作者:遐宇、溪恒
本文是 8 月 17 日直播的文字稿整理,文末可观看直播回放。除去文章内容外,还包括针对实际网络问题的实战环节。 容器网络抖动问题发生频率低,时间短,是网络问题中最难定位和解决的问题之一。
不仅如此,对 Kubernetes 集群内的网络状态进行日常的持续性监测,也是集群运维中很重要的一环。KubeSkoop 基于 eBPF 技术,提供了 Pod 粒度的、低开销的、可热插拔的实时网络监测能力,不仅可以满足日常网络监控的需要,也能够在出现网络问题后,通过开启对应的探针,快速定位及解决问题。KubeSkoop 提供了基于 Prometheus 的指标和 Grafana 大盘,同时也提供了基于命令行、基于 Loki 的异常事件透出能力,提供问题现场的详细信息。
本次分享将包括:
- 应用如何收到/发出数据包
- 网络问题排查的难点,传统网络问题排查工具以及传统工具的问题
- 对 KubeSkoop 和网络监测部分(即 KubeSkoop exporter)的简单介绍
- 结合内核中的不同的模块详细介绍 KubeSkoop exporter 的探针、指标和事件
- 在日常监测和异常排查中使用 KubeSkoop exporter 的一般流程
- KubeSkoop exporter 的未来规划。
容器中的应用如何收到/发出数据包?
在网络中,数据是以数据包为单位进行传输的。在 Linux 系统上,数据包需要经过内核中各个模块层层处理,才能够正常地被应用接收,或是被应用发送。
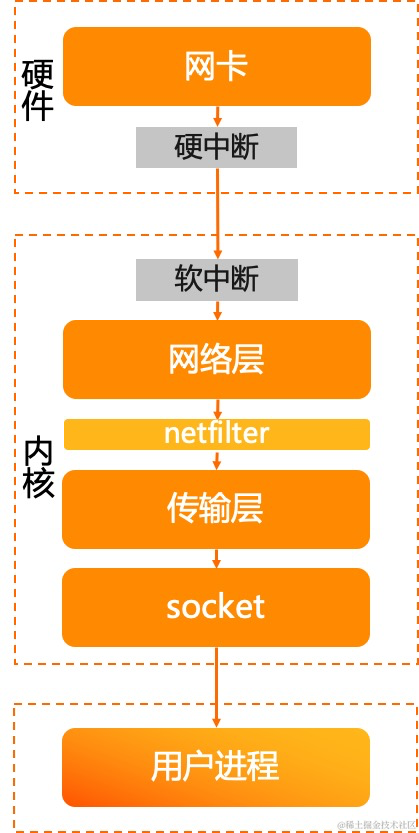
我们先来看接收过程:
- 网卡驱动收取网络报文后,发起中断
- 内核 ksoftirqd 得到调度后,得到数据,进入到协议栈处理
- 报文进入网络层,网络层经过 netfilter 等处理后,进入传输层
- 传输层处理报文后,将报文的 payload 放入 socket 接收队列中,唤醒应用进程,让出 CPU
- 应用进程被调度后,通过系统调用将数据收取的用户态进行处理
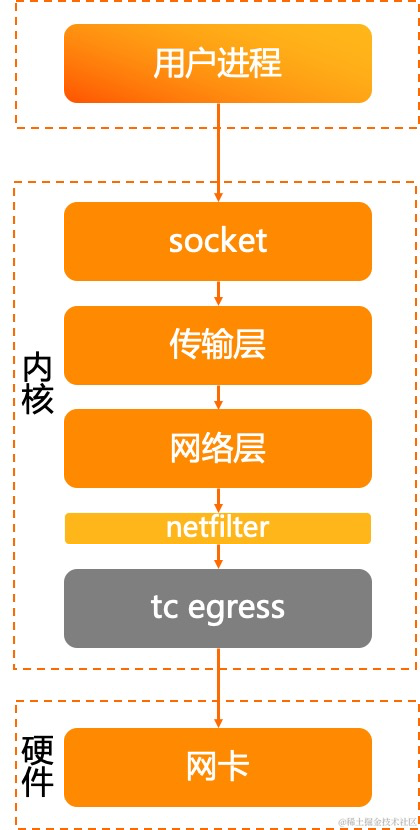
再来看发送过程:
- 应用程序通过系统调用向 socket 发送队列写入数据
- 进入到内核态,socket 调用传输层进行报文发送
- 传输层组装报文,调用网络层发送
- 网络层经过 netfilter 等处理后,进入 tc egress
- tc qdisc 将报文按照顺序调用网卡驱动进行发送
我们在入方向并没有关注到 tc 的处理,但在出方向着重的提了一下,这也是链路中产生丢包异常的常见原因之一。
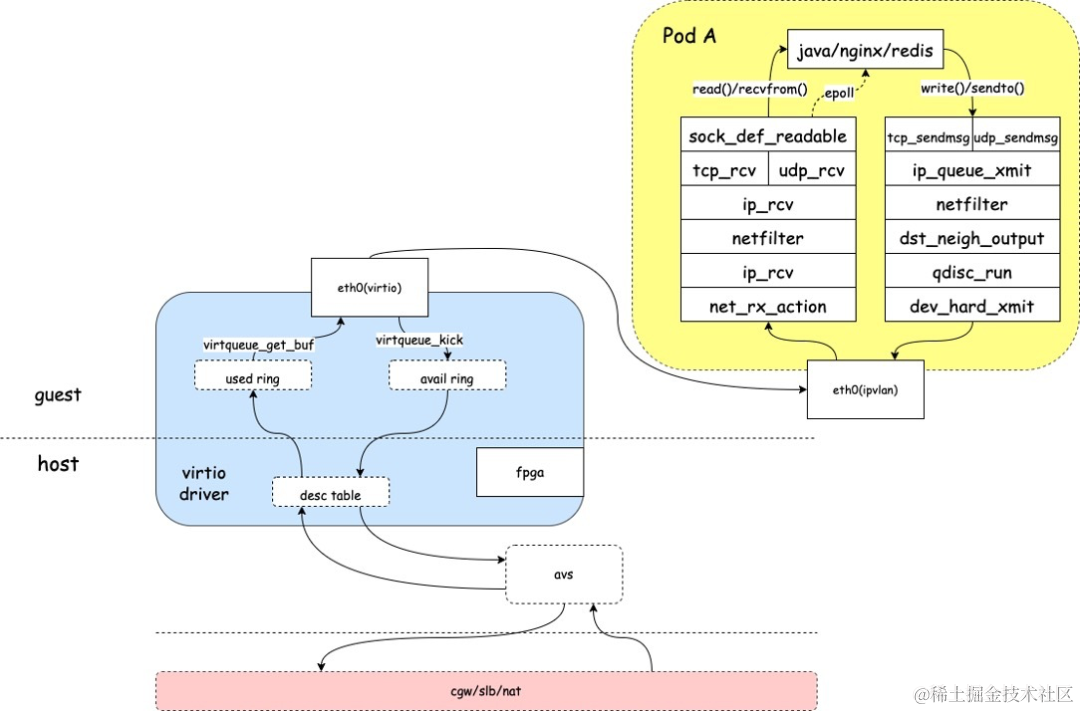
