目录
一、前言
二、Langchain4j概述
2.1 Langchain4j 是什么
2.2 Langchain4j 主要特点
2.3 Langchain4j 核心组件
2.4 Langchain4j 核心优势
三、Langchanin4j组件应用实战
3.1 前置准备
3.1.1 导入如下依赖
3.1.2 获取apikey
3.1.3 获取官方文档
3.2 聊天组件
3.2.1 基本对话
3.2.2 记住上下文对话
3.2.3 流式对话
3.3 文生图
3.4 ChatMemory
3.5 Tools 组件
3.5.1 参考案例代码一
3.5.2 参考案例代码二
3.6 AI Service使用
3.6.1 AiService 介绍
3.6.2 参考案例一
3.6.3 参考案例二
3.5.4 @SystemMessage扩展点
3.6.5 整合整合ChatMemory和Tools
3.7 Embedding组件使用
3.7.1 什么是 Embedding
3.7.1 Embedding案例一
3.7.3 向量数据库
3.7.4 使用向量数据库
3.7.5 使用向量数据库检索
3.8 RAG完整案例
3.8.1 准备一个文档
3.8.2 加载文件到向量数据库
3.8.3 文本检索
3.8.4 结合大模型使用
四、写在文末
一、前言
当下随着各种AI大模型的纷纷登场,AI赋能为业务的拓展和商业价值的延伸带来了无限的可能,于是各大厂商陆续推出对主流AI大模型的接入和支持,方便普通用户或开发者快速体验最新的大模型能力,以DeepSeek为例,像阿里云,硅基流动,腾讯云等多家互联网云厂商,强势接入DeepSeek,让使用者快速尝鲜。与此同时,为了应用开发者能够基于自身的业务快速对接各类AI大模型API能力,更灵活的拓展自身的业务能力。本篇以Langchain4j为例进行说明,详细介绍下Langchain4j的核心技术组件的使用。
二、Langchain4j概述
2.1 Langchain4j 是什么
LangChain4j 是一个基于 Java 的框架,旨在简化与大型语言模型(LLMs)的集成和应用开发。它提供了丰富的工具和组件,帮助开发者快速构建基于 LLM 的应用程序,如聊天机器人、问答系统、文本生成等,官方文档地址:Get Started | LangChain4j
2.2 Langchain4j 主要特点
LangChain4j 主要具备如下特点:
-
模块化设计:
-
LangChain4j 采用模块化架构,允许开发者根据需要选择和使用特定功能,如模型集成、数据加载、链式调用等。
-
-
多模型支持:
-
支持多种 LLM 提供商,如 OpenAI、Hugging Face 等,方便切换和集成不同模型。
-
-
链式调用:
-
提供链式调用功能,允许将多个任务串联,如文本生成后自动进行情感分析。
-
-
数据加载与处理:
-
内置多种数据加载器和处理器,支持从不同来源加载数据并进行预处理。
-
-
扩展性好:
-
提供丰富的 API 和扩展点,开发者可以自定义组件以满足特定需求。
-
-
社区活跃:
-
拥有活跃的社区和详细的文档,便于开发者获取支持和学习。
-
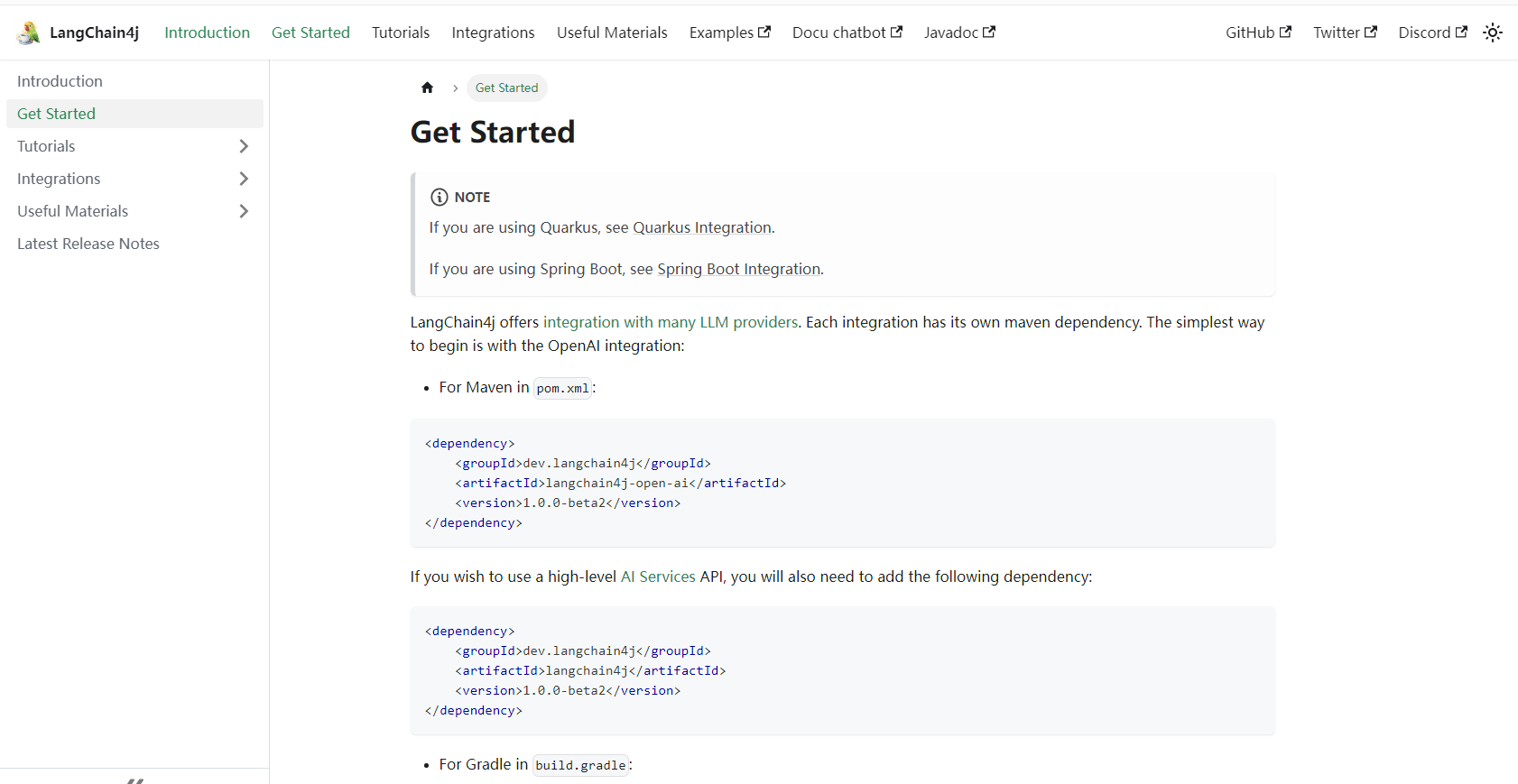
2.3 Langchain4j 核心组件
Langchain4j 的强大之处正是在于其内置了丰富的可以做到开箱即用的组件能力,相比Spring AI,Langchain4j 的组件更加丰富,在使用的时候也更灵活,下面是一张关于Langchain4j 的组件全景图。
2.4 Langchain4j 核心优势
LangChain4j 是一个专为 Java 开发者设计的框架,旨在简化与大型语言模型(LLMs)的集成和应用开发。它的核心优势主要体现在以下几个方面:
Java 原生支持
-
LangChain4j 是专为 Java 生态系统设计的,与 Java 开发工具和框架无缝集成。
-
对于 Java 开发者来说,无需学习其他语言(如 Python)即可使用 LLM 的强大功能。
-
支持 Spring Boot 等主流 Java 框架,便于快速集成到现有项目中。
模块化与灵活性
-
采用模块化设计,开发者可以根据需求选择特定功能,如模型集成、数据加载、链式调用等。
-
提供丰富的扩展点,支持自定义组件和插件,满足个性化需求。
多模型支持
-
支持多种主流 LLM 提供商,如 OpenAI、Hugging Face、Cohere 等。
-
提供统一的 API 接口,方便切换不同模型,降低对单一供应商的依赖。
链式调用(Chains)
-
支持将多个任务串联成链,实现复杂的任务流程。
-
例如,可以将文本生成、情感分析、翻译等任务组合成一个链式调用,简化开发流程。
数据加载与处理
-
内置多种数据加载器,支持从文件、数据库、API 等来源加载数据。
-
提供数据预处理工具,如文本清洗、分词、格式化等,便于后续分析和处理。
高性能与可扩展性
-
针对 Java 的高性能特性进行优化,适合处理大规模数据和复杂任务。
-
支持分布式计算和异步调用,适合高并发场景。
丰富的工具和实用功能
-
提供多种实用工具,如日志记录、配置管理、缓存机制等。
-
内置对 Prompt 工程的支持,帮助开发者更好地设计和优化提示词(Prompts)。
活跃的社区与文档支持
-
拥有活跃的开发者社区,提供及时的技术支持和问题解答。
-
提供详细的文档和示例代码,帮助开发者快速上手。
企业级支持
-
提供对安全性和合规性的支持,适合企业级应用开发。
-
支持模型微调和自定义训练,满足特定业务需求。
跨平台与云原生支持
-
支持在本地、云端或混合环境中部署。
-
与 Kubernetes、Docker 等云原生技术兼容,适合现代微服务架构。
三、Langchanin4j组件应用实战
3.1 前置准备
3.1.1 导入如下依赖
pom文件导入下面的依赖
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<langchain.version>1.0.0-beta1</langchain.version>
</properties>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.4</version>
<relativePath/>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
<version>1.0.0-M3</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.35</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/dashscope-sdk-java -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>dashscope-sdk-java</artifactId>
<!--<version>2.16.9</version>-->
<version>2.18.2</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>${langchain.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>${langchain.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.32</version> <!-- 使用最新版本 -->
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-redis</artifactId>
<version>1.0.0-alpha1</version>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-bom</artifactId>
<version>${langchain.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<build>
