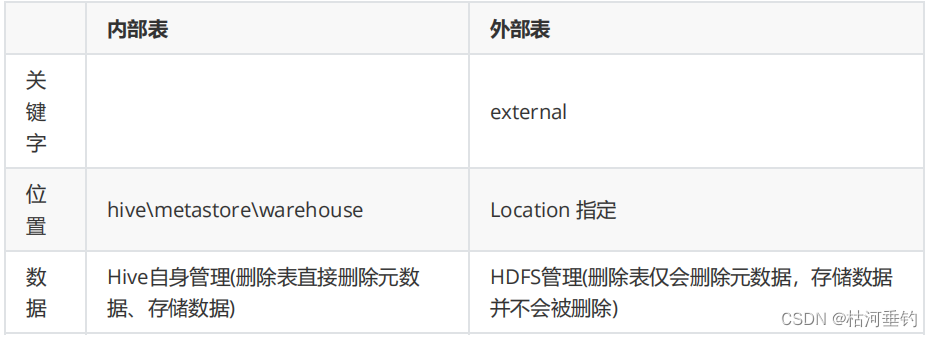
文章目录
- 前言
- 一、Swin Transformer
- 1.Swin Transformer概览
- 2.Patch Partition
- 3.Patch Merging
- 4.W-MSA
- 5.SW-MSA(滑动窗口多头注意力机制)
- 6.Relative Position bias(相对位置偏移)
- 7.网络结构
- 🥇Swin Transformer Block
- 🥈Architecture
- 二、网络实现
- 1.构建EfficientNetV2网络
- 2.训练和测试模型
- 三、实现图像分类
- 结束语
- 💂 个人主页:风间琉璃
- 🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有
帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
前言
Swin Transformer(Liu et al., 2021) 是一种基于视觉Transformer的层次化模型。与之前的Vision Transformer相比,Swin Transformer采用了层次化构建方法,使用不同倍数的下采样来构建特征图,并在每个窗口内使用Windows Multi-Head Self-Attention(W-MSA)进行注意力计算。这种方法既减少了计算量,尤其是在浅层特征图较大时,又能在相邻窗口之间传递信息。
此外,Swin Transformer在目标检测、实例分割等任务上也具有较好的表现,Swin Transformers 已经被用作当今许多视觉模型架构的主干。
在看本篇之前,建议你有Vision Transformer的相关基础,Transformer和Vision Transformer参考连接:
一、Swin Transformer
1.Swin Transformer概览
将 Transformer 从语言应用到视觉方面主要有两大挑战:
⋆
\star
⋆ 视觉实体变化大,在不同场景下视觉Transformer性能未必很好
⋆
\star
⋆ 图像分辨率高,像素点多,Transformer基于全局自注意力的计算导致计算量较大
Swin Transformer 引入了两个关键的概念来解决原始 ViT 所面临的问题:分层特征图(hierarchical feature maps)和转移窗口注意力(shifted window attention)。Swin Transformer 的名字来源于“Shifted window Transformer”。
