数据库高级 I
双向链表
-
什么是双向链表
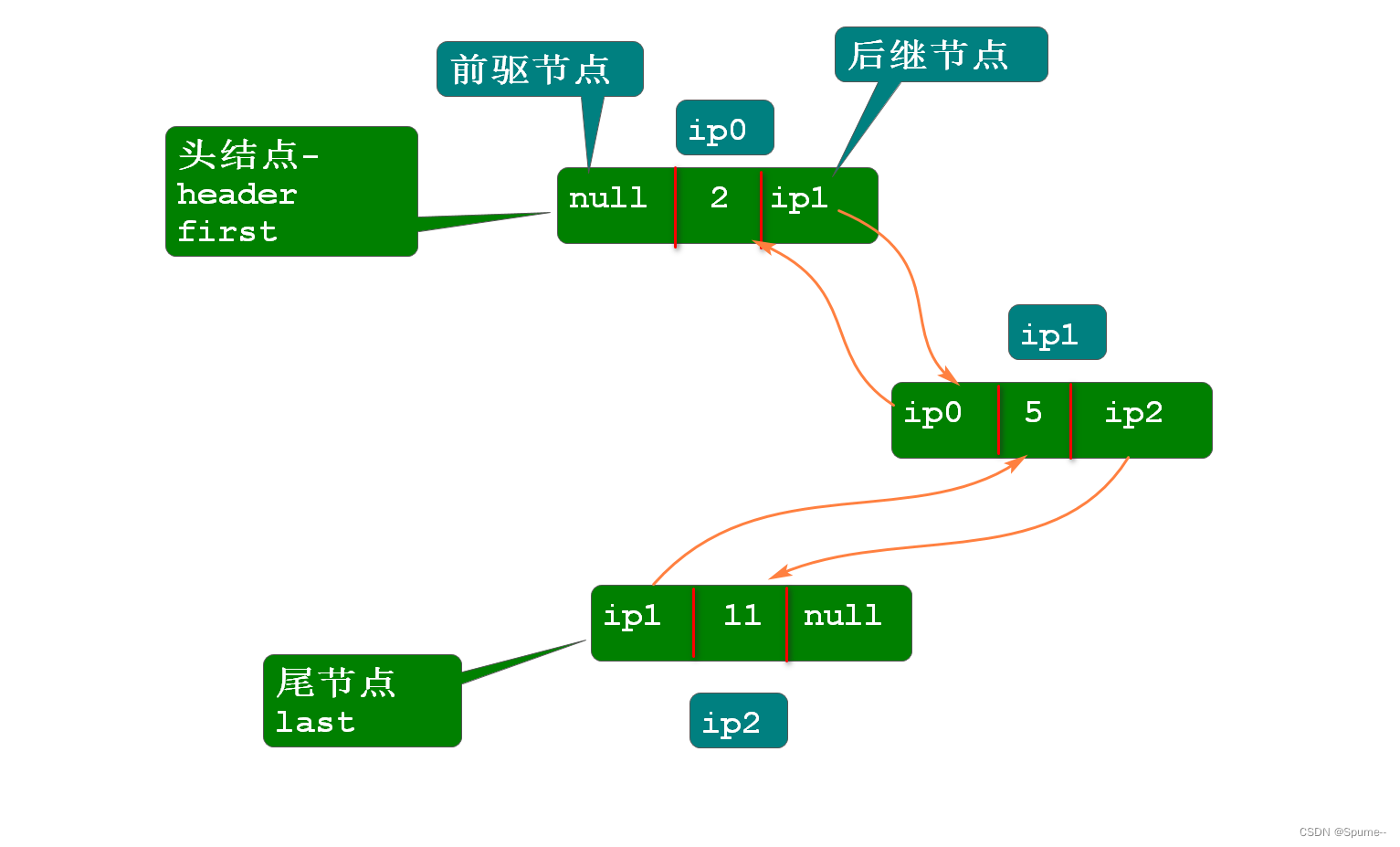
双向链表是一种数据结构,由若干个节点构成,其中每个节点均由三部分构成,分别是前驱节点,元素,后继节点.双向链表中的节点在内存中是游离状态存在的.
