目录
一、RedisJson介绍
1.1 RedisJson是什么
1.2 RedisJson特点
1.3 RedisJson使用场景
1.3.1 数据结构化存储
1.3.2 实时数据分析
1.3.3 事件存储和分析
1.3.4 文档存储和检索
二、当前使用中的问题
2.1 刚性数据库模式限制了敏捷性
2.2 基于磁盘的文档存储导致瓶颈
2.3 附加索引和全文搜索增加了复杂性
2.4 小规模数据量下的准实时搜索问题
三、RedisSearch介绍
3.1 什么是RedisSearch
3.2 RedisSearch功能特性
3.3 与mongodb和es对比
四、RedisSearch安装
4.1 启动镜像
4.2 检查测试
五、RedisJson/ RedisSearch命令使用
5.1 RedisJson操作命令
5.1.1 保存操作
5.1.2 读取操作
5.1.3 批量读取操作
5.1.4 删除操作
5.2 RedisSearch操作命令
5.2.1 创建索引
5.2.2 为索引添加内容
5.2.3 根据关键字查询
5.3 RedisSearch 扩展使用
5.3.1 前置准备
5.3.2 查询全部数据
5.3.3 查询并按照字段排序
5.3.4 返回指定字段
5.3.5 模糊查询
5.3.6 查询范围区间的数据
5.3.7 关键词检索
5.3.8 高亮显示
5.3.9 删除索引
六、Java操作RedisJson
6.1 引入基本依赖
6.2 相关操作API
七、SpringBoot操作RedisJson
7.1 添加配置文件
7.2 添加jedis配置类
7.3 测试类
八、写在文末
一、RedisJson介绍
1.1 RedisJson是什么
RedisJSON是一个Redis模块,它实现了JSON数据交换标准ECMA-404,作为原生数据类型。它允许从Redis中存储、更新和获取JSON值;
- RedisJSON 是一种高性能 JSON 文档存储,允许开发人员构建现代应用程序。它在内存中存储和处理 JSON,以亚毫秒级支持每秒数百万次操作响应时间;
- JSON 文档的原生索引、查询和全文搜索允许开发人员创建二级索引,快速查询数据;
1.2 RedisJson特点
redisJson具有如下特点:
- 完全支持JSON标准;
- 使用类似JSONPath的语法,用于在文档中选择元素;
- 文档以二进制数据的形式存储在树结构中,允许快速访问子元素;
- 所有JSON值类型都是原子操作
1.3 RedisJson使用场景
在下面的这些场景下可以考虑使用RedisJson
1.3.1 数据结构化存储
redisJson允许将复杂的JSON数据存储在redis中,并可以使用Redis的查询功能来快速检索和操作这些数据。
1.3.2 实时数据分析
通过将结构化数据存储在RedisJson中,可以轻松的对数据进行实时分析和计算。
1.3.3 事件存储和分析
RedisJson可以用作事件驱动的存储系统。用于存储和分析事件流数据。
1.3.4 文档存储和检索
RedisJson提供了一些内置的查询功能,可以轻松的在存储的JSON数据中执行文档检索。
二、当前使用中的问题
通过上面的内容我们了解了RedisJson的基本内容,并了解了使用RedisJson可以解决的问题和应用场景,Redis常用的数据结构已经很强大了,可以说已经能够满足大多数的业务场景了,为什么还要了解和学习RedisJson这个点呢?在弄清这个问题之前,先来看看现有的一些业务场景下存在的问题。
2.1 刚性数据库模式限制了敏捷性
传统的关系型数据库,一旦数据库表结构随着业务确定下来,中途想要针对某个表扩展新字段将是一件非常麻烦的事,甚至可能会对团队现有的工作节奏造成难以预估的冲击。简单来说就是,传统的数据库模式限制了业务机动调整的灵活性和自由性。
2.2 基于磁盘的文档存储导致瓶颈
文档类型的结构数据,允许开发人员使用灵活的 JSON 数据模型更快地迭代。 然而,由于磁盘 I/O性能瓶颈, 导致应用程序写入缓慢和读取延迟高。
2.3 附加索引和全文搜索增加了复杂性
我们知道在mysql5.7之后的版本,要实现全文检索功能,可以考虑使用全文索引,但使用过mysql全文索引的同学大多数会得出一个结论就是,不好用,用起来限制较多,不够灵活,但在mysql如果不用全文索引实现,使用其他方式将会增加更大的难度和复杂度。
2.4 小规模数据量下的准实时搜索问题
试想你的系统数据规模并不是很大,只是系统中的某些业务场景需要使用实时搜索,或者存在高性能检索的需求,在这种场景下,引入其他高性能数据存储成本会大大增加,同时这也将给开发和运维带来新的工作量。
综上论述,在下面的场景中可能需要使用RedisJson改进或优化你的使用:
- 数据规模较小的场景下需要完成实时检索,使用mysql无法满足高性能检索场景;
- 数据结构类json文档,且存在文档结构的扩展;
- 能够实现全文检索;
- 存储简单,运维成本低,系统接入成本低;
- ...
