数据库查询操作
前置:首先我们创建一个练习的数据库
/*
SQLyog Professional v12.09 (64 bit)
MySQL - 5.6.40-log : Database - studentsys
*********************************************************************
*/
/*!40101 SET NAMES utf8 */;
/*!40101 SET SQL_MODE=''*/;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/`studentsys` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `studentsys`;
/*Table structure for table `course` */
DROP TABLE IF EXISTS `course`;
CREATE TABLE `course` (
`cno` varchar(10) NOT NULL,
`cname` varchar(20) NOT NULL,
`credit` int(2) DEFAULT NULL,
PRIMARY KEY (`cno`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `course` */
insert into `course`(`cno`,`cname`,`credit`) values ('C01','网页基础',1),('C02','数据库系统',2),('C03','计算机基础',3);
/*Table structure for table `dept` */
DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (
`did` int(11) NOT NULL AUTO_INCREMENT,
`dname` varchar(20) NOT NULL,
PRIMARY KEY (`did`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
/*Data for the table `dept` */
insert into `dept`(`did`,`dname`) values (1,'计算机系'),(2,'土木工程系'),(3,'英语系');
/*Table structure for table `sc` */
DROP TABLE IF EXISTS `sc`;
CREATE TABLE `sc` (
`sno` varchar(10) DEFAULT NULL,
`cno` varchar(10) DEFAULT NULL,
`degree` int(3) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `sc` */
insert into `sc`(`sno`,`cno`,`degree`) values ('S01','C01',80),('S01','C02',85),('S01','C03',90),('S02','C01',63),('S02','C02',58),('S03','C01',55),('S03','C03',65),('S04','C01',58);
/*Table structure for table `student` */
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`sno` varchar(10) NOT NULL,
`sname` varchar(20) NOT NULL,
`sex` char(4) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`brithday` datetime DEFAULT NULL,
`address` varchar(200) DEFAULT NULL,
`did` int(11) DEFAULT NULL,
PRIMARY KEY (`sno`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `student` */
insert into `student`(`sno`,`sname`,`sex`,`age`,`brithday`,`address`,`did`) values ('S01','陈宇乐','男',21,'2022-02-02 00:00:00','浙江义乌',1),('S02','陈紫樱','女',20,'2022-02-10 00:00:00','',1),('S03','杜陈宇','男',21,NULL,NULL,1),('S04','陈宇乐','男',23,NULL,NULL,2),('S05','陈樱','女',21,NULL,NULL,2),('S06','杜佳佳','男',19,NULL,NULL,NULL);
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;
1 查询基础
1.1 select 操作

参考sql
#查询所有学生信息
select * from student;
#查询学生表中的学号与姓名
select sno,sname from student;
#查询学生表中的学号与姓名,并且给一个字段别名
select sno as snum,sname as `姓名` from student;
#查询学生表中的姓名信息,并过滤掉相同姓名信息
select distinct sname from student;
#查询学生个数,年龄总和,平均年龄,最大年龄,最小年龄,并给他们一个别名
select count(*) as `学生个数` ,sum(age) as `年龄总和` from student;
select avg(age) as `平均年龄` ,max(age) as `最大年龄`,min(age) as `最小年龄` from student;
1.2 where

参考SQL
#查询所有男生的信息
select * from student where `sex`="男";
#查询所有21岁男生的信息
select * from student where `sex`="男"
and age = 21;
1.3 模糊查询
参考SQL
#查询姓‘陈’的同学
select * from student where sname like '陈%';
#查询名字中出现‘陈’的同学
select * from student where sname like '%陈%';
#查询姓陈的二个字姓名的同学
select * from student where sname like '陈_';
#查询名字结尾是‘樱’的三个字姓名的同学
select * from student where sname like '__樱';
1.4 排序

参考SQL
#根据学生年龄从大到小进行排序学生信息
select * from student order by age desc;
#根据学生年龄从小到大进行排序'男'同学信息
select * from student where sex='男'
order by age;
#第一排序根据学生年龄升序进行排序,第二排序根据‘学号’降序排序的同学信息
select * from student order by age asc , sno desc;
1.5 分组与having子句

参考SQL
#分组一般和聚合函数一起使用
#根据性别进行分组,并分别统计各组的人数
select sex,count(*) as `人数` from student group by sex;
#根据性别进行分组,并分别统计各组的同学的平均年龄
select sex,avg(age) as `平均年龄` from student group by sex;
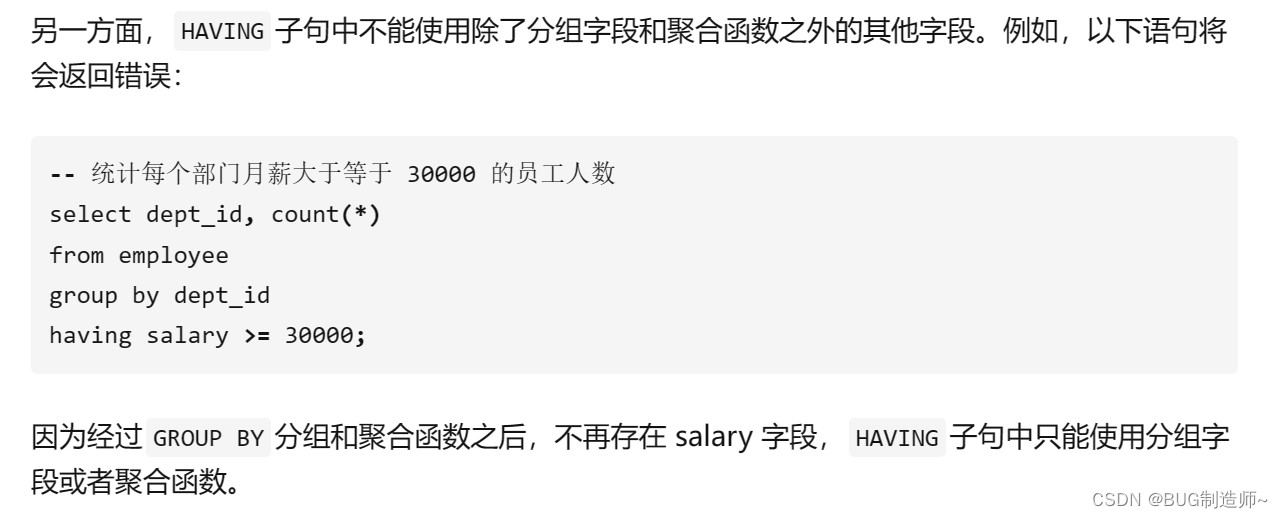
#HAVING子句 一般是配合GROUP BY使用
#根据性别进行分组,并统计各组的人数大于3人的分组信息
select sex,count(*) as `性别组` from student group by sex having `性别组` > 3
having 和 where 的区别
WHERE与HAVING的根本区别在于:
WHERE子句在GROUP BY分组和聚合函数之前对数据行进行过滤;
HAVING子句对GROUP BY分组和聚合函数之后的数据行进行过滤。