<finalName>boot-docker</finalName>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>3.1.2 获取apikey
LangChain4j ,可以理解为一个类似JDBC的底层SDK,支持与多种大模型进行对接使用,本文将使用阿里云百炼平台集成的大模型进行对接,所以,首先你需要在阿里云百炼平台注册一个账户并获取到apikey,百炼平台入口:https://bailian.console.aliyun.com/ ,在模型广场中,该平台对接了很多种主流大模型,只需要在程序中配置对应的模型名称,以及apikey即可;
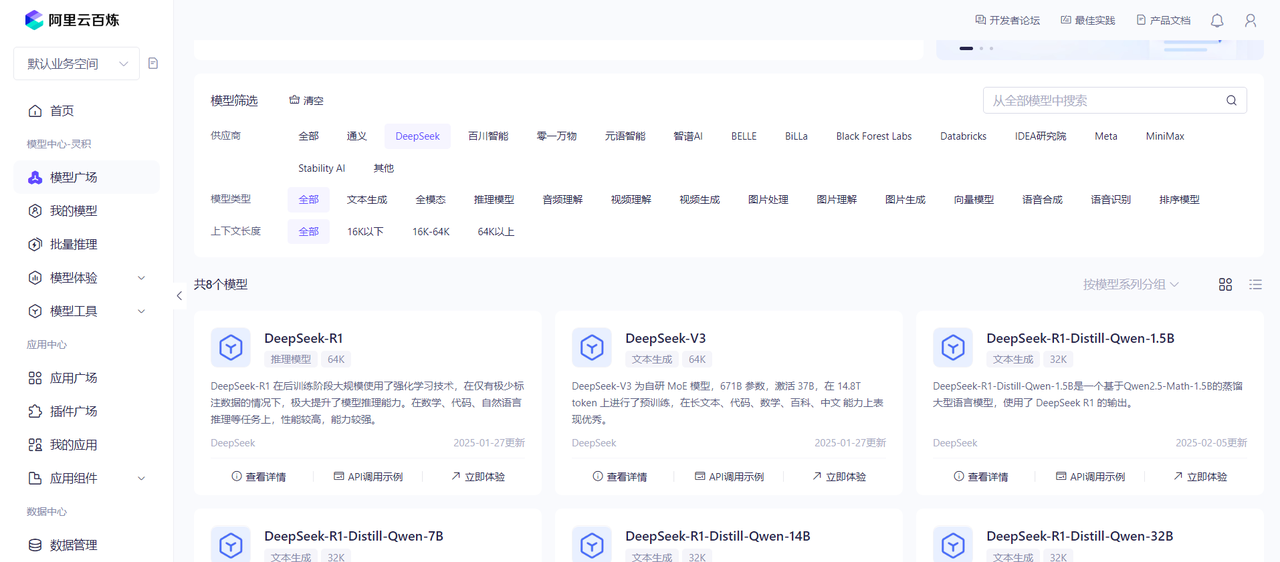
比如下文以deepseek为例进行说明,首先从模型广场找到第一个DeepSeek R1 ,进入之后,找到下面的位置,拷贝模型名称
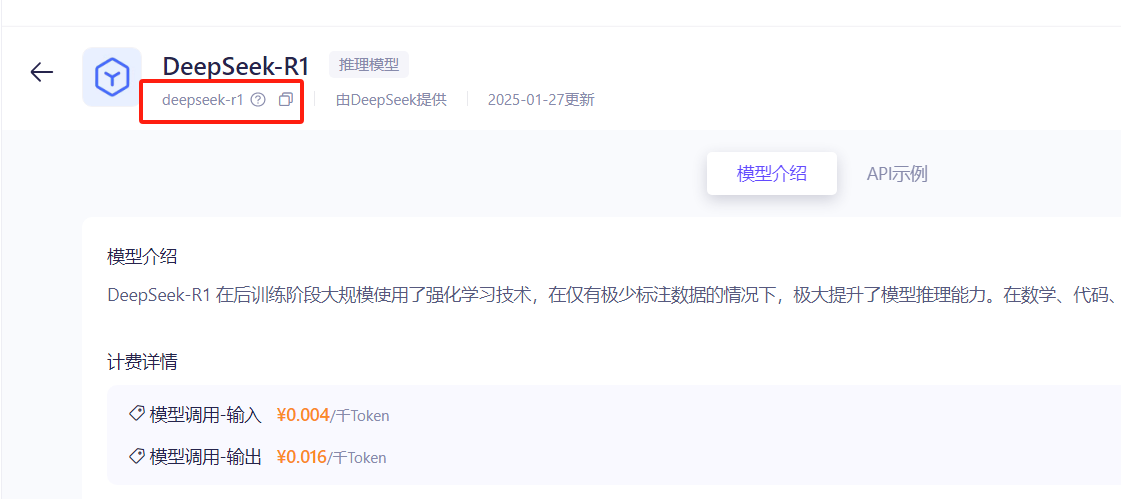
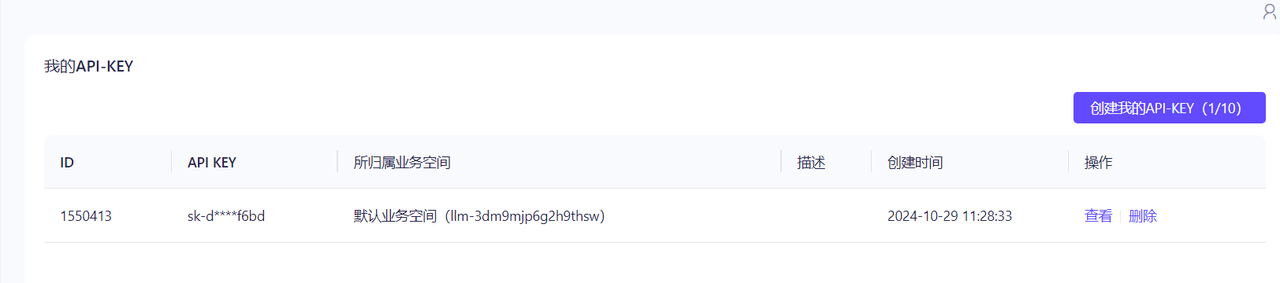
然后,在个人账户那里,查看API-KEY,进去之后创建一个API-KEY即可,每个账户免费可以创建10个API-KEY
3.1.3 获取官方文档
官方文档:LangChain4j | LangChain4j
3.2 聊天组件
3.2.1 基本对话
第一个案例
-
apikey使用自己的;
-
modelName可以选择一个合适的使用;
import dev.langchain4j.community.model.dashscope.QwenChatModel;
import dev.langchain4j.model.chat.ChatLanguageModel;
public class HelloWorld {
public static void main(String[] args) {
ChatLanguageModel model = QwenChatModel.builder()
.apiKey("你的apikey")
.modelName("deepseek-r1")
.build();
String response = model.chat("你好,你是谁");
System.out.println(response);
}
}
3.2.2 记住上下文对话
为了让大模型记住上下文对话,可以通过编码的方式,如下:
public static void main(String[] args) {
ChatLanguageModel model = QwenChatModel.builder()
.apiKey("你的apikey")
.modelName("deepseek-r1")
.build();
UserMessage userMessage = UserMessage.from("你好,你是谁");
ChatResponse response = model.chat(userMessage);
AiMessage aiMessage = response.aiMessage();
System.out.println(aiMessage.text());
UserMessage userMessage2 = UserMessage.from("请重复一次");
ChatResponse chatResponse = model.chat(userMessage, aiMessage, userMessage2);
System.out.println(chatResponse.aiMessage().text());
}运行之后,通过下面的效果可以看出,大模型记住了上一次的对话内容

不同类型的message
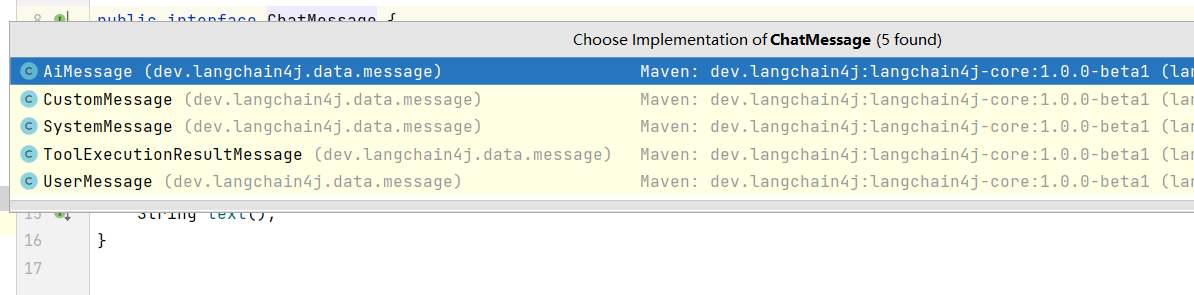
通过源码可以看到,ChatMessage是一个接口,当前的SDK内置了5种实现,每一种都有特定的使用场景:
- UserMessage:这是来自用户的消息。包含文本,但某些LLM也支持文本和图像的混合。
- AiMessage:这是由 AI 生成的消息,响应 UserMessage。generate 方法返回包装在 Response 中的 AiMessage。AiMessage 可以包含文本响应 (String) 或执行工具的请求 (ToolExecutionRequest);
- ToolExecutionResultMessage:ToolExecutionRequest 的结果。
- SystemMessage:定义AI的系统角色信息。
3.2.3 流式对话
流式对话可以模拟在AI大模型的聊天界面输入问题之后,大模型给出的那种带有思考过程的间歇性的输出效果,参考下面的代码
import dev.langchain4j.community.model.dashscope.QwenStreamingChatModel;
import dev.langchain4j.model.chat.StreamingChatLanguageModel;
import dev.langchain4j.model.chat.response.ChatResponse;
import dev.langchain4j.model.chat.response.StreamingChatResponseHandler;
import java.util.concurrent.TimeUnit;
public class StreamDemo {
public static void main(String[] args) {
StreamingChatLanguageModel model = QwenStreamingChatModel.builder()
.apiKey("你的apikey")
.modelName("deepseek-r1")
.build();
model.chat("你好,你是谁?", new StreamingChatResponseHandler() {
@Override
public void onPartialResponse(String token) {
System.out.println(token);
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
@Override
public void onCompleteResponse(ChatResponse chatResponse) {
System.out.println(chatResponse.aiMessage().text());
}
@Override
public void onError(Throwable throwable) {
System.out.println("出错了");
}
});
}
}运行一下可以看到下面的效果
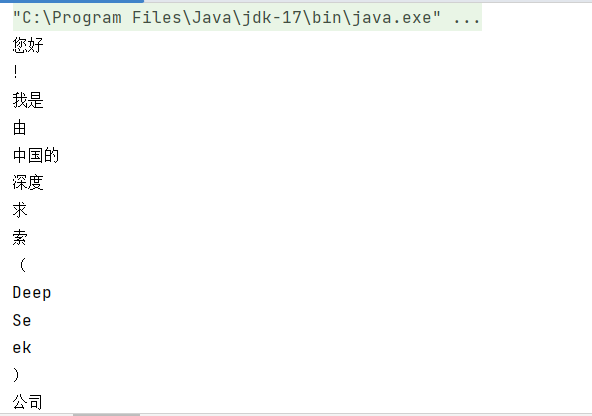
3.3 文生图
选择一个可以文生图的模型
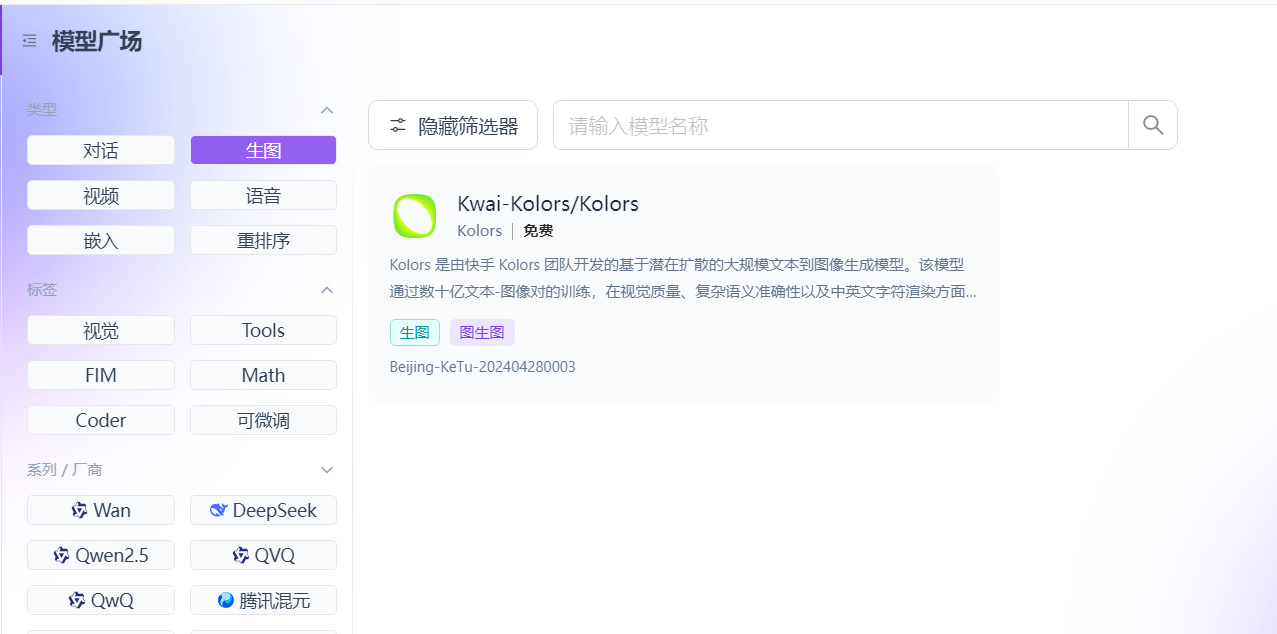
参考下面的代码
import dev.langchain4j.data.image.Image;
import dev.langchain4j.model.image.ImageModel;
import dev.langchain4j.model.openai.OpenAiImageModel;
import dev.langchain4j.model.output.Response;
public class ImageModelTest {
public static void main(String[] args) {
ImageModel model = OpenAiImageModel.builder()
.apiKey("sk-你的apikey")
.modelName("Kwai-Kolors/Kolors")
.build();
Response<Image> response = model.generate("生成一张萌猫的图片");
System.out.println(response.content().url());
