文章链接
https://blog.csdn.net/weixin_44791964/article/details/102585038?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522169675238616800211588158%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=169675238616800211588158&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2blogfirst_rank_ecpm_v1~rank_v31_ecpm-2-102585038-null-null.nonecase&utm_term=VGG&spm=1018.2226.3001.4450
VGG16原理链接
https://zhuanlan.zhihu.com/p/460777014
代码参考:
https://blog.csdn.net/m0_50127633/article/details/117045008?ops_request_misc=&request_id=&biz_id=102&utm_term=pytorch%20vgg16&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-1-117045008.142v95insert_down28v1&spm=1018.2226.3001.4187
https://blog.csdn.net/weixin_46676835/article/details/128730174?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522169681442316800215096882%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=169681442316800215096882&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-5-128730174-null-null.142v95insert_down28v1&utm_term=pytorch%20vgg16&spm=1018.2226.3001.4187
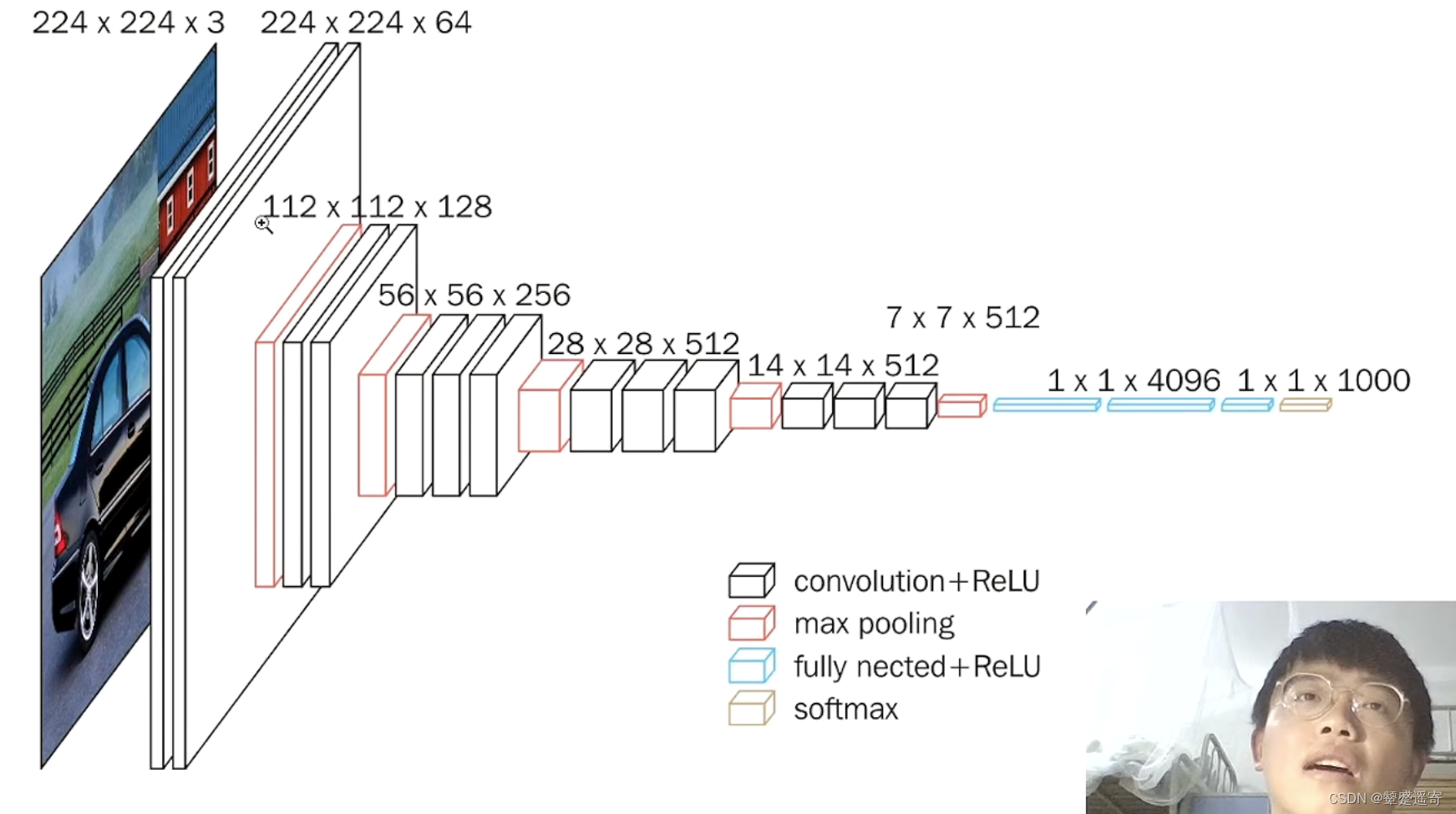

分解一下:
卷积提取特征,池化压缩。
1、一张原始图片被resize到(224,224,3)。
2、conv1两次[3,3]卷积网络,输出的特征层为64,输出为(224,224,64),再2X2最大池化,输出net为(112,112,64)。
注意 池化不会改变通道数

根据公式第一步取stride=1,padding=1

stride=2 padding=0(不用写)
nn.Conv2d(3,64,3,1,1),
nn.Conv2d(64,64,3,1,1)
nn.Conv2d(3,64,3,1,1),
nn.Conv2d(64,64,3,1,1),
nn.MaxPool2d(2,2)
3、conv2两次[3,3]卷积网络,第一次输入的特征层为64,输出net为(112,112,128),再2X2最大池化,输出net为(56,56,128)。
nn.Conv2d(64,128,3,1,1),
nn.Conv2d(128, 128, 3, 1, 1),
nn.MaxPool2d(2,2),
4、conv3三次[3,3]卷积网络,输入的特征层为256,输出net为(56,56,256),再2X2最大池化,输出net为(28,28,256)。
nn.Conv2d(128,256,3,1,1),
nn.Conv2d(256,256,3,1,1),
nn.Conv2d(256,256,3,1,1),
nn.MaxPool2d(2,2)
