基于BERT模型进行文本处理(Python)
所有程序都由Python使用Spyder运行。
对于BERT,在运行之前,它需要安装一些环境。
首先,打开Spyder。其次,在控制台中单独放置要安装的:
pip install transformers
pip install torch
pip install torch torchvision
conda install pytorch torchvision torchaudio -c pytorch
第三,重新启动内核(这意味着关闭Spyder并重新打开它)。
最后,直接打开python文件(后面有完整代码和运行之后的结果),点击运行,就可以产生结果。
所有数据都存储在名为data的BERT文件夹中。处理时,它将自动加载数据文件夹。然后它将创建traintest.csv和validation_test.csv。之后,它将分析test文件包,以自动生成test.csv和test-analysis.csv
Bert并不是专门用来确定一份文件是由单个作者还是由多个作者撰写的。这是因为,要确定一份文档是单作者还是多作者,需要了解文档的结构和内容,并分析整个文本中使用的写作风格。
检测文本中的变化可以使用BERT(一种预先训练的语言模型)和逻辑回归分类器来实现。这个过程的第一步是使用BERT对两段文本进行编码。BERT将文本编码为一系列向量,其中每个向量表示文本中的不同单词或子单词。然后,可以使用这些编码向量来训练分类器,以预测两段文本是相似还是不同。
为了训练分类器,有必要为其提供一组标记的训练数据。这意味着我们需要有一组文本对,其中每一对都被标记为相似或不同。这些信息可以从JSON文件中获得,但在这种情况下,我们使用前面在数据中提到的CSV文件中第二列的更改。我们使用这些文本对来训练分类器来识别相似文本和不同文本之间的差异。
一旦分类器经过训练,它就可以用来预测新的文本对的相似性。要做到这一点,首先使用BERT对两段文本进行编码,然后将编码后的表示输入到逻辑回归分类器中。然后,分类器将输出一个介于0和1之间的值,该值表示两段文本相似的概率。为了避免输出只有一个类的情况,使用1乘以段落数作为预测结果来处理每个段落样式不同的特殊情况。
检测作者涉及与标记化不同的方法。用于此任务的方法称为BertForSequenceClassification,它将每个段落分解为一系列标记。参数model_name和num_labels在该方法中至关重要。Model_name用于加载适用于特定任务的预训练BERT模型,而num_labels则指定分类任务中的类数。在这个项目中,num_labels等于文档中的段落数。然后,使用BERT模型将标记嵌入到高维空间中,该模型为每个段落创建一个矢量表示,以捕捉其语义。
然后,通过将嵌入向量序列作为输入,使用监督学习算法来预测通信作者。该模型是在标记的数据集上使用损失函数进行训练的,该函数测量预测作者和真实作者之间的差异。训练后,使用单独的数据集对模型进行验证,以评估其准确性,并进行任何必要的调整以提高其性能。
一旦该模型经过训练和验证,就可以用来预测新文本中单个段落的作者身份。但是,段落作者的最大数量应与段落数量相同。根据文献综述,发现多个作者主要在2到5个之间,因此该项目将段落作者的数量限制在段落总数的1到一半之间。
from sklearn.metrics import f1_score, accuracy_score
from transformers import BertTokenizer, BertForSequenceClassification
import numpy as np
from sklearn.linear_model import LogisticRegression
import transformers
from transformers import BertTokenizer, BertForSequenceClassification
import torch
from collections import defaultdict
#from hmmlearn import hmm
import math
import operator
import numpy as np
import nltk
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
import string
import os
import math
from scipy.stats import chi2_contingency
import pandas as pd
import glob
import ast
import json
import csv
import pandas as pd
import re
from sklearn.feature_extraction.text import CountVectorizer
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
# create a csv that store the related information from tain or validation(depends on the main part)
def createCsv(rout,csv_name):
test=[]
header = ['id', 'multi-author', 'changes','para_author','paragraph']
rout_txt=glob.glob(rout+'/*.txt')
rout_json=glob.glob(rout+'/*.json')
for n in range(len(rout_txt)):
for m in range(len(rout_json)):
if(rout_txt[n].split('.')[0].split('-')[-1]==rout_json[m].split('.')[0].split('-')[-1]):
with open(rout_txt[n],'r', encoding='utf-8') as f1:
print(rout_txt[n])
paragraph=f1.readlines()
with open(rout_json[m], 'r', encoding='utf-8') as f2:
content = json.load(f2)
uniqId=rout_json[m].split('.')[0].split('-')[-1]
multiauthor=content['multi-author']
changes=content['changes']
para_author=content['paragraph-authors']
csvcontent=(uniqId,multiauthor,changes,para_author,paragraph)
test.append(csvcontent)
with open(csv_name, 'w', encoding='utf-8',newline='') as file_obj1:
writer = csv.writer(file_obj1)
writer.writerow(header)
writer.writerows(test)
def preprocessing(s):
words = s.translate(str.maketrans('','',string.punctuation))
#remove the content punctuation
ps = PorterStemmer()
word = word_tokenize(ps.stem(words))
return word
# stremming all the words
def preanalysis(text):