}
}3.4 ChatMemory
使用ChatMemory可以帮助记住上下文的对话,默认提供了下面两种类型的实现方式,基于内存的和基于token的
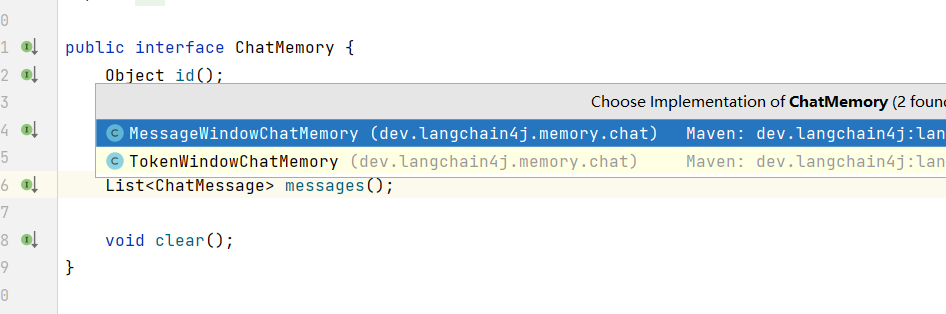
参考下面的案例代码
import dev.langchain4j.community.model.dashscope.QwenChatModel;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.memory.ChatMemory;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.chat.ChatLanguageModel;
public class ChatMemoryTest {
public static void main(String[] args) {
ChatLanguageModel model = QwenChatModel.builder()
.apiKey("你的apikey")
.modelName("deepseek-r1")
.build();
ChatMemory chatMemory = MessageWindowChatMemory.builder()
.maxMessages(10)
.build();
//消息存储到 chatMemory
chatMemory.add(UserMessage.from("你好,我是小明,你是我的好兄弟,你叫小强"));
String text1 = model.chat(chatMemory.messages()).aiMessage().text();
System.out.println(text1);
chatMemory.add(UserMessage.from("小明最好的朋友是谁"));
String text2 = model.chat(chatMemory.messages()).aiMessage().text();
System.out.println(text2);
}
}通过上面的方式,就可以记住上下文的对话

3.5 Tools 组件
Tools机制可以允许将⼀个本地⽅法封装成⼀个⼯具集,也就是ToolSpecification。
-
当前版本创建⼯具集有两种⽅式,⼀种是通过⼀个Method⽅法来定制⼯具集,另⼀种⽅式是通过⼀个Class类来
-
定制⼯具集。 使⽤这两中⽅式都需要⽤到⼀个@Tools注解。例如,我们先定义⼀个⽅法,获取当前⽇期
3.5.1 参考案例代码一
在下面的代码中,自定义了一个工具,用于获取当前的时间
package com.congge.chat;
import dev.langchain4j.agent.tool.Tool;
import dev.langchain4j.agent.tool.ToolExecutionRequest;
import dev.langchain4j.agent.tool.ToolSpecification;
import dev.langchain4j.agent.tool.ToolSpecifications;
import dev.langchain4j.community.model.dashscope.QwenChatModel;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.data.message.ToolExecutionResultMessage;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.output.Response;
import org.apache.commons.compress.utils.Lists;
import java.time.LocalDateTime;
import java.util.Arrays;
public class ToolDemo1 {
@Tool("获取当前日期")
public static String dateUtil(){
return LocalDateTime.now().toString();
}
public static void main(String[] args) throws Exception{
ChatLanguageModel model = QwenChatModel.builder()
.apiKey("你的apikey")
.modelName("qwen-max")
.build();
ToolSpecification toolSpecification = ToolSpecifications
.toolSpecificationFrom(ToolDemo1.class.getMethod("dateUtil"));
UserMessage userMessage = UserMessage.from("今天是几月几号");
Response<AiMessage> aiMessageResponse = model.generate(Arrays.asList(userMessage), Arrays.asList(toolSpecification));
AiMessage aiMessage = aiMessageResponse.content();
if(aiMessage.hasToolExecutionRequests()){
for(ToolExecutionRequest toolExecutionRequest : aiMessage.toolExecutionRequests()){
String name = toolExecutionRequest.name();
Object result = ToolDemo1.class.getMethod(name).invoke(null);
System.out.println(result);
ToolExecutionResultMessage resultMessage = ToolExecutionResultMessage.from(toolExecutionRequest.id(), name, result.toString());
Response<AiMessage> response = model.generate(Arrays.asList(userMessage, aiMessage, resultMessage));
System.out.println(response.content().text());
}
}
}
}运行一下,可以看到下面的效果,这样就结合大模型完成了一个获取当前系统时间的功能

3.5.2 参考案例代码二
在上一个案例中,指定了Tool所在工具类的某个具体方法交给大模型执行得到期望的结果,有时候,也可以直接在一个类中指定多个这样的方法,同时,为了更灵活的使用方法,还可以为具体的工具方法指定参数,从而完成特定场景下的任务,参考下面的案例
package com.congge.chat;
import dev.langchain4j.agent.tool.*;
import dev.langchain4j.community.model.dashscope.QwenChatModel;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.data.message.ToolExecutionResultMessage;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.service.tool.DefaultToolExecutor;
import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.UUID;
public class ToolDemo2 {
static class WeatherUtil {
@Tool("获取某一个具体城市的天气")
public static String getWeather(@P("指定的城市") String city) {
