物理内存
计算机物理内存条的容量,比如我们买电脑会关注内存大小有多少G,这个容量就是计算机的物理内存。
虚拟内存
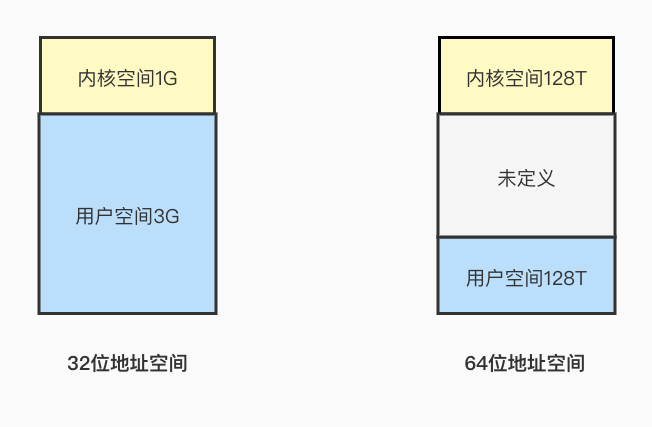
操作系统为每个进程分配了独立的虚拟地址空间,也就是虚拟内存,虚拟地址空间又分为用户空间和内核空间,操作系统的位数不同,虚拟地址空间的大小也不同,32位操作系统虚拟地址内核空间为1G,用户空间大小为3G,64位操作系统用户空间和内核空间大小各为128T:
既然每个进程都拥有一块独立的虚拟地址空间,那么所有进程的虚拟地址空间大小加起来必定大于物理内存的大小,所以虚拟地址空间只是一个虚拟的概念,只有需要分配内存的时候才会为虚拟内存分配物理内存,并通过内存映射来管理虚拟地址和物理内存地址之间的映射关系。
用户空间 / 内核空间
**用户空间:**是运行用户程序代码的地方,为了保证系统内核的安全,它不能直接访问内存等硬件设备,必须通过系统调用进入到内核空间来访问那些受限的资源。
**内核空间:**是运行内核代码的地方,可以执行任意的指令访问系统资源,既可以访问内核空间也可以访问用户空间。
**用户态:**进程运行在用户空间时处于用户态。
**内核态:**进程运行在内核空间时处于内核态。
文件I/O