5、conv3三次[3,3]卷积网络,输入的特征层为256,输出net为(28,28,512),再2X2最大池化,输出net为(14,14,512)。
nn.Conv2d(256,512,3,1,1),
nn.Conv2d(512,512,3,1,1),
nn.Conv2d(512,512,3,1,1),
nn.MaxPool2d(2,2),
6、conv3三次[3,3]卷积网络,输出的特征层为256,输出net为(14,14,512),再2X2最大池化,输出net为(7,7,512)。
nn.Conv2d(512,512,3,1,1),
nn.Conv2d(512,512,3,1,1),
nn.Conv2d(512,512,3,1,1),
nn.MaxPool2d(2,2)
7、利用卷积的方式模拟全连接层,效果等同,输出net为(1,1,4096)。共进行两次。
nn.Linear(25088,4096), #7×7×512
nn.Linear(4096,4096),
nn.Linear(4096,1000)
8、利用卷积的方式模拟全连接层,效果等同,输出net为(1,1,1000)。
最后输出的就是每个类的预测。
nn.Linear(4096,1000)
初步代码框架如下:
import torch
from torch import nn
class VGG(nn.Module):
def __init__(self):
super(VGG, self).__init__()
self.MyVgg=nn.Sequential(
nn.Conv2d(3,64,3,1,1),
nn.Conv2d(64,64,3,1,1),
nn.MaxPool2d(2,2),
nn.Conv2d(64,128,3,1,1),
nn.Conv2d(128, 128, 3, 1, 1),
nn.MaxPool2d(2,2),
nn.Conv2d(128,256,3,1,1),
nn.Conv2d(256,256,3,1,1),
nn.Conv2d(256,256,3,1,1),
nn.MaxPool2d(2,2),
nn.Conv2d(256,512,3,1,1),
nn.Conv2d(512,512,3,1,1),
nn.Conv2d(512,512,3,1,1),
nn.MaxPool2d(2,2),
nn.Conv2d(512,512,3,1,1),
nn.Conv2d(512,512,3,1,1),
nn.Conv2d(512,512,3,1,1),
nn.MaxPool2d(2,2),
nn.Linear(25088,4096), #7×7×512
nn.Linear(4096,4096),
nn.Linear(4096,1000)
)
补充与完善
1、记得进行数据拉平:
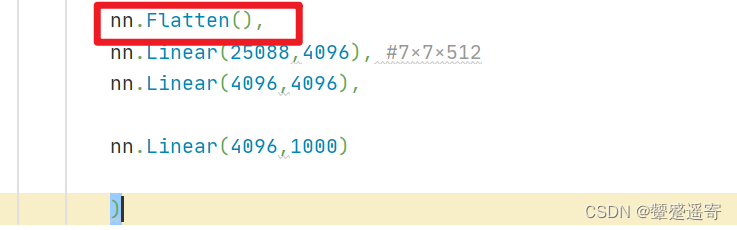
模型部分
class VGG(nn.Module):
def __init__(self):
super(VGG, self).__init__()
self.MyVgg=nn.Sequential(
nn.Conv2d(3,64,3,1,1),
nn.Conv2d(64,64,3,1,1),
nn.MaxPool2d(2,2),
nn.Conv2d(64,128,3,1,1),
nn.Conv2d(128, 128, 3, 1, 1),
nn.MaxPool2d(2,2),
nn.Conv2d(128,256,3,1,1),
nn.Conv2d(256,256,3,1,1),
nn.Conv2d(256,256,3,1,1),
nn.MaxPool2d(2,2),
nn.Conv2d(256,512,3,1,1),
nn.Conv2d(512,512,3,1,1),
nn.Conv2d(512,512,3,1,1),
nn.MaxPool2d(2,2),
nn.Conv2d(512,512,3,1,1),
nn.Conv2d(512,512,3,1,1),
nn.Conv2d(512,512,3,1,1),
nn.MaxPool2d(2,2),
nn.Flatten(),