return "今天[ " + city + " ]天气晴朗";
}
}
public static void main(String[] args) throws Exception {
ChatLanguageModel model = QwenChatModel.builder()
.apiKey("你的apikey")
.modelName("qwen-max")
.build();
//构建工具集合,通过类构建
List<ToolSpecification> toolSpecifications = ToolSpecifications.toolSpecificationsFrom(WeatherUtil.class);
List<ChatMessage> chatMessages = new ArrayList<>();
UserMessage userMessage = UserMessage.from("北京市今天的天气怎么样");
chatMessages.add(userMessage);
//第一次与AI大模型交互时,获得需要调用的工具类
Response<AiMessage> aiMessageResponse = model.generate(chatMessages, toolSpecifications);
AiMessage aiMessage = aiMessageResponse.content();
List<ToolExecutionRequest> toolExecutionRequests = aiMessage.toolExecutionRequests();
//本地执行工具方法
if (aiMessage.hasToolExecutionRequests()) {
for (ToolExecutionRequest toolExecutionRequest : toolExecutionRequests) {
String name = toolExecutionRequest.name();
String arguments = toolExecutionRequest.arguments();
System.out.println("调用的方法:" + name);
System.out.println("方法参数:" + arguments);
}
}
chatMessages.add(aiMessage);
WeatherUtil weatherUtil = new WeatherUtil();
//将工具调用的方法与聊天消息一起传给AI大模型
toolExecutionRequests.forEach(toolExecutionRequest -> {
DefaultToolExecutor toolExecutor = new DefaultToolExecutor(weatherUtil,
toolExecutionRequest);
String result = toolExecutor.execute(toolExecutionRequest,
UUID.randomUUID().toString());
System.out.println("⼯具执⾏结果" + result);
ToolExecutionResultMessage toolResultMessage =
ToolExecutionResultMessage.from(toolExecutionRequest, result);
chatMessages.add(toolResultMessage);
});
//4、调⽤⼤模型,⽣成最终结果
AiMessage finalResponse = model.generate(chatMessages).content();
System.out.println("最终结果:" + finalResponse.text());
}
}运行上面的代码,通过控制台结果输出刻意看到,能够正确解析到我们输入的问题中城市信息,如果是真实的场景下,AI大模型即可获取到指定城市的天气信息

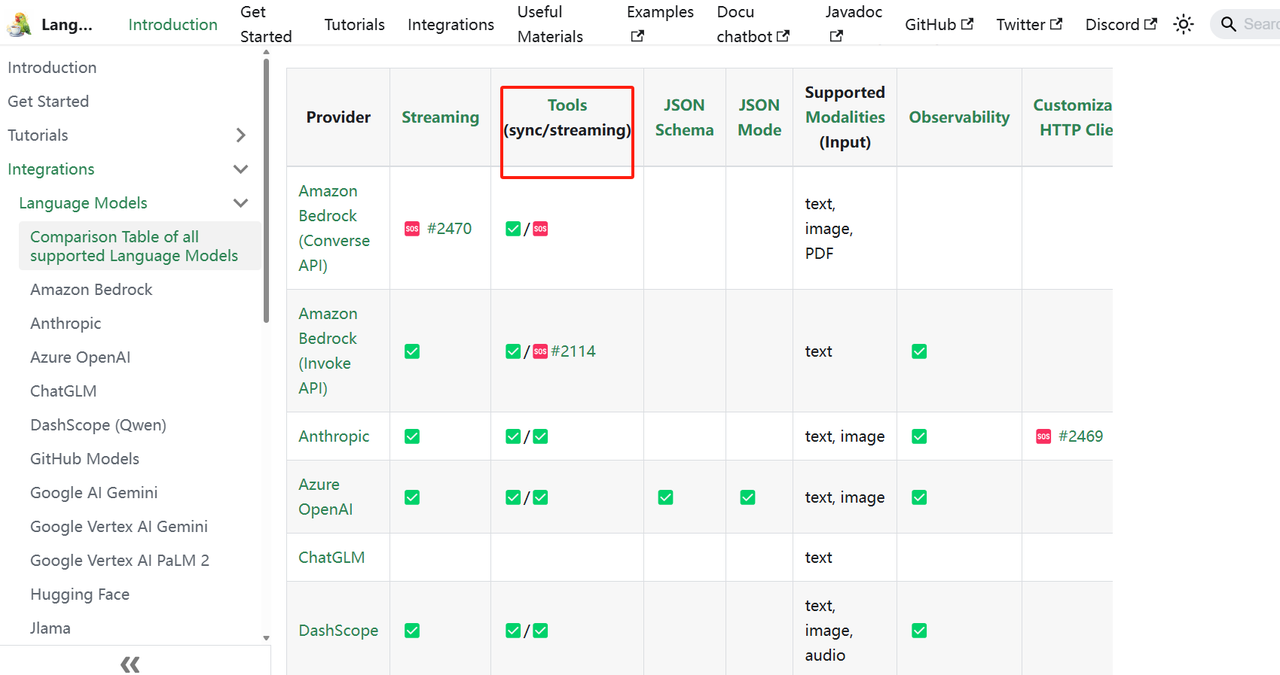
关于Tools的深入使用,可以结合官方文档进行更深入的了解:Comparison Table of all supported Language Models | LangChain4j,并非所有的大模型都支持Tools的使用,可以结合文档中的Tools一栏进行查看
3.6 AI Service使用
到这⾥,我们已经接触到了很多与⼤模型交互的基础组件,包括 ChatLanguageModel,ChatMessage ,ChatMemory等等。你会发现,每次与⼤模型的⾼效交互都需要依靠这些组件精⼼配合。但是要熟记这么多模型,还是⽐较麻烦的。有没有⼀个⽐较统⼀的上层⼯具能够把这些组件整合起来,简化实现过程呢?LangChain4j中就提供了这个⾮常重要的AiServices。官方文档:AI Services | LangChain4j
3.6.1 AiService 介绍
AiService 是 LangChain4j 中的一个核心组件,用于将 AI 模型(如 OpenAI、Hugging Face 等)的能力封装为服务接口,方便开发者调用。通过 AiService,开发者可以轻松地将 AI 模型集成到应用程序中,而无需直接处理复杂的模型调用和数据处理逻辑。
1)主要功能
-
模型调用封装:
AiService将 AI 模型的调用逻辑封装为简单的 Java 接口,开发者只需定义接口方法即可调用模型。 -
自动请求/响应处理:
AiService会自动处理输入数据的预处理和输出数据的后处理,简化开发流程。 -
多模型支持:支持多种 AI 模型(如 GPT、BERT 等),并可以根据需要切换模型。
-
异步调用:支持异步调用 AI 模型,提升应用程序的性能和响应速度。
2)使用步骤
-
定义服务接口:创建一个 Java 接口,定义需要调用的 AI 模型功能。
-
配置模型:在配置文件中指定使用的 AI 模型及其参数。
-
创建服务实例:通过
AiService创建服务实例。 -
调用服务:通过服务实例调用定义的方法,获取 AI 模型的输出。
通过 AiService,开发者可以更高效地将 AI 能力集成到 Java 应用程序中,降低开发复杂度,提升开发效率。
3.6.2 参考案例一
在下面的案例中,首先定义一个带有问题参数的方法接口,然后直接使用AiService的create方法即可获得接口方法的示例,使用这个示例进行执行即可,可以大大减少像上面那样的API编写的复杂程度
package com.congge.chat;
import dev.langchain4j.community.model.dashscope.QwenChatModel;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.service.AiServices;
public class AiServiceDemo {
interface AiWriter {
String write(String message);
}
public static void main(String[] args) {
ChatLanguageModel model = QwenChatModel.builder()
.apiKey("你的apikey")
.modelName("qwen-max")
.build();
AiWriter writer = AiServices.create(AiWriter.class, model);
String response = writer.write("谁是这个世界上对你最重要的人");
System.out.println(response);
}
}运行上面的代码,可以看到下面的效果

3.6.3 参考案例二
还记得在之前分享 【微服务】SpringBoot整合LangChain4j 操作AI大模型实战详解-CSDN博客中提到,ChatMessage 有多种类型的实现,如下是ChatMessage 的5个内置实现:
- UserMessage:这是来自用户的消息。包含文本,但某些LLM也支持文本和图像的混合;
- AiMessage:这是由 AI 生成的消息,响应 UserMessage。generate 方法返回包装在 Response 中的 AiMessage。AiMessage 可以包含文本响应 (String) 或执行工具的请求 (ToolExecutionRequest)。
- ToolExecutionResultMessage:ToolExecutionRequest 的结果。
- SystemMessage:定义AI的系统角色信息。
以SystemMessage为例,基于上面的案例,可以为接口中的方法添加一个SystemMessage的注解,然后指定一段描述,有点类似于身份或角色扮演的效果,参考下面的完整代码
package com.congge.chat;
import dev.langchain4j.community.model.dashscope.QwenChatModel;
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.SystemMessage;
public class AiServiceDemo {
interface AiWriter {
@SystemMessage("你是一个知名的散文作家,根据输入的题目写一篇不超过200字的散文")
String write(String message);
}
public static void main(String[] args) {
ChatLanguageModel model = QwenChatModel.builder()
.apiKey("你的apikey")
.modelName("qwen-max")
.build();
AiWriter writer = AiServices.create(AiWriter.class, model);
String response = writer.write("谁是这个世界上对你最重要的人");
System.out.println(response);
}
}再次运行,通过输出结果不难看出本次给出的回答,就按照要求写出了一篇散文

3.5.4 @SystemMessage扩展点
为了让@SystemMessage注解修饰的方法具备更好的扩展性,比如在实际使用中,为了将这个write方法以更灵活的模板方式进行封装,可以通过传入更多的参数,然后以参数的形式传递到模板描述中,如下:
package com.congge.chat;
import dev.langchain4j.community.model.dashscope.QwenChatModel;
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
import dev.langchain4j.service.V;
public class AiServiceDemo {
interface AiWriter {
@SystemMessage("你是一个知名的散文作家,根据输入的{{title}},写一篇不超过{{count}}字的散文")
String write(@UserMessage String message, @V("title") String title, @V("count") Long count);
}
public static void main(String[] args) {
ChatLanguageModel model = QwenChatModel.builder()
.apiKey("sk-你的apikey")
.modelName("qwen-max")
.build();
AiWriter writer = AiServices.create(AiWriter.class, model);
String response = writer.write("写一篇作文","谁是这个世界上对你最重要的人",200L);
System.out.println(response);
}
}运行上面的代码,可以看到与上一个案例输出相同的效果,只不过本次通过参数的形式传递到SystemMessage的描述模板中,显得更灵活,更具可定制化效果

3.6.5 整合整合ChatMemory和Tools
在之前的分享中,在于springboot进行整合的时候,有下面这样一段配置代码,简单来说就是,通过这个配置类,利用AiService将ChatMemory,ChatLanguageModel等组件进行整合,打包成一个被spring管理的bean,从而一起对外提供完整的组件服务。

在如下的代码中,使用AiService将它们整合在一起使用
package com.congge.chat;
import dev.langchain4j.agent.tool.Tool;
import dev.langchain4j.agent.tool.ToolSpecification;
import dev.langchain4j.agent.tool.ToolSpecifications;
import dev.langchain4j.community.model.dashscope.QwenChatModel;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.MemoryId;
import dev.langchain4j.service.UserMessage;
import java.time.LocalDateTime;
public class AiServiceDemo2 {
interface Assistant {
String chat(@MemoryId Long memoryId, @UserMessage String message);
}
@Tool("获取当前日期")
public static String dateUtil(){
return LocalDateTime.now().toString();
}
public static void main(String[] args) throws Exception{
ChatLanguageModel model = QwenChatModel.builder()
.apiKey("sk-你的apikey")
.modelName("qwen-max")
.build();
ToolSpecification toolSpecification = ToolSpecifications.toolSpecificationFrom(AiServiceDemo2.class.getMethod("dateUtil"));
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(model)
// .chatMemory(chatMemory)
.chatMemoryProvider(memoryId -> MessageWindowChatMemory.withMaxMessages(10))
.tools(toolSpecification)
.build();
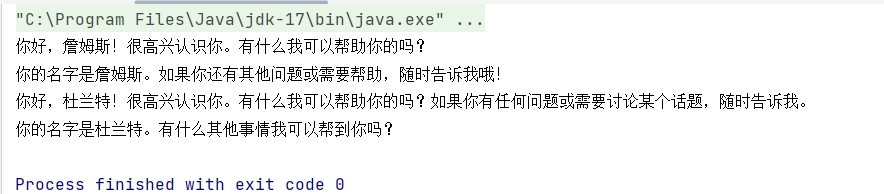
System.out.println(assistant.chat(1L, "你好,我是詹姆斯"));
System.out.println(assistant.chat(1L, "我的名字是什么"));
System.out.println(assistant.chat(1L, "你好,我是杜兰特"));
System.out.println(assistant.chat(1L, "我的名字是什么"));
}
}运行上面的代码,可以看到chatMemory 生效了
3.7 Embedding组件使用
3.7.1 什么是 Embedding
AI⼤模型相⽐于传统的数据检索,最⼤的区别在于能够“理解”⼈类的语⾔。⽐如你向ChatGPT问"我是谁"和“我叫什么名字”,ChatGPT都能够把他们正确理解成⼀个相同的问题。那么计算机是如何理解这些相似的话语之间的意思呢?