由上面的介绍可以看出,一个包在 Linux 内核中需要经过复杂的处理步骤。内核网络子系统的模块众多,代码量庞大且复杂, 是造成网络问题排查的难点之一;包的接收和发送经过的链路长, 给问题定位带来了相当的难度。同时网络相关系统的参数繁多,配置复杂, 因为某些功能或者参数的限制导致了网络问题,也需要我们花大量的时间去定位;同时,系统的磁盘、调度、业务代码缺陷等,都可能表现为网络问题,需要对系统状态进行全面的观测。
常用网络排查工具
接下来,我们再来介绍一下 Linux 环境下常见网络问题排查工具,以及其背后的实现技术。
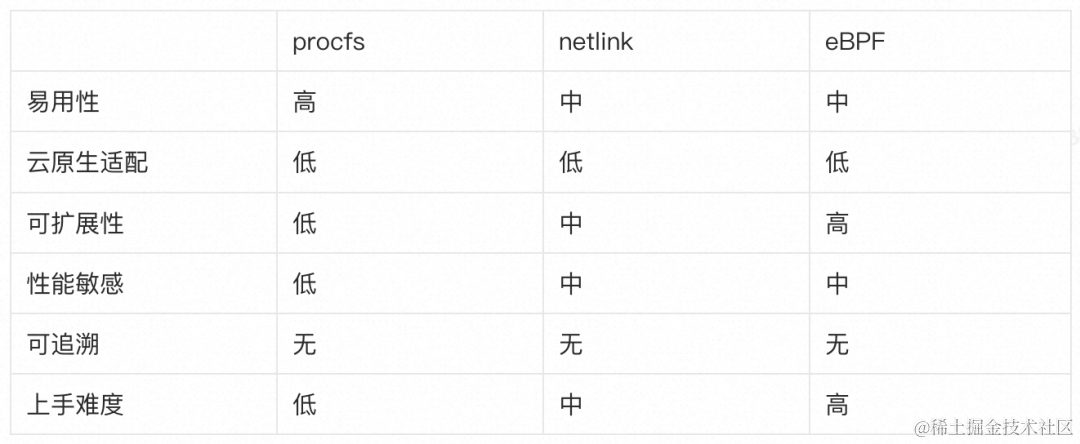
net-tools(netstat 等)
net-tools 所提供的工具,能够用于查看网络统计信息,包括网络当前状态、异常统计计数等。
它的原理是,通过 procfs 中的 /proc/snmp 和 /proc/netstat 文件获取当前的网络状态和异常计数,特点是性能好,开销小,但是它所能提供的信息相对较少,并且不可定制。
procs 是 linux 所提供的虚拟文件系统之一。它能够提供系统的运行信息、进程信息和计数器信息。用户进程通过 write() 或者 read() 系统调用函数,对 procfs 所提供的文件进行访问,如 /proc/net/netstat,或 /proc//net/snmp 等。内核中的 procfs 实现,会将信息通过虚拟文件系统 vfs 返回用户。
和 net-tools 工具包类似的命令还有 nstat、sar、iostat 等。
iproute2(ip、ss 等)
iproute2 工具包中的 ip、ss 工具也提供了查看网络统计信息和网络状态的多种实用工具。但它的原理与 netstat 等工具不同,是基于 netlink 获得信息的。它相比于 net-tools,能够提供更加全面的网络信息,和更好的扩展能力,但是性能相较于通过 procfs 会差一些。
netlink 是 Linux 中一种特殊的 socket 类型,用户程序可以通过标准的 socket API 和内核进行通信。用户程序通过 AF_NETLINK 类型的 socket 进行数据的发送和收取。内核中将会通过 socket 层来处理用户的请求。
与其相似的命令还有 tc、conntrack、ipvsadm 等。
bcc-tools
bcc-tools 提供了多种的内核态观测工具,包括网络、磁盘、调度等方面。它的核心实现是基于 eBPF 计数,有着非常强的扩展性和不错的性能,但是使用门槛相较于上述工具会更高一些。
eBPF 是 Linux 中比较年轻的技术,也是近期社区的热门关注点之一。eBPF 是内核中的一个小型虚拟机,可以动态加载用户自己编写的代码并在内核中运行,同时内核会帮助你校验程序的安全性,确保不会因为自定义的 eBPF 代码导致内核出现工作异常。
在 eBPF 程序加载进内核后,它可以通过 map 来与用户态的程序进行数据的交换。用户进程可以通过用户态的 bpf() 系统调用来获得 map 中的数据,而 eBPF 程序也可以在内核中使用内核 API 来主动更新 map 数据,来完成内核与用户进程之间的交流。与 bcc-tools 中提供的工具相似的,还有 bpftrace、systemtap 等。
