背景
在推荐、广告、搜索等互联网场景下,动则TB甚至PB级数据量。导致几乎不可能在传统单机环境下完成机器学习模型的训练。分布式机器学习训练成为称为唯一选择。
主要手段
• Spark MLlib
• Parameter Server
• Tensorflow
Spark MLlib
MLlib从功能上说与Scikit-Learn等机器学习库非常类似,但计算引擎采用的是Spark,即所有计算过程均实现了分布式,这也是它和其他机器学习库最大的不同。
• 把当前模型参数广播到各个数据Partition(worker)
• 把各计算节点进行数据抽样得到mini batch的数据,
分别计算梯度,再通过treeAggregate操作汇总梯度,
得到最终梯度gradientSum
• 利用gradientSum更新模型参数
局限性:
• 采用全局广播的方式,在每轮迭代前广播全部模型参数,非常消耗带宽资源
• 采用阻断式梯度下降方式,每轮梯度下降由最慢的节点决定(同步问题)
Spark MLlib的mini batch过程是在所有节点计算完各自的梯度之后逐层聚合,最终汇总生成全局的梯度。
也就是说如果出现数据倾斜导致某个节点计算梯度时间过长,那么这一过程将阻断其他所有节点。
• Spark MLlib并不支持复杂深度学习网络结果结构和大量可调超参
Spark MLlib在其标准库里只支持标准的MLP的训练,并不支持RNN、LSTM等复杂网络结构,
而且无法选择不同的激活函数等大量超参。
Parameter Server
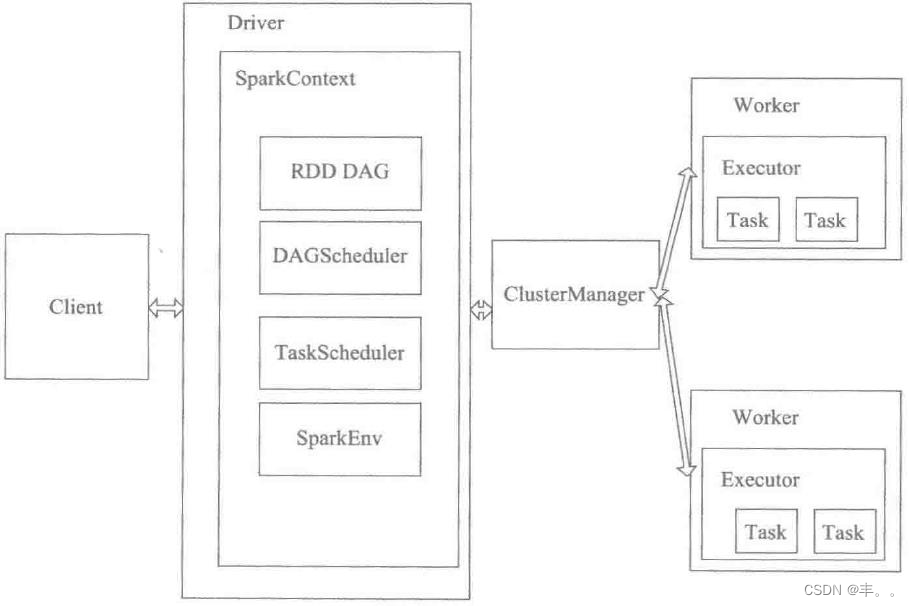
概念:参数服务器是个编程框架,用于方便分布式并行程序的编写,其中重点是对大规模参数的分布式存储和协同的支持。工业界需要训练大型的机器学习模型,一些广泛使用的特定的模型在规模上的两个特点:1. 参数很大,超过单个机器的容纳能力(比如大型Logistic Regression和神经网络)2. 训练数据巨大,需要分布式并行提速(大数据)这种需求下,当前类似MapReduce的框架并不能很好适合。因此需要自己实现分布式并行程序,其实在Hadoop出来之前,对于大规模数据的处理,都需要自己写分布式的程序(MPI)。 之后这方面的工作流程被Google的工程师总结和抽象成MapReduce框架,大一统了。参数服务器就类似于MapReduce,是大规模机器学习在不断使用过程中,抽象出来的框架之一。重点支持的就是参数的分布式,毕竟巨大的模型其实就是巨大的参数。
• 用异步非阻断式的分布式梯度下降策略替代同步阻断式的梯度下降策略。
• 实现多server节点的架构,避免单master节点带来的带宽瓶颈和内存瓶颈
• 实现使用一致性哈希,参数范围pull,参数范围push等工程手段实现信息
的最小传递,避免广播操作带来全局性网络网络阻塞和带宽浪费
服务器节点组
- 每个服务器节点负责保存一部分模型参数,接受工作节点的局部梯度来汇总计算全局梯度,并更新模型参数
- 节点间可通信
- manager node负责metadata的一致性,如节点状态,参数分配
工作节点组 - 每个工作节点保存部分训练数据,拉取对应服务器节点模型参数并计算当前梯度,然后上传对应该服务器节点
- 工作节点组间,以及工作节点组内部的任务节点之间并不通信,任务节点只与server通信
- task scheduler负责为工作节点分配任务监控工作节点运行情况,当有新的工作节点加入或者退出时,!负责重新分配任务
资源管理中心组 - 负责维护和分配各节点资源
物理架构
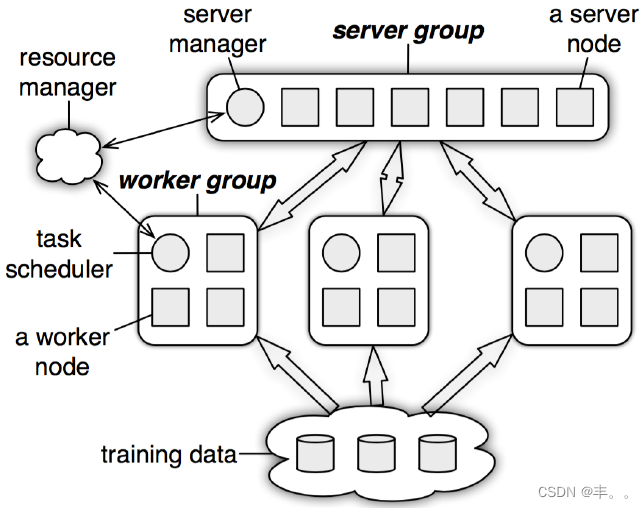
并行训练示意图
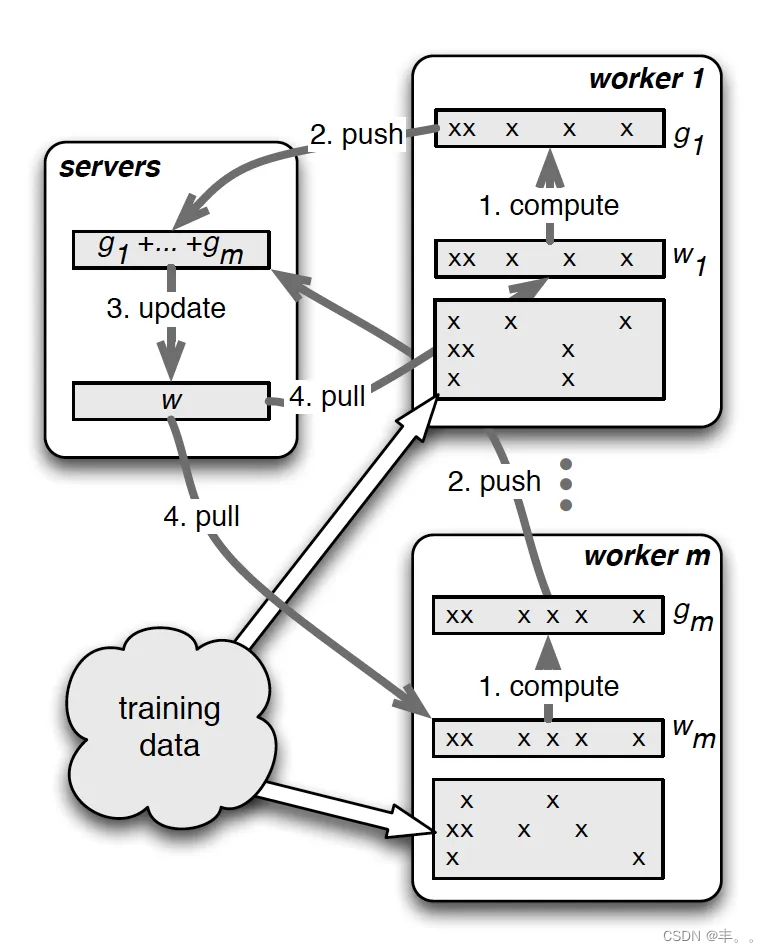
同步的SGD的实现