-
双向链表的应用:LinkedList
双向链表中的元素部分保存的都是对象,实际上保存的是元素对象的地址. -
对双向链表的操作
-
添加元素
add(E) -- 在链表尾部添加元素 将元素封装到节点中,创建新节点,让新节点和前一个节点建立双向链表的关系. add(int index,E e) -- 在指定位置插入元素 其过程实际上就是断开链,重新构建链的过程 -
删除元素
remove(int index)-- 删除指定位置的元素 其过程实际上依然是断开链,重新构建链的过程 -
查询元素
get (int index) - E 查询方式:对半查找 若查找的位置小于链表长度的一半,则从头结点开始顺序查找;否则,从尾结点开始逆序查找,这样做可以提高查询效率.注意点:双向链表中没有下标,index表示的是节点从头结点开始的顺序位置.index并不是双向链表中的属性
-
修改元素
set(int index,E e) -- 将新元素替换指定位置的元素 -
面试题相关:
- LinkedList在JDK1.8前后数据结构是不同的
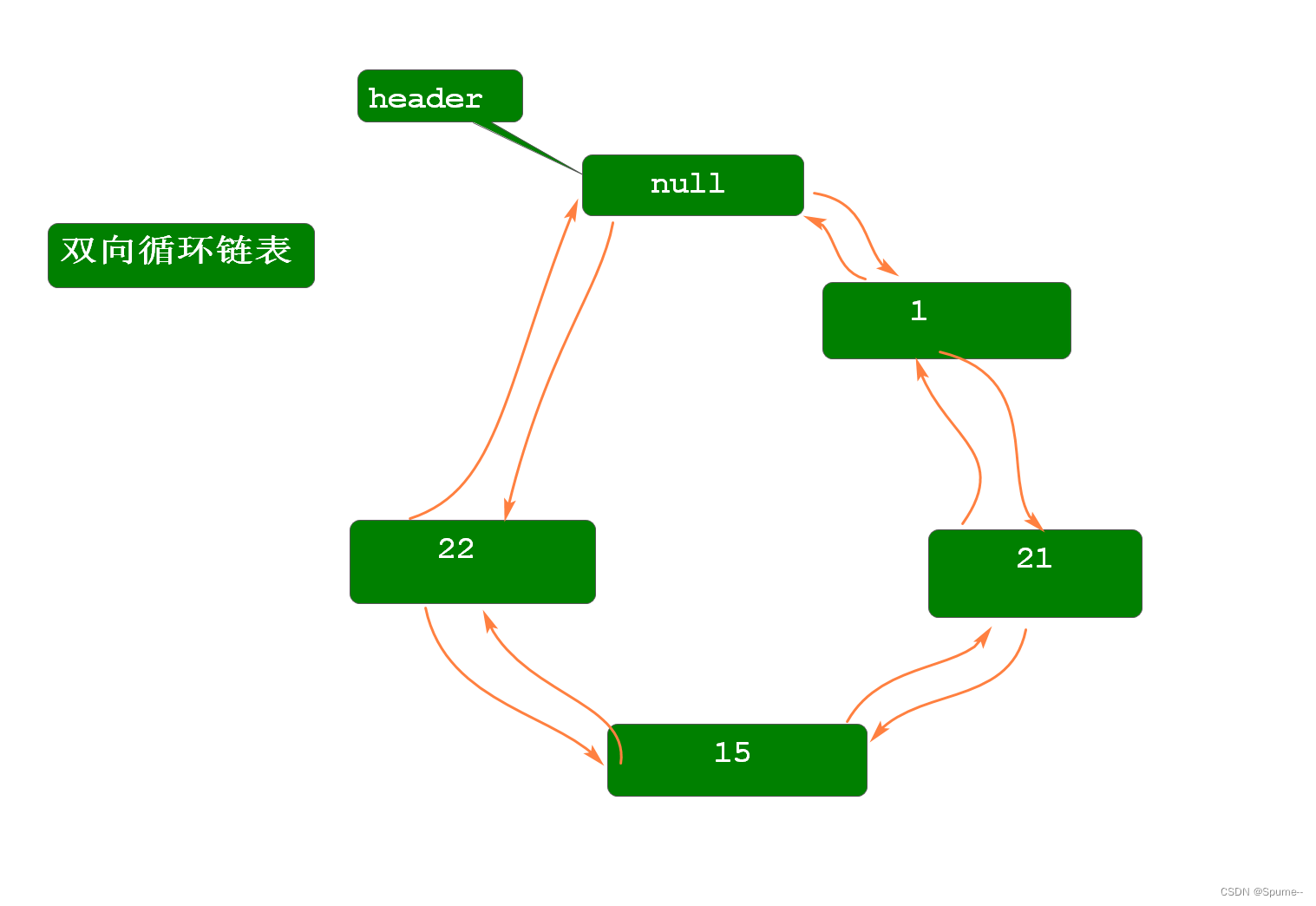
从JDK1.8开始,LinkedList的数据结构为双向链表 在JDK1.8之前,LinkedList的数据结构是双向循环链表.(头尾相接) 双向循环链表的查找过程与双向链表相同,均为: 1. 判断查找元素位置与链表长度一半的关系: 小于,则从header开始顺序查找 否则,则从header开始逆序查找
-
-
-
ArrayList和LinkedList的区别
