延迟队列在实际项目中有非常多的应用场景,最常见的比如订单未支付,超时取消订单,在创建订单的时候发送一条延迟消息,达到延迟时间之后消费者收到消息,如果订单没有支付的话,那么就取消订单。
那么,今天我们需要来谈的问题就是RabbitMQ、RocketMQ、Kafka中分别是怎么实现延时队列的,以及他们对应的实现原理是什么?
RabbitMQ
RabbitMQ本身并不存在延迟队列的概念,在 RabbitMQ 中是通过 DLX 死信交换机和 TTL 消息过期来实现延迟队列的。
TTL(Time to Live)过期时间
有两种方式可以设置 TTL。
-
1. 通过队列属性设置,这样的话队列中的所有消息都会拥有相同的过期时间
-
2. 对消息单独设置过期时间,这样每条消息的过期时间都可以不同
那么如果同时设置呢?这样将会以两个时间中较小的值为准。
针对队列的方式通过参数x-message-ttl来设置。
Map<String, Object> args = new HashMap<String, Object>();
args.put("x-message-ttl", 6000);
channel.queueDeclare(queueName, durable, exclusive, autoDelete, args);针对消息的方式通过setExpiration来设置。
AMQP.BasicProperties properties = new AMQP.BasicProperties();
Properties.setDeliveryMode(2);
properties.setExpiration("60000");
channel.basicPublish(exchangeName, routingKey, mandatory, properties, "message".getBytes());DLX(Dead Letter Exchange)死信交换机
一个消息要成为死信消息有 3 种情况:
-
1. 消息被拒绝,比如调用
reject方法,并且需要设置requeue为false -
2. 消息过期
-
3. 队列达到最大长度
可以通过参数dead-letter-exchange设置死信交换机,也可以通过参数dead-letter- exchange指定 RoutingKey(未指定则使用原队列的 RoutingKey)。
Map<String, Object> args = new HashMap<String, Object>();
args.put("x-dead-letter-exchange", "exchange.dlx");
args.put("x-dead-letter-routing-key", "routingkey");
channel.queueDeclare(queueName, durable, exclusive, autoDelete, args);原理
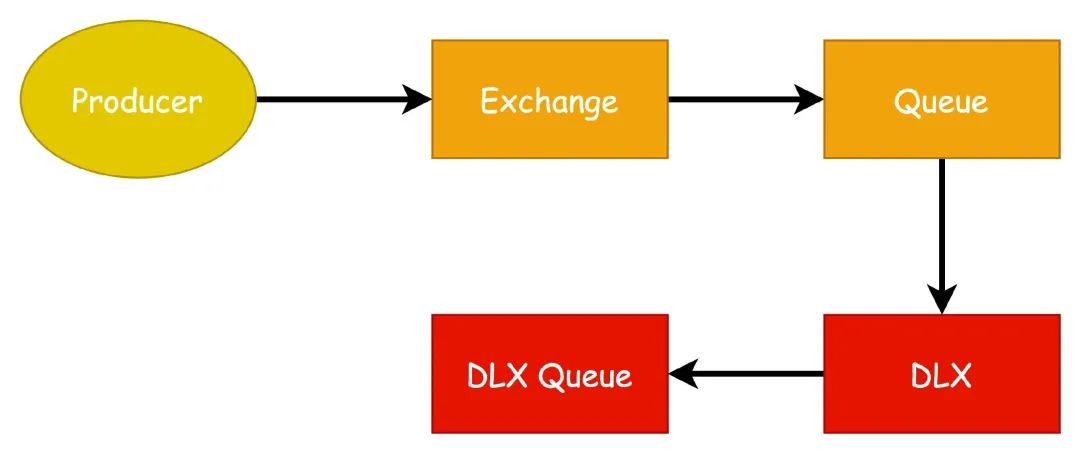
当我们对消息设置了 TTL 和 DLX 之后,当消息正常发送,通过 Exchange 到达 Queue 之后,由于设置了 TTL 过期时间,并且消息没有被消费(订阅的是死信队列),达到过期时间之后,消息就转移到与之绑定的 DLX 死信队列之中。
这样的话,就相当于通过 DLX 和 TTL 间接实现了延迟消息的功能,实际使用中我们可以根据不同的延迟级别绑定设置不同延迟时间的队列来达到实现不同延迟时间的效果。
RocketMQ
RocketMQ 和 RabbitMQ 不同,它本身就有延迟队列的功能,但是开源版本只能支持固定延迟时间的消息,不支持任意时间精度的消息(这个好像只有阿里云版本的可以)。