# Tokenize text into words
tokens = nltk.word_tokenize(text)
stop_words = set(stopwords.words('english'))
# Remove stop words from tokenized text
filtered_tokens = [word for word in tokens if word.lower() not in stop_words]
stemmer = PorterStemmer()
stemmed_tokens = [stemmer.stem(word) for word in filtered_tokens]
return stemmed_tokens
# using google bert
tokenizerchange = transformers.BertTokenizer.from_pretrained('bert-base-uncased')
modelchange = transformers.BertModel.from_pretrained('bert-base-uncased')
# change the format of changes so that it could matched to train
def forchanges(changes):
cleaned_list = [s.strip("[],' ") for s in changes if s not in [",", " "]]
cleaned_list.pop(0)
del cleaned_list[-1]
cleaned_list.insert(0,1)
return cleaned_list
def forchanges1(changes):
cleaned_list = [s.strip("[],' ") for s in changes if s not in [",", " "]]
return cleaned_list
# Define a function to predict the author of new paragraphs
def predict_author(texts, tokenizer, model):
predicted_authors = []
for text in texts:
# Tokenize the input text and convert the labels to PyTorch tensors
tokenized_text = tokenizer(text, padding=True, truncation=True, return_tensors='pt')
# Forward pass
outputs = model(**tokenized_text)
# Get the predicted author
predicted_author = torch.argmax(outputs.logits).item()
predicted_authors.append(predicted_author)
return predicted_authors
def extract_features(paragraphs):
encoded_inputs = tokenizerchange(paragraphs, padding=True, truncation=True, return_tensors='pt')
with torch.no_grad():
outputs = modelchange(**encoded_inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings.numpy()
if __name__ == "__main__":
rout1 = "data/train"
csv_name1 = "train_test.csv"
createCsv(rout1, csv_name1)
counter=0
vectorizer1 = CountVectorizer()
#create a new csv file to store real results and predicted results
with open('test.csv', mode='w', newline='') as result:
writer = csv.writer(result)
#create a new csv file to store all f1 and accuracy
with open('test_analysis.csv', mode='w', newline='') as result1:
f1_writer = csv.writer(result1)
writer.writerow(['id', 'real-multiauthor','pre-multiauthor','real-changes','pre-changes','real-para_author'])
f1_writer.writerow(['id', 'multi-accuracy','changes-f1score','changes-accuracy','para-f1score','para-accuracy'])
with open ('validation_test.csv',"r", encoding='utf-8')as csvFile:
rows=csv.reader(csvFile)
for row in rows:
if(counter>0):
sentsplit=row[-1].split('\\n')
if len(sentsplit) <= 10:
sentsplit1= sentsplit
else:
sentsplit1 = sentsplit.pop()
# load the content inside csv
authors = row[3]
changes = row[2]
authors1 = ast.literal_eval(authors)
multiple = row[1]
filename = row[0]
if int(filename) not in [71,301,340,642,700,1752, 1823, 2019, 2021, 2022, 2096] and int(filename) <= 1000:
#print("filename")
#print(filename)
print("filename")
print(filename)
features = extract_features(sentsplit1)
cleaned_list = forchanges(changes)
#print("correct changes")
#print((cleaned_list))
# Train a logistic regression model to predict the author of a document based on its BERT embeddings
try:
clf1 = LogisticRegression()
clf1.fit(features, cleaned_list)
test_embedding1 = extract_features(sentsplit1)
predicted_changes1 = clf1.predict(test_embedding1)
sumchange= sum(int(x) for x in predicted_changes1)
#criteria = predicted_changes1.count('1')
print('Number of segments with style changes:', sumchange)
if sumchange == 1:
multiauthor = 0
else:
multiauthor = 1
