分区表add columns 查询不到新增字段数据的问题;
5.1元数据管理
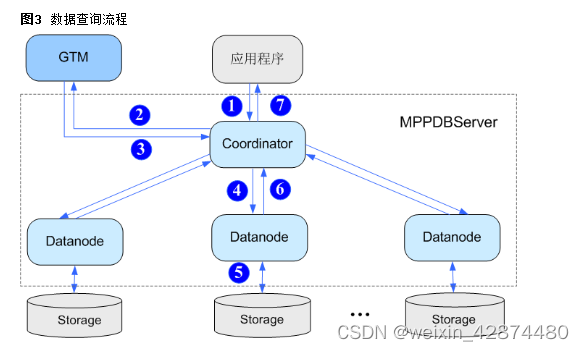
(1)基本架构
Hive的2个重要组件:hiveService2 和metastore,一个负责转成MR进行执行,一个负责元数据服务管理
beeline-->hiveService2/spark-->metastore-->metadata
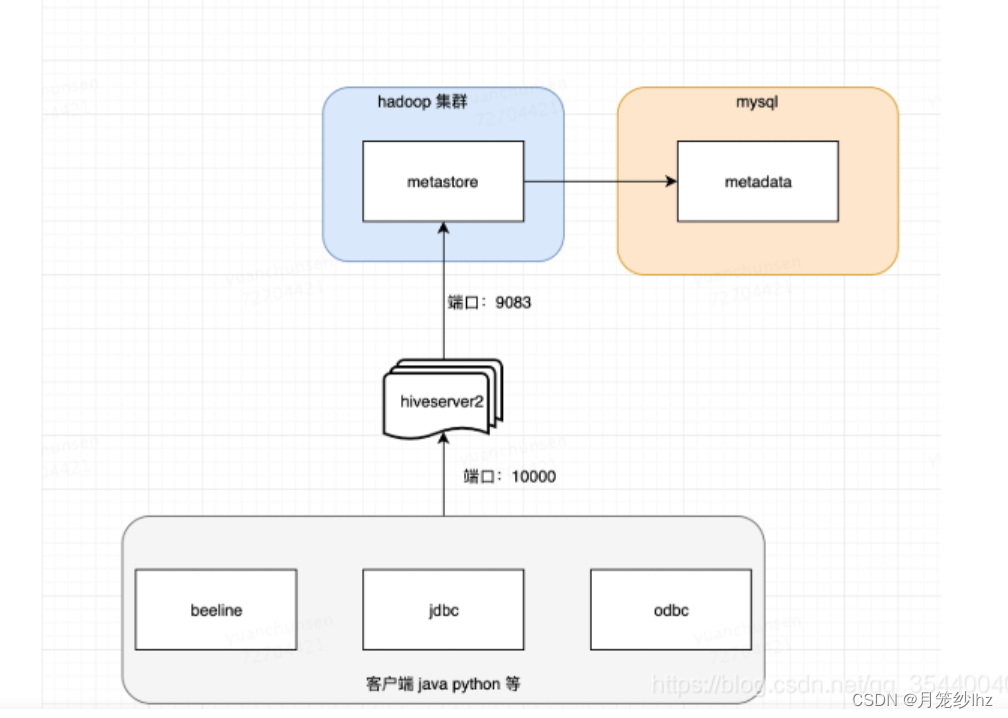
hive 架构及 metastore 功能简单介绍_骑着蜗牛向前跑的博客-CSDN博客
(2)多级管理机制
有数据库、表、分区、字段、存储等多个元数据管理信息;
(3)spark可以使用hive的库表,因为spark也可以配置参数,调取hive的metastore信息,从而访问hdfs取数据;
Hive之深入了解元数据_hive元数据_珞沫的博客-CSDN博客
5.2 cascade关键字
可以认为hadoop 的文件管理粒度对于分区表是到分区粒度的,是比表更细一个粒度的,所以alter table test1 add columns(department string comment ‘部门’) 这个命令不会改变历史分区的元数据信息,这种情况下即便insert overwrite命令更新了hdfs的数据,再使用select命令时仍然根据旧的元数据信息获取数据,所以获取不到新增字段;alter table test1 add columns(department string comment ‘部门’)cascade这个命令可以改变历史分区的元数据信息,insert overwrite命令后可以查到历史分区的新增字段数据;
hive分区表新增字段(add columns)后旧分区报错/字段无法写入(CASCADE)_hive add column-CSDN博客