传统工具在云原生场景下的问题
上述的工具,通过 Linux 的不同能力提供了丰富的状态信息,帮助我们排查系统中发生的网络问题。但是,在云原生容器的复杂场景下,传统工具也有着一些局限性:
- 大部分工具以本机/网络命名空间为维度进行观测,难以针对某个特定容器
- 对于复杂拓扑的观测,没有充足的内核问题排查经验,可能会难以下手
- 对于偶发问题,很难实时抓到现场使用这些工具
- 这些工具提供了大量的信息,但是信息之间的关联并不明显
- 一些观测工具自己本身同时也会带来性能方面的问题
KubeSkoop
基于以上 Linux 网络处理的复杂链路、传统工具在云原生容器场景下的缺陷。基于云原生环境的网络观测要求,KubeSkoop 项目应运而生。
在介绍 KubeSkoop 的网络监测部分,也就是 KubeSkoop exporter 之前,我们先来回顾一下 KubeSkoop 项目的全貌。
KubeSkoop 是一个容器网络问题的自动诊断系统。它针对了网络持续不通问题,如 DNS 解析异常,service 无法访问等场景,提供了一键诊断的能力;针对网络抖动问题,如延迟增高、偶发 reset、偶发丢包等场景,提供了实时监测的能力。KubeSkoop 提供了全链路一键诊断、网络站延迟分析和网络异常事件识别回溯的能力。
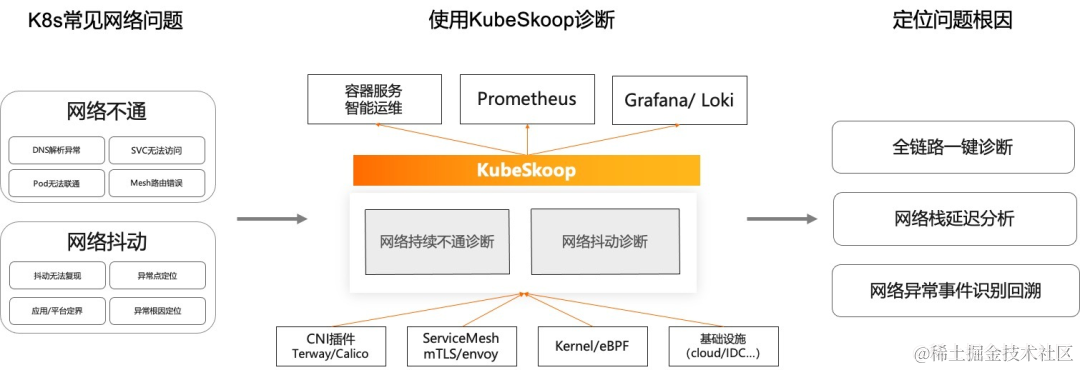
本次分享中,我们的重点在 KubeSkoop 的网络监测能力部分。
KubeSkoop exporter 基于 eBPF、procfs、netlink 等多种数据源的容器网络异常监控,提供了 Pod 级别的网络监控能力,能够提供网络监控指标、网络异常事件记录和实时事件流,覆盖驱动、netfilter、TCP 等完整协议栈和几十种异常场景,与云上 Prometheus、Loki 等可观测体系对接。
KubeSkoop exporter 提供了针对内核中不同位置采集信息的探针,支持探针的热插拔和按需加载的能力。开启的探针会以 Prometheus 指标或是异常事件的形式透出所采集到的统计信息或网络异常。
探针、指标和事件
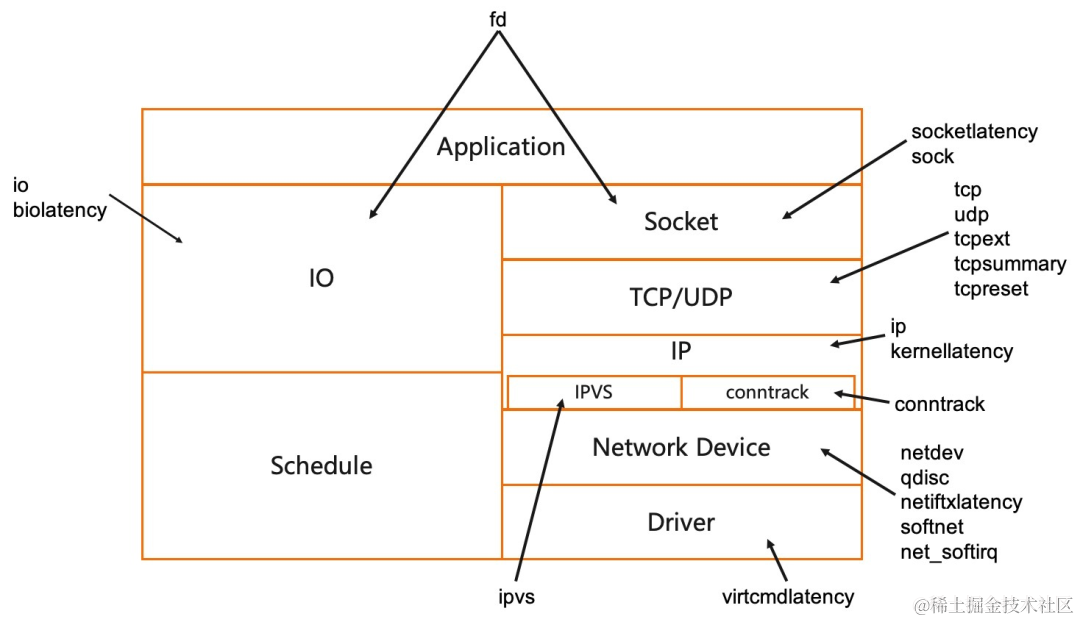
针对内核中的不同模块,KubeSkoop exporter 提供了多种探针,适用于不同的观测需求和不同的网络问题场景。
指标(metrics)是对网络中关键信息,以 Pod 维度汇总的统计数据,如连接数、重传数等。这些信息能够为用户提供网络状态随时间的变化信息,能够更好的帮助用户理解目前容器中的网络状况。
事件会在网络异常发生的时候产生,如丢包、TCP reset、数据处理出现延迟等。相比于指标,事件能够提供更多有关于问题现场的信息,如出现丢包的具体位置、出现延迟的详细统计等。事件更多用来针对某一个具体的网络异常,来进行更加深入的观测和问题定位。