1. ArrayList底层是数组实现的,LinkedList底层是双向链表,二者的数据结构是不同的. 2. 因为数据结构不同,所以最终的性能是不同的. 查询元素: ArrayList是根据下标查找元素,查询效率非常高,时间复杂度为O(1) LinkedList中若查找头部/尾部的元素,其查询效率还是比较高的,但是若查找偏中间位置的元素,其查询效率是比较低下的. 增删元素: ArrayList:若在尾部添加增删元素,此时性能可能会很高,在头部和中间位置进行增删操作,其效率都不是很高. LinedList:若在头尾部分增删元素,此时性能很高,但是若在偏中间位置进行增删元素,此时性能不高的(因为增删,会先查询指定位置的节点,查询效率是低下的) 整体而言: ArrayList查询性能是高于LinkedList的,但是若LinkedList进行头尾查询,此时效率也是非常高的. 若进行的是偏头部和尾部的增删操作,选择LinkedList;而若对其他位置进行增删,此时ArrayList和LinkedList的效率是差不多的. 整体来看,ArrayList查询方面性能更好,增删方面,除了头尾增删,其他增删和LinkedList差不多,所以经常使用ArrayList. 面试标准回答:ArrayList查询性能更高,LinkedList进行头尾增删,性能很高,除此之外,其他增删,ArrayList和LinkedList差不多.
-
递归 – recursion
-
定义
递归是一种思想,应用在编程中体现为方法调用方法本身. -
案例: 实现求某个数的阶乘