Swin Transformer和Vision Transformer对比:
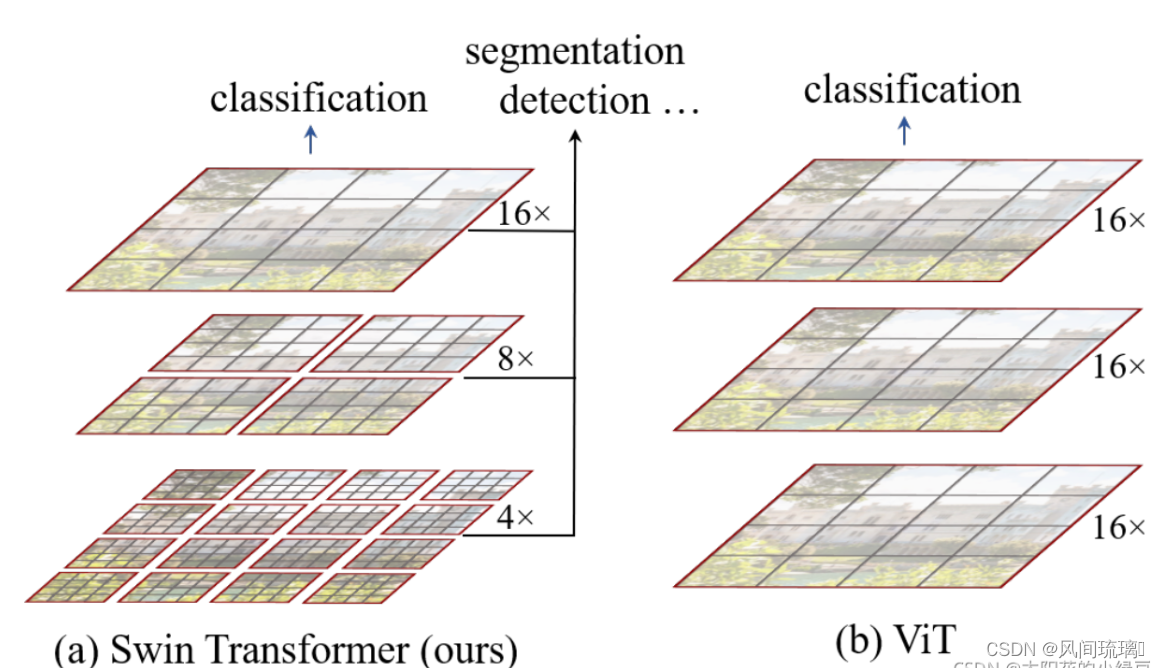
在上图左边是Swin Transformer,右边Vision Transformer,这张图它想表达Swin Transformer的两个核心点:
①Swin Transformer使用层次化构建方法(Hierarchical feature maps),特征图尺寸中有对图像下采样4倍的,8倍的以及16倍的,抽取不同层次的视觉特征,使其更适合分割检测等任务。而ViT中是一直16倍下采样。
Swin Transformer通过从小尺寸 patch开始,逐渐在更深的 Transformer 层中合并相邻 patch,从而构造出一个层次化表示 (hierarchical representation)。通过这些层次化特征图,Swin Transformer 模型可方便地利用先进技术进行密集预测,例如特征金字塔网络 (FPN) 或 U-Net。
②Swin Transformer中使用了Windows Multi-Head Self-Attention(W-MSA),在上图的4倍下采样和8倍下采样中,将特征图划分成了多个不相交的区域(Window),并且Multi-Head Self-Attention只在每个窗口(Window)内进行。
上图两边红框代表在红框内进行transformer,右边ViT的红框是整张图,而左边Swin Transformer的红框是在小窗口上进行的。相对于ViT中直接对整个特征图进行Multi-Head Self-Attention,这样做的目的是能够减少计算量的,尤其是在浅层特征图很大的时候。
这样做虽然减少了计算量但也会隔绝不同窗口之间的信息传递,所以在论文中作者又提出了 Shifted Windows Multi-Head Self-Attention(SW-MSA),通过此方法能够让信息在相邻的窗口中进行传递。
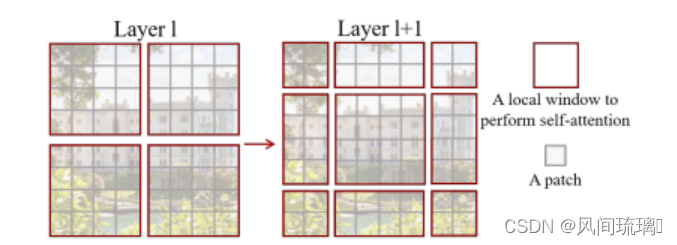
为了解决采用W-MSA模块时,只会在每个窗口内进行自注意力计算,窗口与窗口之间是无法进行信息传递的,Swin Transformer引入了一个关键设计元素是它在连续自注意力层之间的窗口分区的移位 (shift),即Shifted Windows Multi-Head Self-Attention(SW-MSA),如上图所示。