#print("predict multiauthor")
#print(multiauthor)
#print("authors")
#print(multiple)
if int(multiauthor) == int(multiple):
multiauthorf1 = 1
print(f"F1 score of multiauthor: {multiauthorf1:.2f}")
else:
multiauthorf1 = 0
print(f"F1 score of multiauthor: {multiauthorf1:.2f}")
changesf1 = f1_score(cleaned_list, predicted_changes1,pos_label='1')
changesac = accuracy_score(cleaned_list, predicted_changes1)
#print(f"F1 score of change: {changesf1:.2f}")
except Exception as e:
print(f"Error occurred: {e}")
#changesf1 = (1/len(sentsplit1))
#print(f"F1 score of change: {changesf1:.2f}")
multiauthor = 1
#print("multiauthor")
#print(multiauthor)
#print("authors")
#print(multiple)
if int(multiauthor) == int(multiple):
multiauthorf1 = 1
print(f"F1 score of multiauthor: {multiauthorf1:.2f}")
else:
multiauthorf1 = 0
print(f"F1 score of multiauthor: {multiauthorf1:.2f}")
changesf1 = 0
changesac = (1/len(sentsplit1))
num_authors = (len(sentsplit1))
# load pre-trained BERT model and tokenizer
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=num_authors)
# map paragraph indices to author indices
author_mapping = authors1
if len(author_mapping) < len(sentsplit1):
author_mapping += [author_mapping[-1]] * (len(sentsplit1) - len(author_mapping))
new_paragraphs = sentsplit1
# tokenize input paragraphs
input_paragraphs = []
for paragraph in new_paragraphs:
inputs = tokenizer.encode_plus(paragraph, add_special_tokens=True, return_tensors='pt')
input_paragraphs.append(inputs)
# predict authors of new paragraphs
predicted_authors = []
for i in range(1, len(input_paragraphs)):
# concatenate previous paragraph with current paragraph
inputs = input_paragraphs[i].copy()
inputs['input_ids'] = torch.cat([inputs['input_ids'], input_paragraphs[i]['input_ids']], dim=1)
inputs['token_type_ids'] = torch.cat([inputs['token_type_ids'], input_paragraphs[i]['token_type_ids']], dim=1)
inputs['attention_mask'] = torch.cat([inputs['attention_mask'], input_paragraphs[i]['attention_mask']], dim=1)
# predict author using BERT
outputs = model(**inputs)
probabilities = torch.softmax(outputs.logits, dim=1)[0].tolist()
# choose author based on maximum probability
predicted_author = author_mapping[i] # default to known author
max_prob = probabilities[author_mapping[i]-1] # probability of known author
for j in range(1,int((len(authors1))/2)):
if j != author_mapping[i] and probabilities[j] > max_prob:
predicted_author = j+1
max_prob = probabilities[j]
predicted_authors.append(predicted_author)
# add first author to predicted author list
predicted_authors.insert(0, 1)
print("Predicted authors:", predicted_authors)
print(authors1)
f1 = f1_score(authors1, predicted_authors, average='weighted')
print(f"F1 score: {f1:.2f}")
accuracy = accuracy_score(authors1, predicted_authors)
writer.writerow([filename,multiple,multiauthor,cleaned_list,predicted_changes1,authors1,predicted_authors ])
f1_writer.writerow([filename,multiauthorf1,changesf1,changesac,f1,accuracy ])
counter+=1
使用BERT和文本文件夹中的输入txt文件的结果存储在test.csv和test_analysis.csv中。文件test.csv由与三个任务相关的真实结果和预测结果组成。每个列的名称都提供了其内容的清晰指示,每个属性的内容可以在下面看到:
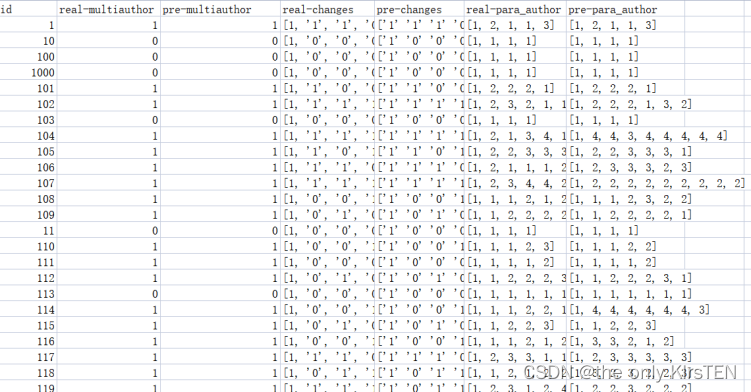
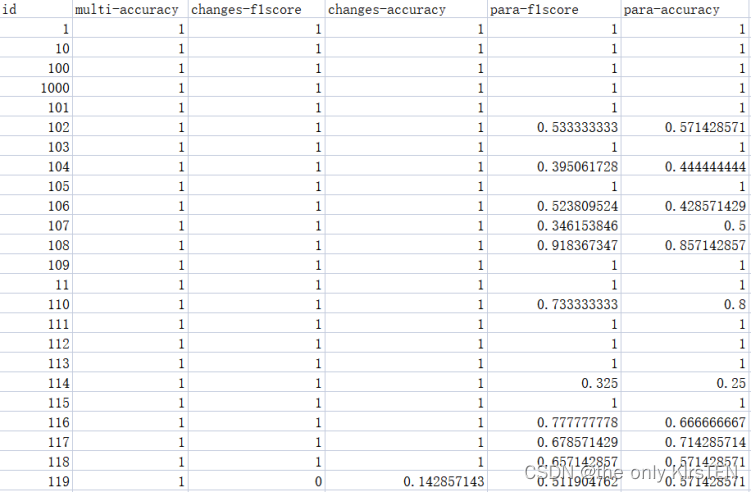
基于之前的分析,逻辑回归在三项任务中表现良好,执行时间最低。然而,仍然存在一些提高准确性的促销活动。当有四个以上的作者时,检测所有作者是很困难的,当只有一个段落是由另一个作者写的时,识别格式也是很有挑战性的。
解决这些问题的一种可能方法是探索更先进的特征提取技术,例如深度学习模型。此外,结合其他语言特征或元数据(如写作风格或文档结构)以提高检测的准确性可能是有益的。
此外,研究组合多个模型的输出以提高整体性能的集成方法可能是有用的。最后,结合用户反馈或手动验证可以帮助进一步细化检测结果并提高准确性。