文章目录
- 0 前言
- 1 基于YOLO的火焰检测与识别
- 2 课题背景
- 3 卷积神经网络
- 3.1 卷积层
- 3.2 池化层
- 3.3 激活函数:
- 3.4 全连接层
- 3.5 使用tensorflow中keras模块实现卷积神经网络
- 4 YOLOV5
- 4.1 网络架构图
- 4.2 输入端
- 4.3 基准网络
- 4.4 Neck网络
- 4.5 Head输出层
- 5 数据集准备
- 5.1 数据标注简介
- 5.2 数据保存
- 6 模型训练
- 6.1 修改数据配置文件
- 6.2 修改模型配置文件
- 6.3 开始训练模型
- 7 实现效果
- 7.1图片效果
- 7.2 视频效果
- 7.3 摄像头实时效果
- 8 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 基于深度学习的火焰识别算法研究与实现
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:4分
- 创新点:3分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 基于YOLO的火焰检测与识别
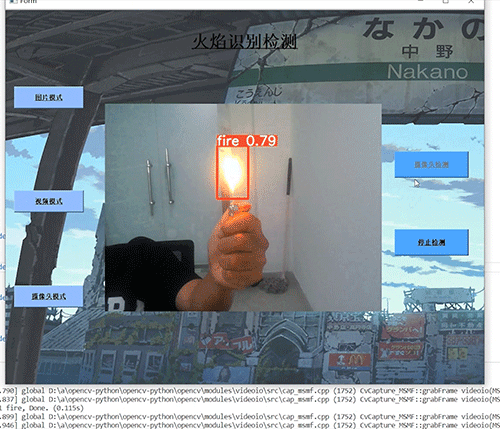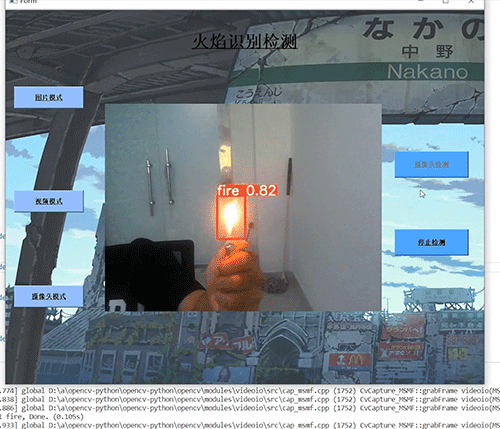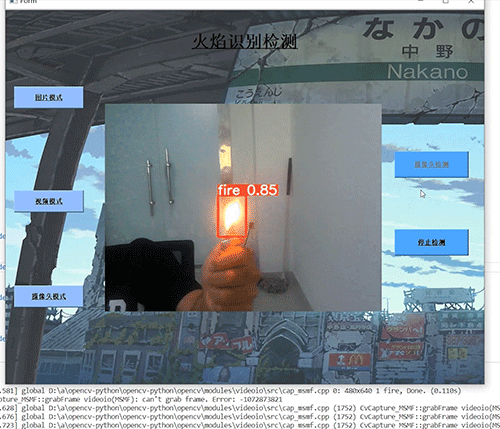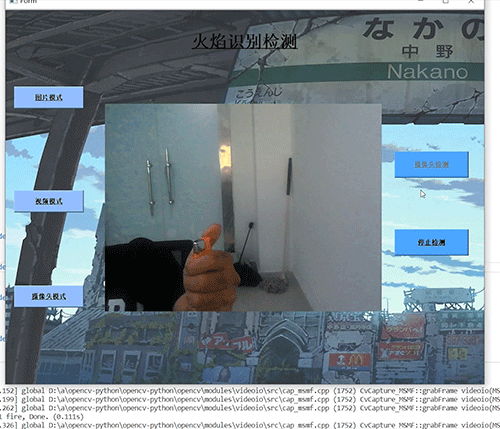
学长设计系统实现效果如下,精度不错!
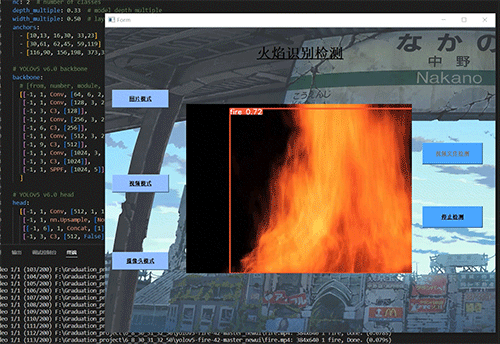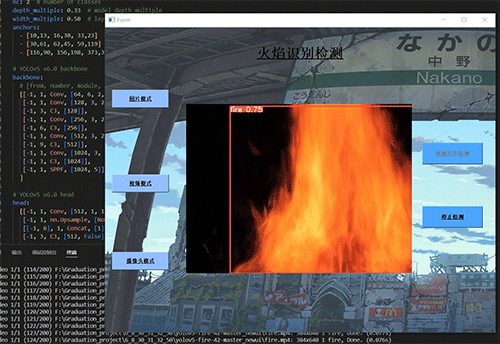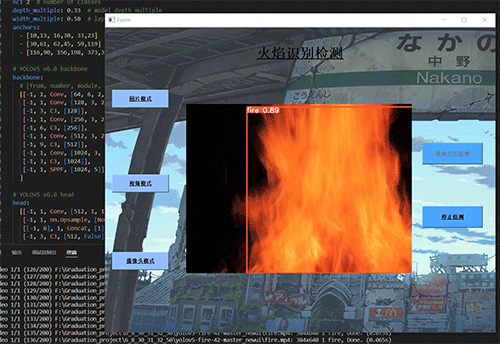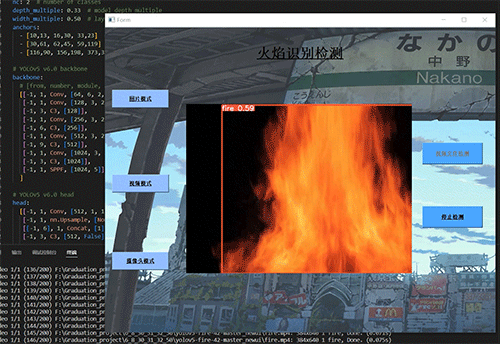
2 课题背景
火灾事故的频发给社会造成不必要的财富损失以及人员伤亡,在当今这个社会消防也是收到越来越多的注视。火灾在发生初期是很容易控制的,因此,如何在对可能发生灾害的场所进行有效监控,使得潜在的损失危害降到最低是当前研究的重点内容。传统的探测器有较大的局限性,感温、感烟的探测器的探测灵敏度相对争分夺秒的灾情控制来说有着时间上的不足,而且户外场所的适用性大大降低。随着计算机视觉的发展,基于深度学习的图像处理技术已经愈发成熟并且广泛应用在当今社会的许多方面,其在人脸识别、安防、医疗、军事等领域已经有相当一段时间的实际应用,在其他领域也展现出跟广阔的前景。利用深度学习图像处理技术对火灾场景下火焰的特征学习、训练神经网络模型自动识别火焰,这项技术可以对具有监控摄像头场景下的火灾火焰进行自动、快速、准确识别并设置预警装置,从而在火灾发生的初期及时响应,赢得更多的时间,把损失降到最低。