探针列表
下面将会介绍目前 KubeSkoop 所提供的探针,说明作用、适用场景、开销以及它所提供的指标/事件。
关于探针、指标和事件的说明,也可以访问 KubeSkoop 文档 https://kubeskoop.io 获取更多信息。
socketlatency
socketlatency 探针通过追踪内核内 socket 相关以及上下游的符号,获得用户态从 socket 数据准备好到读取数据,以及 socket 接收到数据,到传递到 TCP 层进行处理的延迟情况。该探针一般主要关注在数据到达 socket 层时,用户态数据读取的延迟情况。探针提供了 socket 读取/写入延迟的相关指标以及事件。
开销: 高
适用场景: 怀疑进程由于调度、处理不及时等原因,读取数据慢的情况
常见问题: 由于容器进程 CPU 超限导致的网络抖动
sock
sock 探针的数据来源于 /proc/net/sockstat 文件,提供了 Pod 内部对于 socket 的统计指标,采集了 TCP 处于不同状态 (inuse、orphan、tw) 的 socket 数量,以及内存的使用情况。可能由于应用逻辑、系统参数配置等问题,导致 socket、tcpmem 耗尽等情况,产生连接失败的情况,影响并发性能。该探针开销极小,因此也可以做为日常状态中连接大体状态的观测。
开销: 低
适用场景: 日常观测连接状态,socket 泄漏、reuse、socket 内存占用过高等情况
常见问题: 由于 socket 泄漏导致的内存占用持续增长;连接过多、reuse、tcpmem 耗尽等导致的建连失败/偶发RST情况
tcp/udp/tcpext
通过 /proc/net/netstat 和 /proc/net/snmp 两个文件采集的关于 TCP/UDP 协议层的基础信息采集,如 TCP 新建连接/成功建立连接的数量,重传报文数,UDP 协议错误计数等。tcpext 同时也提供了 TCP 更加细粒度的指标,如发送 RST 报文的统计等。该指针在 TCP/UDP 连接相关的异常问题中(如负载不均、连接建立失败、异常连接关闭)等提供关键信息,同时作为基于 procfs 采集信息的探针,可以用于日常对流量状态的观测。
开销: 低
适用场景: 日常对 TCP 和 UDP 相关状态的观测。出现 TCP 连接异常重传、连接建立失败、reset 报文等情况的信息采集,出现 DNS 解析失败等情况的信息采集
常见问题: 应用连接出现异常关闭;由于重传导致的延时抖动
tcpsummary
tcpsummary 探针通过与内核进行 netlink 消息 (SOCK_DIAG_BY_FAMILY) 的通信,获取到 Pod 内的所有 TCP 连接信息,并聚合 TCP 连接状态和发送/接受队列状态产生指标。该探针需要聚合所有连接信息得到最终统计结果,因此在连接较多的高并发场景下,可能会带来较大的开销。