nn.Linear(25088,4096), #7×7×512
nn.Linear(4096,4096),
nn.Linear(4096,1000)
)
def forward(self,x):
x=self.MyVgg(x)
return x
2、导入数据
使用cifar10数据集
import torch
from torch import nn
import torchvision
from torch.utils.data import DataLoader
datasets_train=torchvision.datasets.CIFAR10("./data",train=True,download=True,
transform=torchvision.transforms.ToTensor())
datasets_test=torchvision.datasets.CIFAR10("./data",train=False,download=True,
transform=torchvision.transforms.ToTensor())
dataloader_train=DataLoader(datasets_train,batch_size=64)
dataloader_test=DataLoader(datasets_test,batch_size=64)
3、创建损失函数
使用交叉熵CrossEntropyLoss
from torch import nn
los_fun=nn.CrossEntropyLoss()
4、创建优化器:
learning_rate=0.001
optimizer=torch.optim.SGD(fenlei.parameters(),lr=learning_rate)
5、编写训练代码:
total_train_step=0
tatal_test_step=0
epoch=10
for i in range(epoch):
print("--------第{}轮训练开始-----".format(i+1))
for data in dataloader_train:
imgs,targets=data
outputs=fenlei(imgs)
loss=los_fun(outputs,targets)
optimizer.zero_grad()
loss.backward()
total_train_step=total_train_step+1
print("训练次数:{},Loss:{}".format(total_train_step, loss))
训练时报错:
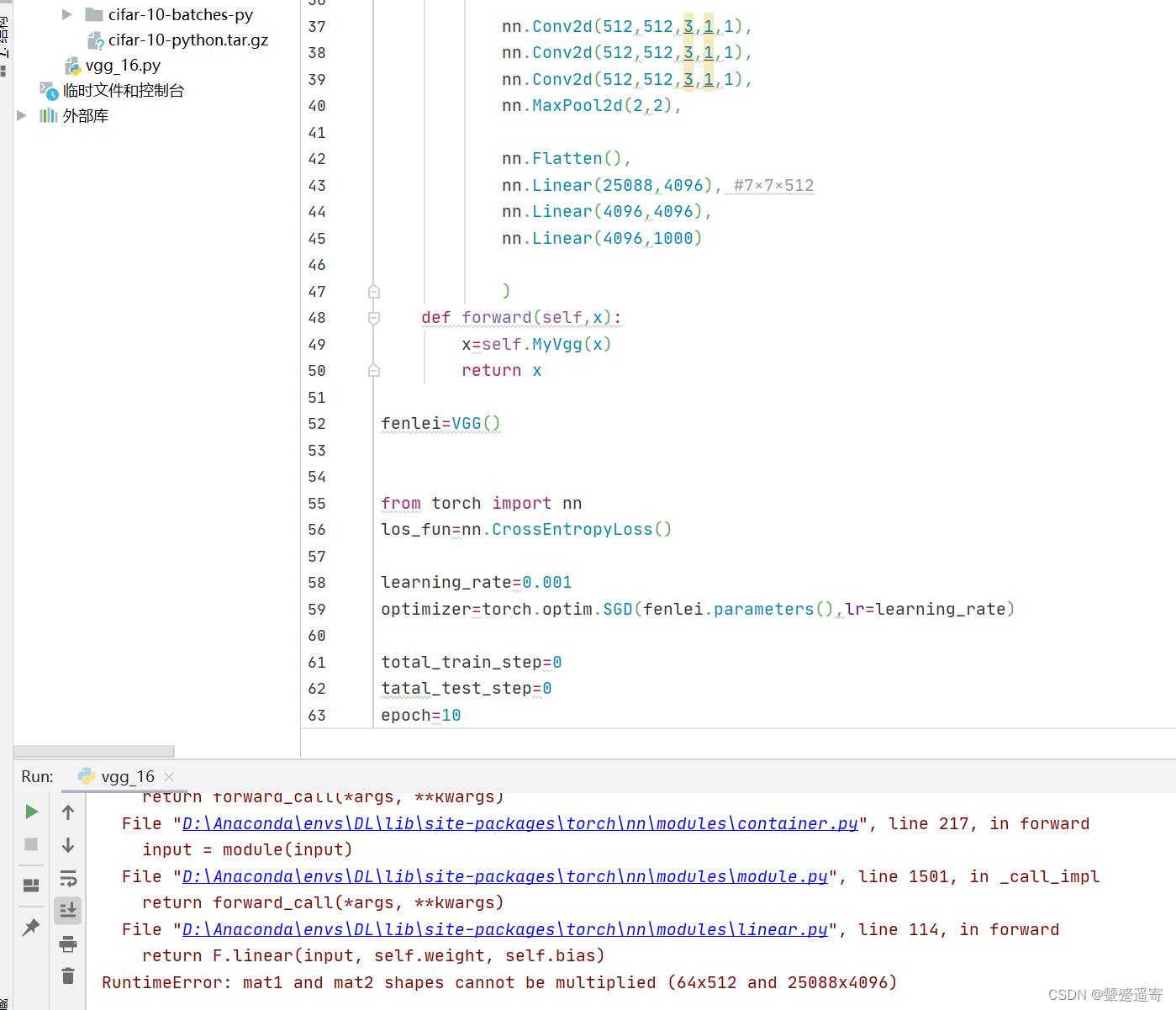
原因我们假设输入的是224×224×3了
然而cfar10的数据集是32×32×3
所以我们需要加入resize操作:
from torchvision import transforms
datasets_train=torchvision.datasets.CIFAR10("./data",train=True,download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Resize([224,224])
]) )
6、使用GPU训练:
#定义训练设备
device=torch.device('cuda'if torch.cuda.is_available()else 'cpu')
fenlei.to(device)
los_fun=los_fun.to(device)
我的
import torch
from torch import nn
import torchvision
from torch.utils.data import DataLoader
from torchvision import transforms
datasets_train=torchvision.datasets.CIFAR10("./data",train=True,download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Resize([224,224])