三、RedisSearch介绍
在上文中我们了解了为什么需要使用RedisJson,其实总结一句话就是,需要基于RedisJson使用其全文检索功能,同时还能方便的对存储其中的JSON文档或字段进行增删改查。
3.1 什么是RedisSearch
RediSearch 是一个高性能的全文搜索引擎,它可以作为一个 Redis Module(扩展模块)运行在 Redis 服务器上,在2.x之后的版本它不在使用基于RDB的基础数据结构,而是采用了一种全新的文件存储结构对数据进行索引,而且性能上也有了成倍的提升。
3.2 RedisSearch功能特性
RedisSearch主要特性如下:
- 多字段联合检索;
- 高性能增量索引;
- 复杂布尔查询;
- 基于管道的查询子句;
- 基于前缀的搜索;
- 支持字段权重设置;
- 自动完成建议(可用于搜索框联想词提示);
- 精确的短语搜索;
- 在许多语言中基于词干分析的查询扩展;
- 支持自定义评分函数(类似ES的function_score);
- 将搜索限制到特定的文档字段;
- 数字过滤器和范围;
- 使用 Redis 自己的地理命令进行地理过滤;
- 检索完整的文档内容或只是 ID 的检索;
- 支持文档删除和更新与索引垃圾收集;
- 支持部分更新和条件文档更新;
- 支持拼写纠错;
- 支持高亮显示;
- 支持聚合分析;
- 支持配置停用词和同义词;
- 支持向量存储与KNN检索(重磅);
- ...
3.3 与mongodb和es对比
结合已有的使用经验对比:
- RedisSearch 2.2 (支持RedisJson *) 比以前的版本更快;
- RedisJson * 在直接读取、写入和更新工作负载方面比Mongodb和es更快;
- 在混合工作负载场景中,实时更新不会影响RedisJson *的搜索和读取性能,而es则会受到影响;
尽管来说从测试的数据来看,在一定情况下RedisSearch的性能确实比es或mongo要高很多,但是两者的使用场景还是有区别的,这点需要额外关注。
四、RedisSearch安装
官方安装手册地址:Install Redis Stack | Redis ,官方提供了多种安装部署方式,这里选择使用Docker来搭建一个RedisSearch的环境。参考下面的安装流程。
4.1 启动镜像
使用下面的命令启动RedisSearch
docker run -p 6379:6379 -d --name=myredis redislabs/redisearch:latest
4.2 检查测试
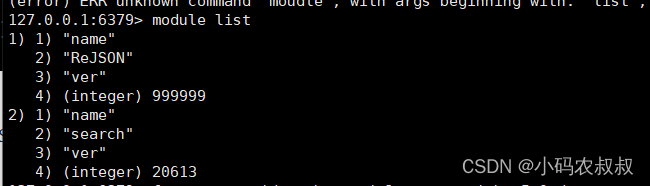
安装完成之后使用 redis-cli 来检查 RediSearch 模块是否加载成功,使用 Docker 启动 redis-cli,命令如下:
docker exec -it myredis redis-cli
在基础命令的使用上,RedisSearch与之前并没有什么区分,可以理解是原生的redis的一种升级版。使用下面的命令检查下安装的RediSearch 包括的功能模块
module list
看到下面的效果,说明RedisSearch模块加载成功
五、RedisJson/ RedisSearch命令使用
接下来对RedisSearch与RedisJson中的常用操作命令通过案例做一下深入的使用和了解。
5.1 RedisJson操作命令
5.1.1 保存操作
语法
JSON.SET <key> <path> <json> [NX | XX]
参数说明:
- 对于新的Key,path需要使用$或 .;
- 对于已经存在Key,在进行保存操作之后,原来path路径的值将会被替换掉;
- NX:表示只有Key不存在,才执行保存操作;
- XX:表示只有Key存在,才执行保存操作;
- 通过命令type doc可以查看到存储进去的数据是ReJSON-RL类型;
使用下面的命令添加一条json数据
JSON.SET json_1 . '{"name":"jerry","age":22,"city":"hangzhou"}'
5.1.2 读取操作
语法
JSON.GET <key>
