简介
LibrA是一个基于开源数据库Postgres-XC开发的分布式并行关系型数据库系统。
LibrA提供了以下功能:
- 标准SQL支持
支持标准的SQL92/SQL2003规范,支持GBK和UTF-8字符集,支持SQL标准函数与OLAP分析函数,支持存储过程。
- 数据库存储管理功能
支持表空间,支持在线扩容功能。
- 提供组件管理和数据节点HA(High Availability)
支持数据库事务ACID特性(即原子性Atomicity、一致性Consistency、隔离性Isolation和持久性Durability),支持单节点故障恢复,支持负载均衡等。
- 应用程序接口
支持标准JDBC 4.0的特性和ODBC 3.5特性。
- 安全管理
支持SSL安全网络连接、用户权限管理、密码管理、安全审计等功能,保证数据库在管理层、应用层、系统层和网络层的安全性。
结构
LibrA采用Share-nothing架构,由多个拥有独立且互不共享CPU、内存、存储等系统资源的节点组成。在这样的系统架构中,业务数据被分散存储在多个物理节点上,数据分析任务被推送到数据所在位置就近执行,通过控制模块的协调,并行地完成大规模的数据处理工作,实现对数据处理的快速响应。
Share-nothing又称为无共享架构,和其他架构的对比请参见图1。

Share-nothing架构具备如下优点:
- 最易于扩展的架构
- 为商业智能BI(Business Intelligence)和数据分析的高并发、大数据量计算提供按需扩展的能力
- 自动化的并行处理机制
- 内部自动并行处理,无需人工分区或优化
- 数据加载与访问方式与一般数据库相同
- 数据分布在所有的并行节点上
- 每个节点只处理其中一部分数据
- 最优化的I/O处理
- 所有的节点同时进行并行处理
- 节点之间完全无共享,无I/O冲突
- 增加节点实现存储、查询及加载性能的线性扩展
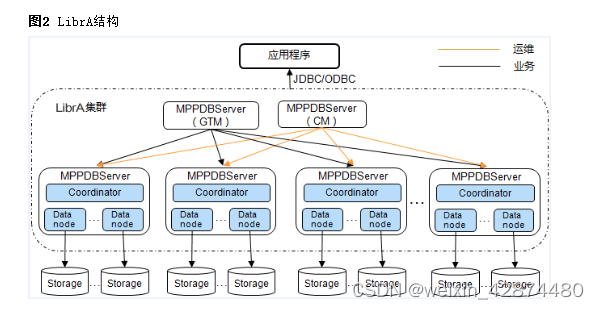
LibrA由多个MPPDBServer组成,LibrA结构具体如图2所示。

原理
作为关系型数据库系统,LibrA主要业务为数据的查询与存储。LibrA进行数据查询的流程如图3所示。
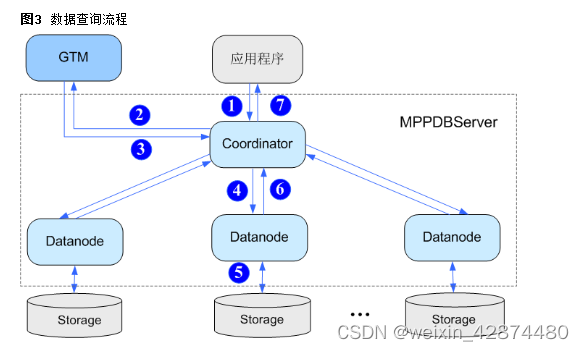
具体查询流程如下:
- 用户通过应用程序发出查询本地数据的SQL请求到Coordinator。
- Coordinator接收用户的SQL请求,分配服务进程,向GTM请求分配全局事务信息。
- GTM接收到Coordinator的请求,返回全局事务信息给Coordinator。
- Coordinator根据数据分布信息以及系统元信息,解析SQL为查询计划树,从查询计划树中提取可以发送到Datanode的执行步骤,封装成SQL语句或者子执行计划树,发送到Datanode执行。
- Datanode接收到读取任务后,查询具体Storage上的本地数据块。
- Datanode任务执行后,将执行结果返回给Coordinator。
- Coordinator将查询结果通过应用程序返回给用户。
LibrA数据存储流程与数据查询流程相近,请参考数据查询流程,此处不再介绍。