]) )
datasets_test=torchvision.datasets.CIFAR10("./data",train=False,download=True,
transform=torchvision.transforms.ToTensor())
dataloader_train=DataLoader(datasets_train,batch_size=24,drop_last=True)
dataloader_test=DataLoader(datasets_test,batch_size=64,drop_last=True)
img,target=datasets_train[0]
print(img.shape)
class VGG(nn.Module):
def __init__(self):
super(VGG, self).__init__()
self.MyVgg=nn.Sequential(
nn.Conv2d(3,64,3,1,1),
nn.Conv2d(64,64,3,1,1),
nn.MaxPool2d(2,2),
nn.Conv2d(64,128,3,1,1),
nn.Conv2d(128, 128, 3, 1, 1),
nn.MaxPool2d(2,2),
nn.Conv2d(128,256,3,1,1),
nn.Conv2d(256,256,3,1,1),
nn.Conv2d(256,256,3,1,1),
nn.MaxPool2d(2,2),
nn.Conv2d(256,512,3,1,1),
nn.Conv2d(512,512,3,1,1),
nn.Conv2d(512,512,3,1,1),
nn.MaxPool2d(2,2),
nn.Conv2d(512,512,3,1,1),
nn.Conv2d(512,512,3,1,1),
nn.Conv2d(512,512,3,1,1),
nn.MaxPool2d(2,2),
nn.Flatten(),
nn.Linear(25088,4096), #7×7×512
nn.Linear(4096,4096),
nn.Linear(4096,1000)
)
def forward(self,x):
x=self.MyVgg(x)
return x
fenlei=VGG()
from torch import nn
los_fun=nn.CrossEntropyLoss()
learning_rate=0.001
optimizer=torch.optim.SGD(fenlei.parameters(),lr=learning_rate)
total_train_step=0
tatal_test_step=0
epoch=10
#定义训练设备
device=torch.device('cuda'if torch.cuda.is_available()else 'cpu')
fenlei.to(device)
los_fun=los_fun.to(device)
for i in range(epoch):
print("--------第{}轮训练开始-----".format(i+1))
for data in dataloader_train:
imgs,targets=data
imgs=imgs.to(device)
targets=targets.to(device)
outputs = fenlei(imgs)
loss=los_fun(outputs,targets)
optimizer.zero_grad()
loss.backward()
total_train_step=total_train_step+1
if total_train_step%10==0:
print("训练次数:{},Loss:{}".format(total_train_step, loss))
为啥人家的代码训练这么快?
