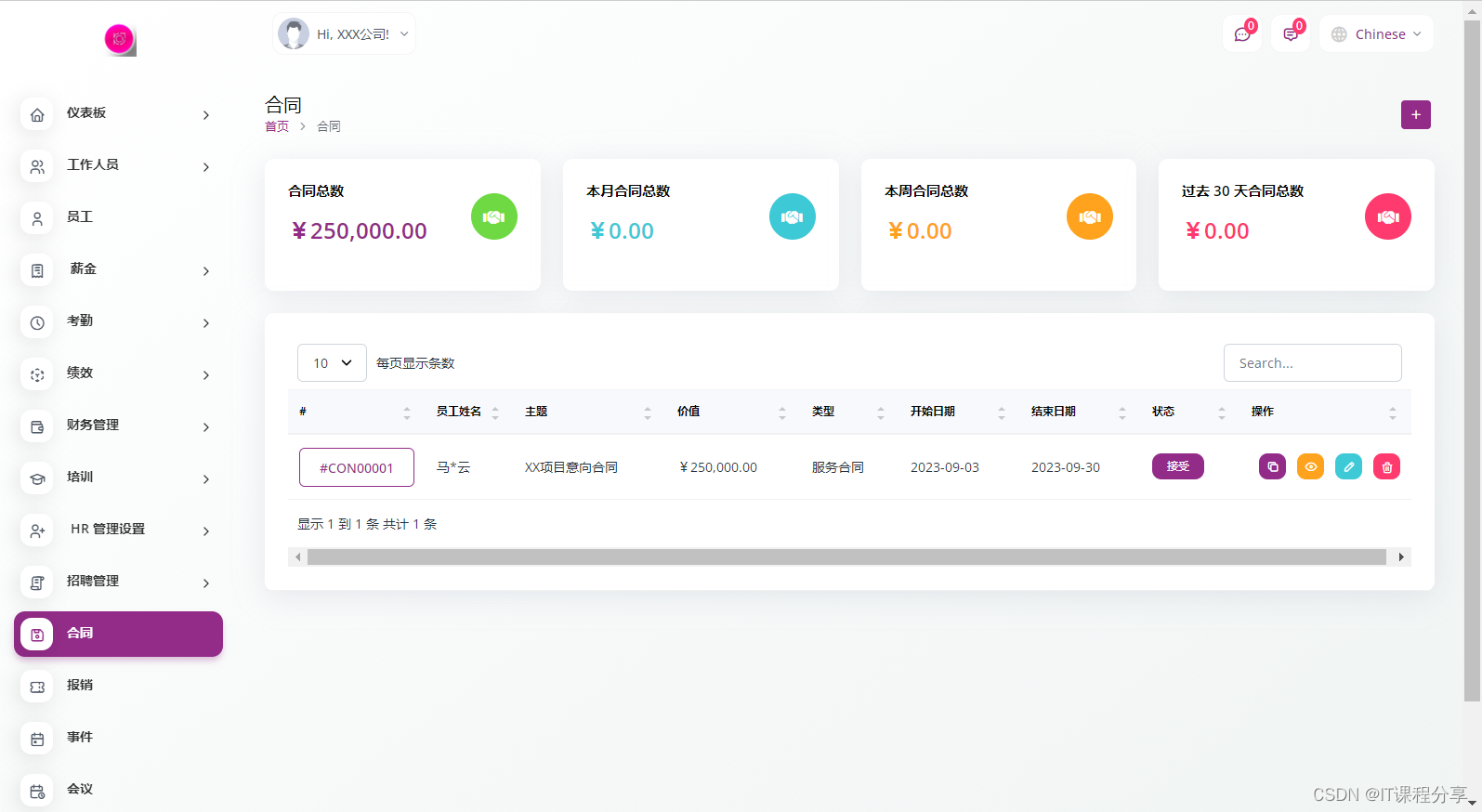
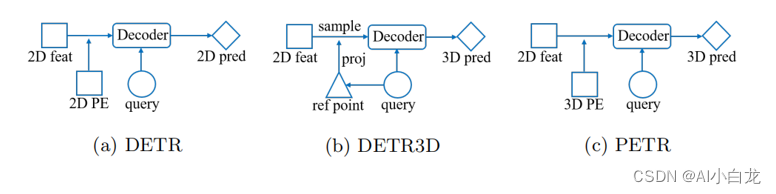
1.PETR
PETR网络结构如下,主要包括image-backbone, 3D Coordinates Generator, 3D Position Encoder, transformer Decoder
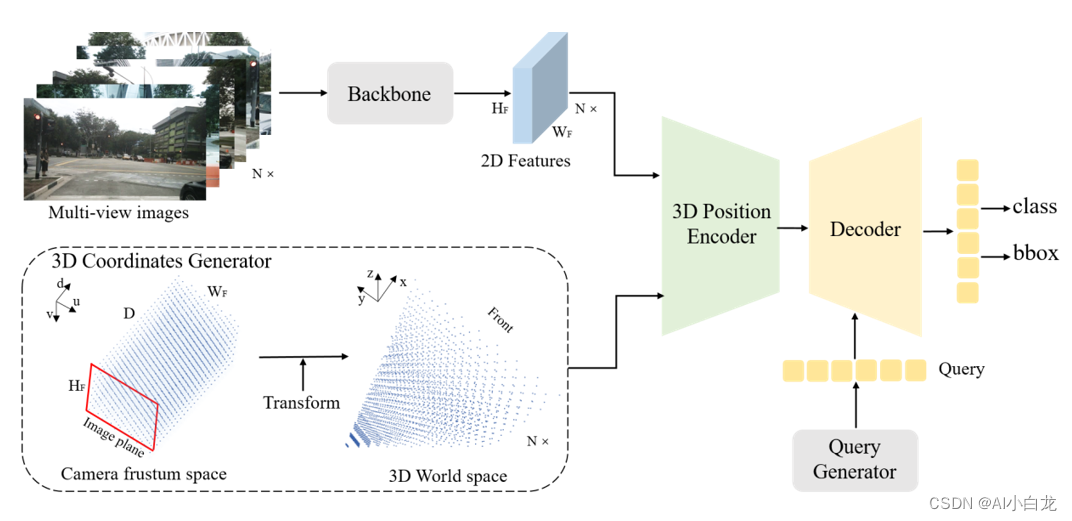
1.1 Images Backbone
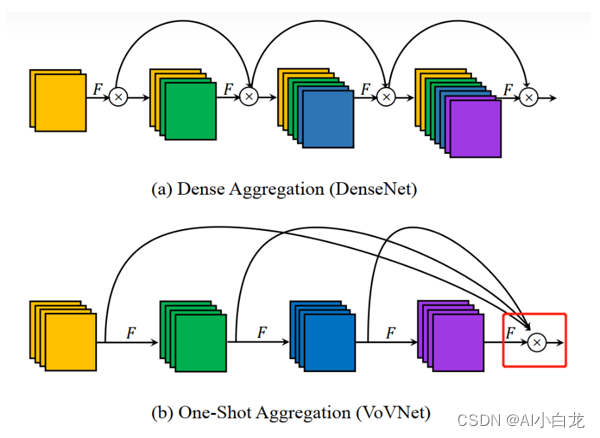
采用resnet 或者 vovNet,下面的x表示concatenate
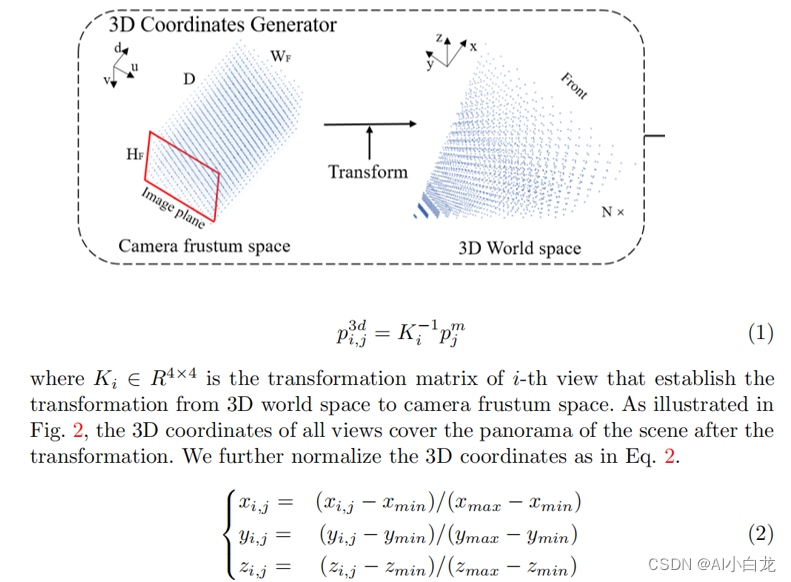