每一个小块叫做一个patch,每一个深色方块框起来的叫一个local window,在每一个local window中计算self-attention。如果是只计算一次self-attention,每个local window之间是孤立的,会隔绝不同窗口之间的信息传递。但是实际上所有的local window组成一张图片,他们之间是有关联的,所以引入了shifted-window进行了第二次self-attention,使用这个滑动窗口多头注意力机制的目的是为了实现不同windows之间的信息交互。
在Swin Transformer网络结构中一般是先使用W-MSA模块,然后紧跟着使用SW-MSA模块的。在使用完W-MSA模块后再对特征进行分块可以理解为在上一层的基础上将每个windows分别向下后再向右移动了两个像素,经过这样处理后每个窗口都具有了特征图不同块的信息。
2.Patch Partition
对于图像数据,其数据格式为[H, W, C],不满足Transformer输入要求。所以需要先通过Patch Partition来对图像数据处理,将图像划分为固定大小的patch。然后将每个块沿着通道维度展开,可以用作后续任务的输入。如下图所示,具体细节可以参考前面给的链接文章。

3.Patch Merging
在 ResNet 等卷积神经网络中,特征图的下采样是使用卷积操作完成的,在Swin Transformer 中使用的无卷积下采样技术称为 Patch Merging。
在每个Stage(Stage1除外)开始前通过一个Patch Merging层进行下采样,用于缩小分辨率,调整通道数 进而形成层次化的设计,同时也能节省一定运算量。在CNN中,则是在每个Stage开始前用stride=2的卷积/池化层来降低分辨率。
每次降采样是两倍,因此在行方向和列方向上,间隔2选取元素。然后拼接在一起作为一整个张量,最后展开。此时通道维度会变成原先的4倍(因为H,W各缩小2倍),此时再通过一个全连接层再调整通道维度为原来的两倍。

如上图所示,假设输入Patch Merging的是一个8x8大小的单通道特征图(feature map),Patch Merging会将每个4x4的相邻像素划分为一个patch,然后将每个patch中相同位置像素给拼在一起得到4个feature map, 并将这四个feature map在深度方向进行concat拼接。然后在通过一个LayerNorm层和全连接层在feature map的深度方向做线性变化,将feature map的深度由C变成C/2,即减半(上图中不包含最后的全连接层调整)。
该模块主要存在于Stage2-4,作用主要为下采样,即高和宽减半、通道翻倍,其动态处理如图:

4.W-MSA
引入Windows Multi-head Self-Attention(W-MSA)模块是为了减少计算量。如下图所示,左侧使用的是普通的Multi-head Self-Attention(MSA)模块,对于feature map中的每个patch,在Self-Attention计算过程中需要和所有的patch去计算。这导致Patch 数量平方复杂度,使其不适合高分辨率图像。