3 卷积神经网络
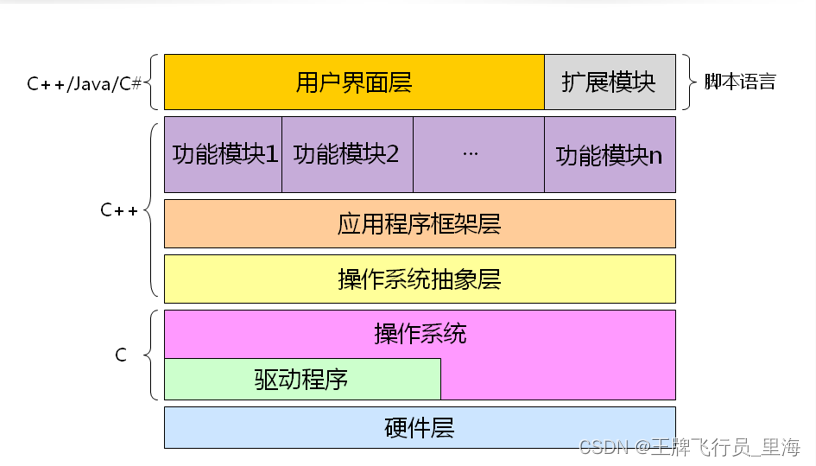
受到人类大脑神经突触结构相互连接的模式启发,神经网络作为人工智能领域的重要组成部分,通过分布式的方法处理信息,可以解决复杂的非线性问题,从构造方面来看,主要包括输入层、隐藏层、输出层三大组成结构。每一个节点被称为一个神经元,存在着对应的权重参数,部分神经元存在偏置,当输入数据x进入后,对于经过的神经元都会进行类似于:y=w*x+b的线性函数的计算,其中w为该位置神经元的权值,b则为偏置函数。通过每一层神经元的逻辑运算,将结果输入至最后一层的激活函数,最后得到输出output。
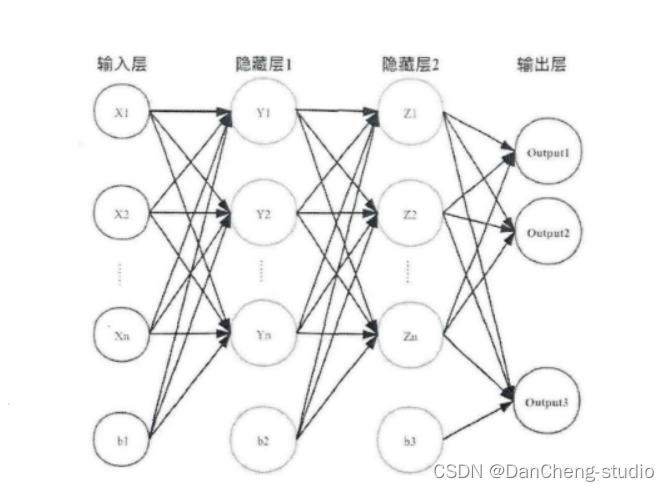
3.1 卷积层
卷积核相当于一个滑动窗口,示意图中3x3大小的卷积核依次划过6x6大小的输入数据中的对应区域,并与卷积核滑过区域做矩阵点乘,将所得结果依次填入对应位置即可得到右侧4x4尺寸的卷积特征图,例如划到右上角3x3所圈区域时,将进行0x0+1x1+2x1+1x1+0x0+1x1+1x0+2x0x1x1=6的计算操作,并将得到的数值填充到卷积特征的右上角。
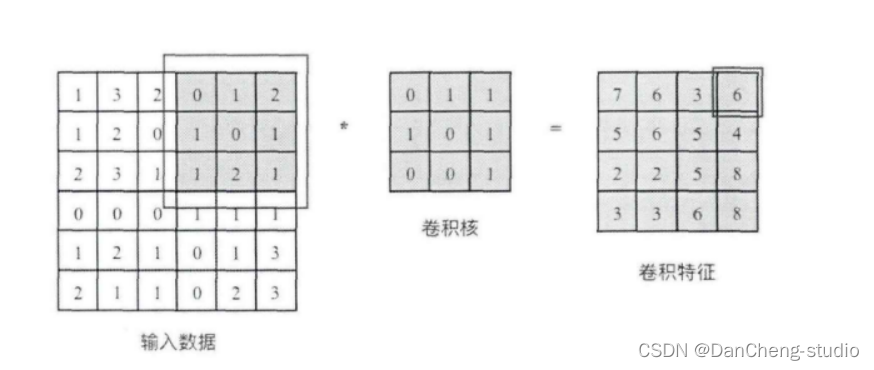
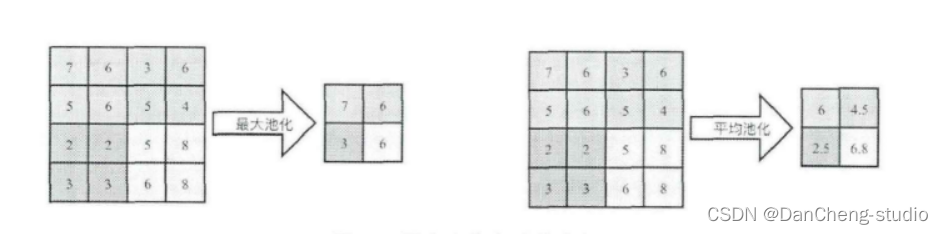
3.2 池化层
池化操作又称为降采样,提取网络主要特征可以在达到空间不变性的效果同时,有效地减少网络参数,因而简化网络计算复杂度,防止过拟合现象的出现。在实际操作中经常使用最大池化或平均池化两种方式,如下图所示。虽然池化操作可以有效的降低参数数量,但过度池化也会导致一些图片细节的丢失,因此在搭建网络时要根据实际情况来调整池化操作。
3.3 激活函数:
激活函数大致分为两种,在卷积神经网络的发展前期,使用较为传统的饱和激活函数,主要包括sigmoid函数、tanh函数等;随着神经网络的发展,研宄者们发现了饱和激活函数的弱点,并针对其存在的潜在问题,研宄了非饱和激活函数,其主要含有ReLU函数及其函数变体
3.4 全连接层
在整个网络结构中起到“分类器”的作用,经过前面卷积层、池化层、激活函数层之后,网络己经对输入图片的原始数据进行特征提取,并将其映射到隐藏特征空间,全连接层将负责将学习到的特征从隐藏特征空间映射到样本标记空间,一般包括提取到的特征在图片上的位置信息以及特征所属类别概率等。将隐藏特征空间的信息具象化,也是图像处理当中的重要一环。
3.5 使用tensorflow中keras模块实现卷积神经网络
class CNN(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(
filters=32, # 卷积层神经元(卷积核)数目
kernel_size=[5, 5], # 感受野大小