文件I/O与读写文件有关,比如我们启动了一个程序,此时运行在用户空间(用户态),接着准备做一个读取磁盘文件的操作,由于用户空间是无法直接从磁盘读取文件的,所以需要调用内核提供的接口来完成文件的读取,调用内核的接口的过程中由用户空间进入到了内核空间(内核态),DMA从磁盘读取文件到内核的缓冲区,之后再将数据从内核的缓冲区拷贝到用户空间完成文件的读取操作:
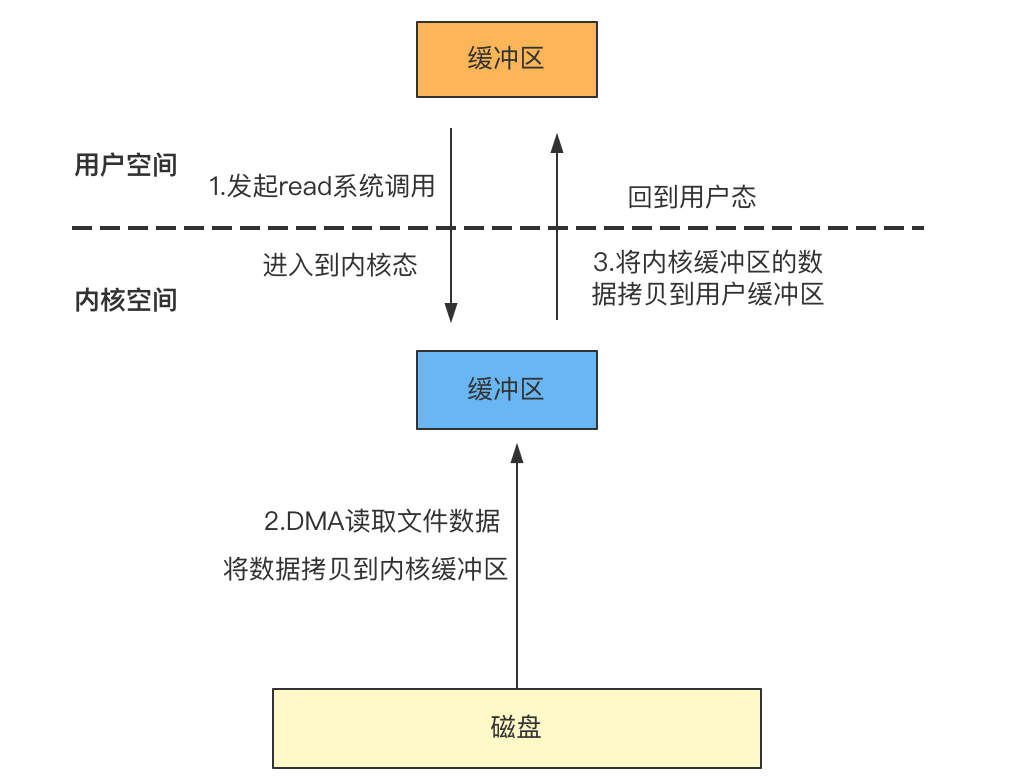
- 应用程序调用read函数发起系统调用,此时由用户空间切换到内核空间;
- 内核通过DMA从磁盘拷贝数据到内核缓冲区(DMA复制);
- 将内核缓冲区的数据拷贝到用户空间的缓冲区(CPU复制),切换回用户空间;
**可以发现,整个读取过程发生了两次数据拷贝,一次是DMA将磁盘上的文件数据拷贝到内核缓冲区,一次是将内核缓冲区的数据拷贝到用户缓冲区。**写操作与读取操作类似,只不过是将用户缓冲区的数据拷贝到内核缓冲区,再将内核缓冲区的数据拷贝到文件。
文件I/O从操作系统的角度来看还可以划分为缓存I/O、直接I/O和mmap内存映射。
缓存I/O
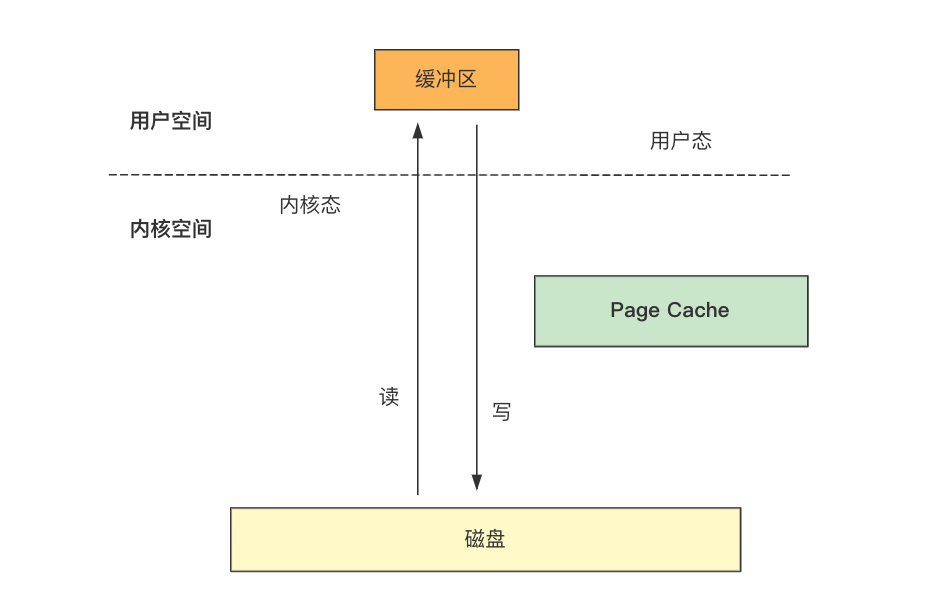
也称标准I/O,上面提到的文件I/O读取数据的例子就是使用的缓存I/O,它需要将数据先拷贝到内核缓冲区,再将内核缓冲区的数据拷贝到用户缓冲区,数据经过两次拷贝,内核缓冲区和用户缓冲区分别指向不同的物理内存,在文件I/O中,内核缓冲区是在Page Cache层,这也是称为缓存I/O的原因:

JAVA中通过java.io包下进行读写文件使用的就是缓存I/O。
为什么需要缓存IO?