为了解决这个问题,Swin Transformer 使用了Windows Multi-head Self-Attention(W-MSA)。 一个 Window 只是一个 patch 的集合,注意力计算只在每个 Window 内进行。 例如,下图右侧使用 2 x 2 块的 Window 大小,然后单独对每个Windows内部进行Self-Attention。。

MSA和W-MSA动态处理过程:

对于普通的MSA模块来说,会对每一个patch去求解它的q,k,v的值,对任意一个patch所求得的q会对特征图中其他像素的k进行一个相似度的匹配,然后再进行一系列的操作,具体细节参考前面ViT的文章。

在W-MSA模块当中,首先会将特征图分成多个Windows后再进行处理,然后再对每个窗口的内部执行多头注意力机制的计算,但是这种方法窗口与窗口之间是无法进行信息交互的,这种缺点也会使得感受野变小,无法看到全局的感受野。
5.SW-MSA(滑动窗口多头注意力机制)
采用W-MSA模块时,只会在每个窗口内进行自注意力计算,导致窗口与窗口之间是无法进行信息传递的。为了解决这个问题,Swin Transformer 在 W-MSA 模块之后使用了 Shifted Windows Multi-Head Self-Attention(SW-MSA)模块,即进行偏移的W-MSA。
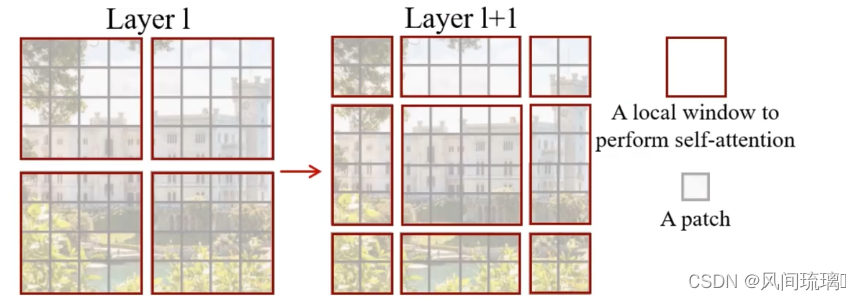
左侧使用W-MSA(假设是第L层),一般W-MSA和SW-MSA是成对使用的,那么第L+1层使用是SW-MSA(右侧图)。根据左右两幅图对比能够发现窗口(Windows)发生了偏移,可以看成窗口从左上角分别向右侧和下方各偏移了
M
2
\cfrac{M}{2}
2M个patch。
在L层时每个窗口里的patch只能和同一个窗口里的patch相互学习。在偏移后的窗口(右侧图),由于窗口的移动,导致某些patch进入新的窗口,这些带有上一层窗口信息的patch可以和别的带有上一层前窗口信息的patch相互学习。解决了不同窗口之间无法进行信息交流的问题。
比如对于第一行第2列的2x4的窗口,它能够使第L层的第一排的两个窗口信息进行交流;第二行第二列的4x4的窗口,他能够使第L层的四个窗口信息进行交流。以上解决了不同窗口之间无法进行信息交流的问题。
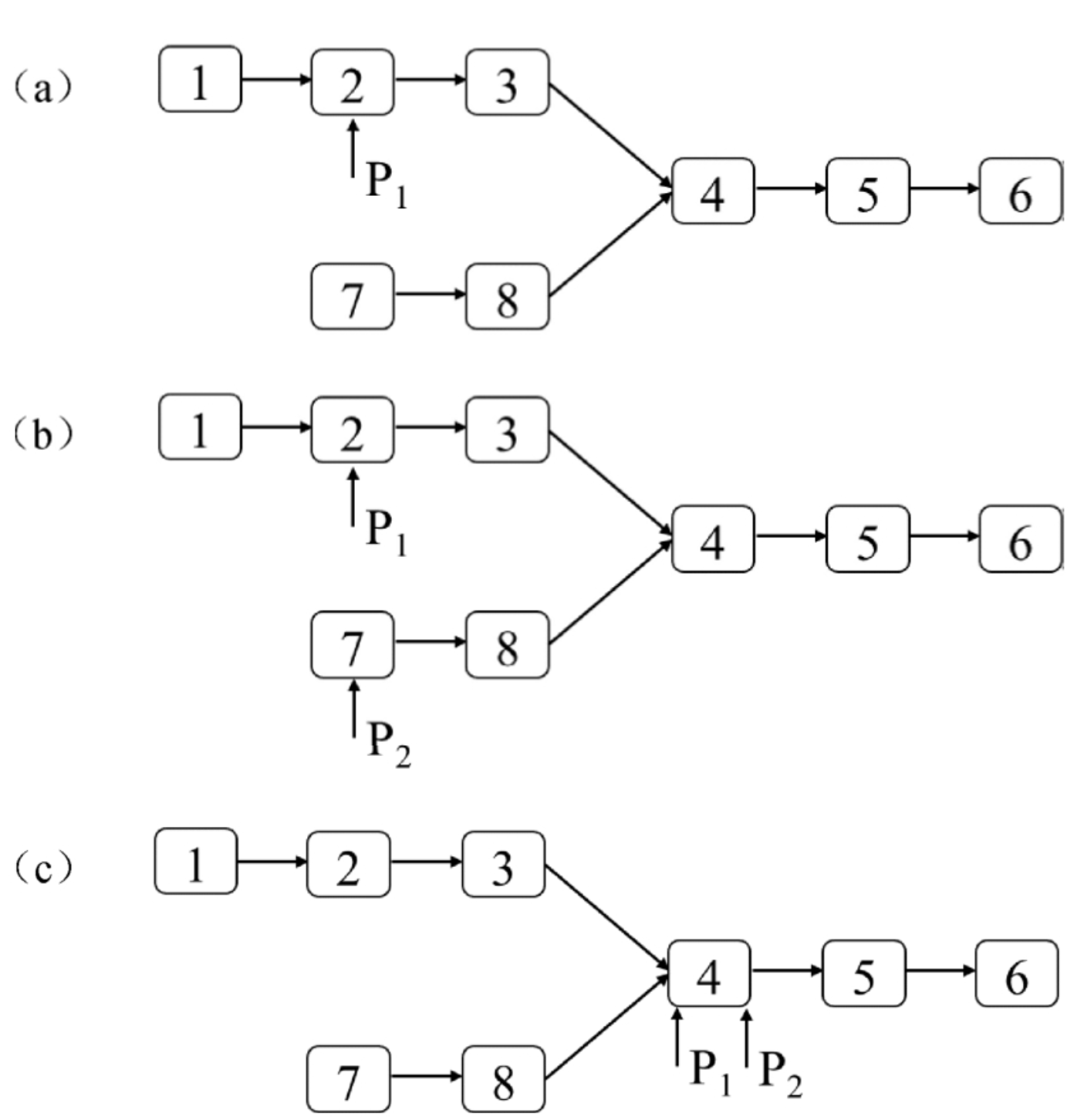