padding='same', # padding策略(vaild 或 same)
activation=tf.nn.relu # 激活函数
)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.conv2 = tf.keras.layers.Conv2D(
filters=64,
kernel_size=[5, 5],
padding='same',
activation=tf.nn.relu
)
self.pool2 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.flatten = tf.keras.layers.Reshape(target_shape=(7 * 7 * 64,))
self.dense1 = tf.keras.layers.Dense(units=1024, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self, inputs):
x = self.conv1(inputs) # [batch_size, 28, 28, 32]
x = self.pool1(x) # [batch_size, 14, 14, 32]
x = self.conv2(x) # [batch_size, 14, 14, 64]
x = self.pool2(x) # [batch_size, 7, 7, 64]
x = self.flatten(x) # [batch_size, 7 * 7 * 64]
x = self.dense1(x) # [batch_size, 1024]
x = self.dense2(x) # [batch_size, 10]
output = tf.nn.softmax(x)
return output
4 YOLOV5
我们选择当下YOLO最新的卷积神经网络YOLOv5来进行火焰识别检测。6月9日,Ultralytics公司开源了YOLOv5,离上一次YOLOv4发布不到50天。而且这一次的YOLOv5是完全基于PyTorch实现的!在我们还对YOLOv4的各种高端操作、丰富的实验对比惊叹不已时,YOLOv5又带来了更强实时目标检测技术。按照官方给出的数目,现版本的YOLOv5每个图像的推理时间最快0.007秒,即每秒140帧(FPS),但YOLOv5的权重文件大小只有YOLOv4的1/9。
目标检测架构分为两种,一种是two-stage,一种是one-stage,区别就在于 two-stage 有region
proposal过程,类似于一种海选过程,网络会根据候选区域生成位置和类别,而one-stage直接从图片生成位置和类别。今天提到的 YOLO就是一种
one-stage方法。YOLO是You Only Look Once的缩写,意思是神经网络只需要看一次图片,就能输出结果。YOLO