开销: 中
适用场景: 偶发延迟、连接失败等场景下提供 TCP 连接的状态信息
常见问题: 用户态进程hang住,接收队列堆积导致的丢包
tcpreset
tcpreset 探针通过在内核中追踪 tcp_v4_send_reset 和 tcp_send_active_reset 的调用,在 TCP 连接中发送 RST 报文时,记录 socket 信息和状态,产生事件。在 tcp_receive_reset 被调用,即收到 RST 报文时,也会记录以上信息。探针基于内核中冷路径的追踪,因此开销较低。该探针只产生事件,建议在出现 tcp reset 问题时再开启。
开销: 低
适用场景: TCP 连接被异常 reset 时,追踪内核中的 reset 位置
常见问题: 由于客户端与服务端两端超时时间设置问题,导致的偶发连接 reset
ip
ip 探针是从 /proc/net/snmp 文件中采集到的 IP 相关的信息指标。包括由于路由目的地址不可达以及数据包长度小于 IP 头中表示长度两种情况的计数器,能够对由于上述两种原因出现丢包的情况做出判断。探针开销极小,也建议在日常监测场景下打开该探针。
开销: 低
适用场景: 日常对 IP 相关状态的观测。出现丢包等问题时
常见问题: 由于节点上路由设置不正确,目的不可达导致的丢包
kernellatency
kernellatency 对报文接收和报文发送全过程的多个关键点进行时间记录,计算报文在内核中的处理延迟。指针提供了接收和发送数据包处理出现延迟的指标,同时也提供了事件,包括了报文五元组和内核中各个点位之间的处理时间。本探针涉及所有报文的时间统计和大量的 map 查询操作,开销较高,因此建议仅在相关问题发生时启用该探针。
开销: 高
适用场景: 连接超时,网络抖动问题
常见问题: 由于 iptables 规则过多导致的内核处理延迟高
ipvs
ipvs 探针采集了 /proc/net/ip_vs_stats 文件中的信息,提供了 IPVS 相关的统计计数。IPVS 是内核提供的 4 层负载均衡能力,在 kube-proxy 的 IPVS 模式中被使用。探针提供的指标主要包括 IPVS 的连接数、出/如数据包数和出/入数据字节数。该探针适用于日常监测中对 IPVS 统计信息的观测,也对访问 service IP 出现网络抖动或连接建立失败等情况起辅助参考作用。
开销: 低
适用场景: 日常对 IPVS 相关状态的观测
常见问题: 无
conntrack
conntrack 探针通过 netlink,提供用于追踪 conntrack 模块的统计数据。conntrack 模块是基于内核提供的 netfilter 框架,对网络层以上的数据流量进行连接追踪,包括每条连接的创建时间,报文数,字节数等数据,并提供根据信息的匹配进行 nat 等上层操作的机制。探针的指标中提供了当前 conntrack 中处于各个状态的条目的统计计数,以及 conntrack 当前条目和条目上限的数量。由于探针需要遍历所有 conntrack 条目,因此在高并发场景下会有较大开销。