因为磁盘I/O是比较耗时的操作,如果每次都从磁盘上读取文件,性能将会大大下降,为了提升读取性能,增加了一层Page Cache,用于缓存读取的文件数据,Page Cache占用的是内存,从内存读取的速度远远大于从磁盘读取,内核缓冲区就是在Page Cache中开辟的一块内存,用户空间进行系统调用读取文件内容时,首先会判断Page Cache中是否缓存了文件的内容,如果缓存了直接读取即可,否则再从磁盘读取,所以缓存I/O可以减少磁盘I/O的次数提升性能。
文件的写操作同样如此,进行写操作时,将数据先写到Page Cache的缓冲区中,后续由操作系统将数据刷回到磁盘中。
缓存I/O的优缺点
优点:减少磁盘I/O次数,提升读写性能。
缺点:数据需要在内核空间和用户空间来回拷贝。
DirectByteBuffer
使用缓存I/O读取数据时,数据会经过两次拷贝,经过两次拷贝是从系统调用开始讲起,在JAVA中由于涉及到JVM堆内和堆外内存,如果使用java.io下的类进行文件读写实际上还会再多一次拷贝(详细可参考【JAVA】普通IO数据拷贝次数的问题探讨 ):
- 底层发起JNI调用,创建堆外缓冲区;
- JNI中发起read系统调用,此时需要由用户空间切换到内核空间;
- 进入到内核空间,DMA读取文件数据到内核缓冲区(DMA拷贝);
- 将内核缓冲区的数据拷贝到用户缓冲区(CPU拷贝),切换回用户空间;
- 将堆外缓冲区的数据拷贝到JVM堆内缓冲区中(CPU拷贝);
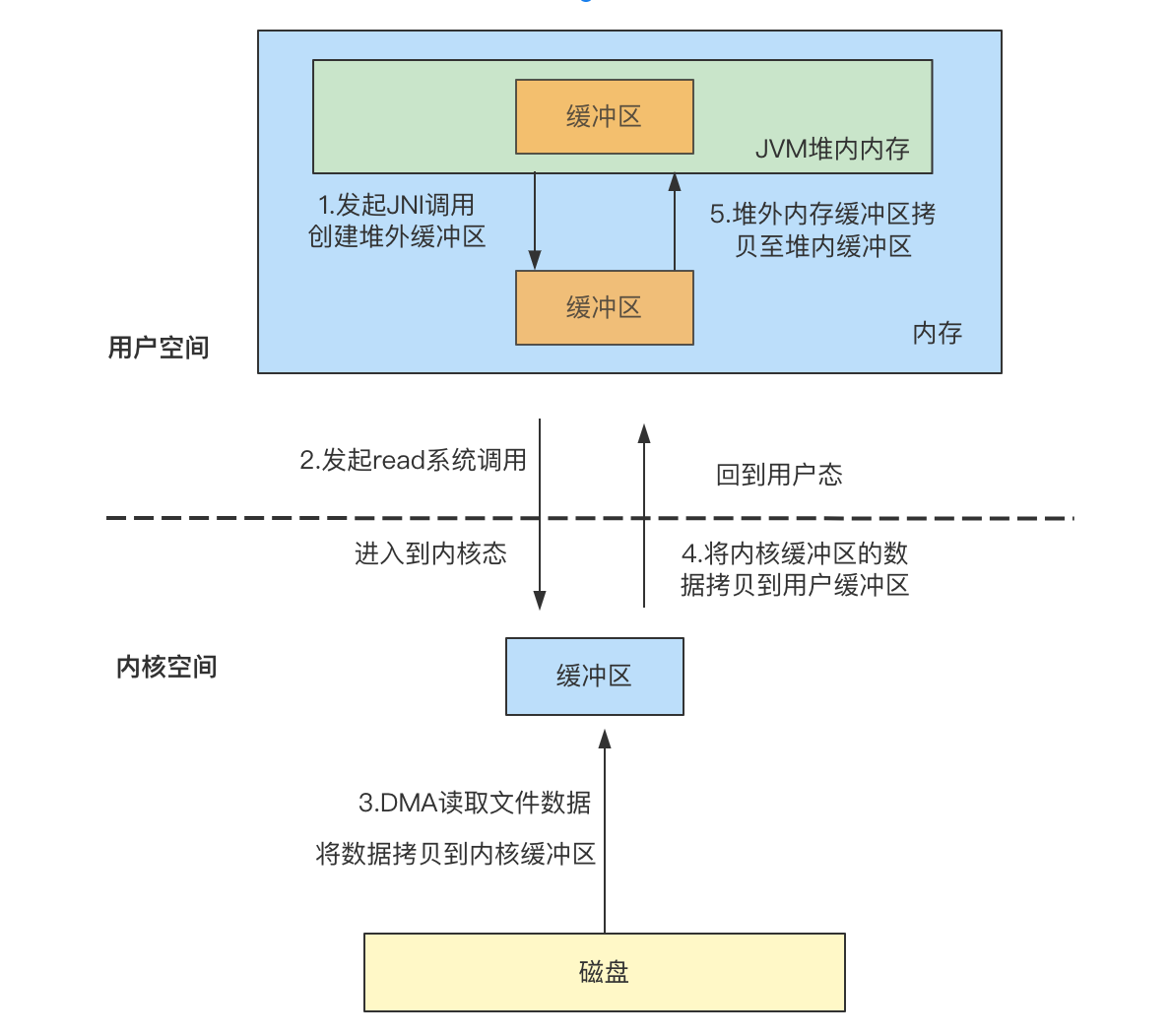
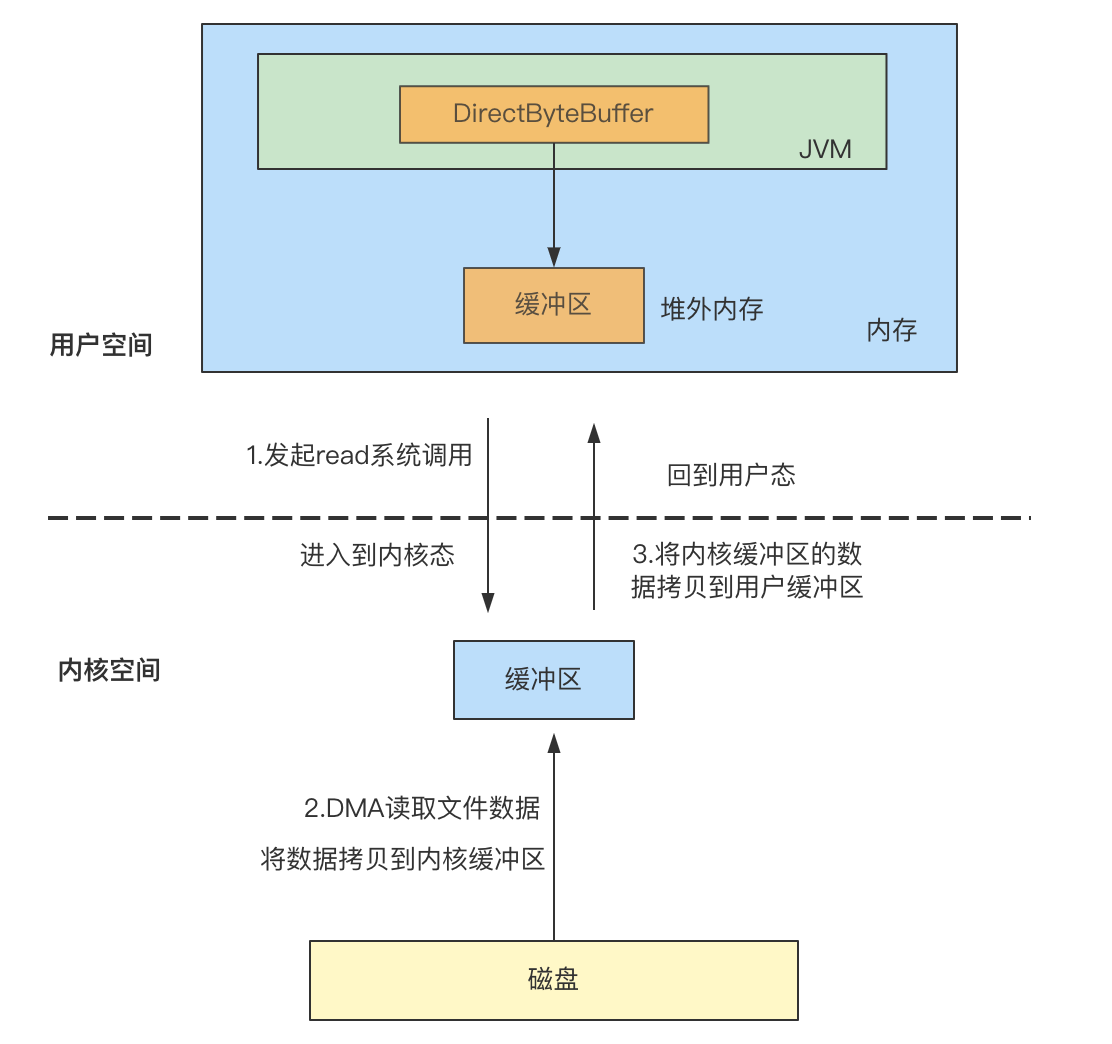
在Java的NIO中,提供了DirectByteBuffer,可以直接分配堆外内存,减少了一次从堆外内存到堆内内存的复制(CPU复制):
直接I/O
缓存I/O经过了Page Cache,读取过程中需要将数据从Page Cache的缓冲区中拷贝到用户空间的缓存区,那么有没有一种方式可以省去这个拷贝的过程?