在SW-MSA方法中,将特征划分为多个不规则的块,则增加了计算量,因为W-MSA模块将模型划分为4个等大小的块,而SW-MSA将模型分为9个块,因此模型计算量加大。为了解决这个麻烦,作者又提出而了Efficient batch computation for shifted configuration,一种更加高效的计算方法。下面是原论文给的示意图: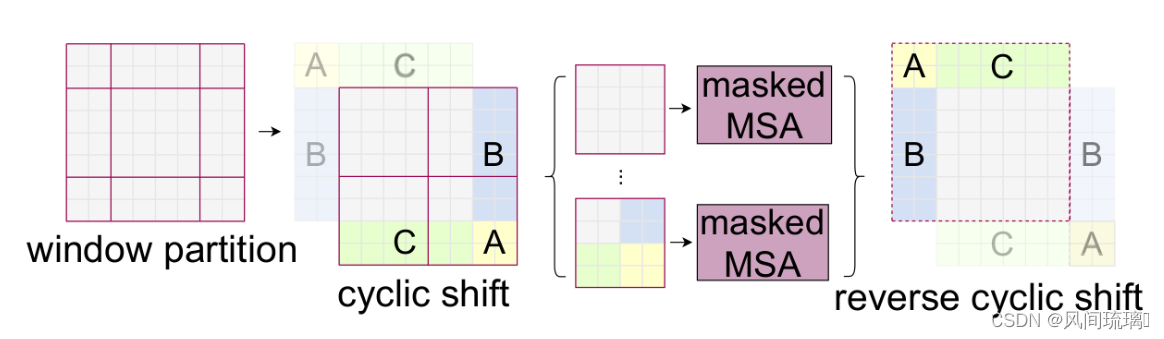
通过对特征图移位,并给 Attention 设置 Mask 来间接实现 Shift Window Attention (SW-MSA)。从而,在保持原 Window 数不变的情况下,使最后的计算结果等价。
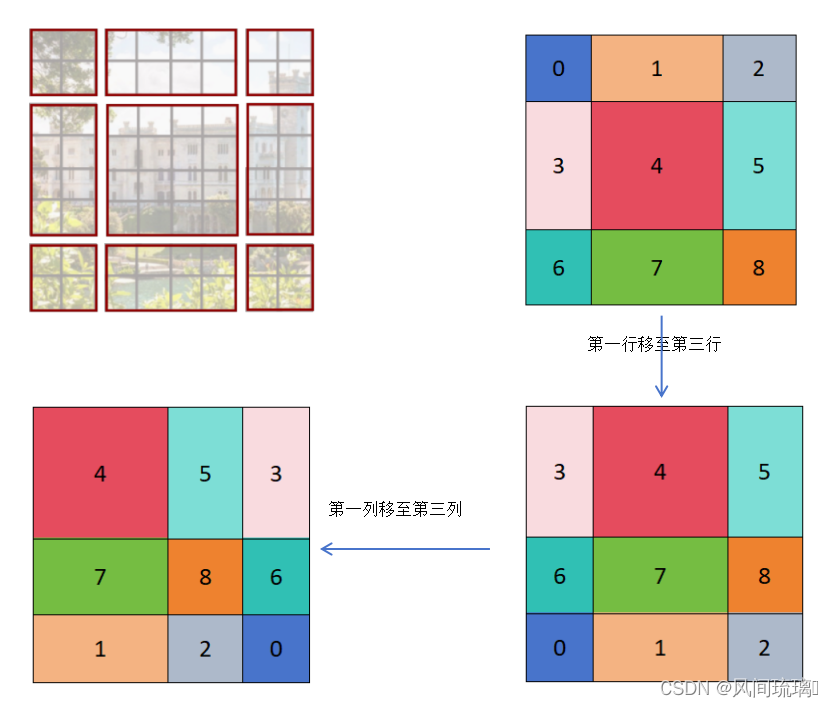
将上图中的区域对应着进行标号,每个块进行了0-8的编号。为了减少计算量,首先将区域第一行移至第三行,然后再将新的的第一列移至第三列。网上另一种移动方式是:首先将1和2两块移到最下方7和8的下面,然后,将3和6移动到右边5和8的右边,最后,将0移动到最右下角。这两种最后得到到的特征图都是一样的。
移动完后,4是一个窗口;将5和3合并成一个窗口;7和1合并成一个窗口;8、6、2和0合并成一个窗口。这样可以间接的划分为新得4x4窗口,所以能够保证计算量是一样的。
但是把不同的区域合并在一起进行MSA,会造成信息错乱,需要设计一种新的计算方式。为了防止这个问题,在实际计算中使用的是masked MSA即带蒙板mask的MSA,可以通过设置蒙板来隔绝不同区域的信息。
关于mask如何使用,可以看下下面这幅图,下图是以上面的区域5和区域3为例。
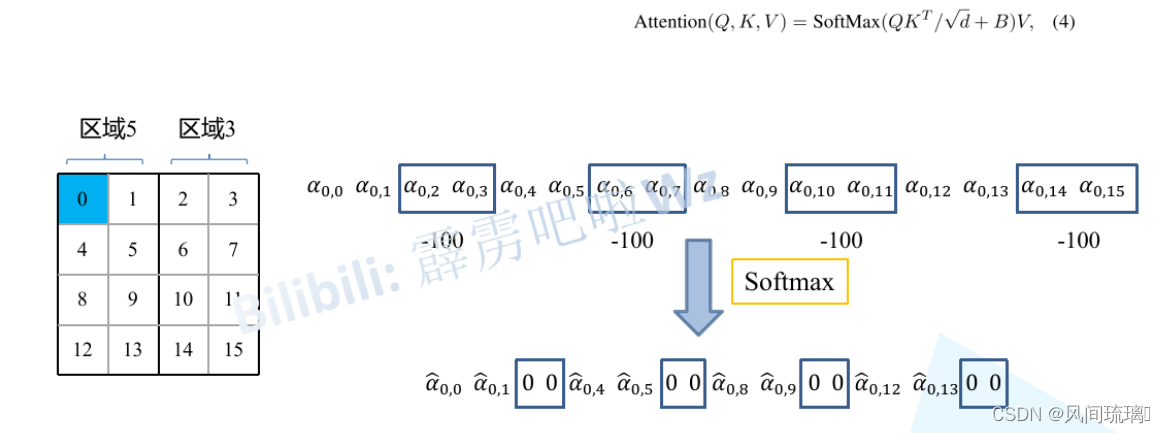
对于该窗口内的每一个patch在进行MSA计算时,都要先生成对应的query(q),key(k),value(v)。假设对于上图的像素0而言,得到
q
0
q^0
q0后要与每一个像素的k进行匹配(match),假设
α
0
,
0
\alpha _{0,0}
α0,0代表
q
0
q^0
q0与像素0对应的
k
0
k^0
k0进行匹配的结果,同理可以得到
α
0
,
0
\alpha _{0,0}
α0,0至
α
0
,
15
\alpha _{0,15}
α0,15。
按照普通的MSA计算,接下来进行SoftMax操作。但对于这里的masked MSA,像素0是属于区域5的,只想让它和区域5内的像素进行匹配。那么可以将像素0与区域3中的所有像素匹配结果
α
\alpha
α都减去100(例如
α
0
,
2
\alpha _{0,2}
α0,2,
α
0
,
3
\alpha _{0,3}
α0,3,
α
0
,
6
\alpha _{0,6}
α0,6,
α