1.2 3D Coordinates Generator
坐标生成跟lss类似,假设一系列深度值,再有相机内存进行坐标转换
1.3 3D Position Encoder
将多视图2D图像特征输入到1×1卷积层以进行降维。这个由三维坐标生成器生成的三维坐标被转换为通过多层感知的3D位置嵌入。3D位置嵌入与同一视图的2D图像特征相加,生成3D位置感知功能。最后,3D位置感知特征被展平并且用作变换器解码器的输入。
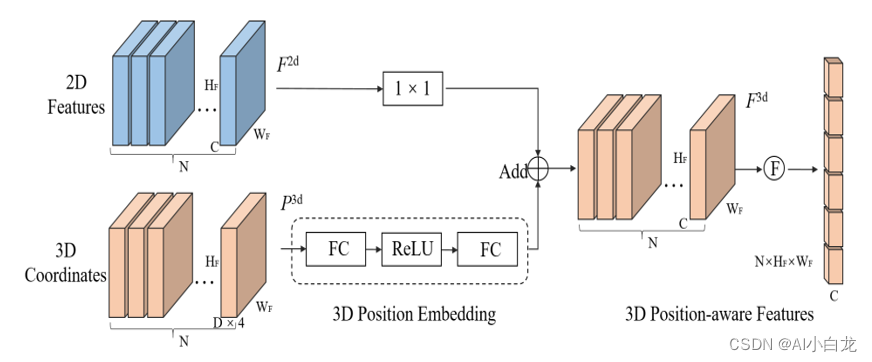
这里2D部分是经过三角函数编码后与3DpositionEmb相加作为K, 原始的iamge feature作为V 输入transformerDecoder
1.4 Transformer Decoder