[INDENT indentation-string]
[NEWLINE line-break-string]
[SPACE space-string]
[path ...]参数说明:
- 允许使用多个path进行查询;
- INDENT 查询结果替换掉默认缩进字符(用于返回Pretty-formatted JSON);
- NEWLINE 查询结果替换掉默认换行符(用于返回Pretty-formatted JSON);
- SPACE 查询结果替换掉默认空格(用于返回Pretty-formatted JSON);
- 获取JSON对象中的属性时需要以.开头
使用下面的命令获取上面添加进去的数据
JSON.GET json_1
5.1.3 批量读取操作
语法
JSON.MGET <key> [key ...] <path>参数说明:
- 最后一个参数作为path进行处理;
- 遍历每一个Key的path,如果不存在,则返回null;
准备两条数据
JSON.SET json_1 . '{"name":"jerry","age":22,"city":"hangzhou"}'
JSON.SET json_2 . '{"name":"mike","age":26,"city":"beijing"}'
使用mget批量获取多条数据

5.1.4 删除操作
语法
JSON.DEL <key> [path]参数说明
- path是可选的,如果没有输入,则默认整个Key删除掉;
更多redisJson命令参考文档说明:Commands | Redis
5.2 RedisSearch操作命令
RedisSearch的操作可以说是与RedisJson密不可分的,两者在使用上具有一定的前后关系,简单理解就是RedisSearch通常操作的数据就是RedisJson结构的数据。
5.2.1 创建索引
RedisSearch在使用之前,需要提前定义json数据结构的相关属性,包括指定索引命名,json中的字段类型等,这就有点像操作mysql表需要提前创建表一样。
ft.create myidx schema title text weight 5.0 desc text参数说明:
- “myidx”为索引的ID;
- 此索引包含了两个字段“title”和“desc”;
- “weight”为权重,默认值为 1.0;

5.2.2 为索引添加内容
添加内容到上面的索引
ft.add myidx doc1 1.0 fields title "He urged her to study English" desc "good idea"
其中“doc1”为文档 ID(docid),“1.0”为评分(score)

5.2.3 根据关键字查询
使用下面的语句查询索引中包含 english关键字的数据
ft.search myidx "english" limit 0 10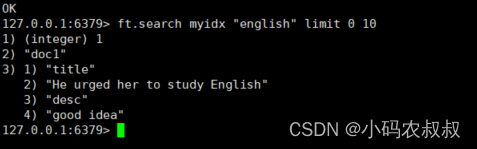
5.3 RedisSearch 扩展使用
上面演示了一下使用RedisJson和RedisSearch的基本操作命令,下面继续深入研究一下RedisSearch更深入的使用。
5.3.1 前置准备
定义json模板
FT.CREATE itemIdx ON JSON LANGUAGE chinese SCHEMA $.name AS name TEXT $.description as description TEXT $.brandName AS brandName TAG $.price AS price NUMERIC SORTABLE
参数说明:
- FT.CREATE itemIdx :创建一个名为 itemIdx 的 RedisSearch索引;
- 此命令创建一个索引,该索引代表 与JSON 文档中的name、description 、brandName和price相关联进行索引,设置索引语言为chinese:
SCHEMA 这部分定义了索引的字段和他们的数据类型
- $.name as name TEXT : 定义了一个名为name的文本字段,对应于JSON键 $name ,这个字段存储的是文本类型的数据;