一共发布了五个版本,其中 YOLOv1 奠定了整个系列的基础,后面的系列就是在第一版基础上的改进,为的是提升性能。
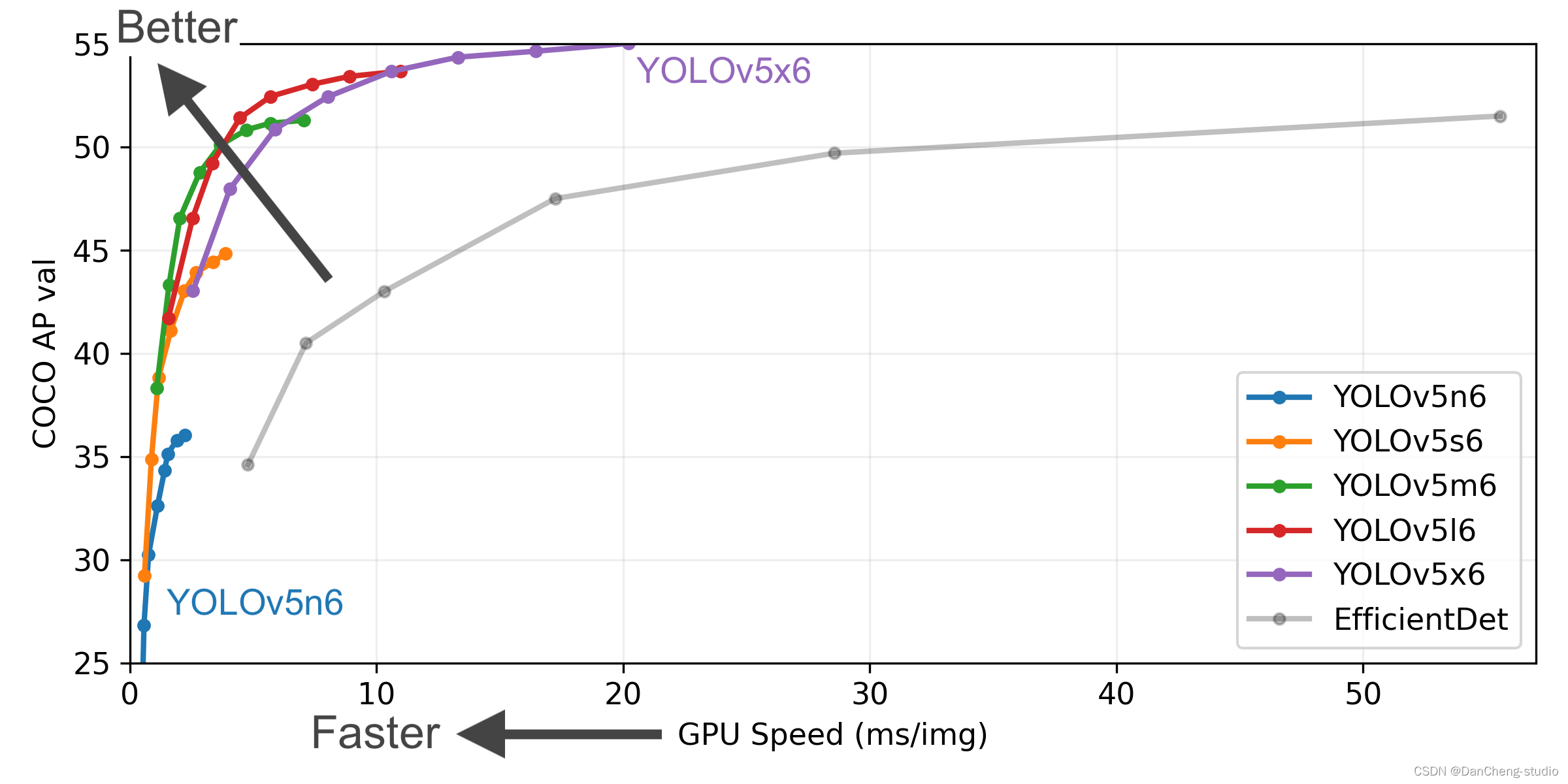
YOLOv5有4个版本性能如图所示:
4.1 网络架构图
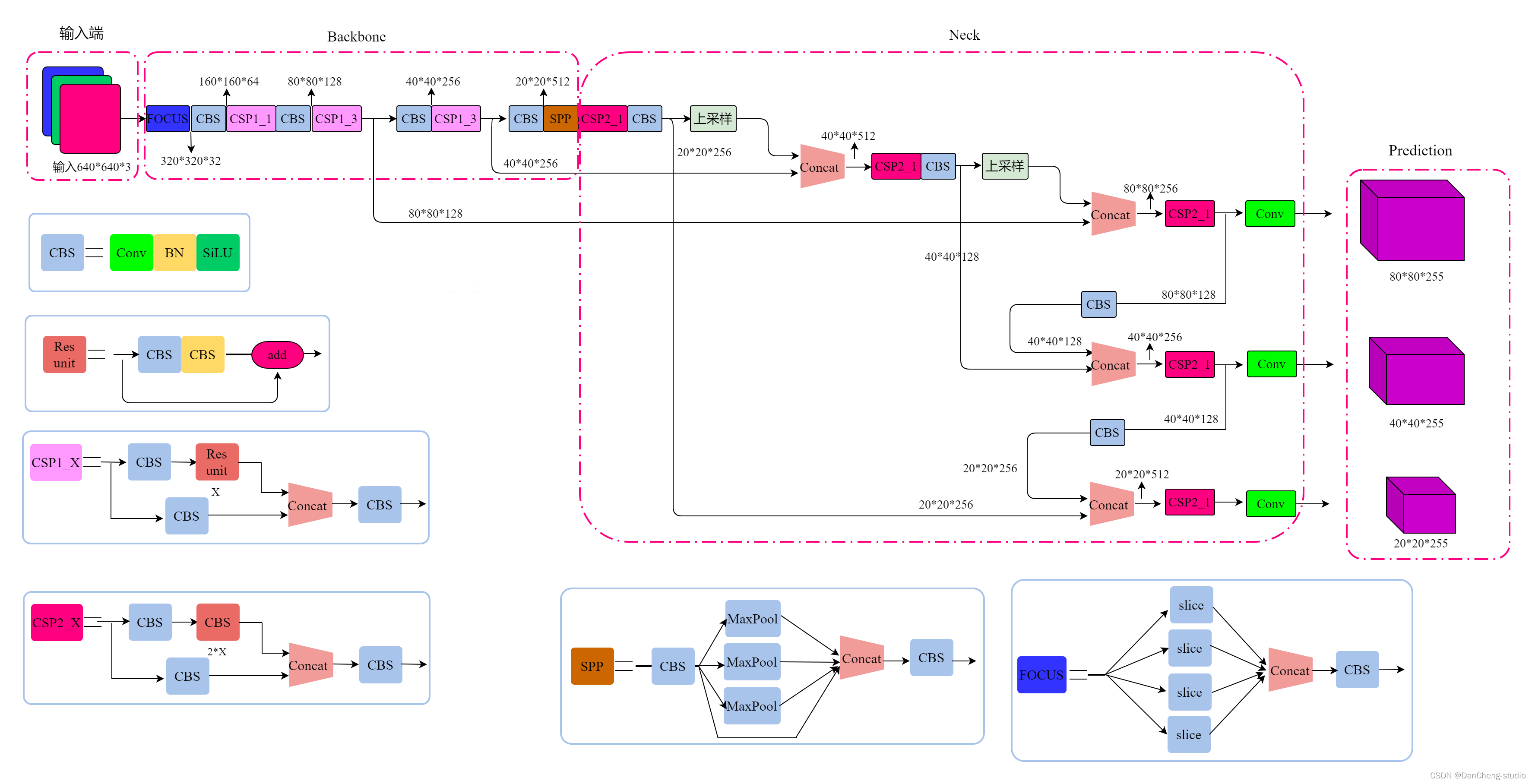
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
4.2 输入端
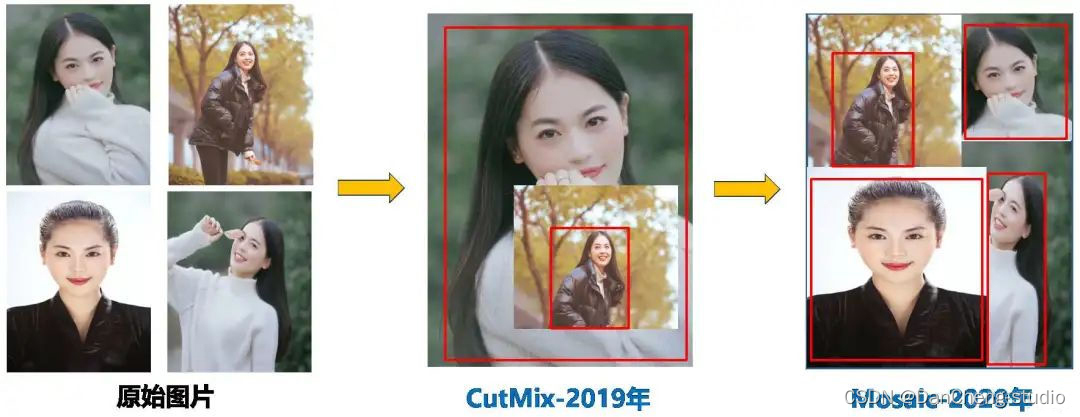
在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
- Mosaic数据增强:Mosaic数据增强的作者也是来自YOLOv5团队的成员,通过随机缩放、随机裁剪、随机排布的方式进行拼接,对小目标的检测效果很不错
4.3 基准网络
融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构;
4.4 Neck网络
在目标检测领域,为了更好的提取融合特征,通常在Backbone和输出层,会插入一些层,这个部分称为Neck。Yolov5中添加了FPN+PAN结构,相当于目标检测网络的颈部,也是非常关键的。
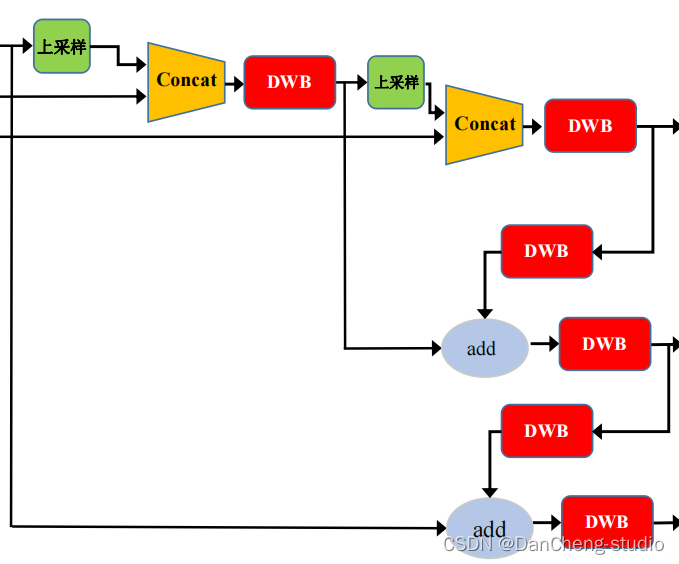
FPN+PAN的结构
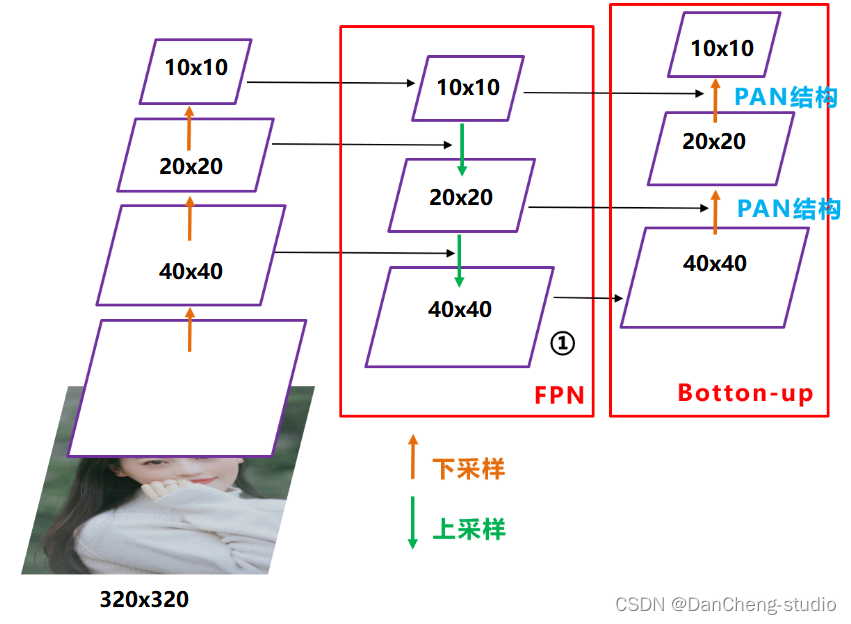
这样结合操作,FPN层自顶向下传达强语义特征(High-Level特征),而特征金字塔则自底向上传达强定位特征(Low-
Level特征),两两联手,从不同的主干层对不同的检测层进行特征聚合。
FPN+PAN借鉴的是18年CVPR的PANet,当时主要应用于图像分割领域,但Alexey将其拆分应用到Yolov4中,进一步提高特征提取的能力。
4.5 Head输出层
输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
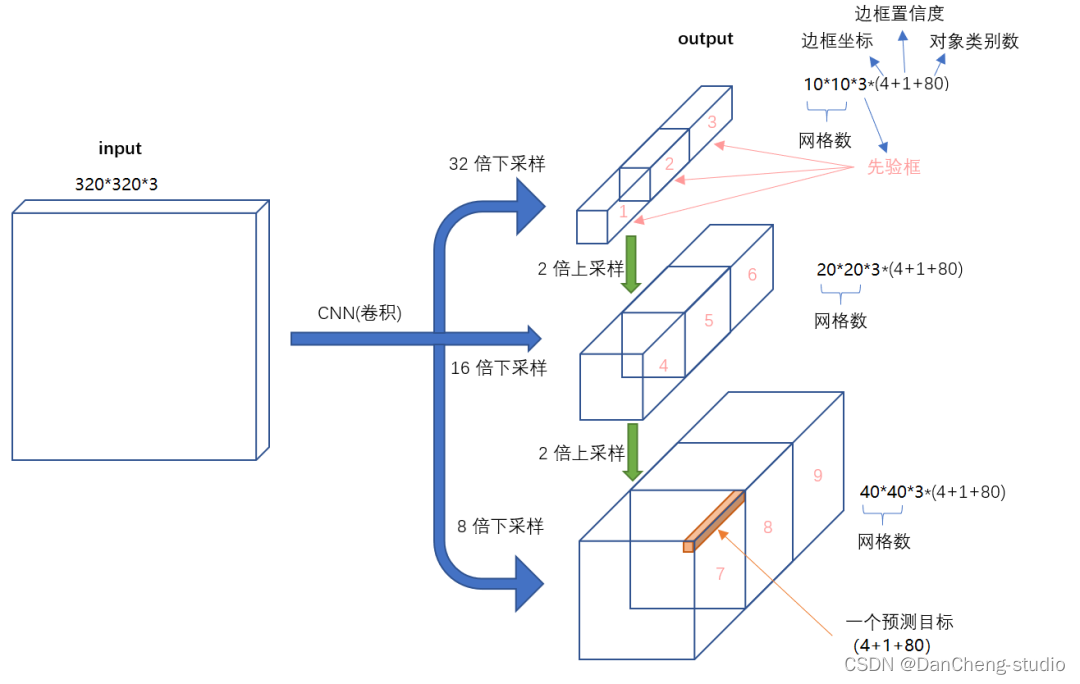
对于Head部分,可以看到三个紫色箭头处的特征图是40×40、20×20、10×10。以及最后Prediction中用于预测的3个特征图:
①==>40×40×255
②==>20×20×255
③==>10×10×255
-
相关代码
class Detect(nn.Module): stride = None # strides computed during build onnx_dynamic = False # ONNX export parameter def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer super().