1! = 1 2! = 2*1 2*1! 3! = 3*2*1 3*2! 4! = 4*3*2*1 4*3! 5! = 5*4*3*2*1 5*4! //f方法用于求出某个数的阶乘 long f(int n){ if(n==1) return 1; return n*f(n-1); }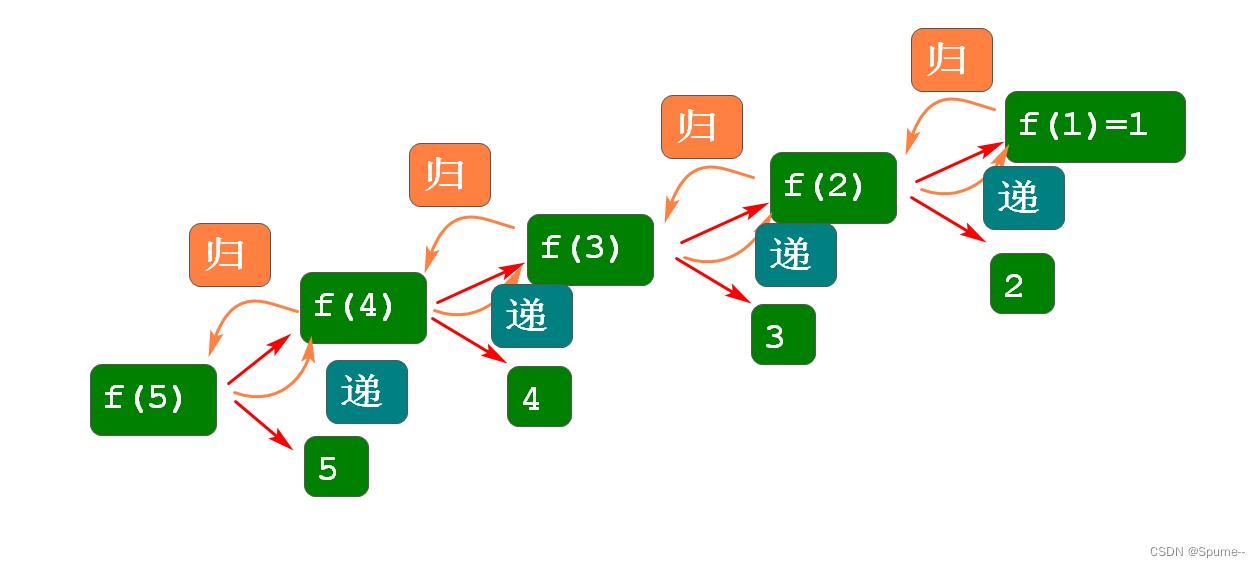
-
递归经典案例:
斐波那契数列(Fibonacci)是这样一组数列: 1 1 2 3 5 8 13 21 34 55..... 第一位第二位为1,从第三位开始,每一位的值等于前两位之和.-
求出斐波那契数列中第20个位置的值是多少
public int f(int pos){ if(pos==1 || pos==2) return 1; return f(pos-1)+f(pos-2); } -
将斐波那契数列前20个数字打印输出
for (int i=1;i<=20;i++){ int result = f(i); System.out.print(result+" "); }
-
-
递归注意点:
1. 递归必须有出口,否则会栈内存溢出(SOF)--StackOverflowError 2. 递归是有深度,若深度太深,可能会造成SOF 栈内存回顾: 用法: 当调用某个方法时,会在栈中为这个方法分配属于这个方法的栈帧区域,某个方法的栈帧中保存这个方法中的所有局部变量 -
面试题: SOF和OOM
SOF: statckOverFlowError -- 栈内存溢出 OOM: OutOfMemoryError -- 堆内存溢出 内存溢出:剩余内存不足以分配给请求的资源,此时会出现内存溢出. 原因: 1. 创建大对象 2. 内存泄漏的不断累积,内存泄漏一直累积到一定程度,则会出现堆内存溢出. 