计算机并不能“理解”⼈类的语⾔,本质上,他只能进⾏各种各样的数据计算。所以要“理解”⼈类的语⾔,我们还是只能将语⾔数据化,转成⼀串串的数字,通过计算去理解语⾔之间的相似性。这中间经过了⼀系列的算法改进。⽬前⽐较主流的⽅法是对语⾔进⾏⼀些语法和词法层⾯的分析,将⼀个⽂本转换成多维的向量,然后通过向量之间的计算,来分析⽂本与⽂本之间的相似性。
向量代表⼀个有位置,有⽅向的变量。⼀个⼆维的向量可以理解为平⾯坐标轴上的⼀个坐标点(x,y),他有x轴和y轴两个维度,在计算机中,就可以⽤⼀个⼆维的数据来表示[x,y]。类似的⼀个多维的变量就对应⼀个更多维度的数组。
⽽⽂本向量化,就是通过机器学习的⽅式将⼀个⽂本转化成⼀个多维向量,后续可以通过⼀些数学公式对多个向量进⾏计算。
在LangChain4j中,抽象出了⼀个公共接⼝EmbeddingModel,来提供⽂本向量化的功能。例如下⾯的⽅法,就可以调⽤OpenAI的向量化模型,将⽂本转换成⼀个向量。
3.7.1 Embedding案例一
在下面的代码中,输入给 EmbeddingModel一句文本 ,理论上调用embeddingModel.embed方法之后,会对这句文本进行向量化
package com.congge.chat;
import dev.langchain4j.community.model.dashscope.QwenEmbeddingModel;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.output.Response;
public class EmbeddingDemo1 {
public static void main(String[] args) {
EmbeddingModel embeddingModel = QwenEmbeddingModel
.builder()
.apiKey("你的apikey")
.modelName("text-embedding-v2")
.build();
Response<Embedding> embed = embeddingModel.embed("你好,你是我的好朋友小明");
System.out.println(embed.content().toString());
System.out.println(embed.content().vector().length);
}
}运行上面的代码,可以看到下面的效果

3.7.3 向量数据库
当文本进行向量化之后,我们最终的目的是为了使用大模型进行知识检索,而知识文本进行向量化之后,提供了相似度的匹配,所以基于这一点,首先需要对文本向量化之后进行存储,存储之后,再次检索时,才能进行相似度匹配,这里需要引入向量数据库,参考langchain4j的官方文档:Embedding Models | LangChain4j ,官方也提供了很多种向量数据库可供选择
这里选择Redis Stack作为向量数据库进行数据存储,直接使用docker命令快速搭建一个Redis Stack的容器,如下:
docker run -d --name redis-stack -p 6379:6379 redis/redis-stack-server:latest
3.7.4 使用向量数据库
上一步安装了redis的向量数据库之后,就可以在代码中使用了,首先引入redis的依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-redis</artifactId>
<version>1.0.0-alpha1</version>
</dependency>参考下面的代码,使用redis-stack作为向量数据库
package com.congge.chat;
import dev.langchain4j.community.model.dashscope.QwenEmbeddingModel;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.store.embedding.redis.RedisEmbeddingStore;
public class EmbeddingDemo2 {
public static void main(String[] args) {
EmbeddingModel embeddingModel = QwenEmbeddingModel
.builder()
.apiKey("你的apikey")
.modelName("text-embedding-v2")
.build();
RedisEmbeddingStore embeddingStore = RedisEmbeddingStore.builder()
.host("你的redis地址")
.port(6379)
.dimension(1536) //维度,需要与计算结果保持⼀致。如果使⽤其他的模型,可能会有不同的结果。
.build();
// ⽣成向量
Response<Embedding> embed = embeddingModel.embed("你好,我是你的好朋友小王");
// 存储向量--单独指定数据ID,索引的ID是固定的embedding-index
embeddingStore.add("vec1", embed.content());
}
}运行之后,登录redis客户端,可以看到文本已经被向量化存储了
3.7.5 使用向量数据库检索
存储之后,接下来就可以提供一个文本,让大模型在向量数据库中进行检索,参考下面的代码
package com.congge.chat;
import dev.langchain4j.community.model.dashscope.QwenEmbeddingModel;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.store.embedding.EmbeddingMatch;
import dev.langchain4j.store.embedding.redis.RedisEmbeddingStore;
import java.util.List;
public class EmbeddingDemo2 {
public static void main(String[] args) {
EmbeddingModel embeddingModel = QwenEmbeddingModel
.builder()
.apiKey("你的apikey")
.modelName("text-embedding-v2")
.build();
RedisEmbeddingStore embeddingStore = RedisEmbeddingStore.builder()
.host("Redis 地址")
.port(6379)
.dimension(1536) //维度,需要与计算结果保持⼀致。如果使⽤其他的模型,可能会有不同的结果。
.build();
// ⽣成向量
//Response<Embedding> embed = embeddingModel.embed("你好,我是你的好朋友小王");
// 存储向量--单独指定数据ID,索引的ID是固定的embedding-index
//embeddingStore.add("vec1", embed.content());