异步的SGD的实现


Sequential:
任务之间是有顺序的,只有上一个任务完成,才能开始下一个任务(同步)
Eventual:
所有任务之间没有顺序,各自独立完成自己的任务(异步)
Bounded Delay:
Sequentia跟 Eventual 之间的trade-off,设置一个 𝜏 作为最大的延时时间,
只有 𝜏 之前的任务都被完成了,才能开始一个新的任务
𝜏 = 0, 情况就是 Sequential
𝜏 = ∞, 情况就是 Eventual

Vector Clock
parameter server中,参数都是可以被表示成(key;value)的集合,key就是feature ID,而value就是它的权重,对于稀疏参数,不存在的key,就可以认为是0
为参数伺服器中的每个参数添加一个时间戳,来跟踪参数的更新和防止重复发送数据,基于此,通信中的梯度更新数据中也有时间戳,防止重复更新
如果每个参数都有一个时间戳,那么参数众多,时间截也众多,由于parameter server在oush和oul的时候都是range-based,那么在range里面的参数共享同一个时间戳,就可以大大降低空间复杂度
Messages
Messages是节点间交互的主要格式,条message包括[ timestamp ,(k, v),(k1, V1),…]
kev和value的压缩
节点增加或减少的一致性哈希(负载均衡
tensorflow
计算图+session
计算存在依赖关系的任务节点或者子图之间需要串行执行,不存在依
赖关系的任务节点或子图可以并行执行
TensorFlow的分布式训练模式采用parameter server策略,则各worker
节点会以数据并行方式训练
单机采用CPU+GPU多核并行
关于tensorflow,更加详细的内容可以看这个专栏