__init__() self.nc = nc # number of classes self.no = nc + 5 # number of outputs per anchor self.nl = len(anchors) # number of detection layers self.na = len(anchors[0]) // 2 # number of anchors self.grid = [torch.zeros(1)] * self.nl # init grid self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2) self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv self.inplace = inplace # use in-place ops (e.g. slice assignment) def forward(self, x): z = [] # inference output for i in range(self.nl): x[i] = self.m[i](x[i]) # conv bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85) x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous() if not self.training: # inference if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]: self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i) y = x[i].sigmoid() if self.inplace: y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953 xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh y = torch.cat((xy, wh, y[..., 4:]), -1) z.append(y.view(bs, -1, self.no)) return x if self.training else (torch.cat(z, 1), x) def _make_grid(self, nx=20, ny=20, i=0): d = self.anchors[i].device if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibility yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)], indexing='ij') else: yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)]) grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float() anchor_grid = (self.anchors[i].clone() * self.stride[i]) \ .view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float() return grid, anchor_grid
5 数据集准备
由于目前针对多源场景下的火焰数据并没有现成的数据集,我们使用使用Python爬虫利用关键字在互联网上获得的图片数据,爬取数据包含室内场景下的火焰、写字楼和房屋燃烧、森林火灾和车辆燃烧等场景下的火焰图片。经过筛选后留下3000张质量较好的图片制作成VOC格式的实验数据集。
深度学习图像标注软件众多,按照不同分类标准有多中类型,本文使用LabelImg单机标注软件进行标注。LabelImg是基于角点的标注方式产生边界框,对图片进行标注得到xml格式的标注文件,由于边界框对检测精度的影响较大因此采用手动标注,并没有使用自动标注软件。
考虑到有的朋友时间不足,博主提供了标注好的数据集和训练好的模型,需要请联系。
5.1 数据标注简介
通过pip指令即可安装
pip install labelimg
在命令行中输入labelimg即可打开
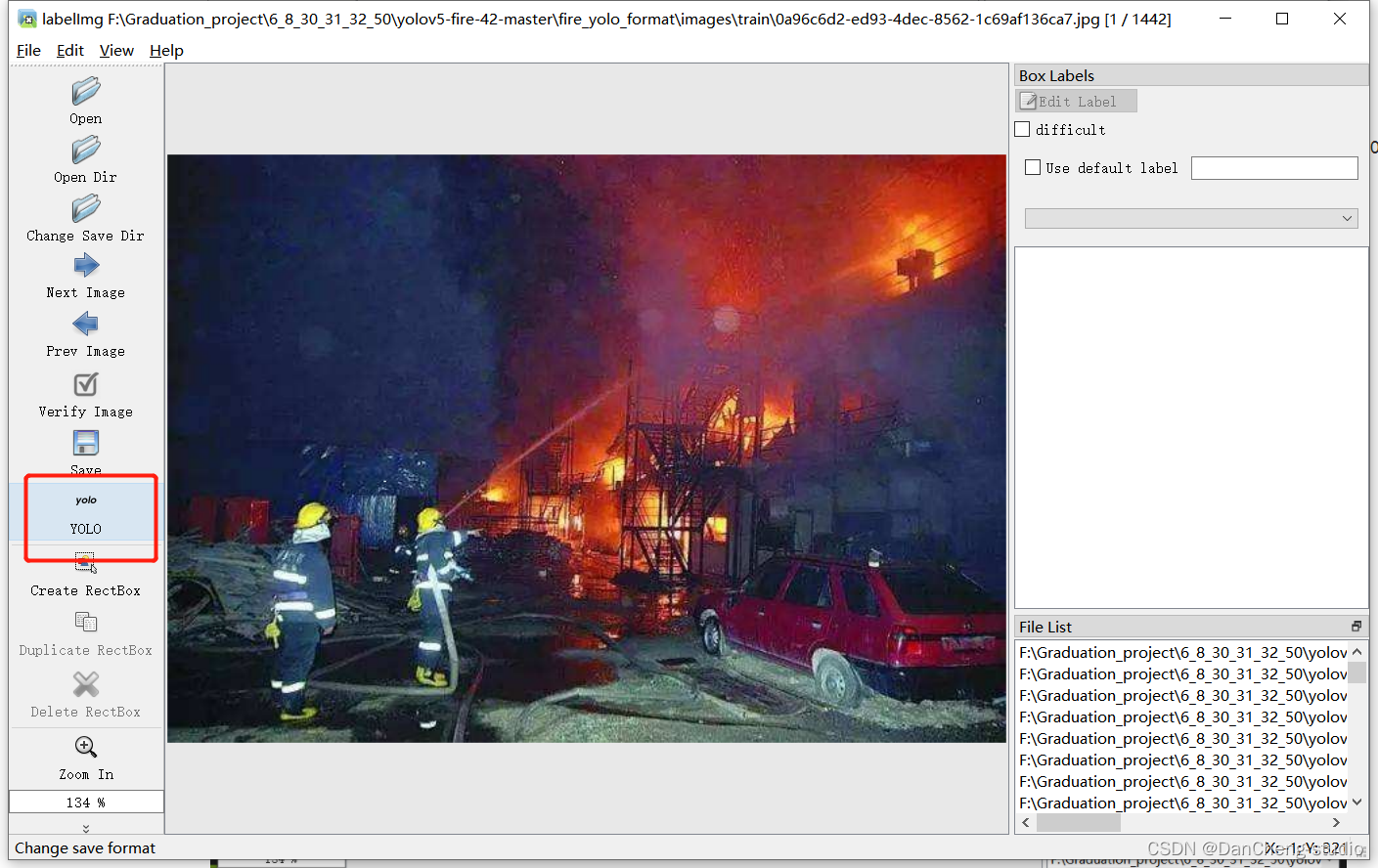
打开你所需要进行标注的文件夹,点击红色框区域进行标注格式切换,我们需要yolo格式,因此切换到yolo
点击Create RectBo -> 拖拽鼠标框选目标 -> 给上标签 -> 点击ok
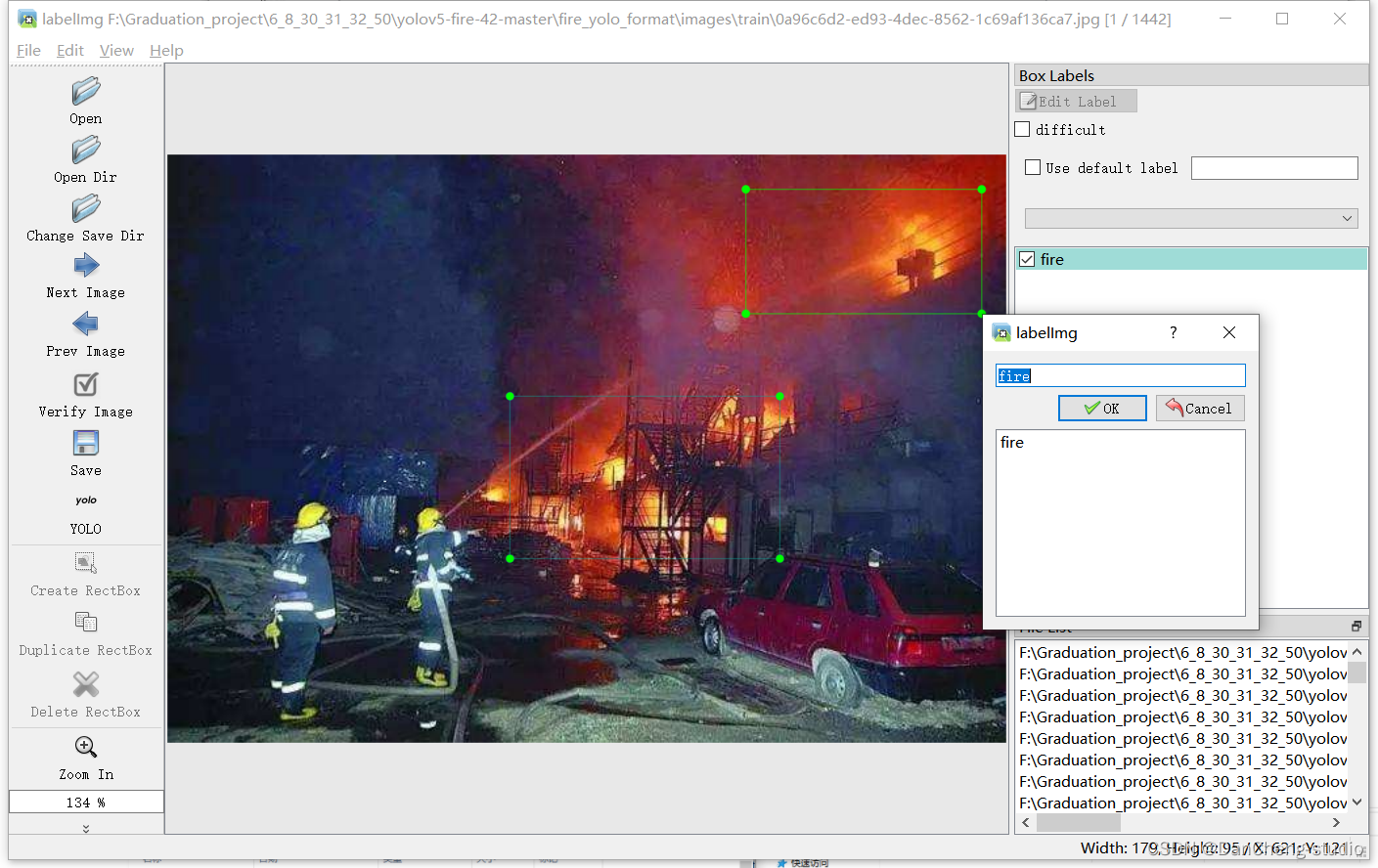
5.2 数据保存
点击save,保存txt。
打开具体的标注文件,你将会看到下面的内容,txt文件中每一行表示一个目标,以空格进行区分,分别表示目标的类别id,归一化处理之后的中心点x坐标、y坐标、目标框的w和h。

6 模型训练
预训练模型和数据集都准备好了,就可以开始训练自己的yolov5目标检测模型了,训练目标检测模型需要修改两个yaml文件中的参数。一个是data目录下的相应的yaml文件,一个是model目录文件下的相应的yaml文件。
6.1 修改数据配置文件
修改data目录下的相应的yaml文件。找到目录下的voc.yaml文件,将该文件复制一份,将复制的文件重命名,最好和项目相关,这样方便后面操作。我这里修改为fire.yaml。
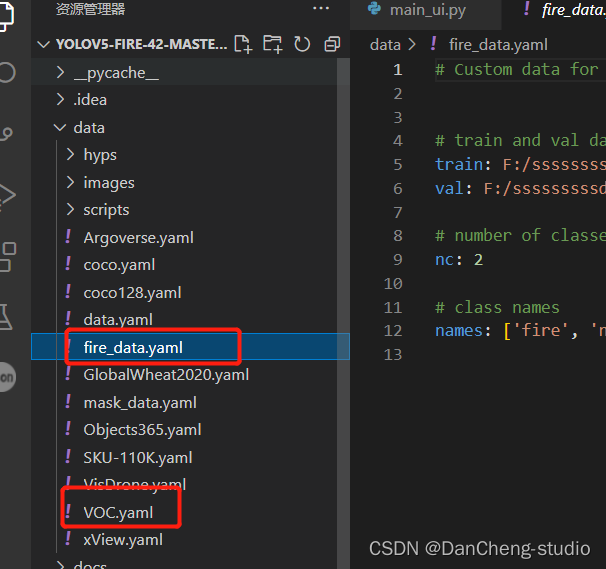
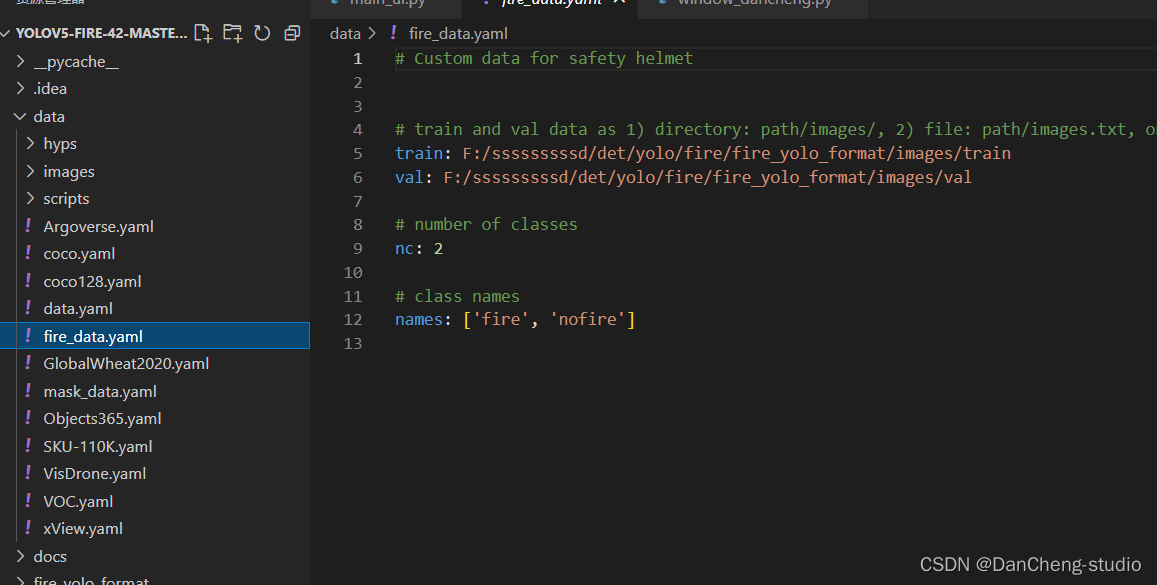