开销: 高
适用场景: 连接建立失败、丢包,conntrack 串流等问题
常见问题: 由于 conntrack 溢出导致的连接建立失败、丢包
netdev
netdev 探针通过采集 /proc/net/dev 文件,提供了网络设备层面的统计指标,包括发送/接收字节数、错误数、数据包数、丢包数。探针通常用于宏观的发现网络问题,在偶发 TCP 握手失败等场景有价值。探针开销极小,建议日常开启。
开销: 低
适用场景: 日常监控。网络抖动,设备底层丢包等情况
常见问题: 网络设备丢包导致的网络抖动或建连失败
qdisc
qdisc 探针通过 netlink,提供了 tc qidsc 的统计指标,包括 qdisc 上的经过的流量统计,以及 qdisc 队列状态的统计计数。tc qdisc 是 LInux 内核中用于对网络设备进行流量控制的模块,qdisc 会根据调度规则控制数据包的发送。网卡上的 qdisc 规则可能会导致数据包被丢弃,或是延迟高情况发生。探针开销较低,建议日常开启。
开销: 低
适用场景: 日常监控。网络抖动丢包等情况
常见问题: 由于 qdisc 队列超限导致丢包,产生网络抖动
netiftxlatency
对内核中网络设备处理部分的关键点位进行追踪并计算延迟,主要集中在 qdisc 对报文的处理时间,以及底层设备对外发送的时间,提供了两部分延迟超过一定阈值的报文数量统计,以及包含报文五元组信息的异常事件。探针会对所有报文进行延迟的计算,因此开销较高,建议出现延迟问题时再开启。
开销: 高
适用场景: 连接超时,网络抖动等情况
常见问题: 底层网络抖动导致延迟升高
softnet
softnet 探针的数据来源于内核的 proc 文件接口 /proc/net/softnet_stat,以 Pod 级别进行指标的聚合。softnet 探针按照 cpu 的方式对网卡收取的数据包进行整合,他表征着数据包从网卡设备进入 Linux 内核的软中断处理过程的状态,对外提供了接收和处理数据包的总览数据。探针对出现爱你节点级别的网络问题时能够起到辅助作用,开销极小,建议开启。
开销: 低
适用场景: 日常监控。出现节点级别的网络问题时能够提供帮助
常见问题: 无
net_softirq
net_softirq 探针通过内核态程序,采集了与网络相关的两种中断 (netif_tx、netif_rx) 的调度和执行时长,包括软中断发起到开始执行,和软中断开始执行到执行完成的耗时,并将超过一定阈值的报文以指标或者事件的形式进行统计透出。
开销: 高
适用场景: 出现偶发延迟,网络抖动常见问题: cpu 争抢导致的软中断调度延迟,产生网络抖动
virtcmdlatency