在PyTorch中,nn.Dropout和nn.ReLU是常用的神经网络模块,分别用于正则化和激活函数。
nn.Dropout是一种正则化技术,旨在减少神经网络的过拟合问题。过拟合是指模型在训练集上表现很好,但在测试集上表现较差的现象。Dropout通过在训练过程中随机将一定比例的神经元置为0,以强制网络学习到冗余特征,从而提高模型的泛化能力。这可以防止过拟合,并提高网络的鲁棒性。
nn.ReLU是一种常用的激活函数,它被广泛应用在神经网络中。ReLU的全称是Rectified Linear Unit,它的定义很简单:对于输入x,当x小于0时,输出为0;当x大于等于0时,输出为x。ReLU函数的优点是计算简单、非线性、减轻梯度消失等。
在神经网络中,ReLU函数能够引入非线性,增加模型的拟合能力,并且减少梯度消失问题。当输入为负时,ReLU将输出为0,这有助于稀疏表示,从而使得网络更加有效地学习特征。
综上所述,nn.Dropout用于减少过拟合,提高泛化能力,而nn.ReLU用于引入非线性和解决梯度消失问题。它们在神经网络中的应用非常常见,并且经过广泛验证的有效技术。
明天看录播有助于理解他的代码:
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
transform_train = transforms.Compose(
[transforms.Pad(4),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
transforms.RandomHorizontalFlip(),
transforms.RandomGrayscale(),
transforms.RandomCrop(32, padding=4),
])
transform_test = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))]
)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
trainLoader = torch.utils.data.DataLoader(trainset, batch_size=24, shuffle=True)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
testLoader = torch.utils.data.DataLoader(testset, batch_size=24, shuffle=False)
vgg = [96, 96, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M']
class VGG(nn.Module):
def __init__(self, vgg):
super(VGG, self).__init__()
self.features = self._make_layers(vgg)
self.dense = nn.Sequential(
nn.Linear(512, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
)
self.classifier = nn.Linear(4096, 10)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.dense(out)
out = self.classifier(out)
return out
def _make_layers(self, vgg):
layers = []
in_channels = 3
for x in vgg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
layers += [nn.AvgPool2d(kernel_size=1, stride=1)]
return nn.Sequential(*layers)
model = VGG(vgg)
# model.load_state_dict(torch.load('CIFAR-model/VGG16.pth'))
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=5e-3)
loss_func = nn.CrossEntropyLoss()
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.4, last_epoch=-1)
total_times = 40
total = 0
accuracy_rate = []
def test():
model.eval()
correct = 0 # 预测正确的图片数
total = 0 # 总共的图片数
with torch.no_grad():
for data in testLoader:
images, labels = data
images = images.to(device)
outputs = model(images).to(device)
outputs = outputs.cpu()
outputarr = outputs.numpy()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
accuracy = 100 * correct / total
accuracy_rate.append(accuracy)
print(f'准确率为:{accuracy}%'.format(accuracy))
for epoch in range(total_times):
model.train()
model.to(device)
running_loss = 0.0
total_correct = 0
total_trainset = 0
for i, (data, labels) in enumerate(trainLoader, 0):
data = data.to(device)
outputs = model(data).to(device)
labels = labels.to(device)
loss = loss_func(outputs, labels).to(device)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
_, pred = outputs.max(1)
correct = (pred == labels).sum().item()
total_correct += correct
total_trainset += data.shape[0]
if i % 1000 == 0 and i > 0:
print(f"正在进行第{i}次训练, running_loss={running_loss}".format(i, running_loss))
running_loss = 0.0
test()
scheduler.step()
# torch.save(model.state_dict(), 'CIFAR-model/VGG16.pth')
accuracy_rate = np.array(accuracy_rate)
times = np.linspace(1, total_times, total_times)
plt.xlabel('times')
plt.ylabel('accuracy rate')
plt.plot(times, accuracy_rate)
plt.show()
print(accuracy_rate)