答案是有的,那就是直接I/O,应用程序直接访问磁盘数据,绕过了Page Cache,省去了从内核缓冲区拷贝到用户缓冲区的过程:
目前JAVA并没有原生的直接/O操作方式,不过公众号博主Kirito提供了在JAVA中进行直接I/O操作的方法,具体参见【Kirito的技术分享】Java 文件 IO 操作之 DirectIO。
内存映射
内存映射就是将虚拟空间地址映射到物理空间地址,每个进程维护了一张页表,记录虚拟地址和物理地址之间的映射关系,当进程访问的虚拟地址在页表中无法查到映射关系时,系统产生缺页异常,进入内核空间为虚拟地址分配物理内存,并更新页表,记录映射关系。
文件映射
内存映射除了映射虚拟空间地址和物理空间地址,还包括将磁盘的文件内容映射到虚拟地址空间,称为文件映射,此时可以通过访问内存来访问文件里面的数据 。
mmap系统调用可以将文件映射到虚拟内存空间。文件映射的流程如下:
- 进行mmap系统调用,将文件和虚拟地址空间建立映射,注意此时还没有分配物理内存空间,只是在逻辑上建立了虚拟地址和文件之间的映射关系,物理内存只有真正使用的时候才会分配。
- 应用程序访问用户空间虚拟内存中的某个地址,发现无法在页表中查到数据,产生缺页异常,此时进入内核空间
- 因为不能直接使用物理地址,所以需要使用内核的虚拟地址临时建立与物理内存的映射关系,将文件内容读取到物理内存中,待数据读取完毕之后取消临时映射即可。
- 缺页异常处理完毕,物理内存中已经加载了文件的数据,此时用户空间就可以通过虚拟地址直接访问物理内存中映射的文件数据。
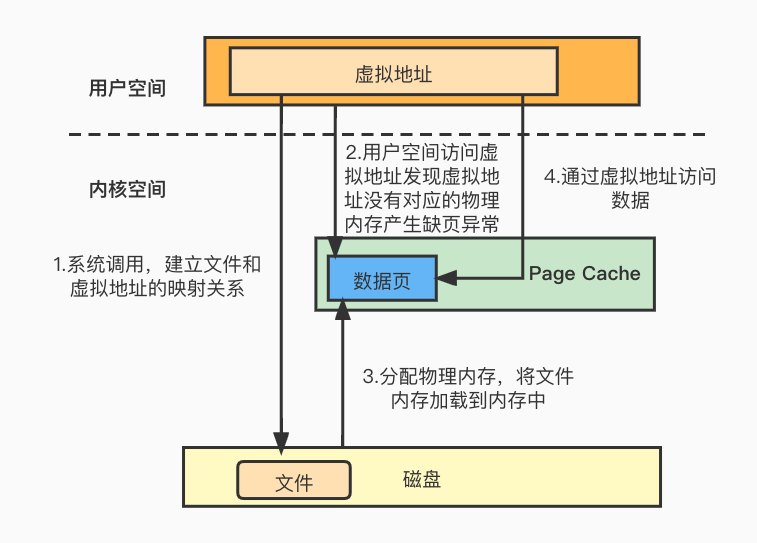
从文件映射的流程中可以看出它与缓存I/O相比,少了从内核缓冲区将数据拷贝到用户缓冲区的步骤,减少了一次拷贝。
Java NIO中提供了MappedByteBuffer来处理文件映射,下面是一个读取文件的例子:
public class MappedByteBufferTest {
public static void main(String[] args) {