0
,
7
\alpha _{0,7}
α0,7…)。
一般
α
\alpha
α的值都很小,一般都是零点几,将其中一些数减去100后在通过SoftMax得到对应的权重基本上为0。所以对于像素0而言实际上还是只和区域5内的像素进行了MSA。对于其他像素也可以采用相同的操作。注意,在计算完后还要把数据给挪回到原来的位置上。
SW-MSA动态过程:在这种Shifted操作之后,一个窗口可能由原始特征图中不相邻的patch组成,因此在计算时使用了 Mask,以限制对相邻 patch 的自注意。

6.Relative Position bias(相对位置偏移)
绝对位置编码是在进行self-attention计算之前为每一个token添加一个可学习的参数,相对位置编码如下式所示,是在进行self-attention计算时,在计算过程中添加一个可学习的相对位置参数。
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
+
B
)
V
Attention(Q,K,V) = softmax(\cfrac{QK^T}{\sqrt{d_k}} + B)V
Attention(Q,K,V)=softmax(dkQKT+B)V
计算流程如下:
假设输入的feature map高宽为2,首先可以构建出每个像素的绝对位置,如左下方的矩阵所示,对于每个像素的绝对位置是使用行号和列号表示的。
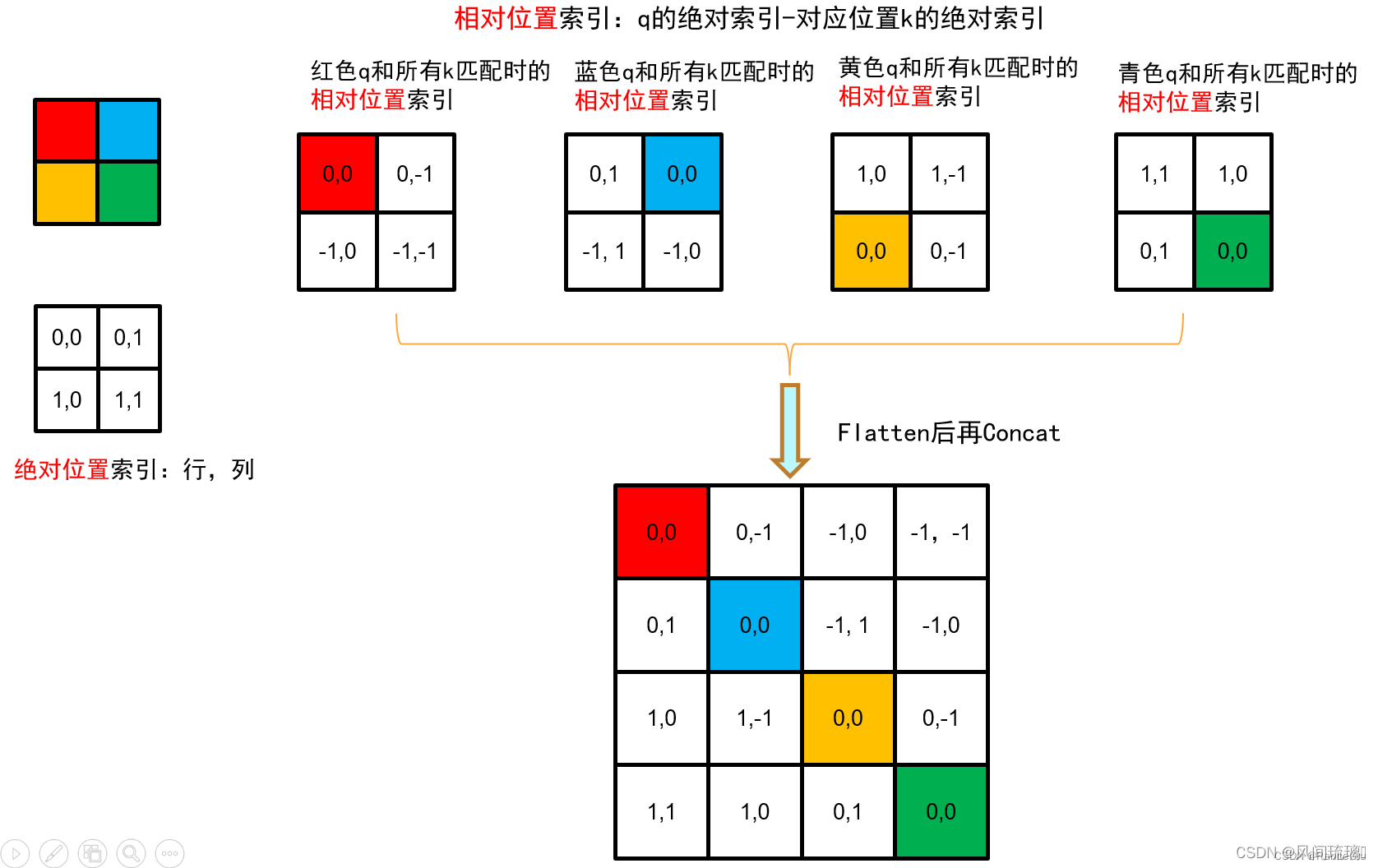 首先对蓝色像素使用q与所有像素k进行匹配过程中,是以蓝色像素为参考点,使用蓝色像素的绝对位置索引与其他位置索引进行相减,得到其他位置相对蓝色像素的相对位置索引。同理可以得到相对黄色,红色以及绿色像素的相对位置索引矩阵。
首先对蓝色像素使用q与所有像素k进行匹配过程中,是以蓝色像素为参考点,使用蓝色像素的绝对位置索引与其他位置索引进行相减,得到其他位置相对蓝色像素的相对位置索引。同理可以得到相对黄色,红色以及绿色像素的相对位置索引矩阵。
接下来将每个相对位置索引矩阵按行展平,并拼接在一起可以得到下面的4x4矩阵 。作者为了方便把二维索引给转成一维索引,如下图所示。
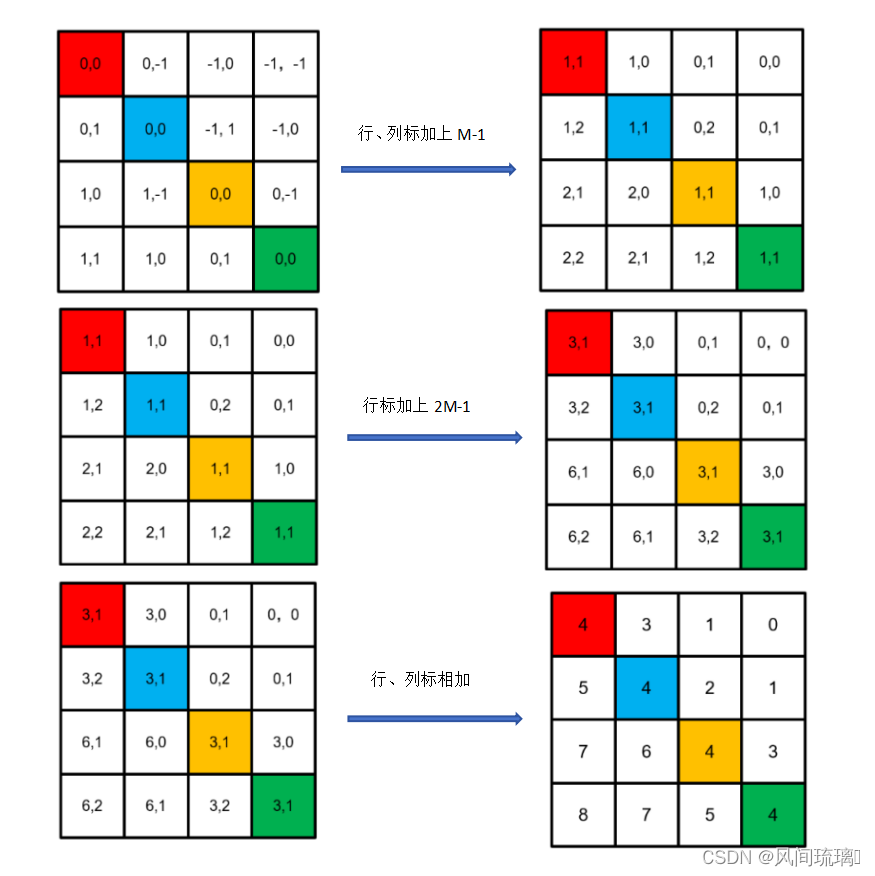 首先在原始的相对位置索引上加上M-1(M为窗口的大小,在本示例中M=2)。然后将所有的行标都乘上2M-1。最后将行标和列标进行相加,这样即保证了相对位置关系。
首先在原始的相对位置索引上加上M-1(M为窗口的大小,在本示例中M=2)。然后将所有的行标都乘上2M-1。最后将行标和列标进行相加,这样即保证了相对位置关系。
至此相对位置索引计算完毕,但是公式中要的是相对位置偏置参数,可训练参数