List<EmbeddingMatch<TextSegment>> matches = embeddingStore.findRelevant(embeddingModel.embed("我的名字叫小王").content(), 3, -1);
for (EmbeddingMatch<TextSegment> match : matches){
System.out.println(match.score());
}
}
}运行代码,控制台显示结果如下
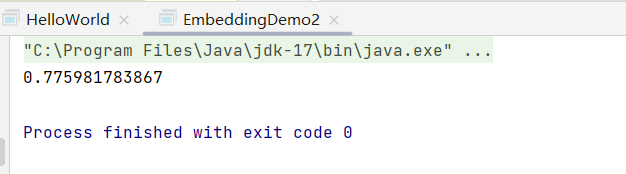
结果表明,本次输入的 ”我的名字叫小王“文本,通过检索向量数据库,得到匹配的得分数,数字的范围为0~1,越大表明相似程度越高。下面再看一个结合Redis Stack作为向量数据库的综合案例
package com.congge.chat;
import dev.langchain4j.community.model.dashscope.QwenEmbeddingModel;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.store.embedding.EmbeddingMatch;
import dev.langchain4j.store.embedding.redis.RedisEmbeddingStore;
import java.util.List;
public class EmbeddingDemo3 {
public static void main(String[] args) {
EmbeddingModel embeddingModel = QwenEmbeddingModel
.builder()
.apiKey("你的apikey")
.modelName("text-embedding-v2")
.build();
RedisEmbeddingStore embeddingStore = RedisEmbeddingStore.builder()
.host("你的redis")
.port(6379)
.dimension(1536) //维度,需要与计算结果保持⼀致。如果使⽤其他的模型,可能会有不同的结果。
.build();
//预设⼏个指示,⽣成向量
TextSegment textSegment1 = TextSegment.textSegment("客服电话是400-8558558");
TextSegment textSegment2 = TextSegment.textSegment("客服⼯作时间是周⼀到周五");
TextSegment textSegment3 = TextSegment.textSegment("客服投诉电话是400-8668668");
Response<dev.langchain4j.data.embedding.Embedding> embed1 = embeddingModel.embed(textSegment1);
Response<dev.langchain4j.data.embedding.Embedding> embed2 = embeddingModel.embed(textSegment2);
Response<dev.langchain4j.data.embedding.Embedding> embed3 = embeddingModel.embed(textSegment3);
// 存储向量
embeddingStore.add(embed1.content(), textSegment1);
embeddingStore.add(embed2.content(), textSegment2);
embeddingStore.add(embed3.content(), textSegment3);
// 预设⼀个问题,⽣成向量
Response<dev.langchain4j.data.embedding.Embedding> embed = embeddingModel.embed("客服电话多少");
// 查询
List<EmbeddingMatch<TextSegment>> result =
embeddingStore.findRelevant(embed.content(), 5);
for (EmbeddingMatch<TextSegment> embeddingMatch : result) {
System.out.println(embeddingMatch.embedded().text() + ",分数为:" +
embeddingMatch.score());
}
}
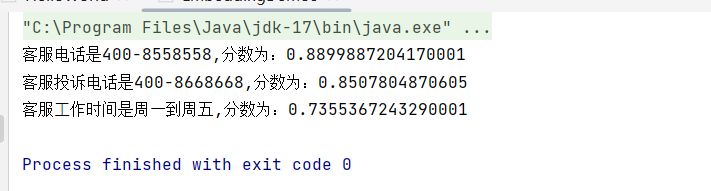
}运行一下,控制台的输出结果如下,不难看出,由于最终问的问题与最初设置答案里面第一个最相近,所以给出的回答中,也是排在了第一个,得分也最高,也是符合预期的效果的
3.8 RAG完整案例
AI⼤模型回答所有问题都要基于他之前训练过的数据,很显然,如果AI⼤模型没有专⻔“学习”过美团的业务说明,那么⾯对⼀些跟美团业务直接相关的问题,例如“美团外卖中在线⽀付取消订单后钱怎么返还?”时,是⽆法给出理想的答案的。
如何让AI⼤模型能够“学习”美团的业务知识呢?⽬前有两种主要的⽅法:
-
对模型进⾏微调Fine-Tuning:
-
这是在已有的预训练模型的基础上,根据特定的任务和数据集,对模型的参数进⾏进⼀步调整和优化。你可以简单的理解为从胎⼉时期开始专⻔训练⼀个只会Java的机器⼈。这种⽅式针对性更强,对Java问题的理解更准确。但是,随之⽽来的问题是成本更⾼,并且针对其他领域,性能就不太好。
-
-
RAG(Retrieval-Augmented Generation,检索增强⽣成):
-
这种⽅式还是使⽤泛化的⼤模型,只不过通过对问题和答案进⾏优化,增强,让⼤模型能够结合已有数据,给出更准确的答案。你可以理解为教⼀个什么都会的机器⼈学Java。这种⽅式成本相对⽐较低,也更适合处理那些涉及到⼤量外部数据的特定问题。
-
从这两种⽅式的⽐较。你应该能够⼤致理解RAG的⼯作过程。RAG通常分为两个阶段:
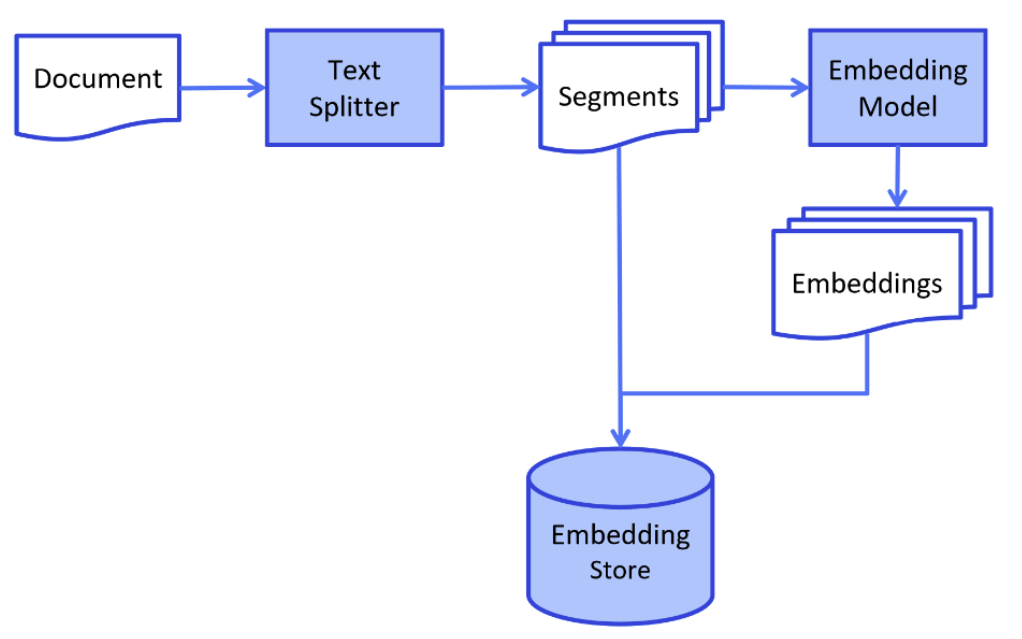
1)Indexing 索引阶段
这⼀阶段主要是要对知识库进⾏处理。例如对知识库的内容进⾏Embedding向量化处理,并保存到向量数据库中。
2)Retrieval 检索阶段
这⼀阶段主要是当⽤户提出⼀个问题时,可以到向量数据库中检索出跟⽤户的问题⽐较关联的“知识”,整理成完整的prompt,⼀起发送给⼤模型,然后由⼤模型对信息进⾏整合,再给⽤户正确答案。
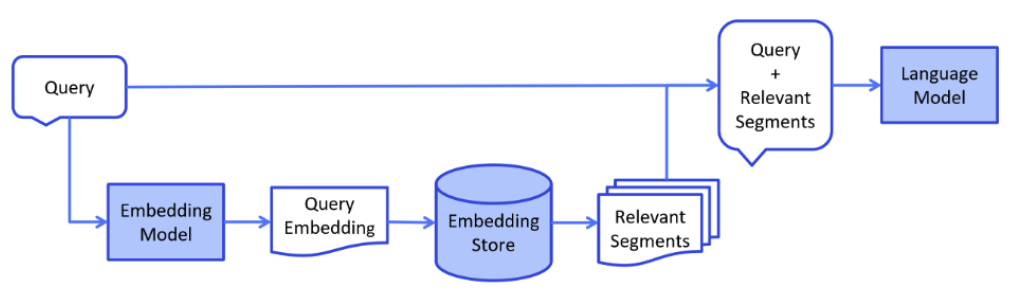
比如可以定制下面这样一个Prompt模板 :
prompt_template = "*"
你是⼀个问答机器⼈。
你的任务是根据下述给定的已知信息回答⽤户问题。
已知信息:
{context} # {context}就是检索出来的⽂档
⽤户问:
{question} # {question} 就是⽤户的问题
如果已知信息不包含⽤户问题的答案,或者已知信息不⾜以回答⽤户的问题,请直接国复“我⽆法回答您的问
题”。
请不要输出已知信息中不包含的信息或答案。
请⽤中⽂回答⽤户问题。
下面通过案例代码演示下完整的过程。
3.8.1 准备一个文档
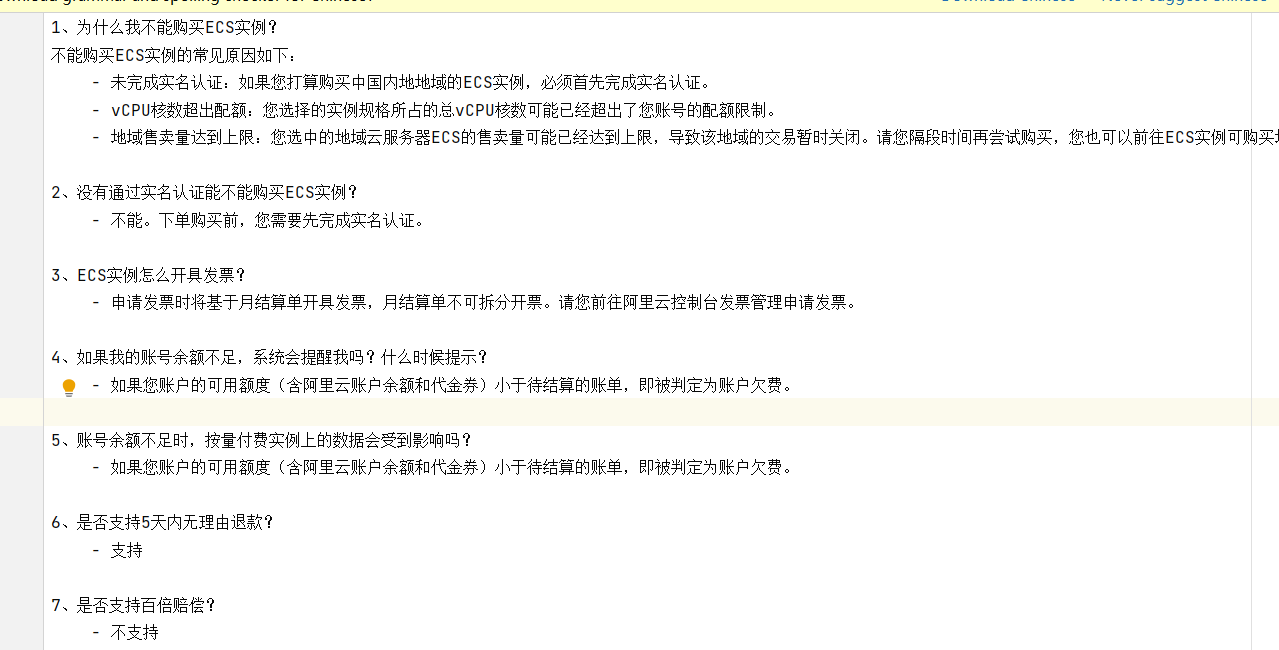