内存泄漏:分配出去的内存回收不回来,此时这个现象就叫做内存泄漏 内存泄漏和内存溢出的区别 内存溢出:剩余内存不足以分配给请求的资源,这种现象叫做内存溢出. 内存泄漏:分配出去的内存回收不回来,这个现象叫做内存泄漏 关系: 内存泄漏累积到一定程序才会造成内存溢出,并不是内存泄漏一旦出现,则立即出现内存溢出, 出现内存溢出并不一定是由于内存泄漏造成的,还可能是因为创建了大对象造成的。 内存泄漏,则一定会出现内存溢出? 错误 内存溢出一定是由于内存泄漏引起的? 错误
树 - tree
-
树是数据结构,由若干个节点构成,其中有且仅有一个根节点.
-
树的术语:
高度: 树的层次 根节点: 有且仅有一个 度: 树中节点的最大子节点数 叶子节点: 度为0的节点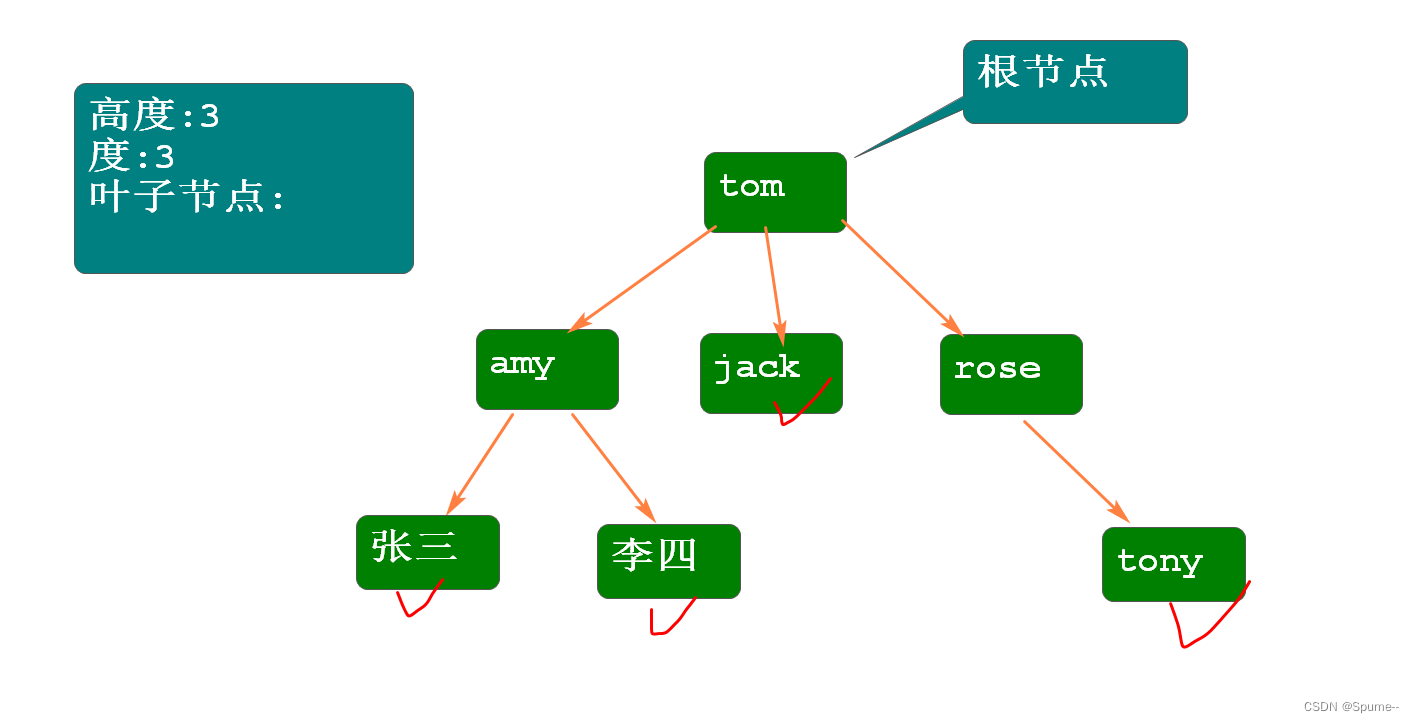
二叉树:
- 度为2的树,则为二叉树
二叉排序树
-
定义
二叉排序树(Binary Sort Tree),又称二叉查找树(Binary Search Tree),亦称二叉搜索树。是数据结构中的一类。在一般情况下,查询效率比链表结构要高。 -
特点
1. 元素不能重复 2. 左子树中的节点均小于根节点 3. 右子树中的节点均大于根节点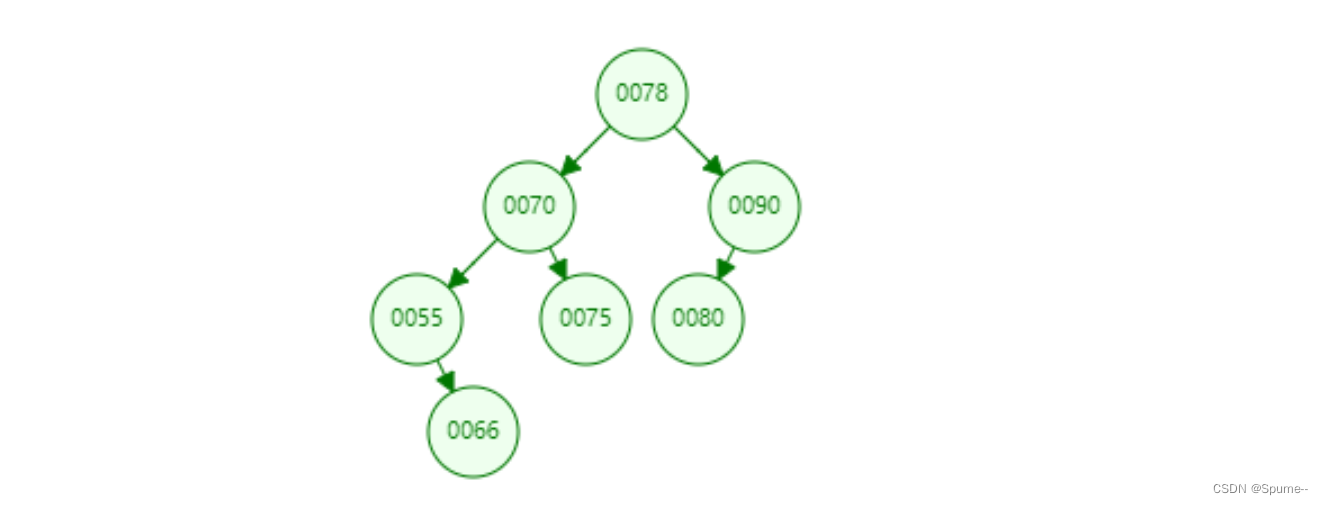
-
二叉排序树的查询效率高于单向链表
单向链表中,查询元素,最差的情况要查询n次;而在二叉排序树中,每次比较,均可以排除将近一半的数据,所以查询次数会大大减少.查询效率高于单向链表 -
二叉排序树中的元素可以是其他引用类型,但是要求该引用类型的对象之间是可比较大小的,如何保证对象之间能比大小?
实现Comparable接口,在类中定义比较规则,则对象之间是可比较大小的.