B
^
\widehat{B}
B
保存在relative position bias table(相对位置偏置表)里的,由于相对位置索引总共有(2M-1)×(2M-1)种,则表的长度为(2M-1) x (2M-1),上述公式中的相对位置偏执参数B是根据上面的相对位置索引表根据查relative position bias table表得到的,如下图所示。
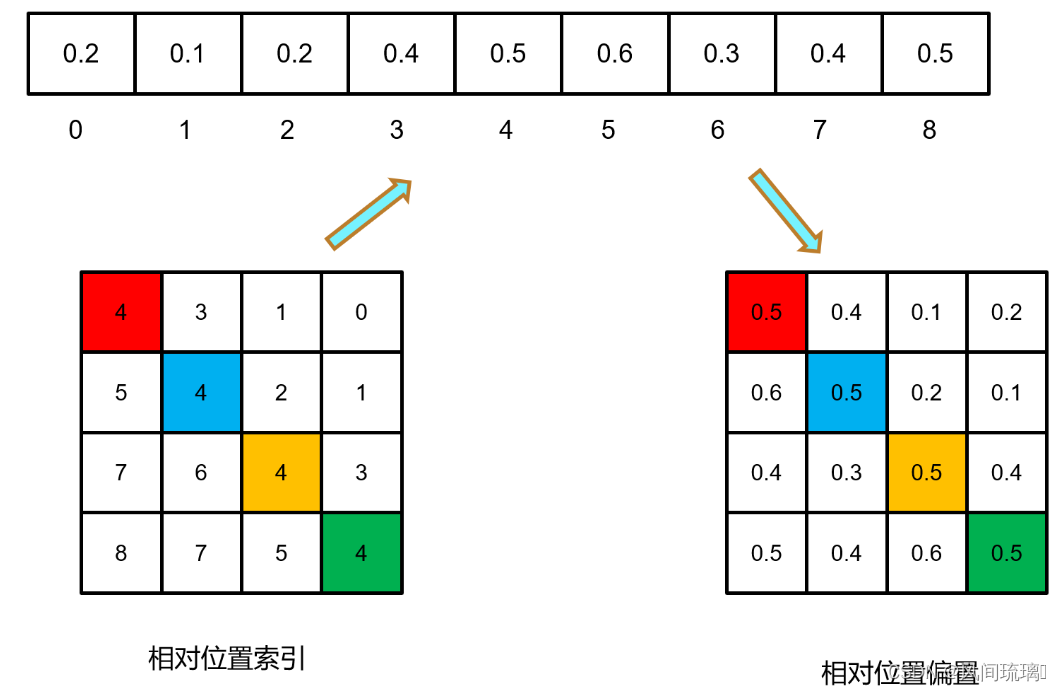
最后使用对应的相对位置偏置表(Relative position bias table)进行映射即可得到最终的相对位置偏置B。
7.网络结构
🥇Swin Transformer Block
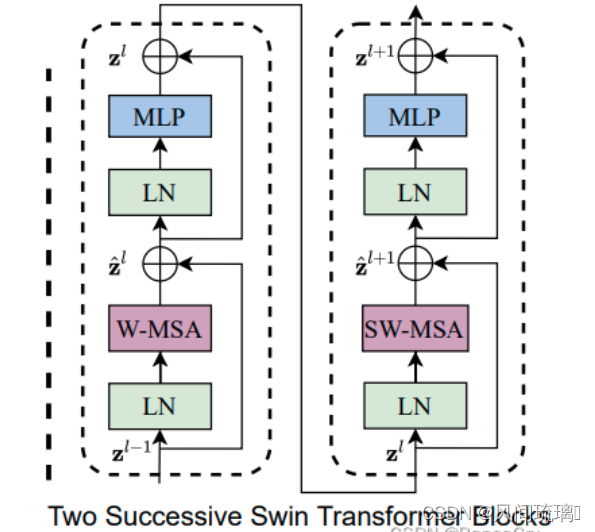
上图为Swin Transformer Block结构图,一个 Swin Transformer block 由一个 基于移位窗口的 MSA 模块 构成,且后接一个夹有 GeLU 非线性在中间的 2 层 MLP。LayerNorm (LN) 层被应用于每个 MSA 模块和每个 MLP 前,且一个残差连接被应用于每个模块后。Swin Transformer使用window self-attention降低了计算复杂度,又为了保证不重叠窗口之间有联系,采用了shifted window self-attention的方式重新计算一遍窗口偏移之后的自注意力。
所以Swin Transformer Block都是成对出现的 (W-MSA + SW-MSA为一对) ,先使用一个W-MSA结构再使用一个SW-MSA结构。所以堆叠Swin Transformer Block的次数都是偶数,在整体模型里Swin Transformer Blocks下的×2、×6就是因为成对使用的意思。
两个连续 Swin Transformer Blocks 的计算可表示为计算过程如下:
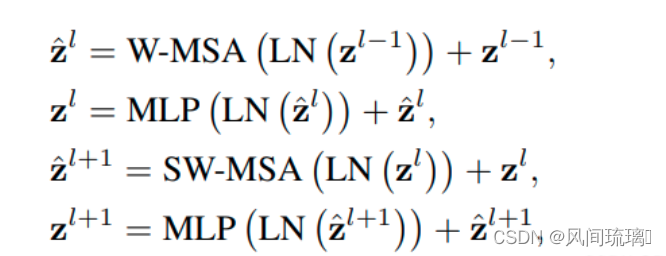
🥈Architecture
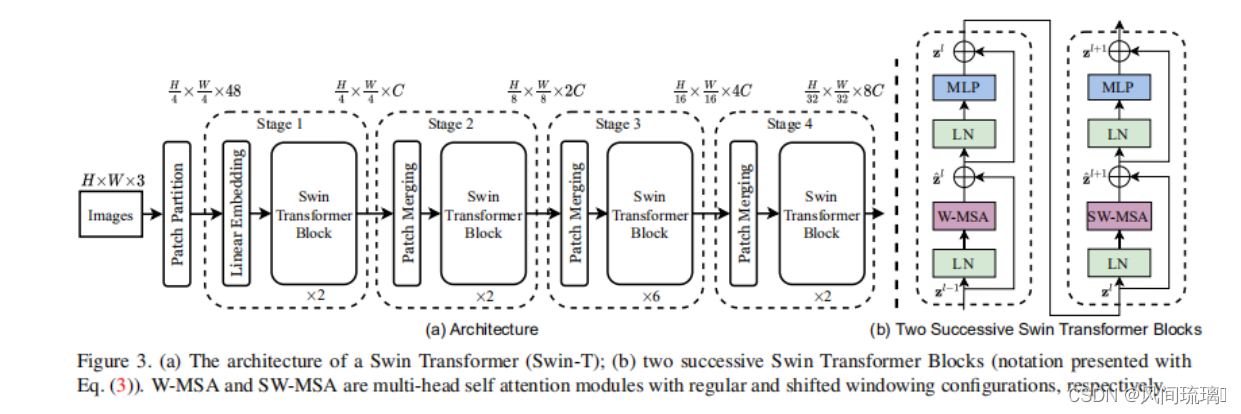
上图展示了 Swin Transformer 架构概览 (tiny 版 SwinT)。它首先将图片输入到Patch Partition模块中进行分块,即每4x4相邻的像素为一个Patch,然后在channel方向展平(flatten)。假设输入的是RGB三通道图片,那么每个patch就有4x4=16个像素,然后每个像素有R、G、B三个值所以展平后是16x3=48,所以通过Patch Partition后图像shape由 [H, W, 3]变成了 [H/4, W/4, 48]。