try (RandomAccessFile file = new RandomAccessFile(new File("/Users/sml/test.txt"), "r")) {
// 获取FileChannel
FileChannel fileChannel = file.getChannel();
long size = fileChannel.size();
// 调用map方法进行文件映射,返回MappedByteBuffer
MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_ONLY, 0, size);
byte[] bytes = new byte[(int)size];
for (int i = 0; i < size; i++) {
// 读取数据
bytes[i] = mappedByteBuffer.get();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
零拷贝
零拷贝一般指的是从磁盘读取文件发送到网络或者从网络接收数据写入到磁盘文件的过程中,减少数据的拷贝次数。
网络I/O
网络I/O与网络数据发送/接收有关,与文件I/O的底层原理一致,同样以读取数据为例,文件I/O是从磁盘读取文件,网络I/O是从网卡中读取数据。比如客户端与服务端建立了一个连接,客户端向服务端发送数据,服务端从网卡中读取客户端发送的数据到内核中的socket缓冲区,再将socket缓冲区的数据复制到用户空间的缓冲区:
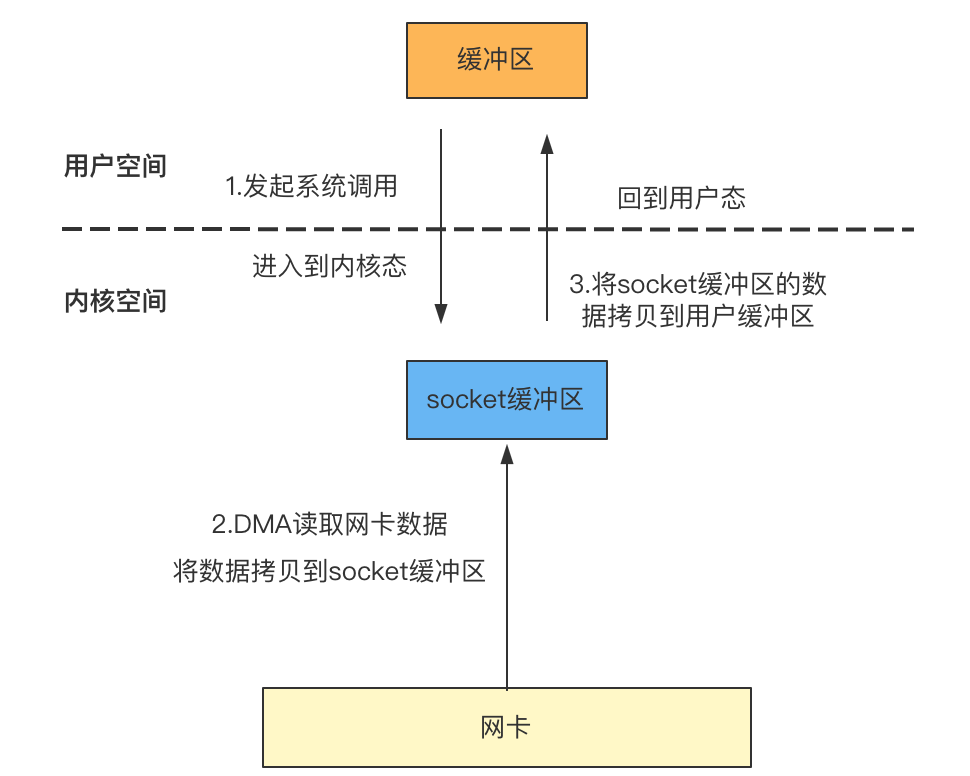
使用缓存I/O发送数据到网络
首先看一下使用缓存I/O从磁盘文件读取数据并发送到网络上的过程:
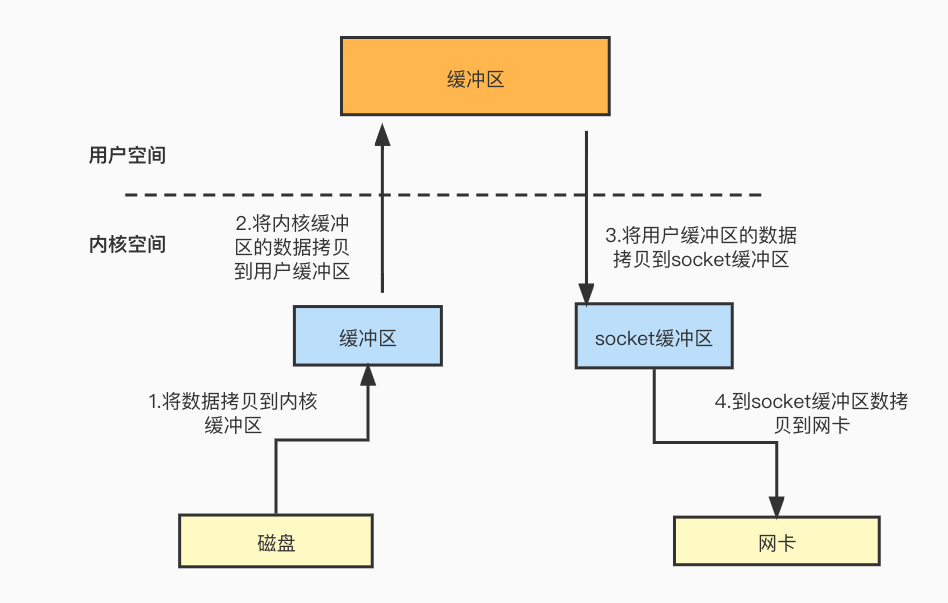
- 用户发起系统调用,进入到内核态,DMA从磁盘上读取数据到内核缓冲区(DMA复制);
- CPU将内核缓冲区的数据拷贝到用户缓冲区(CPU复制),切换回到用户空间;
- 再次从用户空间切换到内核空间,CPU将用户缓冲区的数据拷贝到socket缓冲区(CPU复制);