virtcmdlat 探针通过对内核态调用虚拟化指定的方法 (virtnet_send_command) 的执行时间进行计算,来获取虚拟机执行虚拟化调用的耗时,提供了出现延迟次数的指标和事件。virtio 是比较常见的虚拟化网络方案,由于其半虚拟化的特性,虚拟机对网卡设备驱动的操作可能会因为底层物理机的阻塞而产生延迟。探针开销较高,建议怀疑因宿主机原因出现网络抖动时再将其开启。
开销: 高
适用场景: 出现偶发延迟,网络抖动
常见问题: 底层物理机资源争抢导致的网络抖动
fd
fd 探针通过对单个 Pod 内所有进程持有的句柄进行采集,获取 Pod 中进程打开的文件描述符及 socket 类型的文件描述符的数量。探针需要遍历进程的所有 fd,开销较高。
开销: 高
适用场景: fd 泄漏,socket 泄漏等问题
常见问题: socket 未被用户态程序关闭,产生泄漏导致 TCP OOM,进而导致网络抖动
io
io 探针的数据来源于 /proc/io 提供的文件接口,用于表征单个 Pod 进行文件系统io的速率与总量。探针提供的指标包括文件系统读写操作的次数以及字节数。部分网络问题可能是由于同节点上其它进行进行大量 IO,导致用户进程响应慢产生的,在这种情况下,可以按需开启该探针以进行验证,也可以用于日常对 Pod IO 的监测。
开销: 低
适用场景: 由于用户进程响应慢导致的延迟增长,重传升高
常见问题: 大量文件读写导致的网络抖动问题
biolatency
biolatency 追踪了内核中块设备读取和写入调用的执行时间,并将超过阈值的执行以异常事件的形式透出。设备 IO 延迟增加,可能会导致用户进程的业务处理受到影响,进而产生网络抖动问题,在怀疑因为 IO 产生网络异常时,可以开启此探针。探针需要对所有块设备的读写操作进行统计,开销中等,建议按需开启。
开销: 中
适用场景: IO 读写慢导致的网络抖动、延迟升高等
常见问题: 由于块设备读写延迟产生的网络抖动
如何使用 KubeSkoop exporter
KubeSkoop exporter 适用于日常监控以及网络异常问题发生时的排查两种场景。这两种场景对 KubeSkoop exporter 的使用方式有所不同,下面讲简单介绍。
日常监控

在日常监控中,推荐使用 Prometheus 收集 KubeSkoop exporter 所透出的指标,以及可选的通过 Loki 来收集异常事件的日志。收集到的指标和日志,可以透过 Grafana 大盘进行展示。KubeSkoo exporter 也提供了现成的 Grafana 大盘,可以直接使用。
在配置好指标收集和大盘后,还需要对 KubeSkoop exporter 本身进行一些配置。我们在日常的监控中,为了对业务的流量造成影响,我们可以选择性开启一些低开销的探针,如基于 porcfs 的大部分探针,和部分基于 netlink、eBPF 的低开销探针。如果使用了 Loki,还需要同时配置 Loki 的服务地址,并且将其启用。在这些准备工作结束之后,我们就可以在大盘上看到所启用的指标和事件情况。