DET Query Generator
为了缓解在3D场景中的收敛困难,类似于Anchor DETR,我们首先在均匀分布的3D世界空间中初始化一组可学习的锚点从0到1。然后将3D锚点的坐标输入到小MLP具有两个线性层的网络,并生成初始对象查询Q0。在我们的实践中,在三维空间中使用锚点可以保证收敛在采用DETR中的设置或生成锚点的同时在BEV空间中不能实现令人满意的检测性能。
1.5 测试
训练资源如下:

代码执行图:
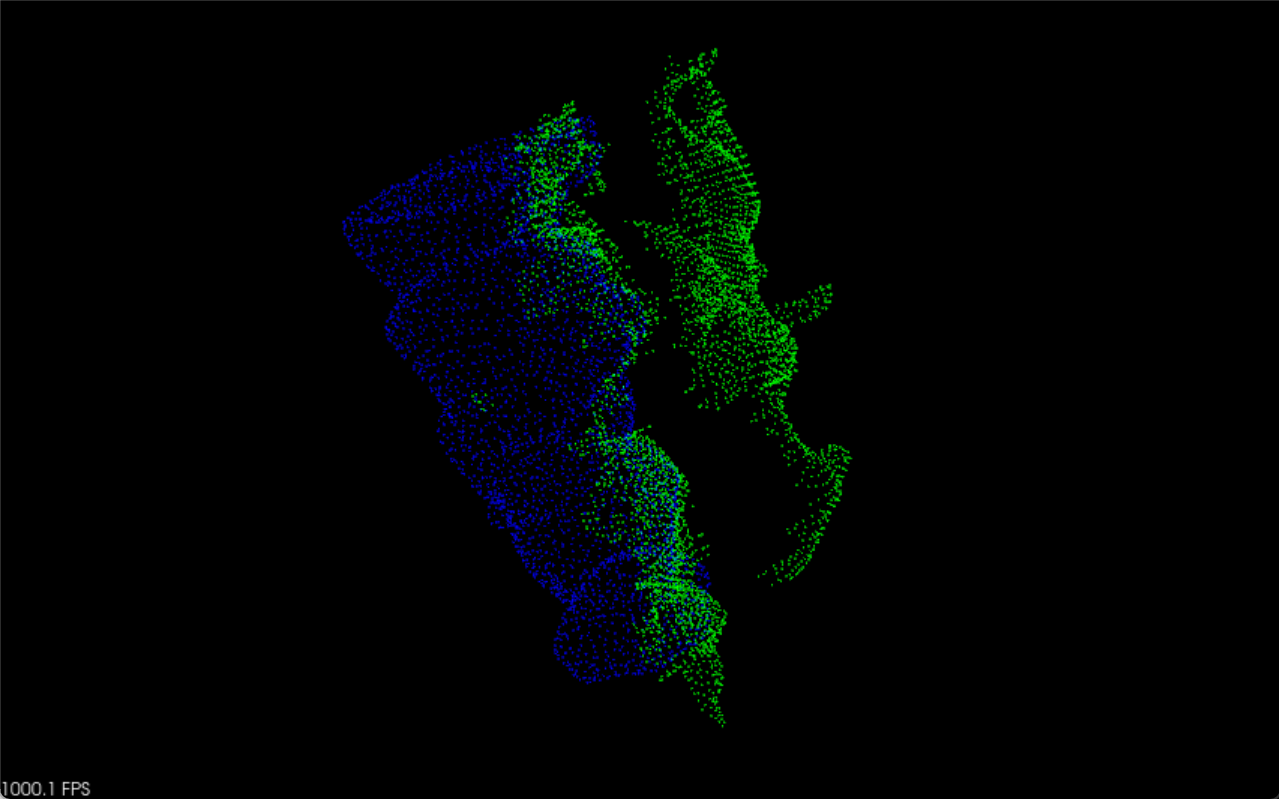
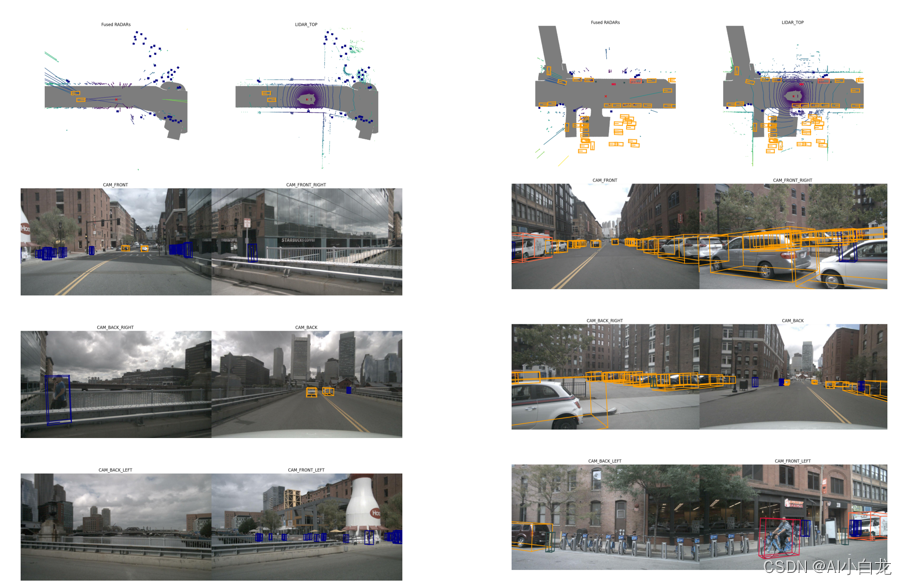
可视化效果
时延测试:
| extract_feat_time | 0.0166 |
| positional_encod_time | 0.0150 |