他的默认时间间隔分为 18 个级别,基本上也能满足大部分场景的需要了。
默认延迟级别:1s、 5s、 10s、 30s、 1m、 2m、 3m、 4m、 5m、 6m、 7m、 8m、 9m、 10m、 20m、 30m、 1h、 2h。
使用起来也非常的简单,直接通过setDelayTimeLevel设置延迟级别即可。
setDelayTimeLevel(level)原理
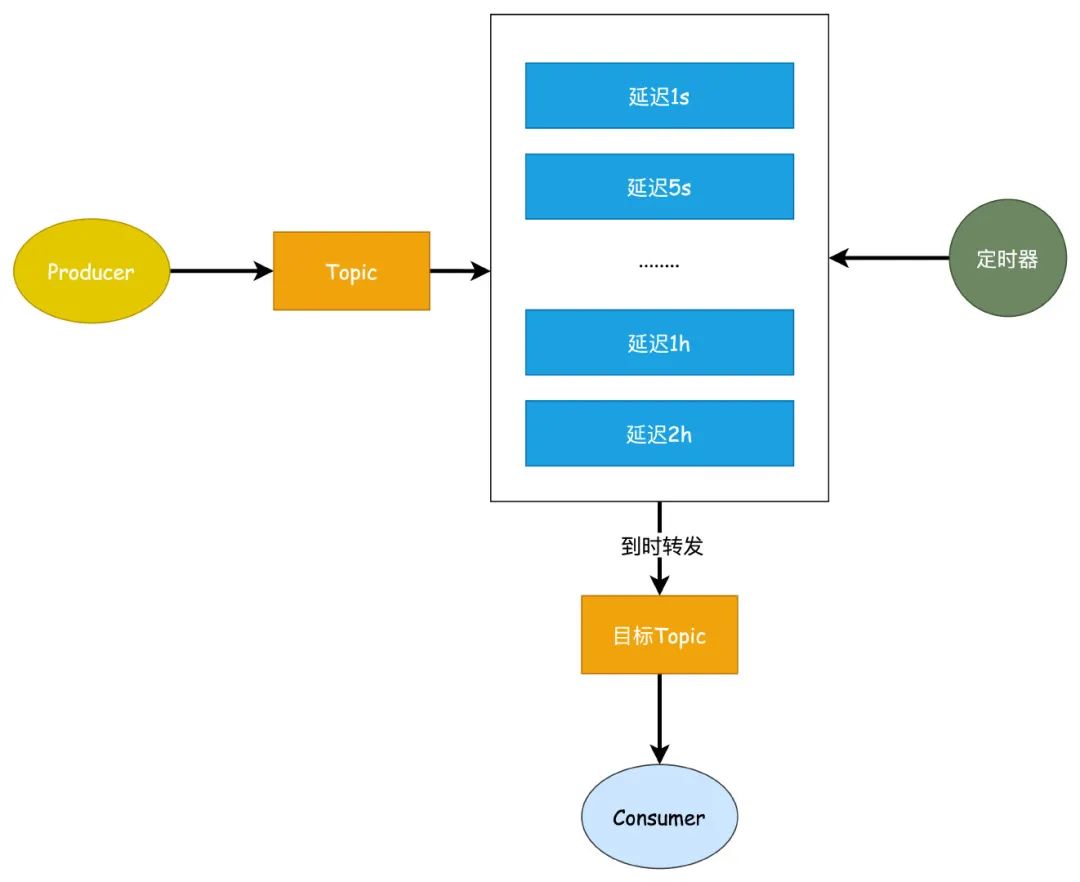
实现原理说起来比较简单,Broker 会根据不同的延迟级别创建出多个不同级别的队列,当我们发送延迟消息的时候,根据不同的延迟级别发送到不同的队列中,同时在 Broker 内部通过一个定时器去轮询这些队列(RocketMQ 会为每个延迟级别分别创建一个定时任务),如果消息达到发送时间,那么就直接把消息发送到指 topic 队列中。
RocketMQ 这种实现方式是放在服务端去做的,同时有个好处就是相同延迟时间的消息是可以保证有序性的。
谈到这里就顺便提一下关于消息消费重试的原理,这个本质上来说其实是一样的,对于消费失败需要重试的消息实际上都会被丢到延迟队列的 topic 里,到期后再转发到真正的 topic 中。
Kafka
对于 Kafka 来说,原生并不支持延迟队列的功能,需要我们手动去实现,这里我根据 RocketMQ 的设计提供一个实现思路。
这个设计,我们也不支持任意时间精度的延迟消息,只支持固定级别的延迟,因为对于大部分延迟消息的场景来说足够使用了。
只创建一个 topic,但是针对该 topic 创建 18 个 partition,每个 partition 对应不同的延迟级别,这样做和 RocketMQ 一样有个好处就是能达到相同延迟时间的消息达到有序性。
原理
-
• 首先创建一个单独针对延迟队列的 topic,同时创建 18 个 partition 针对不同的延迟级别
-
• 发送消息的时候根据延迟参数发送到延迟 topic 对应的 partition,对应的
key为延迟时间,同时把原 topic 保存到 header 中
ProducerRecord<Object, Object> producerRecord = new ProducerRecord<>("delay_topic", delayPartition, delayTime, data);
producerRecord.headers().add("origin_topic", topic.getBytes(StandardCharsets.UTF_8));-
• 内嵌的
consumer单独设置一个ConsumerGroup去消费延迟 topic 消息,消费到消息之后如果没有达到延迟时间那么就进行pause,然后seek到当前ConsumerRecord的offset位置,同时使用定时器去轮询延迟的TopicPartition,达到延迟时间之后进行resume -
• 如果达到了延迟时间,那么就获取到
header中的真实 topic ,直接转发
这里为什么要进行pause和resume呢?因为如果不这样的话,如果超时未消费达到max.poll.interval.ms 最大时间(默认300s),那么将会触发 Rebalance。









![[洛谷]P1996 约瑟夫问题](https://img-blog.csdnimg.cn/0c9a985cb9804a8e8c43c9db0fd7b693.png)





![[力扣c++实现]85. 最大矩形](https://img-blog.csdnimg.cn/071ec42ac0ca450a8b114e8fc44087e2.png#pic_center)
