3.6 HDFS的高级功能
3.6.1 安全模式
安全模式(Safemode)是HDFS所处的一种特殊状态。处于这种状态时,HDFS只接受读数据请求,不能对文件进行写、删除等操作。安全模式是保证一个系统保密性、完整性及可使用性的一种机制,一定程度上可以防止系统里的资源遭到破坏、更改和泄露,安全模式可以使整个系统持续可靠地正常运行。若没有安全模式,则Hadoop将处在不受保护的状态,可能存在Hadoop服务将不验证用户或其他服务,攻击者可以伪装成Hadoop服务,DataNode节点不会对节点上数据块的访问实施任何访问控制。
Hadoop开发者设定了一个安全模式,以满足如下需求:
- 用户只能访问有权限访问的HDFS目录或文件。
- 用户只能访问或修改自身的MapReduce任务。
- 用户对Hadoop集群的相关服务要进行身份验证,以防未经授权的NameNode、DataNode、jobtracker或tasktracker服务。
- 服务与服务之间也需要相互认证,以防未经授权的服务。
- Kerberos凭证的获取和使用对用户和应用程序是透明的,前提是操作系统在登录时为用户获取了Kerberos票证授予票证(TGT)。Kerberos是一种计算机网络授权协议,使用在非安全网络中,对个人通信以安全的手段进行身份认证。
当启动Hadoop集群时,首先会进入安全模式,主要是为了检查系统中DataNode节点上的数据块数量和有效性。在Linux系统上启动Hadoop集群,启动完成后可以在本机的浏览器输入“http://Hadoop102:9870”网址,查看HDFS的监控服务。

Summary模块下将提示安全模式信息,默认情况下刚开启集群时将自动开启安全模式,显示“Safe mode is ON”的信息,说明安全模式已启动。
衔接的信息为“The reported blocks 0 needs additional 1376 blocks to reach the threshold 0.9990 of total blocks 1378. The minimum number of live datanodes is not required. Safe mode will be turned off automatically once the thresholds have been reached.”,这说明报告的数据块数是0块,如果要达到总数据块1378中的0.9990 (即阈值)还需要额外的1376个数据块。不需要活动数据节点的最小数目,一旦达到阈值,即使用的数据块个数达到总数据块数量的99.9%,安全模式将自动关闭。
在NameNode主节点启动时,HDFS首先进入安全模式,DataNode会向NameNode上传它们数据块的列表,让NameNode得到数据块的位置信息,并对每个文件对应的数据块副本进行统计。当最小副本条件满足时,集数据块都达到最小副本数,HDFS自动离开安全模式。
假如设置的副本数(即参数dfs.replication)是5,那么在DataNode上就应该有5个副本存在,若只有3个副本,那么比例就是3/5=0.6。默认的最小副本率是0.999。当前副本率0.6明显小于0.999,因此系统会自动地复制副本到其他的DataNode,使得副本率不小于0.999。
除了在web端查看安全模式情况外,还可以在Linux终端使用命令查看安全模式情况,安全模式的相关命令如下:
查看当前状态:
hdfs dfsadmin -safemode get
进入安全模式:
hdfs dfsadmin -safemode enter
强制离开安全模式:
hdfs dfsadmin -safemode leave
当启动Hadoop集群时集群会开启安全模式,原因是DataNode的数据块数没有达到总块数的阈值。如果没有先关闭Hadoop集群时,而直接关闭了虚拟机,那么Hadoop集群也会进入安全模式,保护系统。当再次开启Hadoop集群时,系统会一直处于安全模式不会自动解除,这时使用“hdfs dfsadmin -safemode leave”令可以解除安全模式。
一直等待直到安全模式结束:
hdfs dfsadmin -safemode wait
3.6.2 垃圾回收
HDFS为每一个用户都创建了类似操作系统的回收站(Trash),位置在/usr/用户名/.Trash/。当用户删除文件时,文件并不是马上被永久性删除,会被保留在回收站一段时间,这个保留的时间是可以设置的。当用户在保留时间内需要恢复文件时,可以到回收站进行数据的恢复。当超过保留时间用户没有进行恢复操作,文件才会被永久删除。用户也可以手动清空回收站中的内容。
- 打开回收站的相关选项
Hadoop中的Trash选项默认是关闭的,如果要使其生效,需要提前将Trash选项打开。修改conf里的core-site.xml即可打开Trash选项,相关配置如下:
