在 Elasticsearch 的运行过程中,如何合理分配与设置内存是一件十分重要的事情,否则十分容易出现各种问题。
一、Elasticsearch为什么吃内存:
我们先看下 ES 服务器的总体内存消耗情况:
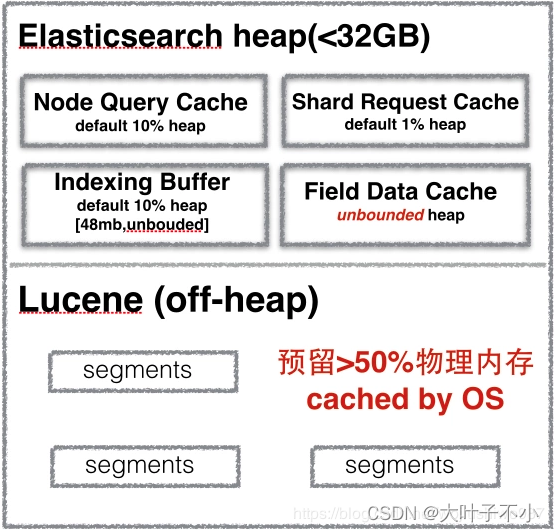
对于Query Cache、Request Cache、FieldData Cache、Indexing Buffer 以及 Segment 的介绍,在前面的文章以及介绍过了,这里就不重复介绍了:
Elasticsearch搜索引擎之缓存:Request Cache、Query Cache、Fielddata Cache
ElasticSearch搜索引擎:数据的写入流程
要回答 Elasticsearch 为什么这么耗费内存的问题,我们需要从两个角度切入:
(1)ES 是 JAVA 应用,那么就与 JVM 与 GC 息息相关。 我们这里不对 JVM GC 做深入探讨,只需知道:应用层面生成大量长生命周期的对象,是给 heap 造成压力的主要原因。例如读取大量数据在内存中进行排序,或者在 heap 内部缓存大量数据,如果 GC 释放的空间有限,而应用层面持续大量申请新对象,GC 频率就开始上升,不仅会消耗掉很多CPU时间,严重时可能恶性循环,导致整个集群停工。
(2)ES 底层存储引擎是基于 Lucene 的,Lucene 的倒排索引(Inverted Index)是先在内存里生成,然后定期以段文件(segment file)的形式刷到磁盘的。每个段实际就是一个完整的倒排索引,并且一旦写到磁盘上就不会做修改。API 层面的文档更新和删除实际上是增量写入的一种特殊文档,会保存在新的段里,所以不变的段文件非常容易被操作系统缓存,热数据几乎等效于内存访问。
二、Elasticsearch 的内存分配:
为什么分配给ES的堆内存不能超过物理机内存的一半?
1、预留一半内存给Lucene使用:
为什么需要预留一半的内存给 Lucene,将所有的内存都分配给 Elasticsearch 不是更好吗?毋庸置疑,堆内存对于 ES 来说绝对是重要的,但还有另外一个非常重要的内存使用者——Lucene。
在讲 Lucene 前,我们先简单介绍一下 segment。每个 segment 段是分别存储到单个文件的,即 segment 文件。它其实是一个包含正排(空间占90~95%) + 倒排(占5~10%) 的完整索引文件,并且一旦写到磁盘上就不会再修改,ES中文档更新和删除实际上是增量写入的一种特殊文档,会保存在新的段里而不修改旧的段。
回到 Lucene,Lucene 实际目的就是把底层 OS 里的数据缓存到内存中。由于 Lucene 的段 segment 是不会变化的,所以很利于缓存,操作系统会将这些段文件缓存起来,以便更快的访问。这些段包括倒排索引(用于全文搜索)和文档值(用于聚合)。
Lucene 的性能依赖于与 OS 的这种交互,如果把所有的内存都给了ES的堆内存,而不留一点给 Lucene,那么全文检索的性能会很差的。所以官方建议是将可用内存的 50% 提供给ES堆,而其他 50% 的剩余内存也并不会被闲置,因为 Lucene 会利用他们来缓存被用读取过的段文件。
ES的文件存储类型默认使用的是 mmap 内存映射,将 Lucene 索引文件用映射到内存中,这样进程就能够直接从内存中读取 Lucene 数据了。由于使用了内存映射,ES 进程读取 Lucene 文件时读取到的数据就会占用了堆外内存的空间。
2、分配给 ES 的堆内存不要超过 32G:
堆内存为什么不能超过32GB?事实上 JVM 在内存小于 32 G 的时候会采用一种内存对象指针压缩技术。