- $.description as description TEXT : 定义了一个名为description 的文本字段,对应于JSON键 $description ,这个字段存储的是文本类型的数据;
- $.brandName as brandName TAG : 定义了一个名为brandName 的TAG字段,对应于JSON键 $brandName ,这个字段存储的是TAG类型的数据;
- $.price as price NUMERIC : 定义了一个名为price的文本字段,对应于JSON键 $price ,这个字段存储的是NUMERIC类型的数据;
支持的常用的数据类型
- TEXT(文本):用于存储文本类型的数据,可以进行全文搜索和模糊匹配;
- NUMERIC(数值):用于存储数值数据,支持范围查询和聚合操作;
- TAG(标签):用于存储标签或分类信息,支持过滤和聚合操作;
- VECTOR(向量):用于存储多维向量数据,支持基于向量相似性的搜索;
执行下面的语句为上述自定义json索引添加几条数据
JSON.SET a1 $ '{"name": "Iphone 15plus","description": "Iphone15-16G-25G","brandName":"Iphone","price": 5699}'
JSON.SET a2 $ '{"name": "华为Mate60 pro","description": "HuaWei-32G-512G","brandName":"华为","price": 7799}'
5.3.2 查询全部数据
建立完索引后,我们就可以使用FT.SEARCH对数据进行查看了,比如使用*可以查询全部;
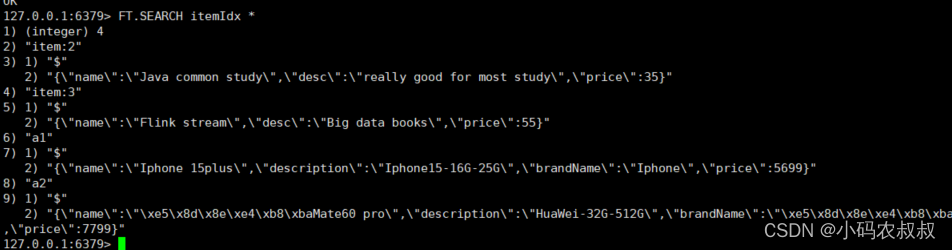
5.3.3 查询并按照字段排序
设置了price字段为SORTABLE,我们可以以price降序返回查询数据
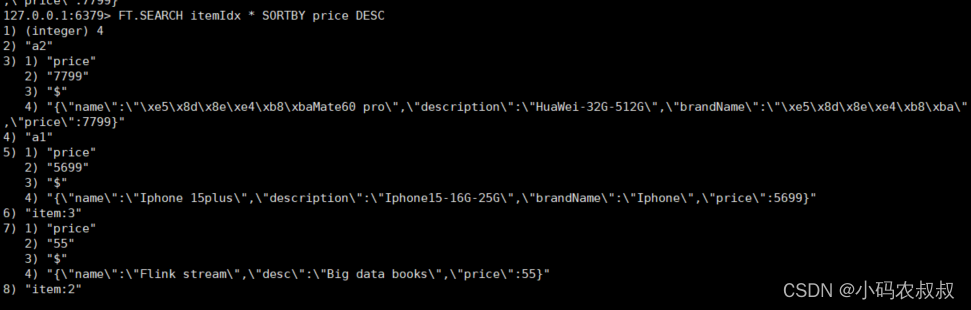
5.3.4 返回指定字段
FT.SEARCH itemIdx * RETURN 2 name price
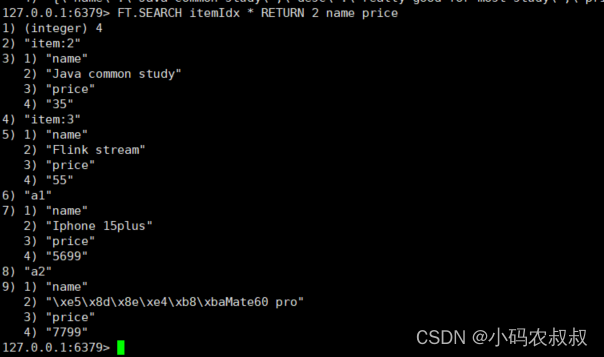
5.3.5 模糊查询
还可以使用像like一样的模糊查询,例:查询name以华为开头的
FT.SEARCH item '@name:华为*'

5.3.6 查询范围区间的数据
使用如下语句查询价格在5000~6000的商品;
FT.SEARCH itemIdx '@price:[5000 6000]'

5.3.7 关键词检索
FT.SEARCH中直接指定搜索关键词,可以对所有TEXT类型的属性进行全局搜索,支持中文搜索
FT.SEARCH itemIdx 'Iphone'

5.3.8 高亮显示
使用HIGHLIGHT来进行高亮显示效果(默认对搜索关键字加上<b></b>),HIGHLIGHT必须跟在return后面,return 1 name表示返回一个name字段;对name字段高亮显示。测试了一下,高亮只对TEXT类型有效
FT.SEARCH itemIdx '@name:(华为)' return 1 name HIGHLIGHT

5.3.9 删除索引
使用FT.DROPINDEX命令可以删除索引,如果不加DD只会删除索引,与索引关联的JSON文档不会删除;如果加入DD选项的话,会连数据一起删除;
FT.DROPINDEX itemIdx DD
小结:
细心的同学可能会发现,在Redis的基本数据结构中,Hash这种数据结构和json很类似,因为它们两者存储的都是json类型结构的数据,但是使用JSON的方式与HASH相比,JSON更快。在对数据做修改时,hash需要删除整个文档再将修改后的文档添加,而json可以直接对文档中的某一字段修改。
六、Java操作RedisJson
在Java中操作RedisJson和RedisSearch毕比较简单的方式就是使用jedis,下面演示如何基于jedis来操作RedisJson和RedisSearch
6.1 引入基本依赖
