文章目录
- 一、作用
- 二、参数
- 三、锁的流程
- 四、SpringBoot 集成
- 1. pom 依赖
- 2. yaml 配置
- 3. 使用方式
- 五、变量级锁和方法级锁
- 六、常见应用场景
- 1. 页面重复提交
- 2. 定时任务
- 3. 核心业务
- 七、锁的粒度与锁的时间
一、作用
注解 @klock 是基于 Redis 的分布式锁,作用在分布式事务中避免并发冲突。只作用于方法上。
二、参数
-
name:锁的名称。锁唯一标识。
-
keys:加锁 id。加锁对象的唯一标识。
-
lockType:锁类型。默认可重入锁。
LockType.Reentrant 可重入锁。默认。 LockType.Fair 公平锁。 LockType.Reentrant 读锁。 LockType.Reentrant 写锁。 -
waitTime:获取锁最长等待时间。单位秒。
-
leaseTime:获取到锁后,自动释放锁的时间。
-
lockTimeoutStrategy:获取锁超时的处理策略。默认 NO_OPERATION 继续执行业务逻辑,不做任何处理。
NO_OPERATION:不做处理,不加锁继续执行业务逻辑。(默认) FAIL_FAST:快速失败,直接抛出获取锁超时异常。 KEEP_ACQUIRE:阻塞等待,一直阻塞,直到获得锁,在太多的尝试后,仍会报错。 一般下一次获取锁的间隔时间初始为0.1秒、总共尝试次数为10次,下一次获取锁的时间间隔会成倍增长。很可能引起死锁。 -
customLockTimeoutStrategy:自定义加锁超时的处理策略。String 类型,当前类中的方法名。会覆盖 lockTimeoutStrategy 的处理策略。
自定义处理方法,方法参数必须与加锁的方法参数一致。 -
releaseTimeoutStrategy:占有锁超时的处理策略。默认 NO_OPERATION 继续执行业务逻辑,不做任何处理。
NO_OPERATION:不做处理,不加锁继续执行业务逻辑。(默认) FAIL_FAST:快速失败,直接抛出获取锁超时异常。 -
customReleaseTimeoutStrategy:自定义释放锁时已超时的处理策略。String 类型,当前类中的方法名。会覆盖 releaseTimeoutStrategy 的处理策略。
自定义处理方法,方法参数必须与加锁的方法参数一致。
三、锁的流程
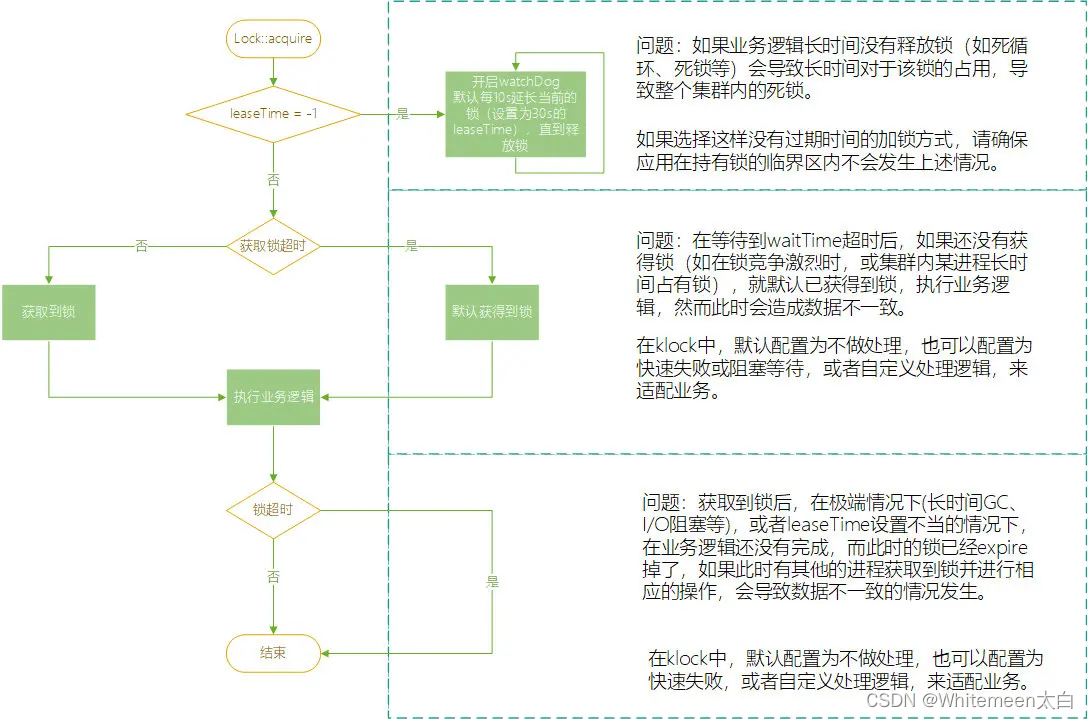
四、SpringBoot 集成
1. pom 依赖
<!--klock-->
<dependency>
<groupId>cn.keking</groupId>
<artifactId>spring-boot-klock-starter</artifactId>
<version>1.4-RELEASE</version>
</dependency>
2. yaml 配置
- 单节点配置
spring:
klock:
#单节点地址
address: 192.168.0.193:6379
#密码,没有密码就不要配置password
#password:
#获取锁最长阻塞时间(默认:60,单位:秒)
wait-time: 20
#已获取锁后自动释放时间(默认:60,单位:秒)
lease-time: 20
- 集群配置
spring:
klock:
#密码
#password:
#获取锁最长阻塞时间(默认:60,单位:秒)
wait-time: 20
#已获取锁后自动释放时间(默认:60,单位:秒)
lease-time: 20
#集群配置
cluster-server:
node-addresses: 192.168.0.111:6379,192.168.0.112:6379,192.168.0.113:6379,192.168.0.101:6379,192.168.0.102:6379,192.168.0.103:6379,192.168.0.114:6379,192.168.0.104:6379
3. 使用方式
/**
* 根据id查询
*
* @param id 文章id
* @return 文章
*/
@Override
@Klock(name = "article-hist-lock", // 锁名称
keys = "#id", // 加锁id
lockType = LockType.Fair, // 锁类型;公平锁
waitTime = 10, // 获取锁最长等待时间:10s
leaseTime = 300, // 获得锁后,自动释放锁的时间:300s
lockTimeoutStrategy = LockTimeoutStrategy.FAIL_FAST, // 获取锁超时的处理策略:直接返回失败
releaseTimeoutStrategy = ReleaseTimeoutStrategy.FAIL_FAST) // 占有锁超时的处理策略:直接返回失败
public CmsArticleVo selectCmsArticleVoByIdForApi(Long id) {
// 设置查询文章的内容类型
String contentType = CmsConstants.CONTENT_TYPE_ARTICLE;
CmsArticleVo cmsArticleVo = cmsArticleMapper.selectCmsArticleVoById(id, contentType);
if (cmsArticleVo != null) {