<!--Enable Trash-->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>1440</value>
</property>
fs.trash.interval是指在这个保留时间之内,文件实际上是被移动到"/user/用户名/.Trash/"目录下,而不是马上把文件数据删除掉。等保留时间真正到了以后,HDFS才会将文件数据真正删除。默认的保留时间单位是分钟。1440表示保留时间为1440分钟。1440=60*24,1440分钟刚好是一天的时间。
fs.trash.checkpoint.interval则是指垃圾回收的检查时间间隔,一般小于或者等于fs.trash.interval指定的时间。
配置完成后需要重新启动hadoop集群
- 实际测试回收站的使用
示例:使用如下代码查看文件:
# 上传文件jkd到hadoop集群的/目录中
[li@hadoop102 hadoop-3.1.3]$ hadoop fs -put /opt/software/jdk-8u212-linux-x64.tar.gz /
# 查看集群/目录中的内容
[li@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /
# 删除jdk
[li@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -f /jdk-8u212-linux-x64.tar.gz
# 配置完后集群的/目录中并没有产生.Trash目录,需要删除文件后会自动生成.Trash目录
# 查看.Trash目录
[li@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /user/li
Found 1 items
drwx------ - li supergroup 0 2022-10-12 11:51 /user/li/.Trash
集群回收站在集群中的路径:/user/用户名/.Trash/。使用hadoop fs -ls 可以查看该目录。
# 查看被删除的文件
[li@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /user/li/.Trash/Current
Found 1 items
-rw-r--r-- 3 li supergroup 195013152 2022-10-12 11:49 /user/li/.Trash/Current/jdk-8u212-linux-x64.tar.gz
恢复删除的文件:
[li@hadoop102 ~]$ hadoop fs -mv /user/li/.Trash/Current/jdk-8u212-linux-x64.tar.gz /
查看恢复的文件:
[li@hadoop102 ~]$ hadoop fs -ls /
Found 3 items
-rw-r--r-- 3 li supergroup 195013152 2022-10-12 11:49 /jdk-8u212-linux-x64.tar.gz
drwxrwx--- - li supergroup 0 2022-10-12 11:48 /tmp
drwx------ - li supergroup 0 2022-10-12 11:51 /user
清空回收站:
[li@hadoop102 ~]$ hadoop fs -expunge
2022-10-12 12:07:29,588 INFO fs.TrashPolicyDefault: TrashPolicyDefault#deleteCheckpoint for trashRoot: hdfs://hadoop102:8020/user/li/.Trash
2022-10-12 12:07:29,590 INFO fs.TrashPolicyDefault: TrashPolicyDefault#deleteCheckpoint for trashRoot: hdfs://hadoop102:8020/user/li/.Trash
2022-10-12 12:07:29,599 INFO fs.TrashPolicyDefault: TrashPolicyDefault#createCheckpoint for trashRoot: hdfs://hadoop102:8020/user/li/.Trash
2022-10-12 12:07:29,604 INFO fs.TrashPolicyDefault: Created trash checkpoint: /user/li/.Trash/221012120729