- DMA将socket缓冲区的数据拷贝到网卡(DMA复制),之后从内核空间切换回用户空间;
使用缓存I/O数据经过了四次拷贝,需要多次在内核空间和用户空间来回切换,影响系统性能。从数据拷贝的过程可以看到有些步骤其实是多余的,比如第二步,如果可以直接将内核缓存区的数据拷贝到socket缓冲区,或者直接将内核缓冲区的数据拷贝到网卡,岂不是减少了数据拷贝的次数?零拷贝就是这样一种致力于减少数据拷贝的技术。
Linux中的零拷贝
sendfile
Linux在2.1版本中引入了sendfile函数,可以实现将数据从一个文件描述符传输到另外一个文件描述符:
- 发起sendfile系统调用,进入到内核空间;
- DMA从磁盘读取文件到内核缓冲区(DMA复制);
- 将内核缓冲区数据拷贝到socket缓冲区(CPU复制);
- 将socket缓冲区数据拷贝到网卡(DMA复制),之后切换回用户空间;
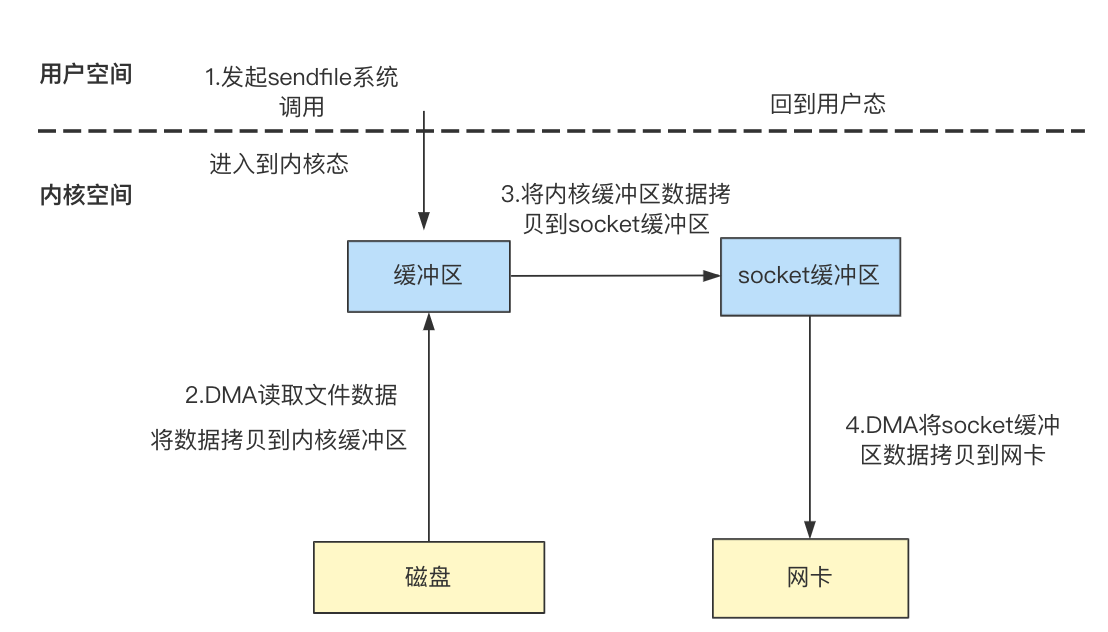
sendfile减少了一次数据从内核缓冲区拷贝到用户缓冲区的过程,可以直接将内核缓冲区的数据拷贝到socket缓冲区。
sendfile + DMA GATHER
Linux在2.4版本中引入了gather技术,我们知道内核缓冲区在内存中有对应的地址,gather操作可以将内核缓冲区的内存地址、地址偏移量信息记录到socket缓冲区中,之后DMA根据地址信息从内存中读取数据到网卡中,减少了数据从内核缓冲区到socket缓冲区的拷贝过程:
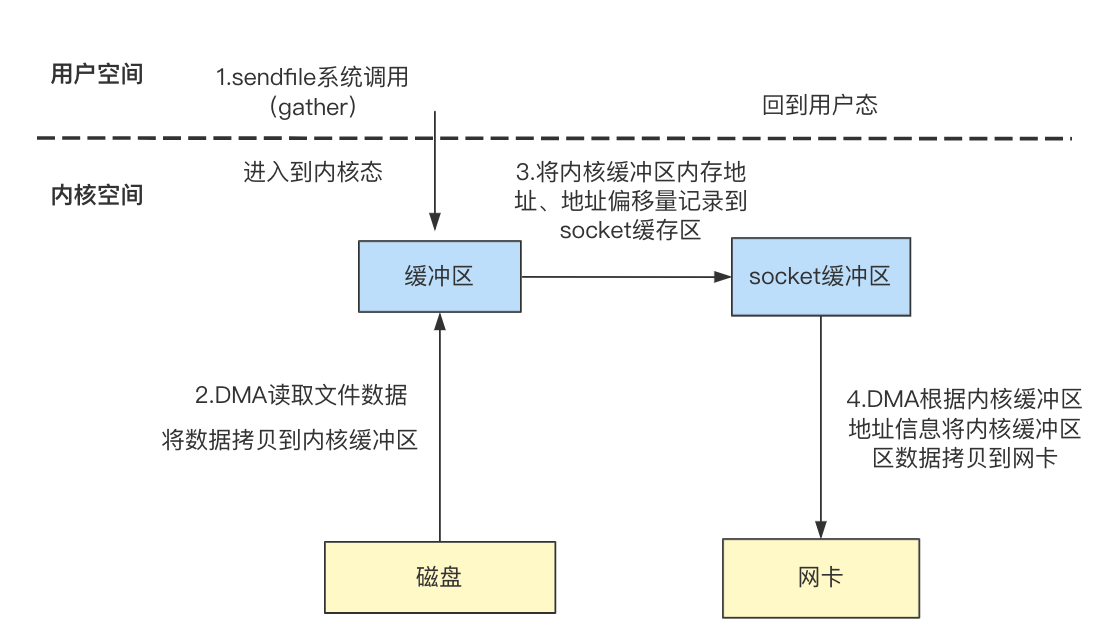
可以看到零拷贝并不是指的数据一次拷贝都没有发生,而是指减少CPU进行数据拷贝的次数。
Java中的零拷贝
MappedByteBuffer
在内存映射中说过,可以通过文件映射的方式将磁盘的文件内容映射到虚拟地址空间,用户空间就可以通过虚拟地址直接访问物理内存中的映射的文件数据,而Java NIO中也提供了MappedByteBuffer来处理文件映射,使用MappedByteBuffer向网络中发送数据的过程如下:
-
使用MappedByteBuffer建立文件映射,用户空间可以通过虚拟地址直接访问映射的文件数据;