打开这个文件夹修改其中的参数,需要检测的类别数,我这里是识别有无火焰,所以这里填写2;最后箭头4中填写需要识别的类别的名字(必须是英文,否则会乱码识别不出来)。到这里和data目录下的yaml文件就修改好了。
6.2 修改模型配置文件
由于该项目使用的是yolov5s.pt这个预训练权重,所以要使用models目录下的yolov5s.yaml文件中的相应参数(因为不同的预训练权重对应着不同的网络层数,所以用错预训练权重会报错)。同上修改data目录下的yaml文件一样,我们最好将yolov5s.yaml文件复制一份,然后将其重命名
打开yolov5s.yaml文件,主要是进去后修改nc这个参数来进行类别的修改,修改如图中的数字就好了,这里是识别两个类别。
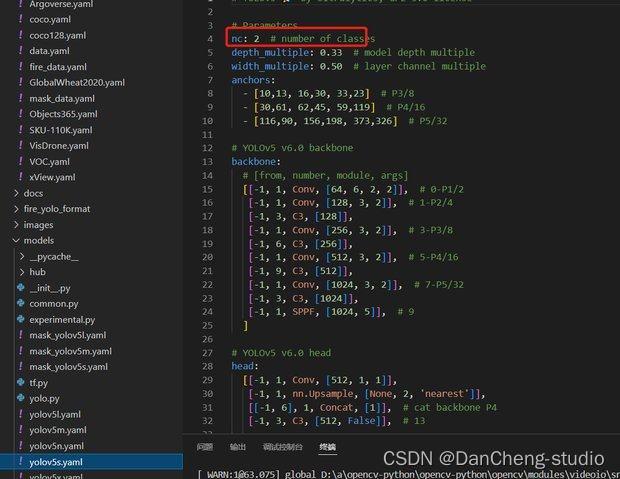
至此,相应的配置参数就修改好了。
目前支持的模型种类如下所示:

6.3 开始训练模型
如果上面的数据集和两个yaml文件的参数都修改好了的话,就可以开始yolov5的训练了。首先我们找到train.py这个py文件。
然后找到主函数的入口,这里面有模型的主要参数。修改train.py中的weights、cfg、data、epochs、batch_size、imgsz、device、workers等参数
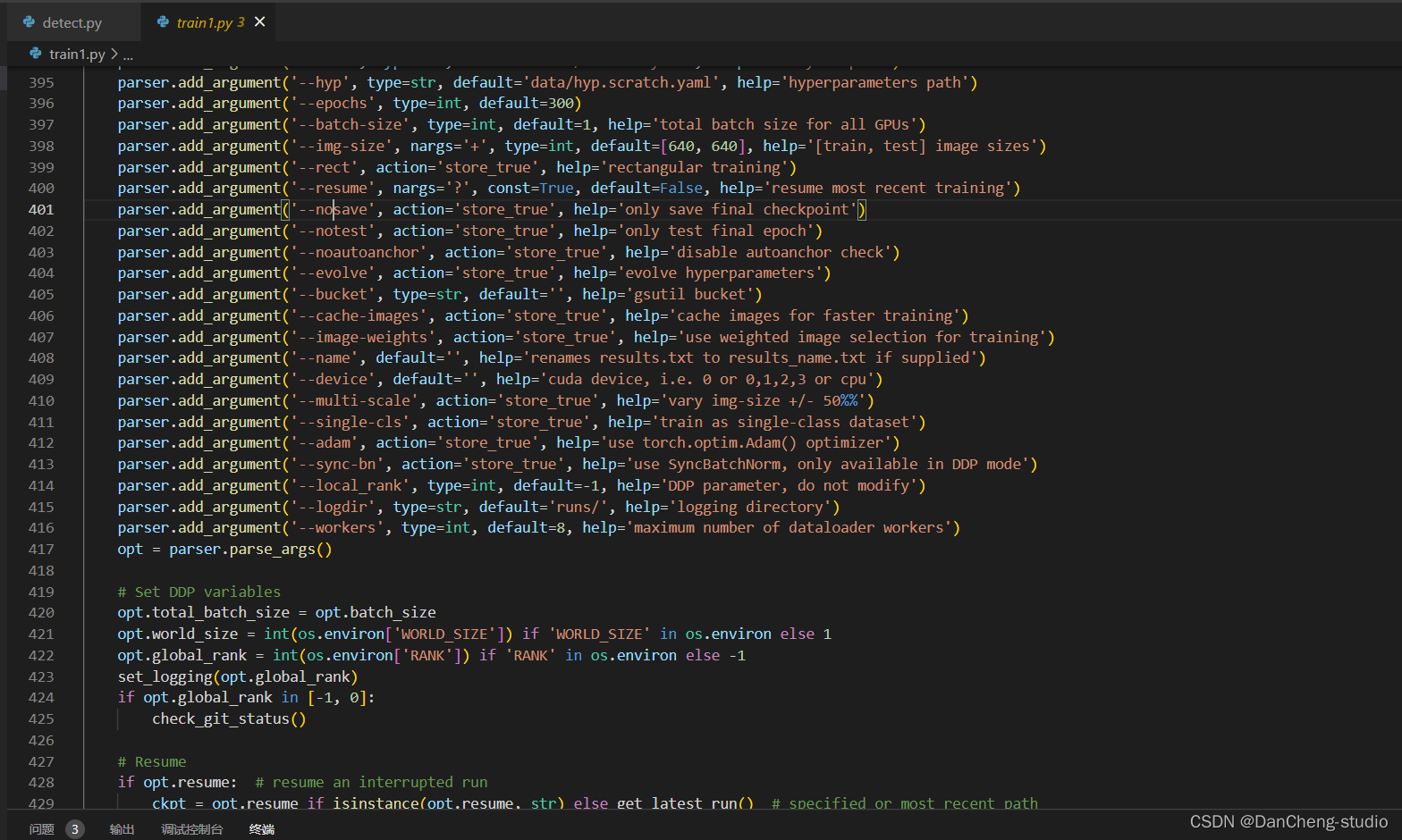
至此,就可以运行train.py函数训练自己的模型了。
训练代码成功执行之后会在命令行中输出下列信息,接下来就是安心等待模型训练结束即可。
7 实现效果
我们实现了图片检测,视频检测和摄像头实时检测接口,用Pyqt自制了简单UI
#部分代码
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_Win_mask(object):
def setupUi(self, Win_mask):
Win_mask.setObjectName("Win_mask")
Win_mask.resize(1107, 868)
Win_mask.setStyleSheet("QString qstrStylesheet = \"background-color:rgb(43, 43, 255)\";\n"
"ui.pushButton->setStyleSheet(qstrStylesheet);")
self.frame = QtWidgets.QFrame(Win_mask)
self.frame.setGeometry(QtCore.QRect(10, 140, 201, 701))
self.frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.frame.setObjectName("frame")
self.pushButton = QtWidgets.QPushButton(self.frame)