3.6.3 快照
快照(Snapshot)是HDFS 2.X版本增加的基于某时间点的数据的备份(复制)。快照可以针对某个目录,或整个文件系统,即快照可以使某个损坏的目录或整个损坏的HDFS恢复到过去的一个数据正确的时间点。快照比较常见的应用场景是数据备份,以防止一些用户错误或灾难。快照相当于对目录做一个备份,并不会立即复制所有文件,而是记录文件变化。
快照的功能默认是禁用的。开启或禁用快照功能,需要针对目录操作,命令如下(表示某个目录)。
开启指定目录的快照功能
hdfs dfsadmin -allowSnapshot <snapshotDir>
禁用指定目录的快照功能
hdfs dfsadmin -disallowSnapshot <snapshotDir>
对目录创建快照
hdfs dfs -createSnapshot <snapshotDir>
指定名称创建快照
hdfs dfs -createSnapshot <snapshotDir> [<snapshotName>]
重命名快照
hdfs dfs -renameSnapshot <snapshotDir> <oldName> <newName>
列出当前用户所有可快照目录
hdfs lsSnapshottableDir
比较两个快照的不同之处
hdfs snapshotDiff <path1> <path2>
删除快照
hdfs dfs -deleteSnapshot <path> <snapshotName>
3.6.4 高可用性
NameNode主要在以下两个方面影响HDFS集群:
- NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启
- NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用
HDFS HA是指HFDS High Available,即HDFS高可用性。通常一个集群中只有一个NameNode,所有元数据由唯一的NameNode负责管理。如果该主机或进程变得不可用,整个集群将无法使用,直到NameNode恢复服务为止。这将影响集群的可用性。HDFS通过在同一个集群中运行两个NameNode不能对外提供服务的情况下,可以快速将服务转移到另一个备用的NameNode。
在典型的HDFS HA集群中,有两台独立的计算机配置为NameNode。任何时候,只有一个NameNode处于活跃(Active)状态,另一个NameNode处于备用(Standby)状态。两个NameNode上的数据保存同步,Active NameNode 负责处理集群中所有的客户端操作,而Standby NameNode只是充当从属服务器,在必要时提供快速故障恢复。
为了能够实时同步Active和Standby两个NameNode的元数据信息(实际上是edit log),需提供一个共享存储系统,可以是NFS、QJM(Quorum Journal Manager)或者Zookeeper。Active NameNode 将元数据写入共享存储系统,而Standby NameNode监听该系统,一旦发现有新数据写入,则读取这些数据,并加载到自己内存中,以保证自己内存状态与Active NameNode保持基本一致。在紧急情况下Standby NameNode便可快速切换为Active NameNode。为了实现这一目标,DataNode需要配置NameNode的信息(包括NameNode的RPC通信地址和HTTP通信地址等),并定期给这些NameNode汇报文件的数据块信息以及发送心跳信息,与NameNode保持联系。
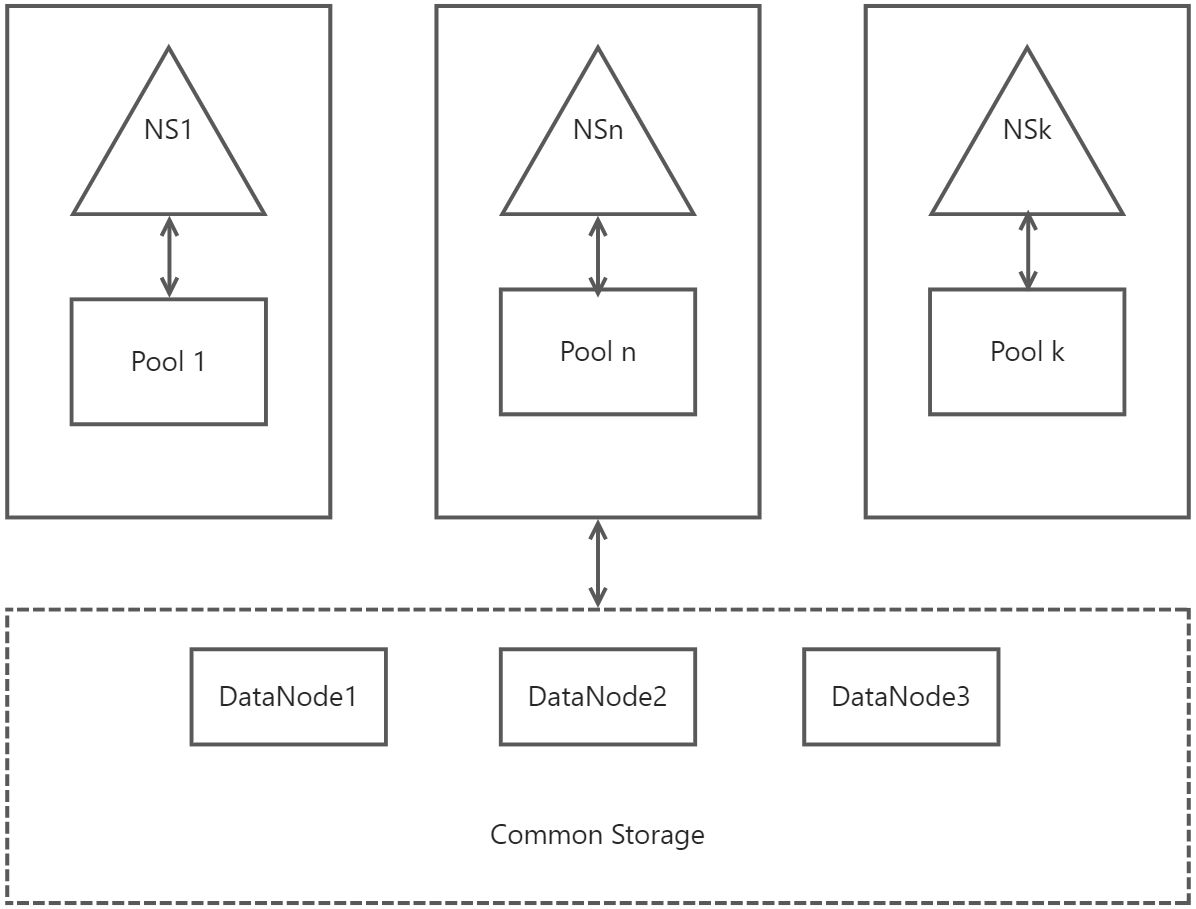
3.6.5 联邦
HDFS的Federation,即HDFS联邦,指的是HFDS有多个NameNode或NameSpace(NS),这些NameNode或NameSpace是联合的,它们相互独立且不需要互相协调,各自分工,管理自己的区域。每个NameNode或NameSpace有自己的数据块池(Block Pool),池与池之间是独立的。一个NameNode挂掉了,不会影响其他NameNode。但所有的数据块池都共享一个HDFS的存储空间。一个NameSpace和它的Block Pool作为一个管理单元。当一个NameNode或NameSpace被删除,对应于DataNodes中的数据块池也会被删除。在集群的升级过程中,每个管理单元都是以一个整体进行升级的。这里引入ClusterID来标识集群中的所有节点。当一个NameNode格式化后,这个ClusterID会生成,格式化其他NameNode时如果指定这个ClusterID,则可以使其加入到同一个集群中。