目录
- 前置知识
- 课程内容
- 一、Zookeeper分布式锁实战
- 1.1 什么是分布式锁
- 1.2 基于数据库设计思路
- 1.3 基于Zookeeper设计思路一
- 1.4 基于Zookeeper设计思路二
- 1.5 Curator 可重入分布式锁工作流程
- 1.6 总结
- 二、基于Zookeeper实现服务的注册与发现
- 2.1 设计思路
- 2.2 Zookeeper实现注册中心的优缺点
- 学习总结
前置知识
单体、分布式、微服务小口诀:
厨房里一开始只有一个厨师,这个厨师既要自己洗菜,切菜,还要自己炒菜,这叫做单体;
老板又请了一个厨师,这个厨师同样既要自己洗菜,切菜,还要自己炒菜,两个厨师之间的关系叫做分布式(职责一样,重在对硬件资源的横向拓展应用);
老板又分别请了一个洗菜的阿姨和切菜的师傅,以后厨师只需要专注于炒菜了。洗菜阿姨,切菜师傅,炒菜厨师之间的关系就是微服务(职责不同,专注于各自的服务)
课程内容
一、Zookeeper分布式锁实战
1.1 什么是分布式锁
说到分布式锁,这里其实有2个概念,即【分布式 + 锁】。分布式这个概念我们可以看看【前置知识】;至于锁嘛,第一概念当然是JUC中的锁了。如:Sychronized和ReentractLock。但是,这些作为JVM级别的锁,只能应用在同一个进程中,不同线程的竞争中,没办法满足分布式(多进程)的使用场景、于是,就需要一种更加高级的锁机制来处理多进程之间的数据同步问题,这种机制就是:分布式锁。
目前分布式锁,比较成熟、主流的方案:
- 基于数据库的分布式锁。这种方案使用数据库的事务和锁机制来实现分布式锁。虽然在某些场景下可以实现简单的分布式锁,但由于数据库操作的性能相对较低,并且可能面临锁表的风险,所以一般不是首选方案
- 基于Redis的分布式锁。Redis分布式锁是一种常见且成熟的方案,适用于高并发、性能要求高且可靠性问题可以通过其他方案弥补的场景。Redis提供了高效的内存存储和原子操作,可以快速获取和释放锁。它在大规模的分布式系统中得到广泛应用(大部分人都在用)
- 基于ZooKeeper的分布式锁。这种方案适用于对高可靠性和一致性要求较高,而并发量不是太高的场景。由于ZooKeeper的选举机制和强一致性保证,它可以处理更复杂的分布式锁场景,但相对于Redis而言,性能可能较低。
对Redis分布式锁比较熟悉的同学估计会想:Redis不是最优方案了吗,还搞什么劳什子的ZK分布式锁啊?只能说各有各的优点。Redis分布式锁在高可用上确实不错,但是因为没满足强一致性,所以,如果出现宕机,确实是有可能会出现最长30秒无法解锁的问题。但是在ZK中就不会出现,这是因为ZK的强一致性和监听机制带来的好处。
1.2 基于数据库设计思路
可以利用数据库的唯一索引来实现,唯一索引天然具有排他性
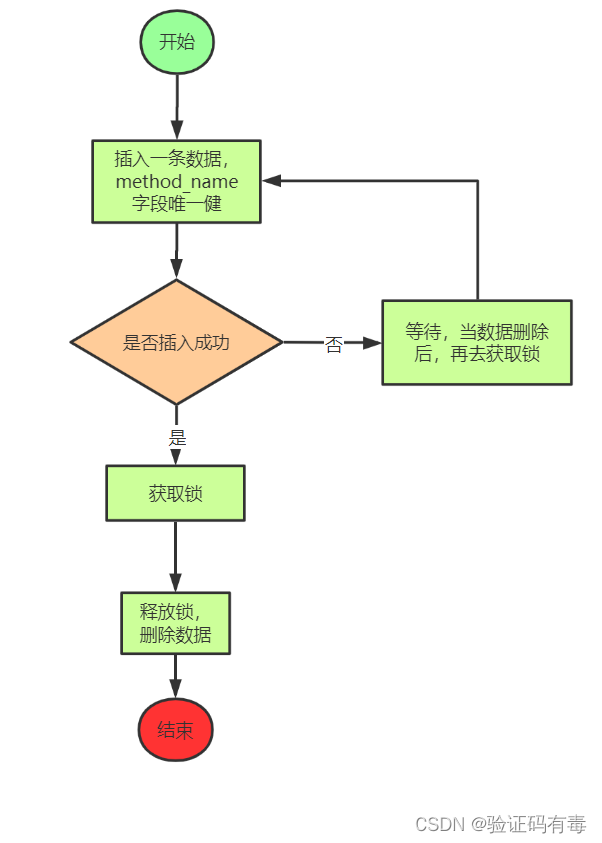
但还是那句话,有Redis分布式锁了,没必要使用这个数据库的分布式锁(我在上古C语言项目使用过,甚至还用过Linux文件系统来做分布式锁的)。
1.3 基于Zookeeper设计思路一
使用临时 znode 来表示获取锁的请求,创建 znode成功的用户拿到锁。
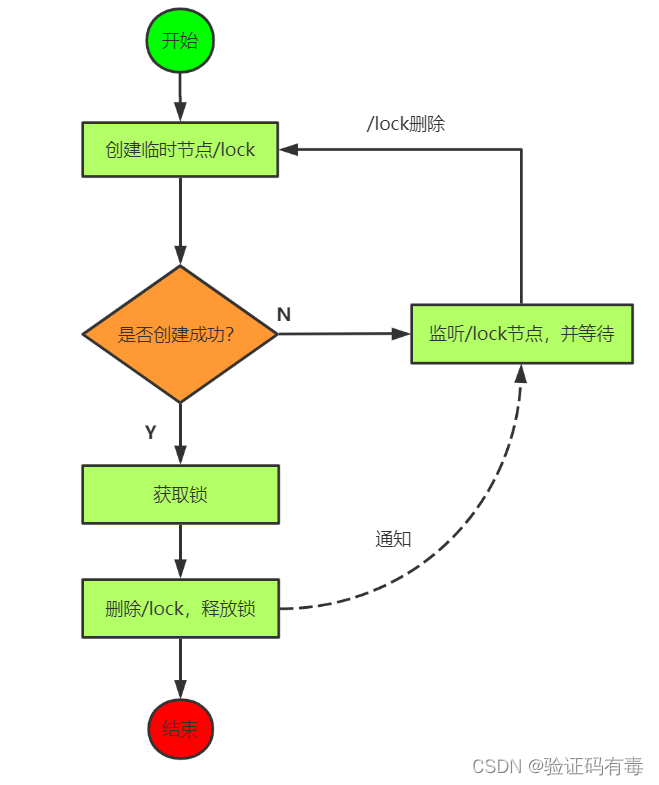
上述这种方案虽然能实现,但其实会有一个问题。那就是:
- 如果同时有100个用户请求锁,最终只有1个会成功,99个失败,阻塞等待锁
- 锁释放后,会通知唤醒剩余99个等待线程,重新获取锁,然后又只有1个能获取成功,98个失败
- 以此类推,知道全部都获取成功
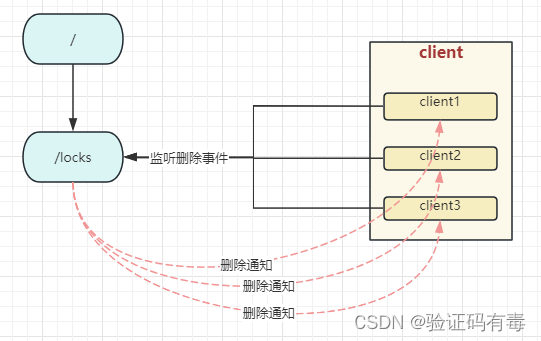
这就是问题所在,每次都有大量的线程重新竞争。JUC是怎么解决这个所问题的呢?JUC新增了一个等待队列来解决。每次只让队列中的头结点去竞争。详情请看我这篇文章《【并发专题】深入理解AQS独占锁之ReentrantLock源码分析》
所以,这里是否也可以参考JUC的解决办法呢?可以的,但是略有不同
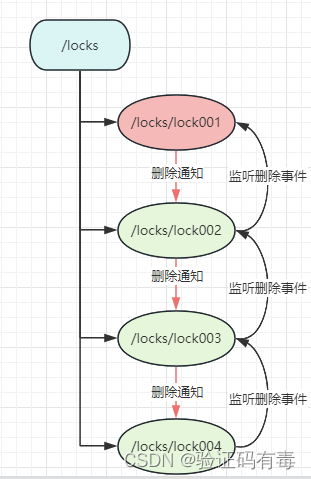
1.4 基于Zookeeper设计思路二
使用临时有序znode来表示获取锁的请求,创建后,znode序号最小的用户成功拿到锁。下面是一种公平锁的实现的实现原理图:
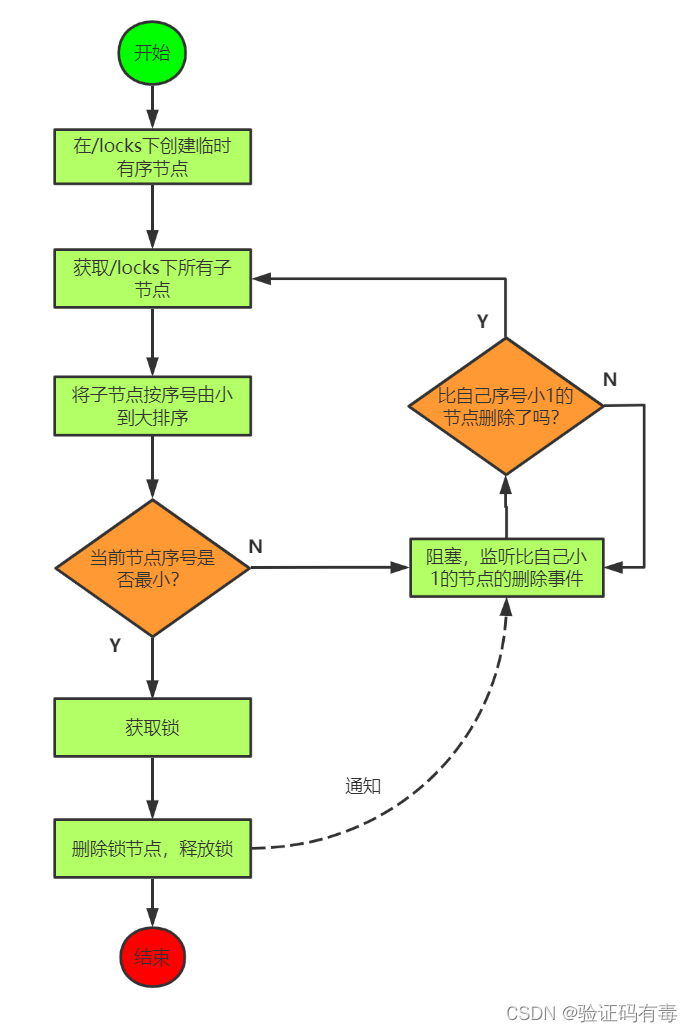
我们可以看看上面的流程图,它通过,每次让节点监听比自己小1的节点的删除事件,来让自己实现排队等待唤醒的机制。
不过,上述的流程已经不需要我们我们自己去写了,之前介绍过的Curator客户端,已经提供了相应的API了。
1.5 Curator 可重入分布式锁工作流程
它的大概流程如下:
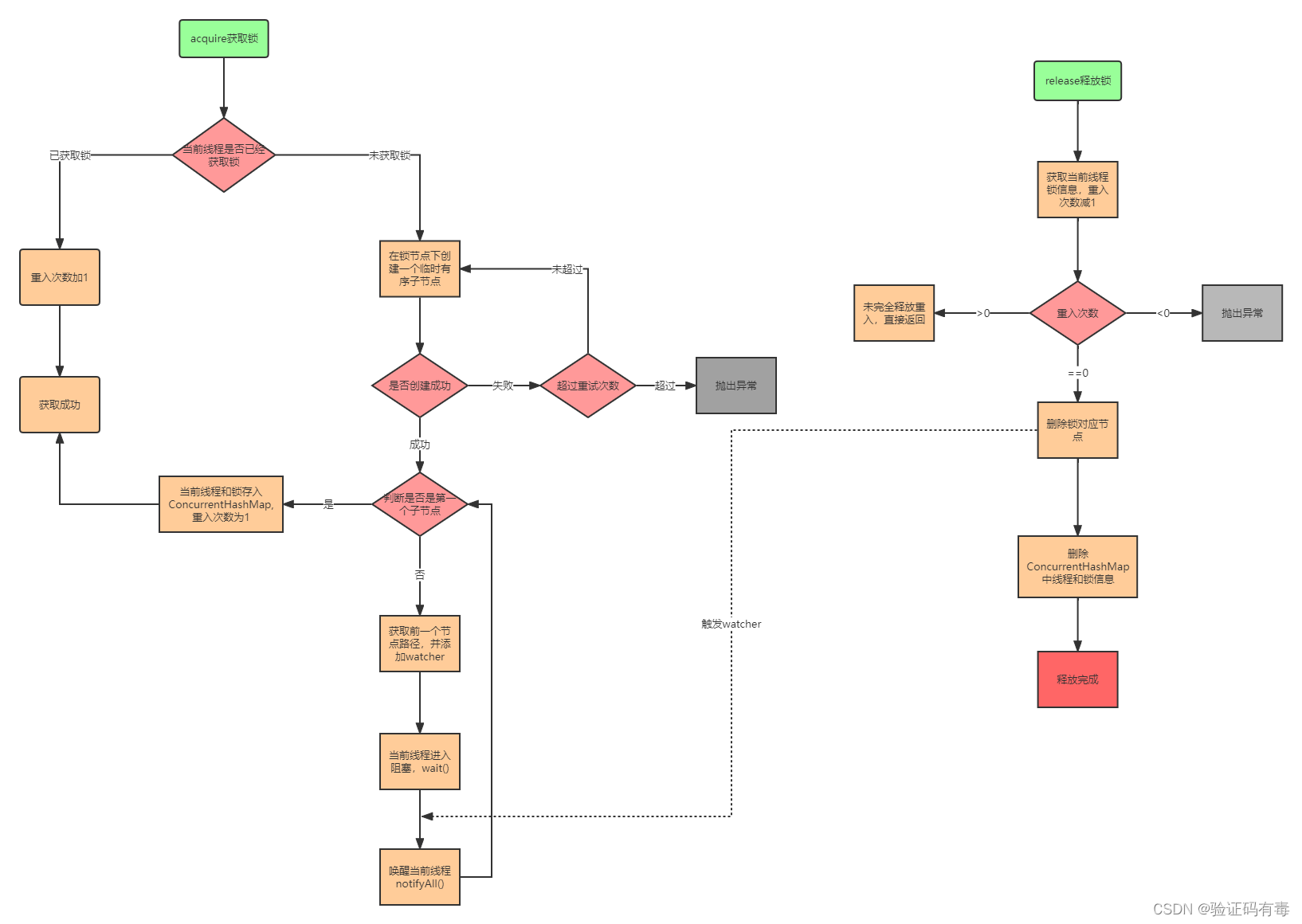
简单的代码使用案例如下:
public class CuratorLockTest implements Runnable {
final static CuratorFramework client = CuratorFrameworkFactory.builder().connectString("localhost:2181")
.retryPolicy(new ExponentialBackoffRetry(100, 1)).build();
private OrderCodeGenerator orderCodeGenerator = new OrderCodeGenerator();
// 可重入互斥锁
final InterProcessMutex lock = new InterProcessMutex(client, "/curator_lock");
public static void main(String[] args) throws InterruptedException {
client.start();
for (int i = 0; i < 30; i++) {
new Thread(new CuratorLockTest()).start();
}
Thread.currentThread().join();
}
@Override
public void run() {
// 加锁
lock.acquire();
try {
String orderCode = orderCodeGenerator.getOrderCode();
System.out.println("生成订单号 " + orderCode);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
// 释放锁
lock.release();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
/**
* 订单号生成工具类
* 由于++count非原子的,所以是线程不安全的
* 没有锁的话,肯定会出现订单号重复的现象
*/
public class OrderCodeGenerator {
private static int count = 0;
public String getOrderCode(){
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyyMMddhhmmss");
return simpleDateFormat.format(new Date()) + "-" + ++count;
}
}
1.6 总结
优点:ZooKeeper分布式锁(如InterProcessMutex),具备高可用、可重入、阻塞锁特性,可解决失效死锁问题,使用起来也较为简单
缺点:因为需要频繁的创建和删除节点,性能上不如Redis
在高性能、高并发的应用场景下,不建议使用ZooKeeper的分布式锁。而由于ZooKeeper的高可靠性,因此在并发量不是太高的应用场景中,还是推荐使用ZooKeeper的分布式锁。
二、基于Zookeeper实现服务的注册与发现
基于ZooKeeper本身的线性写、监听等特性可以实现服务注册中心。
2.1 设计思路
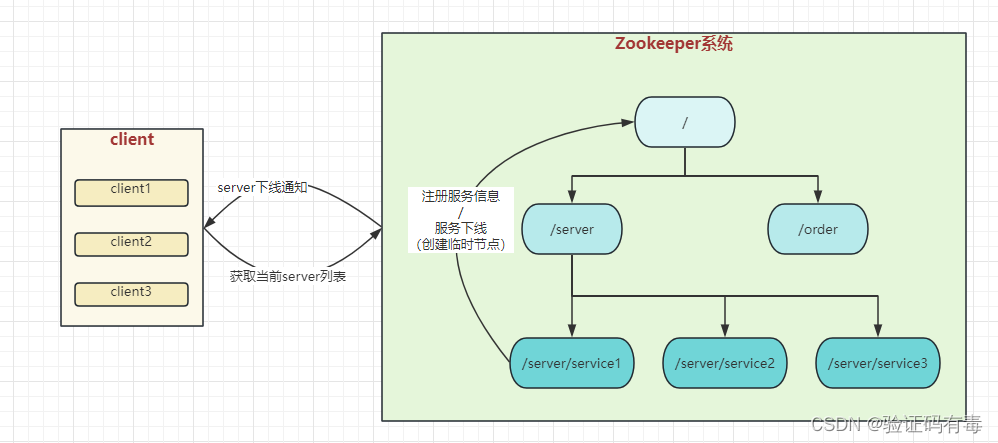
Q1:什么是服务注册与发现?
在分布式架构中,由于微服务实例数量较多,其 IP 地址和端口号会经常变化,因此需要一个机制来自动维护微服务的实例信息,实现微服务之间的通讯。服务注册发现机制就是解决这个问题的机制。
服务提供者会将自己的实例信息注册到服务注册中心,服务消费者通过服务注册中心获取服务提供者的实例信息进行通讯。服务消费者和服务提供者之间的通讯不需要知道对方的实际 IP 地址和端口号,只需要通过服务名即可。
2.2 Zookeeper实现注册中心的优缺点
优点:(其实就是ZK本身的优点)
- 高可用性:ZooKeeper是一个高可用的分布式系统,可以通过配置多个服务器实例来提供容错能力。如果其中一个实例出现故障,其他实例仍然可以继续提供服务
- 强一致性:ZooKeeper保证了数据的强一致性。当一个更新操作完成时,所有的服务器都将具有相同的数据视图。这使得ZooKeeper非常适合作为服务注册中心,因为可以确保所有客户端看到的服务状态是一致的
- 实时性:ZooKeeper的监视器(Watcher)机制允许客户端监听节点的变化。当服务提供者的状态发生变化时(例如,上线或下线),客户端会实时收到通知。这使得服务消费者能够快速响应服务的变化,从而实现动态服务发现
缺点:
- 性能限制:ZooKeeper的性能可能不如一些专为服务注册中心设计的解决方案,如Nacos或Consul。尤其是在大量的读写操作或大规模集群的情况下,ZooKeeper可能会遇到性能瓶颈
学习总结
- 学习了ZK的分布式锁实现流程,并通过次加深了对ZK强一致性的理解