| transformer_time | 0.0074 |
| fnn_time | 0.0031 |
| get_bboxes_time | 0.0015 |
2. PETRV2
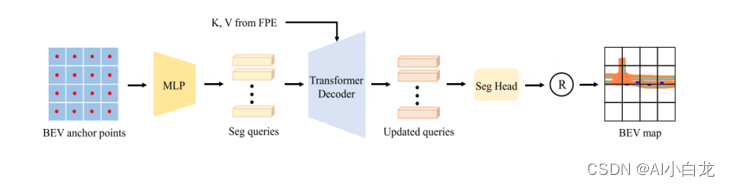
petrv2的整体框图如下,与petr不同的地方在于加入了时序模块,分割头,以及改变了 3D Position Encoder
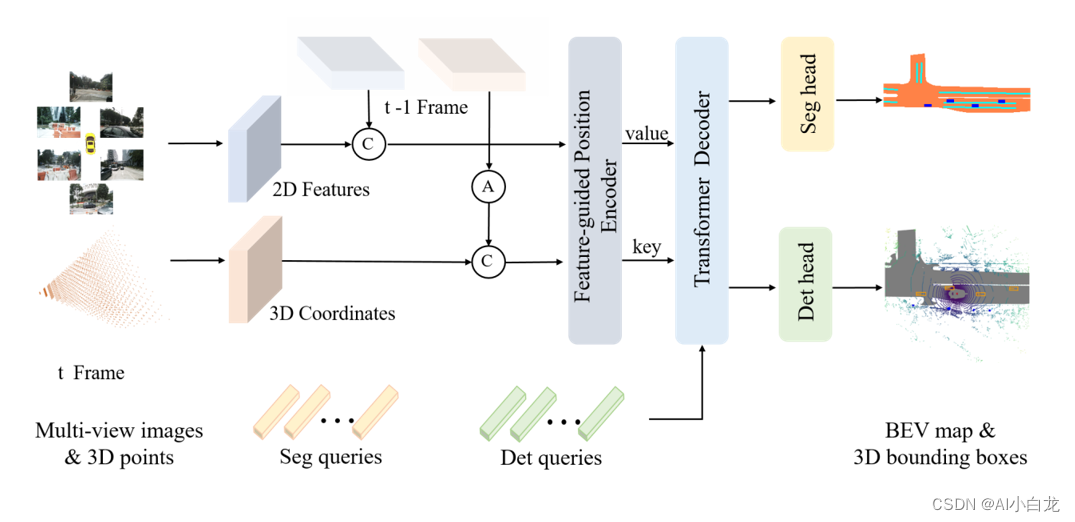
2.1 与petr差异
PE : 3D Position Encoder部分
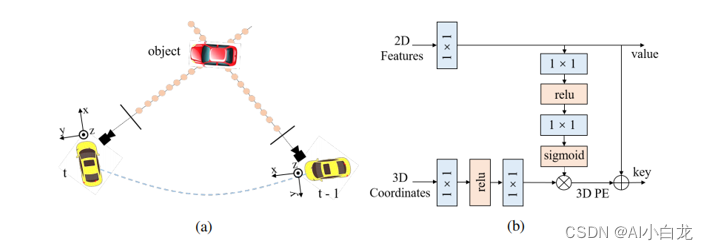
Query Generator