在日常的监控之中,需要关注一些敏感的指标的异常。比如说新建连接数的异常突增,或者是连接建立失败数上涨,reset 报文增加等。针对这些明显能够代表异常的指标,我们也可以通过配置告警的形式,能够在出现异常时,更快的介入去进行问题的排查和恢复。
异常问题排查

当我们通过日常监控、业务告警、错误日志等方面发现可能存在网络异常后,需要先对网络异常问题的类型进行一个简单的归类,如 TCP 建连失败、网络延迟抖动等。通过简单的归类,能够更好的帮助我们确立问题的排查方向。
根据问题类型不同,我们就可以根据问题类型,开启适用于该问题的探针。比如出现了网络延迟抖动的问题,我们就可以开启 socketlatency 关注应用从 socket 读数据延迟的情况,或是开启 kernellatency 追踪内核中延迟的情况。
开启这些探针后,我们就可以通过已经配置好的 Grafana 来观测探针暴露出的指标或是事件结果。同时,异常事件也可以直接通过 Pod 日志,或是 exporter 容器中的 inspector 命令来直接观测。如果我们这次开启的探针结果没有异常,或是无法针对问题根因做出结论,可以考虑开启其它方面的探针,继续辅助我们进行问题的定位。
根据这些所得到的指标和异常事件,我们最终会定位到问题的根因。问题的根因可能出自系统中的某一些参数的调整,或者是出现在用户的程序之中。我们根据定位到的根因就可以进行这些系统参数调整或者是程序代码的优化了。
未来规划
KubeSkoop 已于上周发布第一个正式版本 0.1.0,主要改进点包括:
诊断
- 支持 k3s 集群
- 支持节点 host interface 自动选择
- 修复若干诊断错误
网络监测
- 支持大部分主流操作系统的 btf 自动发现
- 优化 exporter 性能,CPU 开销大幅下降
- 支持探针的热加载
- 初步支持 flow 级别指标采集
以下是我们近几个月的开发规划,包括:
- KubeSkoop exporter 代码重构,增强扩展性与稳定性
- 全面支持 flow 级别的 metrics 展示,快速定位问题连接
- 支持事件透出到本地文件 /ELK 等
- 更加友好的 UI,支持集群内流量拓扑全览
结语
本次分享是对 KubeSkoop 项目的网络监测能力的重点介绍,主要介绍了 KubeSkoop exporter 所拥有的指标,以及日常使用和排查问题的一般方法,能够帮助您更好的使用本项目,对网络进行观测和问题排查。
KubeSkoop 项目仍处于早期阶段,如果您在使用过程中遇到了任何问题,可以在 Github 项目主页 [ 1] 提出 issue,或是加入钉钉用户群,与我们进行交流。同时,也期待您参与项目贡献,一起推动项目发展!(群号: 26720020148)
相关链接:
[1] Github 项目主页https://github.com/alibaba/kubeskoop