// 文章点击量+1
CmsArticle cmsArticle = new CmsArticle();
cmsArticle.setId(cmsArticleVo.getId());
cmsArticle.setHist(cmsArticleVo.getHist() + 1);
cmsArticleMapper.updateById(cmsArticle);
}
return cmsArticleVo;
}
五、变量级锁和方法级锁
VariableAndMethodLockService
package com.alian.redisklock.service;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.autoconfigure.klock.annotation.Klock;
import org.springframework.boot.autoconfigure.klock.model.LockTimeoutStrategy;
import org.springframework.stereotype.Service;
@Slf4j
@Service
public class VariableAndMethodLockService {
/**
* 变量级加锁
* @param userId
*/
@Klock(keys = "#userId", lockTimeoutStrategy = LockTimeoutStrategy.FAIL_FAST)
public void variableLock(String userId) {
log.info("变量级加锁收到的消息:{}", userId);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("变量级加锁业务处理完:{}", userId);
}
/**
* 方法级加锁
* @param userId
*/
@Klock
public void methodLock(String userId) {
log.info("方法级加锁收到的消息:{}", userId);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("方法级加锁业务处理完:{}", userId);
}
}
使用5个线程来进行并发验证:
TestLockTypeService
package com.alian.redisklock.service;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import javax.annotation.PostConstruct;
import java.util.concurrent.CountDownLatch;
@Slf4j
@Service
public class TestLockTypeService {
private final CountDownLatch countDownLatch = new CountDownLatch(1);
@Autowired
private VariableAndMethodLockService vmService;
@PostConstruct
public void testVariableAndMethodLock() {
for (int i = 0; i < 5; i++) {
int finalI = i;
new Thread(() -> {
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
//变量级加锁
vmService.variableLock("10001_" + finalI);
//方法级加锁
// vmService.methodLock("10002_"+ finalI);
}, "Thread" + i).start();
}
countDownLatch.countDown();
}
}
变量级加锁结果
2023-09-23 17:42:15 432 [Thread0] INFO :变量级加锁收到的消息:10001_0
2023-09-23 17:42:15 432 [Thread1] INFO :变量级加锁收到的消息:10001_1
2023-09-23 17:42:15 432 [Thread4] INFO :变量级加锁收到的消息:10001_4
2023-09-23 17:42:15 432 [Thread2] INFO :变量级加锁收到的消息:10001_2
2023-09-23 17:42:15 432 [Thread3] INFO :变量级加锁收到的消息:10001_3
2023-09-23 17:42:16 439 [Thread3] INFO :变量级加锁业务处理完:10001_3
2023-09-23 17:42:16 439 [Thread2] INFO :变量级加锁业务处理完:10001_2
2023-09-23 17:42:16 439 [Thread0] INFO :变量级加锁业务处理完:10001_0
2023-09-23 17:42:16 439 [Thread4] INFO :变量级加锁业务处理完:10001_4
2023-09-23 17:42:16 439 [Thread1] INFO :变量级加锁业务处理完:10001_1
方法级加锁结果