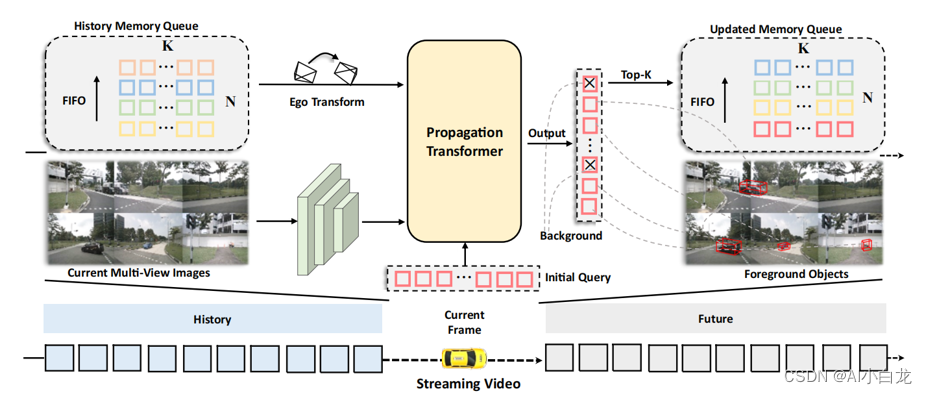
3. StreamPETR
StreamPETR的总体架构。内存队列存储历史对象查询。在Propagation Transformer中,最近的对象查询依次与历史查询和当前图像特征交互,以获得时间和空间信息。输出查询被进一步用于生成检测结果,并且前K个非背景目标查询被推送到存储器队列中。通过存储器队列的循环更新,长期时间信息被逐帧传播。
3.1 Propagation Transformer模块
Propagation Transformer和MLN 的细节。在PT中,object查询与混合查询和图像特征进行迭代交互。运动感知层规范化对运动属性进行编码(姿态、时间戳、速度),并隐式地执行补偿。不同色调的矩形象征着来自不同帧,灰色矩形表示当前帧的初始化查询,虚线矩形对应于背景查询。
