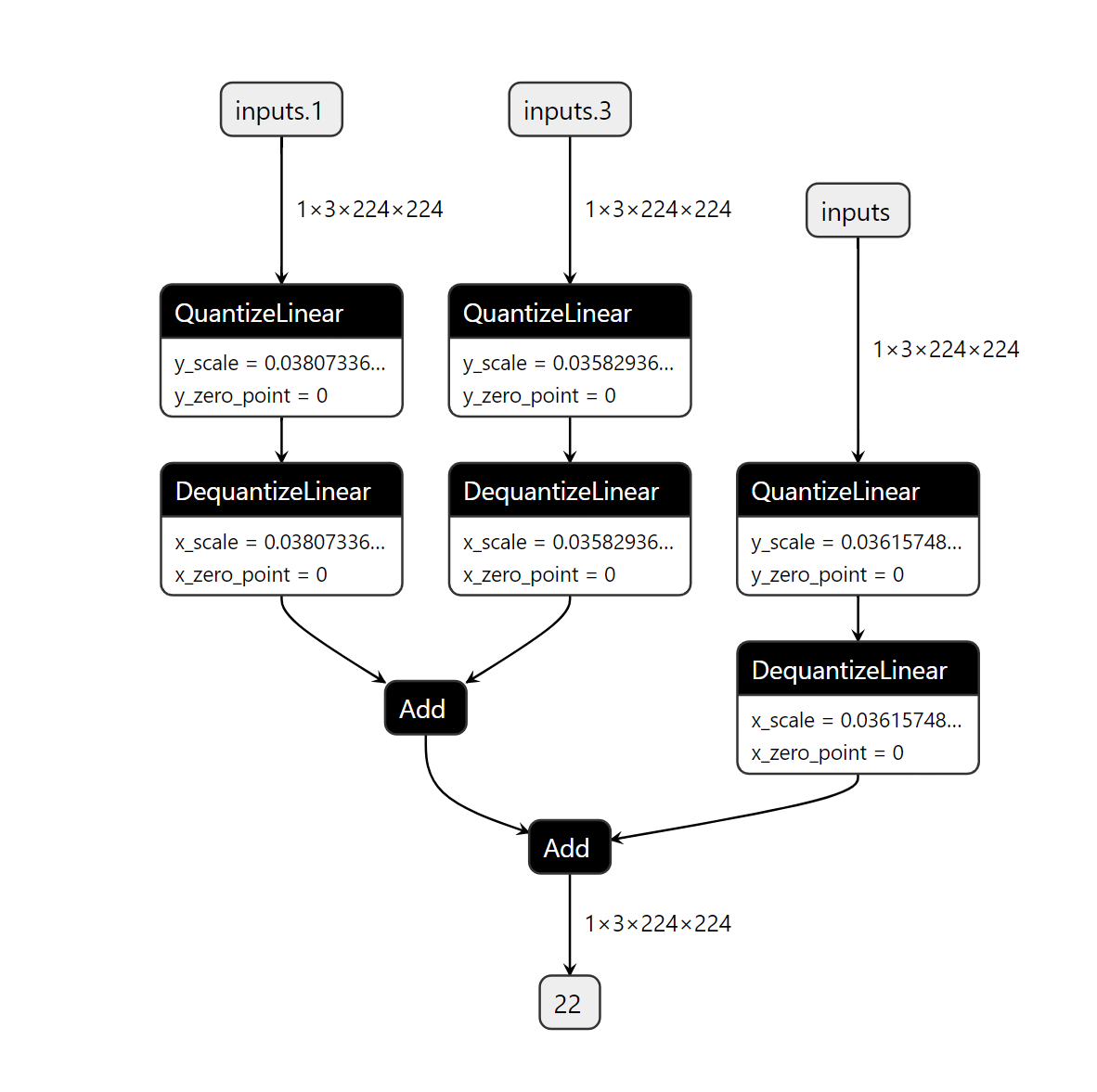
10. 总结流程
- 定义模型
- 对模型插入qdq
- 统计qdq节点的range 和 scale
- 做敏感词分析
- 导出一个qdq节点的ptq
- 对模型进行finetune ----> qat