2023-09-23 17:43:15 779 [Thread3] INFO :方法级加锁收到的消息:10002_3
2023-09-23 17:43:16 787 [Thread3] INFO :方法级加锁业务处理完:10002_3
2023-09-23 17:43:16 797 [Thread2] INFO :方法级加锁收到的消息:10002_2
2023-09-23 17:43:17 800 [Thread2] INFO :方法级加锁业务处理完:10002_2
2023-09-23 17:43:17 819 [Thread0] INFO :方法级加锁收到的消息:10002_0
2023-09-23 17:43:18 833 [Thread0] INFO :方法级加锁业务处理完:10002_0
2023-09-23 17:43:18 844 [Thread1] INFO :方法级加锁收到的消息:10002_1
2023-09-23 17:43:19 847 [Thread1] INFO :方法级加锁业务处理完:10002_1
2023-09-23 17:43:19 863 [Thread4] INFO :方法级加锁收到的消息:10002_4
2023-09-23 17:43:20 864 [Thread4] INFO :方法级加锁业务处理完:10002_4
结论:
- 变量级锁,针对的是一个变量,变量不同,获取的锁就不存在先后顺序,都可以获取到自己的锁。
- 方法级锁,针对的是方法,哪怕请求值不一样,也只能一个线程获取到锁,直到释放后,下一个线程才能获取。
- 变量级锁的效率更适合高并发场景,而方法级锁可能引起阻塞。
六、常见应用场景
1. 页面重复提交
最常见的就比如手机端录入信息到后台,比如注册之类的等等,用户端可能因为各种原因可能会点击多次,导致后台可能会出现多笔记录的情况,这个时候很简单,用到我们的锁,假设,我们是注册用户,手机号是唯一的。
@Klock(keys = "#phone", lockTimeoutStrategy = LockTimeoutStrategy.FAIL_FAST)
@RequestMapping("register")
public void register(String phone,String nickName) {
log.info("注册账户收到的信息:{},{}", phone,nickName);
try {
//模拟业务过程
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("注册账户业务处理完");
}
这个时候,如果是点击了两次,第一次业务进入获取到锁进行处理,第二过来了也是一个等待,要么第一次处理完成,第二次业务判断已注册,要么第二次直接超时了。
2. 定时任务
工作中定时任务使用还是蛮多的,但是也会有很多问题,当遇到分布式服务时,一个服务部署多台,定时任务就可能会同时运行,这种情况怎么处理呢?有些人可能会给两个服务的配置改成不一样,比如定时任务的时间修改,一个正常执行,一个在不可能的时间执行,还有人直接给服务设置一个标志位,只有某个标志位的能执行。好吧,在分布式环境,并且服务不是很多的情况下,也许还能勉强维护,那么如果是容器下呢?所以分布式锁的方案就更加重要了。
@Scheduled(cron = "0 0 2 * * ?")
public void dataCollector(){
//开始做任务
String dataTime = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyyMMdd"));
createDataFile(dataTime);
//结束任务
}
@Klock(keys = "#dataTime", lockTimeoutStrategy = LockTimeoutStrategy.FAIL_FAST)
public void createDataFile(String dataTime) {
log.info("开始生成对账文件:{}", dataTime);
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("对账文件生成完成:");
}
这是一个示例,实际中,createDataFile方法是另外一个service中的方法,这样不管是单机,分布式多机,还是在容器中都只有一个定时任务在执行,而不会导致重复数据问题。
3. 核心业务
其实这个场景是用的最多的,比如商品库存的扣减,因为我们不能超卖啊。实际工作中,需要根据自己的业务定义特定意义的key就可以了。
@Klock(keys = "#goodId", lockTimeoutStrategy = LockTimeoutStrategy.FAIL_FAST)
public void deductCommodityInventory(String goodId,int num) {
log.info("商品【{}】扣减库存:{}", goodId,num);
//扣减库存操作
//dosomething()
log.info("商品扣减库存完成");
}
七、锁的粒度与锁的时间
锁的粒度一定要把握好,不能过小或者过大。能使用粒度小的锁,就尽量使用。比如尽量使用粒度更小的变量级锁,而不是方法级锁。尽量使用对象的唯一性字段作为锁的 key,而不是对象。
锁的时间控制一定要合理,不能太长也不能太短,根据相应的需求来合理设置以达到较好的性能。包括等待时间、释放时间、超时策略的时间响应问题。