然后通过Linear Embeding层对每个像素的channel数据做线性变换,由48变成C,即图像shape再由 [H/4, W/4, 48]变成了 [H/4, W/4, C]。在源码中Patch Partition和Linear Embeding直接通过一个卷积层实现的。
然后通过四个Stage构建不同大小的特征图,除了Stage1中先通过一个Linear Embeding层外,剩下三个stage都是先通过一个Patch Merging层进行下采样,像 CNN 一样逐层扩大感受野,以便获取到全局的信息。为产生一个层次化表示 (Hierarchical Representation),随着网络的加深,tokens 数逐渐通过Patch Meraging被减少,其维度扩大。每个 Stage 都会改变张量的维度,从而形成一种层次化的表征。由此,该架构可方便地替换现有的各种视觉任务的主干网络。
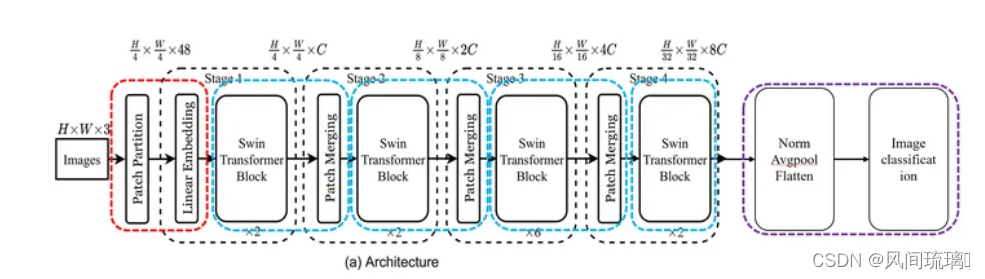
最后对于分类网络,后面还会接上一个Layer Norm层、全局池化层以及全连接层得到最终输出。如下图所示:
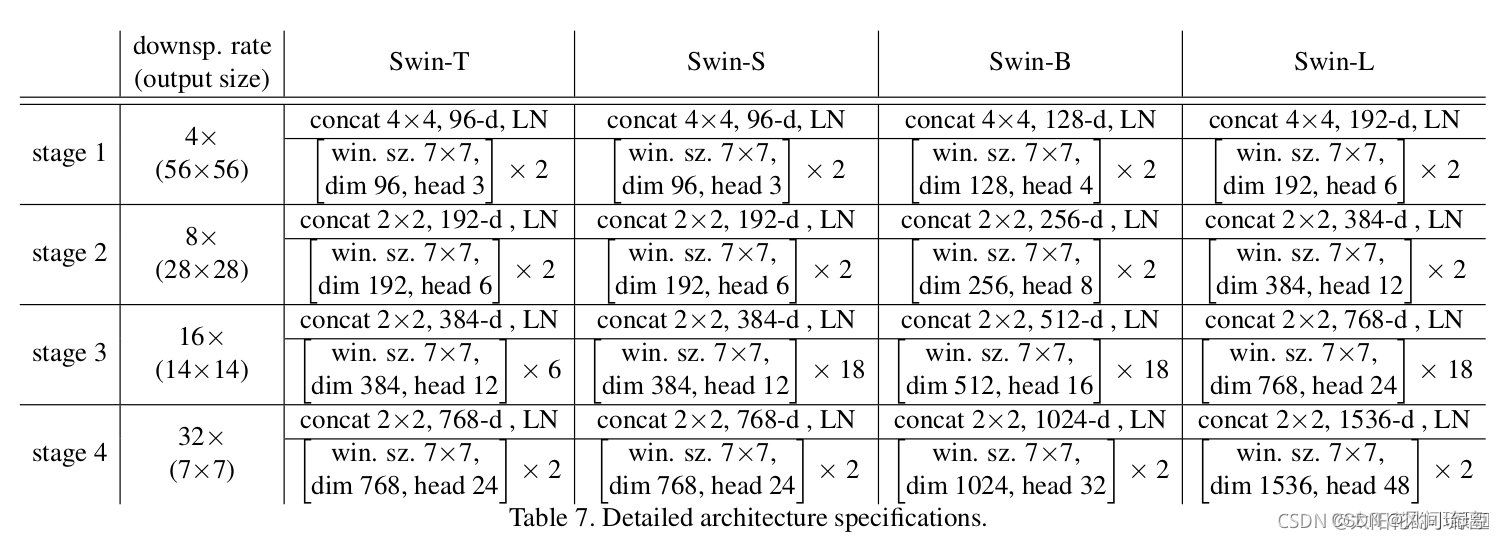
下图给出的关于不同Swin Transformer的配置,T(Tiny),S(Small),B(Base),L(Large):
参数说明:
⋆
\star
⋆ win. sz. 7x7表示使用的窗口(Windows)的大小
⋆
\star
⋆ dim表示feature map的channel深度(或者说token的向量长度)
⋆
\star
⋆ head表示多头注意力模块中head的个数
二、网络实现
1.构建EfficientNetV2网络
2.训练和测试模型
三、实现图像分类
结束语
感谢阅读吾之文章,今已至此次旅程之终站 🛬。
吾望斯文献能供尔以宝贵之信息与知识也 🎉。
学习者之途,若藏于天际之星辰🍥,吾等皆当努力熠熠生辉,持续前行。
然而,如若斯文献有益于尔,何不以三连为礼?点赞、留言、收藏 - 此等皆以证尔对作者之支持与鼓励也 💞。











![红队专题-从零开始VC++远程控制软件RAT-C/S-[1]远控介绍及界面编写](https://img-blog.csdnimg.cn/e074aa9bcfcd41fa951492e75d2df131.png)
![2023年中国滑雪设备行业分析:随着滑雪运动人数增加,产品需求不断提升[图]](https://img-blog.csdnimg.cn/img_convert/6bf7b23166378ec5ef17849e83b7aa11.png)