在工程的resources目录下准备一个文件,作为存储到向量数据库中的原始文档,文档可以是txt,pdf,md等格式的文件,内容如下:
3.8.2 加载文件到向量数据库
参考下面的代码,上述的文档内容加载到向量数据库中
package com.congge.rag;
import dev.langchain4j.community.model.dashscope.QwenEmbeddingModel;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.DocumentParser;
import dev.langchain4j.data.document.DocumentSplitter;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.data.document.parser.TextDocumentParser;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.store.embedding.redis.RedisEmbeddingStore;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.List;
public class RagSearchDemo {
public static void main(String[] args) throws Exception{
Path documentPath =
Paths.get(RagSearchDemo.class.getClassLoader().getResource("question.txt").toURI());
DocumentParser documentParser = new TextDocumentParser();
Document document = FileSystemDocumentLoader.loadDocument(documentPath,
documentParser);
//文本切分
DocumentSplitter splitter = new MyDocumentSplitter();
List<TextSegment> segments = splitter.split(document);
//文本向量化村粗
EmbeddingModel embeddingModel = QwenEmbeddingModel
.builder()
.apiKey("你的apikey")
.modelName("text-embedding-v2")
.build();
RedisEmbeddingStore embeddingStore = RedisEmbeddingStore.builder()
.host("Redis地址")
.port(6379)
.dimension(1536) //维度,需要与计算结果保持⼀致。如果使⽤其他的模型,可能会有不同的结果。
.indexName("service_rag")
.build();
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
embeddingStore.addAll(embeddings,segments);
System.out.println("文档加载向量数据库成功");
}
}运行上述代码进行文本的向量化存储
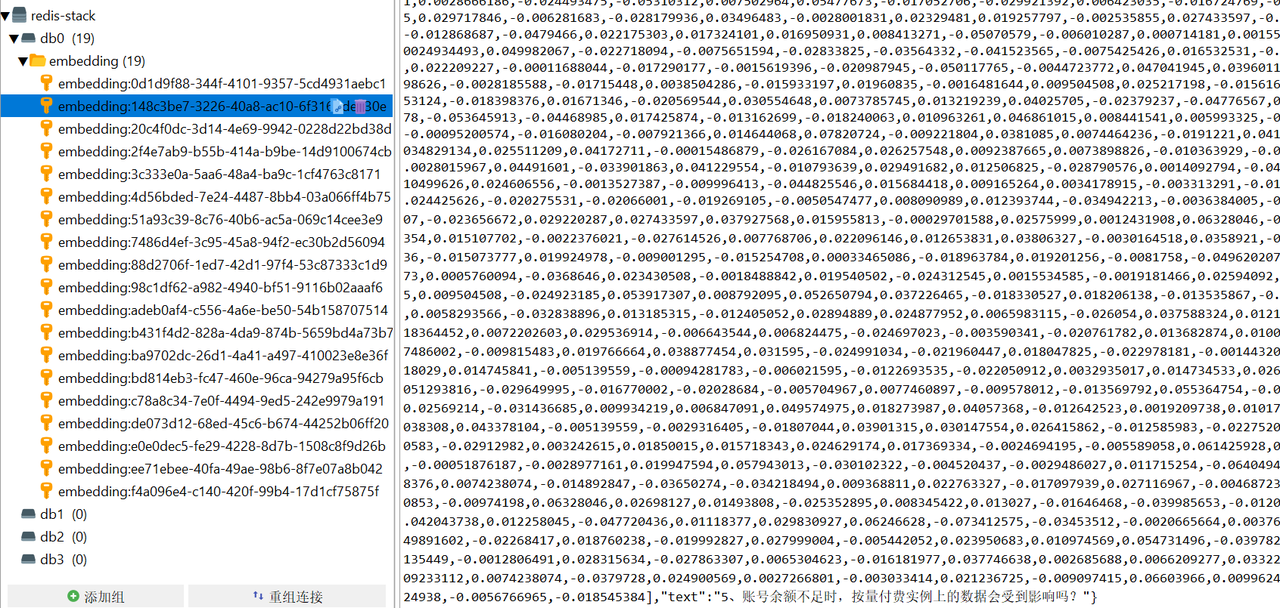
可以去redis中进一步检查是否加载成功,可以看到已经加载成功
3.8.3 文本检索
上一步将文本内容存储到向量数据库之后,接下来就可以进行问题的检索了,参考下面的代码
package com.congge.rag;
import dev.langchain4j.community.model.dashscope.QwenEmbeddingModel;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.rag.content.Content;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.rag.query.Query;
import dev.langchain4j.store.embedding.redis.RedisEmbeddingStore;
import java.util.List;
public class RagSearchDemo1 {
public static void main(String[] args) throws Exception{
String question = "ECS实例怎么开具发票";
//文本向量化村粗
EmbeddingModel embeddingModel = QwenEmbeddingModel
.builder()
.apiKey("你的apikey")
.modelName("text-embedding-v2")
.build();
RedisEmbeddingStore embeddingStore = RedisEmbeddingStore.builder()
.host("Redis服务地址")
.port(6379)
.dimension(1536) //维度,需要与计算结果保持⼀致。如果使⽤其他的模型,可能会有不同的结果。
.indexName("service_rag")
.build();
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore) //向量存储模型
.embeddingModel(embeddingModel) //向量模型
.maxResults(5) // 最相似的5个结果
.minScore(0.8) // 只找相似度在0.8以上的内容
.build();
Query query = new Query(question);
List<Content> contentList = contentRetriever.retrieve(query);
for (Content content : contentList) {
System.out.println(content);
}
}
}运行上面的代码,通过控制台输出可以看到,就输出了与本次查询的问题相关的知识条目信息,从向量数据库中检索到了一个相关的内容

3.8.4 结合大模型使用
接下来就需要将向量数据库查询得到的结果,作为一个Prompt发给大模型,然后大模型根据问题给出回答,只需要在上面的代码中继续追加下面的内容
ChatLanguageModel model = QwenChatModel.builder()
.apiKey("sk-你的apikey")
.modelName("qwen-max")
.build();
Response<AiMessage> generate = model.generate(promptMessage);
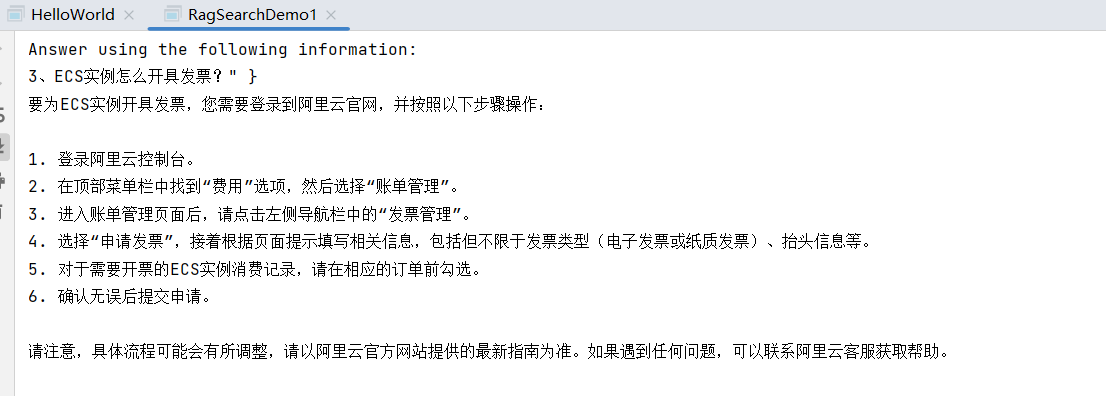
System.out.println(generate.content().text());再次运行一下,可以看到下面的结果,此时就得到了一个比较完整的答案
四、写在文末
本文通过较大的篇幅详细介绍了RAG技术中Langchain4j的核心组件的使用,并通过案例代码演示了各个组件的具体使用,希望对看到的同学有用哦,本篇到此结束,感谢观看。