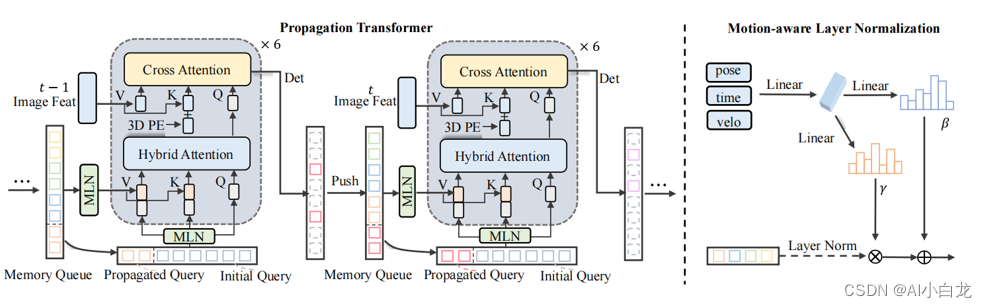
3.2 Hybrid Attention
Hybrid Attention在这里用于取代原生的self-attention。首先它起到self-attention的作用,对于当前帧的重复框进行抑制。其次,当前帧的object query还需要和历史帧object query做类似cross attention操作,进行时序的交互。 由于hybrid queries远小于cross attention中 image token的数量,因此所带来的额外计算量可以忽略不计。此外历史object query也会传递到当前帧为当前帧提供更好的初始化(propagate query)。

其他部分与petrv2模块相同