这里注意引入的jedis的版本,我这里使用的是4.0以上的版本,版本太低的话某些与RedisJson相关的API可能无法使用
<!--测试单元 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!--用来操作redis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.0.1</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.15</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lomok.version}</version>
</dependency>6.2 相关操作API
下面给出了使用RedisJson的方式操作对象的相关API,以及RedisSearch的操作API
import cn.hutool.core.lang.Console;
import cn.hutool.json.JSONUtil;
import com.congge.entity.TbUser;
import org.junit.Test;
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.UnifiedJedis;
import redis.clients.jedis.providers.PooledConnectionProvider;
import redis.clients.jedis.search.*;
import java.util.List;
public class RedisJsonTest {
static UnifiedJedis client;
static {
// redis连接
HostAndPort config = new HostAndPort("IP", 6379);
PooledConnectionProvider provider = new PooledConnectionProvider(config);
client = new UnifiedJedis(provider);
}
/**
* 添加json数据
*/
public static void addJson(){
TbUser tbUser1 = new TbUser("jerry",30,"杭州西湖区");
TbUser tbUser2 = new TbUser("mike",29,"北京东城区");
TbUser tbUser3 = new TbUser("john",28,"武汉汉口");
// 添加json
client.jsonSet("user:1", redis.clients.jedis.json.Path.ROOT_PATH,tbUser1);
client.jsonSet("user:2",redis.clients.jedis.json.Path.ROOT_PATH,tbUser2);
client.jsonSet("user:3",redis.clients.jedis.json.Path.ROOT_PATH,tbUser3);
System.out.println("添加json数据成功");
}
/**
* 根据key查询对象数据
*/
public static void getFromJsonKey(){
// 查询
TbUser student = client.jsonGet("user:1", TbUser.class,redis.clients.jedis.json.Path.ROOT_PATH);
System.out.println(JSONUtil.toJsonStr(student));
}
/**
* 创建索引
*/
public static void createIndex(){
Schema schema = new Schema().
addField(new Schema.Field(new FieldName("$.userName", "userName"), Schema.FieldType.TEXT)).