-
将映射的文件数据拷贝到socket网络缓冲区(CPU复制);
-
DMA将socket缓冲区的数据拷贝到网卡(DMA复制);
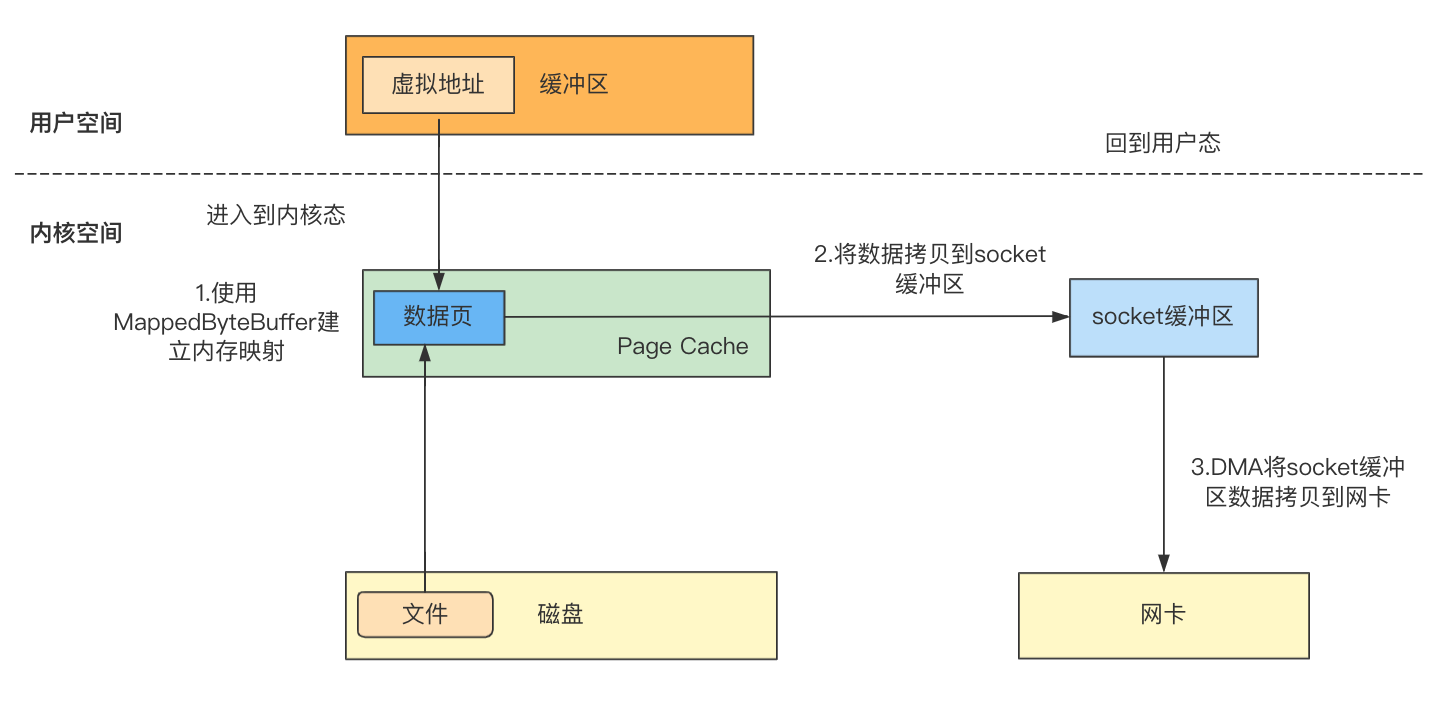
MappedByteBuffer减少了从内核缓冲区到用户缓冲区的数据拷贝,可以直接将内核缓冲区的数据拷贝到网络缓冲区。
FileChannel
Java NIO中的FileChannel可以实现将数据从FileChannel直接传输到另一个Channel,它是sendfile的一种实现:
RandomAccessFile file = new RandomAccessFile(new File("/Users/sml/test.txt"), "r");
// 获取FileChannel
FileChannel fileChannel = file.getChannel();
long size = fileChannel.size();
SocketChannel socketChannel = SocketChannel.open(new InetSocketAddress("localhost", 8080));
fileChannel.transferTo(0,size,socketChannel);
参考
【极客时间-倪朋飞】Linux性能优化实战
【极客时间-刘超】趣谈Linux操作系统
【拉勾教育-若地】Netty 核心原理剖析与 RPC 实践
【 Kirito的技术分享】文件IO操作的最佳实践
【小码农叔叔】java使用nio读写文件
【占小狼】深入浅出MappedByteBuffer
【零壹技术栈】深入剖析Linux IO原理和几种零拷贝机制的实现
【tomas家的小拨浪鼓】堆外内存 之 DirectByteBuffer 详解
网络IO和磁盘IO详解
![[网鼎杯 2018]Comment git泄露 / 恢复 二次注入 bash_history文件查看](https://img-blog.csdnimg.cn/77f22c8faf9e4393b66dda3dca254612.png)