self.pushButton.setGeometry(QtCore.QRect(10, 40, 161, 51))
font = QtGui.QFont()
font.setBold(True)
font.setUnderline(True)
font.setWeight(75)
self.pushButton.setFont(font)
self.pushButton.setStyleSheet("QPushButton{background-color:rgb(151, 191, 255);}")
self.pushButton.setObjectName("pushButton")
self.pushButton_2 = QtWidgets.QPushButton(self.frame)
self.pushButton_2.setGeometry(QtCore.QRect(10, 280, 161, 51))
font = QtGui.QFont()
font.setBold(True)
font.setUnderline(True)
font.setWeight(75)
self.pushButton_2.setFont(font)
self.pushButton_2.setStyleSheet("QPushButton{background-color:rgb(151, 191, 255);}")
self.pushButton_2.setObjectName("pushButton_2")
self.pushButton_3 = QtWidgets.QPushButton(self.frame)
self.pushButton_3.setGeometry(QtCore.QRect(10, 500, 161, 51))
QtCore.QMetaObject.connectSlotsByName(Win_mask)
7.1图片效果

7.2 视频效果
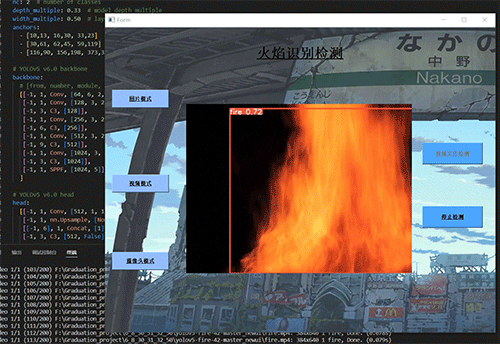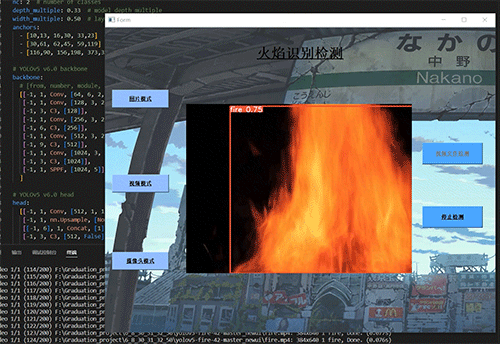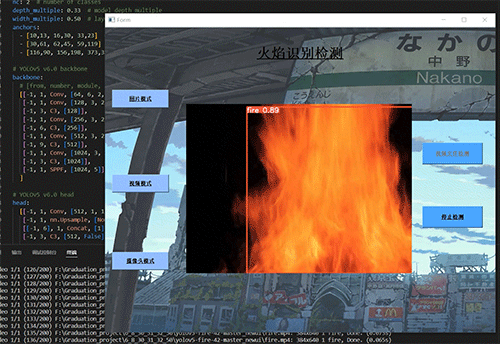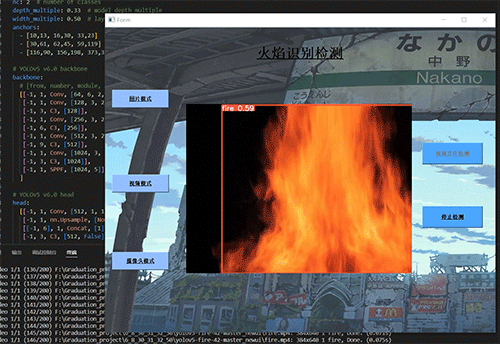
7.3 摄像头实时效果
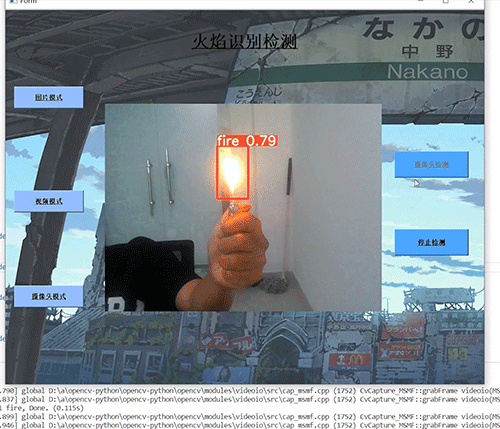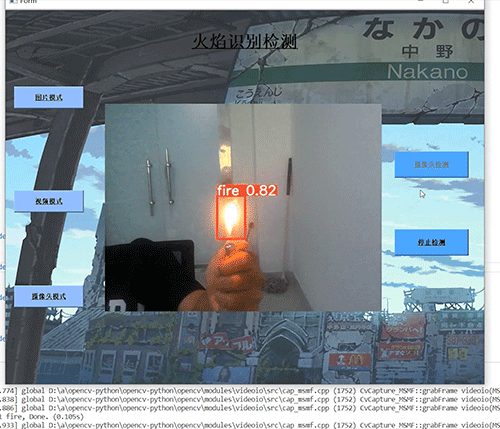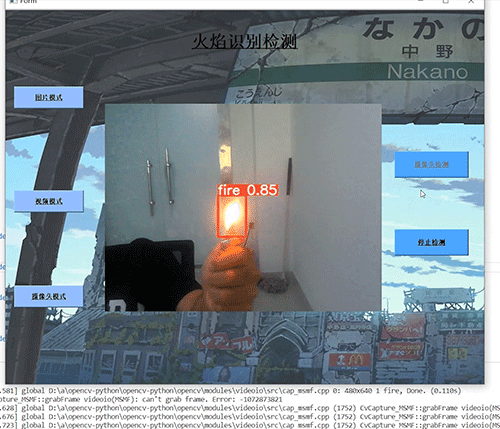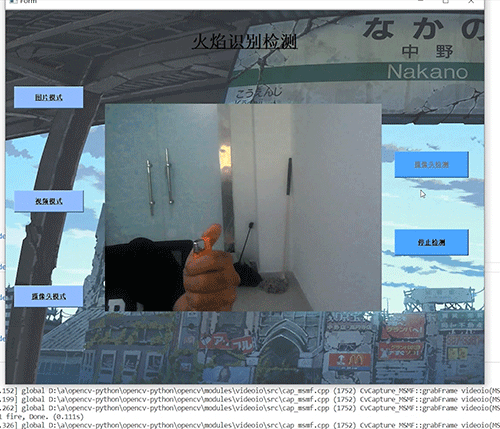
8 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate