JVM垃圾回收的目标:主要针对内存中的堆空间进行垃圾回收。
Java中,大量的内存都在堆中。
程序计数器:固定大小,不涉及释放
栈:函数执行完毕,对应栈的空间就自动释放了,不需要垃圾回收
方法区:类对象加载时申请内存,类卸载时释放内存。操作低频,不涉及垃圾回收。
JVM将堆分为三块空间
- 正在使用的内存。
- 不在使用,但是尚未回收的内存
- 未分配的内存。
正在使用的内存一定不能释放。
而不在使用,但是尚未回收的内存中,一定需要回收。
一部分仍在使用的对象,一部分不在使用的对象,不进行回收。
垃圾回收的基本单位是对象而不是字节。
垃圾回收的步骤:
-
判定不使用的内存:
Ⅰ基于引用计数:非Java中采用方案(Python)
针对每个对象,额外引入一块内存,保存这个对象有多少个引用指向它。 当引用计数为0是就需要释放这块内存。 缺点: 1. 空间利用率低每个对象都有计数器,对象比较小时,计数器占用空间比例大 2. 会出现类似C++智能指针的循环引用问题。 优点:简单容易实现。Ⅱ基于可达性分析:JVM采取的方案
通过额外的线程,定期针对整个内存空间进行扫描。 从GCRoots,类似深度优先遍历,将可以访问的对象进行标记。没有被标记的对象就是不可达,需要释放的空间。 GCRoots包括: 1. 栈上的局部变量 2. 常量池中引用指向的对象. 3. 方法区中的静态成员指向的对象. 缺点:如果内存中的对象特别多,这个遍历会很慢。系统开销大 优点:克服了引用计数的两个缺点。 -
释放垃圾内存:三种基本策略
Ⅰ标记-清除:可达性分析+直接释放内存
注意:如果直接释放内存,不同对象被释放可能会导致内存碎片。 为了解决内存碎片,引入了复制算法: 将整体内存分为两部分,释放内存时,将需要保存的数据连续复制到另一半内存上,释放内存直接释放一般内存。这样解决了内存碎片。 复制算法问题: 1. 内存利用率低 2. 复制开销大Ⅱ 标记-整理:类似于顺序表删除中间元素,会将后面的元素拷贝到中间的内存碎片,从而解决内存碎片
缺点: 1. 搬运元素开销大。Ⅲ分代回收:对上述方案就行结合
根据垃圾回收周期将对象进行分类: 一个对象经过一轮GC扫描,这个对象的垃圾回收周期+1 针对不同时间周期的对象进行不同的处理:首先将内存分为下图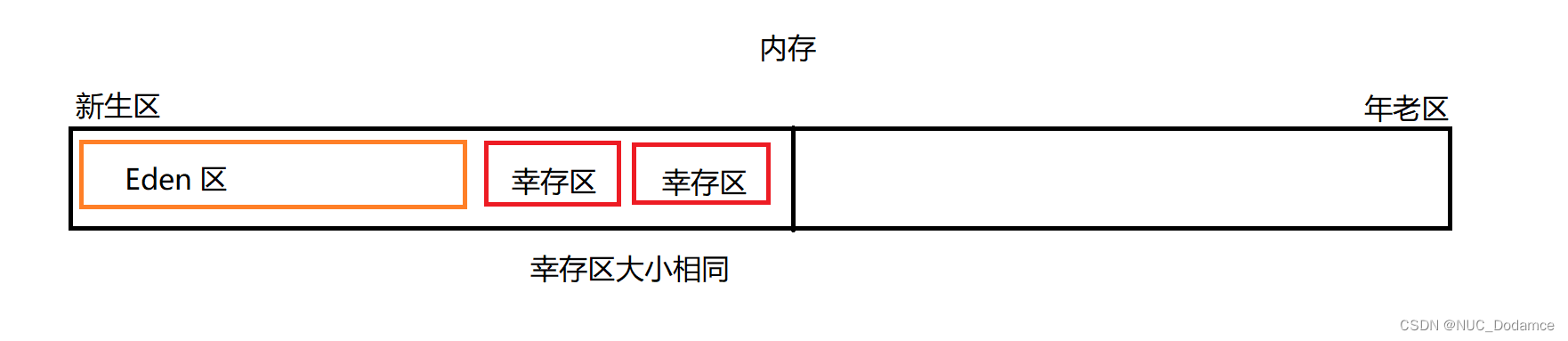
1. 刚创建的对象放到Eden区 2. Eden区的对象经过一轮GC扫描,会被拷贝到幸存区(应用复制算法) 大部分对象会在经过一轮GC扫描后被销毁,很少一部分会被拷贝到幸存区。 3. 后序的几轮GC中,幸存区之间的对象在两个幸存区之间来回拷贝 4. 持续若干轮后,进入内存老年区。(这个对象不会释放的概率很大) 老年代的GC扫描概率比较低 老年代内存使用标记-整理的方式进行内存回收。 在分代回收中,有个特殊情况:占用内存大的对象会直接进入老年区。 因为大对象拷贝成本大,不适合使用拷贝算法。
JVM垃圾回收器:在JVM中,真正实现上数算法的模块,称为垃圾回收器。
历史的垃圾回收器:
-
Serial回收器:串行垃圾回收器(扫描时业务线需要停止工作)
-
Parallel old回收器:引入多线程,并发垃圾回收器(垃圾扫描时,业务线不需要停止)
-
CMS回收器:尽可能让STW时间短
可达性分析阶段:
①初始标记:找GCRoots速度快,STW短
②并发标记:速度慢,但是于业务线并发执行,无STW
③重新标记:业务代码可能重新影响并发标记结果,这里进行微调内存释放阶段:使用标记整理法。
-
G1垃圾回收器:
给内存分成很多区域Region,给这些Region进行不同标记,给这些区域不同标记区分不同区域。在扫描中,一次扫描若干区域,不全部扫描。这样基本不影响业务代码










![[ 常用工具篇 ] 使用 kali 实现网络钓鱼 -- setoolkit 详解实战(一)](https://img-blog.csdnimg.cn/cbae5ca4b6d345f1af7d2644aeccec25.png)