混沌工程初分享
一、什么是混沌工程
1、什么是混沌
混沌是一种现象,在一个动力系统中,因为各种不同的参数变化导致的一系列的连锁反应。
比如:
在南美洲亚马逊河流域热带雨林中的蝴蝶,偶尔的几次振翅,可以在两周以后引起美国得克萨斯州的一场在龙卷风。
因为蝴蝶振动翅膀的行为,导致其身边的空气系统发生变化,并产生微弱的气流,而微弱的气流的产生又会引起四周空气或其他系统产生相应的变化,由此引起一个连锁反应,最终导致其他系统的极大变化。
2、什么是混沌测试
混沌测试 是一种 可试验的、基于系统 的方法来 处理大规模分布式系统中的混乱问题。
通过不断试验,观察系统的行为和反应。了解系统的实际能承受的韧性边界并建立信心,总而言之—— 以试验的方法尽早揭露系统弱点。
3、如果不做混沌测试
我们会尽可能多地编写单元测试,覆盖代码逻辑;
进行足够多的系统测试、场景覆盖测试,确保我们的系统可以与其他组件一起工作;
进行回归测试,确保新功能与老系统的兼容性等。
还会执行性能测试,用以改进处理数百万次请求的性能。
可是,这些 对于分布式系统来说还远远不够。
无论我们做了多少测试,仍然无法100%保证我们的系统能够应对生产环境的各种不可预测性。
我们可能会遇到以下的应用层、数据层、中间件层、操作系统层、存储层、网络层存在的各种问题。
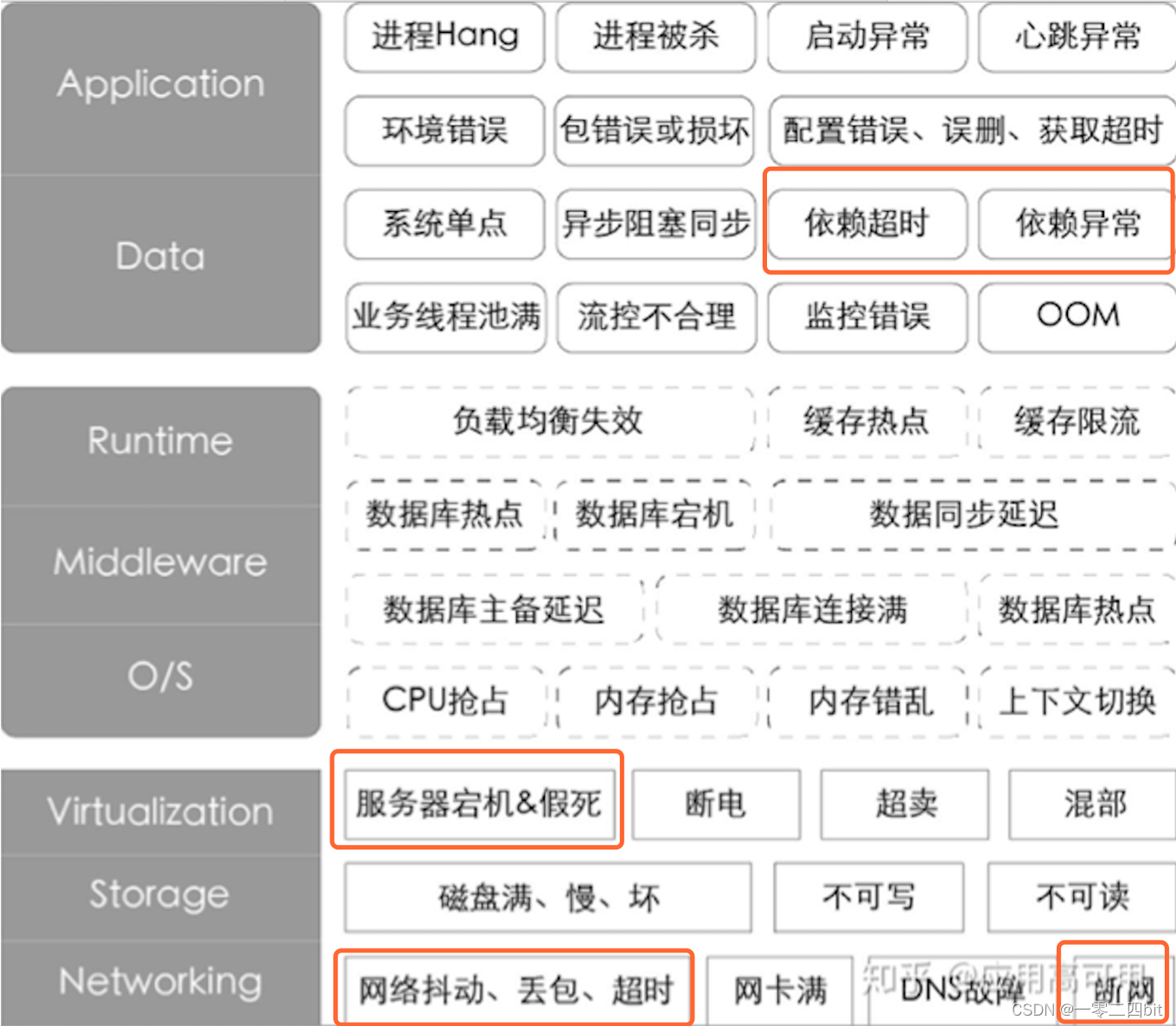
所以为了让我们的分布式系统更加健壮,我们需要注入各种可以控制的异常;
并进行全链路实时监控,全面掌握注入异常可能导致的系统问题;
从而 提升系统容错性,建立系统抵御生产环境中不可预知问题的信息。
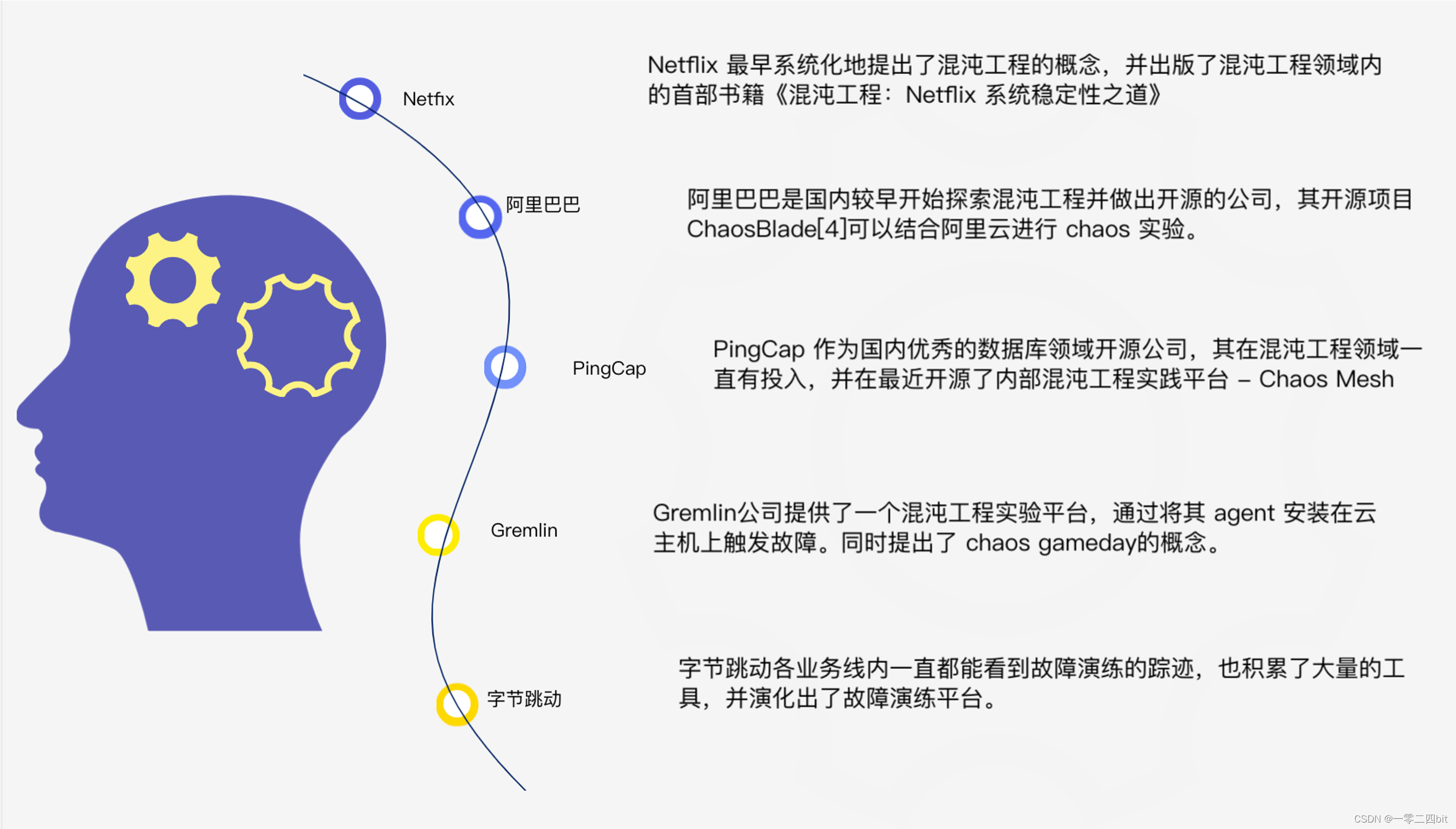
4、业内混沌工程有哪些
-
Netflix 是混沌工程的著名先驱,也是最早将其用于生产系统的公司之一。并出版了混沌工程领域内的首部书籍《混沌工程:Netflix 系统稳定性之道》,另外其开源混沌项目-Chaos Monkey (用于向基础设施以及业务系统中注入各类故障类型。这只 “猴子” 就是混沌工程起源。)
-
阿里巴巴是国内较早开始探索混沌工程并做出开源的公司,其开源项目 ChaosBlade可以结合阿里云进行 chaos 实验。
-
PingCap 作为国内优秀的数据库领域开源公司,在最近开源了内部混沌工程实践平台 - Chaos
Mesh。(一个云原生的混沌测试平台,Chaos Mesh 提供在 Kubernetes 平台上进行混沌测试的能力。让应用跟混沌在
Kubernetes 上共舞。) -
Gremlin 为一家混沌工程商业化公司,该公司提供了一个混沌工程实验平台,用于在已安装 Gremlin
守护进程(代理)的计算设备上执行和管理混沌实验。同时提出了 chaos gameday
的概念。(目的是通过有目的地、定期地、创建重大故障来提高可靠性。它们还有助于提升混沌工程的价值) -
字节跳动早期在内部使用的故障演练平台,主要通过网络干扰模拟下游依赖故障。
5、不同角色混沌测试中的任务
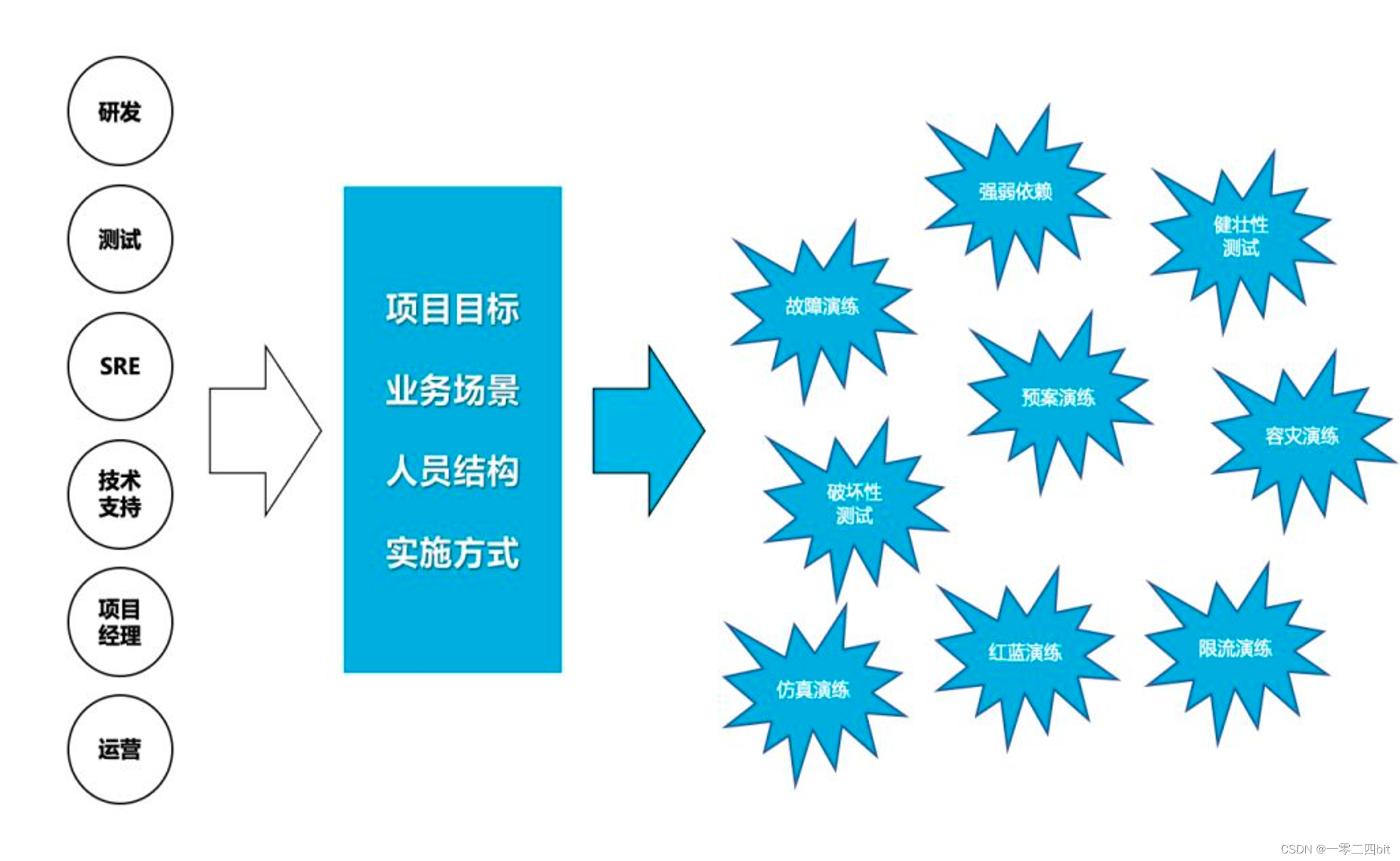
架构师:验证系统架构的容错能力
开发&运维:提高故障的应急效率
测试:提早暴露线上问题,降低故障复发率
产品&设计:提升客户使用体验
二、混沌测试梳理思路
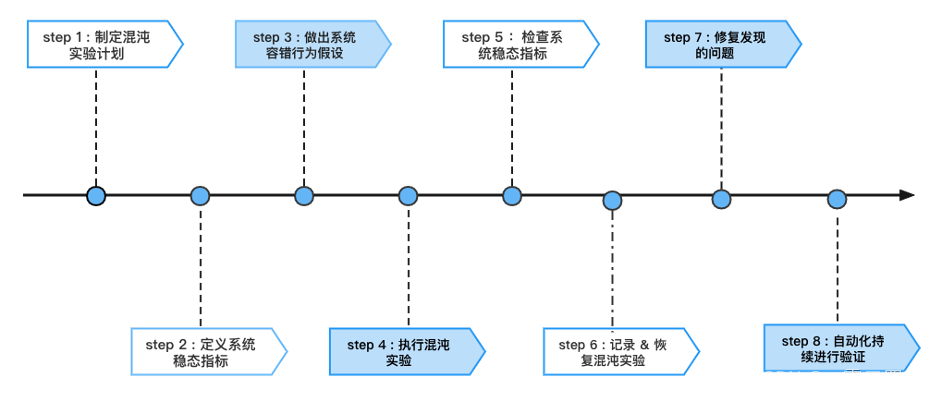
1、被测服务链路梳理
-数据链路(进直播间接口)
链路追踪:
1、使用服务链路梳理平台对被测服务的上下游依赖进行梳理
梳理服务依赖
2、强弱依赖梳理:梳理核心接口依赖,选择接口,筛选trace,选择查看深层关系依赖图
3、涉及中间件
方法A:
使用traceid 查看数据链路,同时结合代码查看 ,从代码里可得知,网关层,网关层接口有热门房间缓存 是本地缓存(需要重启容器才可清缓存)
由链路可得知,直播间接口 → 房间信息接口 → 勋章信息接口, 勋章信息接口服务依赖redis(后续注入中间件故障时,需在勋章信息接口服务进行)
方法B:服务依赖梳理平台也会罗列 mysql、redis 的配置信息,进行梳理
2、故障类型梳理
-依赖RPC服务故障:强弱依赖超时/不可用/内容异常
-中间件故障:配置中心超时/不可用,Redis 超时/不可用,Databus 超时/不可用
-机器故障:自身宕机、CPU满载、内存异常、磁盘空间满载、网卡流量满载、网络中断
-基础设施故障:数据库超时/不可用,DNS 超时/不可用,机房超时/不可用
故障类型大致分为不可用、不稳定,给出以下参考配置,给出以下参考配置
故障类型 故障配置 备注
服务不稳定
CPU占用率>=70%
内存占用率>=70%
服务网络丢包50%
服务不可用
服务超时
服务网络丢包100%
服务自身宕机(杀pod)
CPU占用率100%
内存占用率100%
数据库中间件不稳定
redis网络丢包50%
db网络丢包50%
数据库中间件不可用
redis连接超时 (注入overlord伴生容器)
redis连接报错
db连接超时
其他 配置中心超时
3、故障方式确认(故障平台)
故障注入平台 平台地址 使用指南 实现原理 支持功能 优缺点
基于chaosblade的FIT平台
uat 环境:http://uat-sre.bilibili.co/chaos/test
pre/prod 环境:http://sre.bilibili.co/chaos/test
2.1 单一实验
容器层面故障:
使用Linux中的一些kill、tc等一些命令,提供故障模拟的能力
模拟CPU负载:CPU100% 就是起个服务,真实的去占用容器的CPU资源,这个是模拟CPU争抢(处理慢或者超时,能响应 也是符合预期的)
模拟IO高:两个进行,一个读、一个写,调用dd命令实现的 IO 高模拟;
模拟端口不通:ChaosBlade 是通过 iptables 命令添加 drop 规则来实现的禁用端口;
模拟丢包: ChaosBlade 是通过 traffic control 添加过滤器队列、分类、过滤器来实现的。也就是 tc 的 netem loss。
模拟网络延迟:通过 traffic control 添加过滤器队列、分类、过滤器来实现的网络延时。也就是 tc 的netem delay。
ChaosBalde 是通过将 tc 来实现的模拟丢包和延时。杀死进程:kill命令
支持系统问题的异常注入:
基础组件:server重启、下游服务宕机、网络延迟&丢包、内存&CPU高负载、中间件Redis、DB、MQ等调用异常
业务:CPU打满、内存异常、磁盘读写故障、数据库、缓存、下游服务的网络延时和丢包、DNS篡改。
服务层面仅支持 A 到B这种故障,B自身这块平台上没支持
优点:
使用chaosblade方案,容器级别 的故障
缺点:
1、手工方式操作,比较繁琐,效率低、难以复用
2、每次执行要手动重新配置
3、容器爆炸半径难以控制
4、不能在线上环境操作
混沌故障平台
uat环境:https://uat-main-infra.bilibili.co/#/applicationHighAvailability/appList
pre/prod 环境:https://main-infra.bilibili.co/#/applicationHighAvailability/appList
故障演练平台-Quick Start
集成SDK的模式:
调用(redis、mc、grpc、http)组件前,会先调用故障演练的sdk,根据平台配置按需注入错误,拦截到真实组件的调用;
指定集群、节点、接口和用户,在请求粒度上注入错误,实现故障的精确控制。
比如请求redis: 请求-> 故障演练sdk(这里拦截,redis请求报错、超时等) -> redis sdk -> 真实redis
优点:
1、简便选择接口、缓存端口号等;
2、支持实际强弱依赖自动收集
3、可控制爆炸半径范围
4、实时日志等
缺点:
1、使用前,代码需接入sdk(一行代码),对实际性能无影响
2、不支持cpu、内存异常故障
4、故障表现梳理
- 强弱依赖确认:强弱依赖关系是否合理,弱依赖是否走降级策略
- 故障后预期:预期是什么(兜底、重试策略、崩溃等),是否可控
- 指标的确认:故障注入、恢复时间
详情:混沌测试梳理思路
EG : 直播送礼场景梳理:https://info.bilibili.co/pages/viewpage.action?pageId=298977715
以送礼功能为参考:
【混沌测试一期】…/…/混沌工程/【已评审–全量】–混沌测试送礼功能.xmind
【混沌测试二期】s12送礼混沌测试
三、问题详情举例
1、送礼 下游依赖的 用户 服务,对于礼物面板展示属于弱依赖,故障不可用后
预期礼物面板应该展示正常,送礼失败,其他功能不受影响;
实际上游依赖方超时,礼物面板不展示,影响送礼核心功能;
因为针对强依赖我们也需要关注:
2、下游数据能正常返回,即使是错误数据也对主流程(长链路)不影响
3、下游不能将耗时耗尽,影响主流程执行
4、送礼服务缓存超时,查缓存不回源时,礼物面板不展示;预期送礼异常,面板正常返回。【技术预期优化】
5、全屏动画资源配置服务下游 的 飘屏资源服务 注入故障不可用(丢包率100%),Android 配置全屏动画的道具可以正常展示,送礼正常;
预期配置全屏动画的道具不可展示,不能赠送,iOS符合预期。【产品预期优化】
四、Q&A
Q A 备注
五、后续优化
1、根据业务形态,新增不同场景,不同业务的混沌测试。
2、可以从UAT环境逐步走向预发、生产环境。
3、全自动、全随机的混沌测试。通过不定期、不定时的进行随机故障注入。
4、端上能够全时段,全平台,对主干体验进行监控,在故障时,有兜底策略。