addField(new Schema.Field(new FieldName("$.address", "address"), Schema.FieldType.TEXT));
// 只索引key以user:开头的
IndexDefinition rule = new IndexDefinition(IndexDefinition.Type.JSON).setPrefixes("user:");
// 创建索引
client.ftCreate("user-index",IndexOptions.defaultOptions().setDefinition(rule),schema);
System.out.println("索引创建成功");
}
/**
* 根据索引中的字段查询
*/
public static void queryByIndexField(){
// 查询名字以John开头的学生,并高亮显示
Query q = new Query("@userName:jerry")
//.highlightFields(new Query.HighlightTags("<b>","</b>"),"userName")
.returnFields("userName","address");
SearchResult searchResult = client.ftSearch("user-index", q);
List<Document> documents = searchResult.getDocuments();
for(Document document : documents){
Console.log(JSONUtil.toJsonStr(document));
System.out.println();
document.getProperties().forEach(item ->{
System.out.println(item.getKey());
System.out.println(item.getValue());
});
}
}
public static void main(String[] args) {
//addJson();
//getFromJsonKey();
//createIndex();
queryByIndexField();
}
}下面是根据某个字段的查询结果

七、SpringBoot操作RedisJson
基于上述使用jedis操作RedisJson与RedisSearch的操作,接下来演示如何与springboot进行整合
7.1 添加配置文件
添加application.yaml配置文件,主要配置redis相关的信息,参考如下内容
server:
port: 8087
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
redis:
database: 0
host: IP
port: 6379
jedis:
pool:
max-active: 307.2 添加jedis配置类
该配置类即为全局注入一个jedis的客户端,可以在需要调用的位置直接注入使用
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.UnifiedJedis;
import redis.clients.jedis.providers.PooledConnectionProvider;
@Configuration
public class UnifiedJedisClientConfig {
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port:6379}")
private Integer port;
@Bean
public UnifiedJedis unifiedJedis() {
HostAndPort config = new HostAndPort(host, 6379);
PooledConnectionProvider provider = new PooledConnectionProvider(config);
UnifiedJedis unifiedJedis = new UnifiedJedis(provider);
return unifiedJedis;
}
}7.3 测试类
编写一个测试接口
@RestController
public class UserRedisJsonController {
private static final Logger logger = LoggerFactory.getLogger(UserRedisJsonController.class);
@Autowired
private UnifiedJedis jedis;
//localhost:8087/addJson
@GetMapping("/addJson")
public String add(){
TbUser tbUser1 = new TbUser("jerry",30,"杭州西湖区");
TbUser tbUser2 = new TbUser("mike",29,"北京东城区");
TbUser tbUser3 = new TbUser("john",28,"武汉汉口");
// 添加json
jedis.jsonSet("user:1", redis.clients.jedis.json.Path.ROOT_PATH,tbUser1);
jedis.jsonSet("user:2",redis.clients.jedis.json.Path.ROOT_PATH,tbUser2);
jedis.jsonSet("user:3",redis.clients.jedis.json.Path.ROOT_PATH,tbUser3);
System.out.println("添加json数据成功");
return "success";
}
/**
* 根据key查询对象数据
* localhost:8087/getFromJsonKey
*/
@GetMapping("/getFromJsonKey")
public void getFromJsonKey(){
// 查询
TbUser tbUser = jedis.jsonGet("user:1", TbUser.class,redis.clients.jedis.json.Path.ROOT_PATH);
System.out.println(JSONUtil.toJsonStr(tbUser));
}
@GetMapping("/createIndex")
public String createIndex(){
// 创建索引
createIndex("users-index","users:", new String[]{"userName","address"});
return "索引创建成功";
}
public boolean createIndex(String indexName, String key, String... fields){
try {
try{
Map<String, Object> map = jedis.ftInfo(indexName);
logger.info("index configuration:{}",map);
jedis.ftDropIndex(indexName);
} catch (Exception e){
logger.error("the index does not exist", e);
}
Schema schema = new Schema();
float weight = 1.0f;
for(String field : fields) {
String attribute;
if (!StringUtils.isEmpty(field)) {
if (field.indexOf(".") == -1) {
attribute = field;
} else {
String[] fieldSplit = field.split("\\.");
attribute = fieldSplit[fieldSplit.length - 1];
}
if (attribute.toLowerCase().startsWith("geo")) {
Schema.Field field1 = new Schema.Field(FieldName.of("user:" + field).as(attribute), Schema.FieldType.GEO);
schema.addField(field1);
continue;
} else {
Schema.TextField textField = new Schema.TextField(FieldName.of("user:" + field).as(attribute), weight, false, false, false, null);
schema.addField(textField);
weight *= 3;
continue;
}
}
}
IndexDefinition rule = new IndexDefinition(IndexDefinition.Type.JSON).setLanguage("chinese")
.setPrefixes(new String[]{key});
jedis.ftCreate(indexName,
IndexOptions.defaultOptions().setDefinition(rule),
schema);
return true;
} catch (Exception e){
logger.error("create redis search index failed", e);
return false;
}
}
}测试其中一个接口,效果如下

八、写在文末
RedisJson是Redis扩展功能中的重要数据结构,基于RedisJson结构可以在实际业务中巧妙处理一些疑难杂症,让程序得到很好的灵活性和扩展性,值得深入研究和学习,本篇到此结束,感谢观看,