1.6 限制显示条数-limit
参考SQL
#显示学生表信息的前3条
select * from student limit 3;
#显示学生表信息的2-4条
select * from student limit 1,3;
#显示年龄第2大和第3大的"男"学生
select * from student where sex='男' order by age desc limit 1,2;
2 比较逻辑运算

参考SQL
#查询年龄大于20岁小于23岁的男生
select * from student where age > 20 and age < 23 and sex='男';
#区间的另一种写法 BETWEEN 大于等于20岁小于等于23岁
select * from student where sex='男' and age between 20 and 23;
#查询性别是男,或者年龄大于等于21岁的学生
select * from student where sex='男' or age >= 21;
#查询地址为''的学生信息
select * from student where address = '';
#查询地址为null的学生信息,和is搭配
select * from student where address is null;
#查询年龄不是21岁的学生
select * from student where age != 21;
select * from student where age <> 21;
#查询地址不为null的学生信息
select * from student where address is not null;
3 多表连接

3.1 内连接
参考SQL
#显示拥有系别学生学号,姓名,及所在系名称-[内连接方式]
select s.sno,s.sname,d.dname from student s inner join dept d on s.did = d.did;
#不推荐写法
select s.sno,s.sname,d.dname from student s ,dept d where s.did = d.did;
3.2 左连接
参考代码
#显示所有学生信息,及所在系情况-[左连接/左外连接]
#左连接已左边的表为主
select s.sno,s.sname,d.dname from student s left join dept d on s.did = d.did;
3.3 右连接
参考代码
#右连接/右外连接
select s.*,d.dname from student s right join dept d on s.did = d.did
3.4 全连接
MYSQL不支持FULL JOIN
select s.*,d.dname from student s left join dept d on s.did = d.did
union
select s.*,d.dname from student s right join dept d on s.did = d.did;
3.5 综合案例
#查询已选课学生姓名,课程名称,课程成绩
select st.sname,c.cname,sc.degree from sc
left join student st on sc.sno = st.sno
inner join course c on sc.cno = c.cno;
#查询至少选修一门课的女同学姓名,除去重复姓名项
select st.sname,sc.degree from sc
join student st on sc.sno = st.sno where st.sex = '女';
4 子查询
4.1 =
SQL代码
#查询和'陈樱'同龄的学生信息
select * from student where age = (
select age from student where sname = '陈樱'
);
4.2 in/not in
SQL代码
#查询课程成绩不及格的选修课课程信息
select * from course where cno in (
select distinct cno from sc where degree < 60
);
#查询课程成绩及格的选修课课程信息
select * from course where cno not in (
select distinct cno from sc where degree < 60
);
#in或者not in一般来说查询效率低,采用多表连接
select distinct c.cname from sc join course c on sc.cno = c.cno
where sc.degree < 60;
4.3 all
满足所有条件
SQL代码
#ALL表示必须满足子查询结果的所有记录
#查询sc表里成绩最高的记录
select * from sc where degree >= ALL (select degree from sc);
#查询sc表里成绩最低的记录
select * from sc where degree <= ALL (select degree from sc);
4.4 any
满足其中的一个条件
SQL代码
#any表示满足子查询结果的任意一条记录即可,和some一样
#查询选择’C01‘课程的成绩高于’C02‘的成绩的学生的学号
select * from sc where cno = 'C01' and degree > any(
select degree from sc where cno = 'C02'
);
select * from sc where cno = 'C01' and degree > some(
select degree from sc where cno = 'C02'
);
4.5 exist/not exists
SQL代码
#EXISTS子查询返回结果类型bool
#EXISTS运算符的含义为"存在",
#使用 EXISTS 关键字引入一个子查询时,就相当于进行一次存在测试。
#外部查询的 WHERE 子句测试子查询返回的行是否存在。
#子查询实际上不产生任何数据;它只返回 TRUE 或 FALSE 值
#显示已经选修了课程的学生信息
select distinct s.* from student s
inner join sc
on sc.sno = s.sno;
select * from student s where exists (select * from sc where s.sno = sc.sno);
#查询选修了C03课程的学生信息
select * from student s where exists (select * from sc where s.sno = sc.sno and sc.cno = 'C03');