在 Java 中,所有的对象都分配在堆上,然后有一个指针引用它。指向这些对象的指针大小通常是 CPU 的字长的大小,不是 32 bit 就是 64 bit,这取决于你的处理器,指针指向了你的值的精确位置。对于 32 位系统,你的内存最大可使用 4 G。对于 64 系统可以使用更大的内存。但是 64 位的指针意味着更大的浪费,因为你的指针本身大了。并且比浪费的空间更糟糕的是,更大的指针在主内存和缓存器(例如 LLC,L1 等)之间移动数据的时候,会占用更多的带宽。
Java 使用一个叫内存指针压缩的技术来解决这个问题。它的指针不再表示对象在内存中的精确位置,而是表示偏移量。这意味着 32 位的指针可以引用 40 亿个对象,而不是 40 亿个字节。最终,也就是说堆内存长到 32 G 的物理内存,也可以用 32 bit 的指针表示。
一旦越过那个神奇的 30 - 32 G 的边界,指针就会切回普通对象的指针,每个对象的指针都变长了,就会使用更多的 CPU 内存带宽,也就是说你实际上失去了更多的内存。事实上当内存到达 40 - 50 GB 的时候,有效内存才相当于使用内存对象指针压缩技术时候的 32 G 内存。
所以,即便你有足够的内存,也尽量不要超过 32 G,因为它浪费了内存,降低了 CPU 的性能,还要让 GC 应对大内存。
3、ElasticSearch 的堆内存该设置:
分配给 Heap 堆的内存不要超过系统可用物理内存的一半,以确保有足够的物理内存留给 Lucene 系统文件缓存,并且不要超过 32 GB。那么 JVM 参数呢?只需要将最小堆大小(Xms)和最大堆大小(Xmx)设置和 heap 一样大小,避免动态分配 heap size 就好了。确保 Xms 和 Xmx 的大小是相同的,其目的是为了能够在 java 垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小而浪费资源,可以减轻伸缩堆大小带来的压力。
虽然说 32 GB 是 ES 的一个内存设置限制,那如果机器有很大的内存怎么办?比如现在的机器内存普遍都大,设置有 300 - 500 GB 内存的机器。当然,如果有这种机器,那是极好的,接下来有两个方案:
(1)如果主要做全文检索,可以考虑给 Elasticsearch 32 G 内存,剩下的交给 Lucene 用作操作系统的文件系统缓存,所有的 segment 都缓存起来,会加快全文检索。
(2)如果需要更多的排序和聚合,那就需要更大的堆内存。可以考虑一台机器上创建两个或者更多的 ES 节点,而不要部署一个使用 32 + GB 内存的节点。仍然要坚持 50% 原则,假设你有个机器有 128 G 内存,你可以创建两个 node,使用 32 G 内存。也就是说 64 G 内存给 ES 的堆内存,剩下的 64 G 给 Lucene。
PS:如果选择第二种方案,需要配置 cluster.routing.allocation.same_shard.host: true,防止同一个 shard 的主副本存在同一个物理机上,因为如果存在一个机器上,副本的高可用性就没有了
————————————————
版权声明:本文为CSDN博主「张维鹏」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/a745233700/article/details/117917338







![[网鼎杯 2018]Comment git泄露 / 恢复 二次注入 bash_history文件查看](https://img-blog.csdnimg.cn/77f22c8faf9e4393b66dda3dca254612.png)