从零搭建完整python自动化测试框架(UI自动化和接口自动化)
文章目录
总体框架
PO模式、DDT数据驱动、关键字驱动
框架技术选择
框架运行结果
各用例对应的定义方式(PO/DDT)
测试执行结果
从零开始搭建项目
一、开发环境搭建
二、新建项目
三、基础功能实现
1. 配置功能实现(Conf)
2. 日志功能实现(Log)
3. 读取EXCEL实现(data)
4. 邮件发送实现(Email)
四、WEB UI自动化
1. 页面PO对象配置
2. 实现basePage基类
3. 写业务测试用例
五、实现主程序
1. API对象配置
2.实现base_api基类
3.测试用例
补:MD5函数
结语
本自动化测试框架采用python + unittest 的基础来搭建,采用PO模式、数据驱动的思想,通过selenium来实现WEB UI自动化,通过request来实现接口自动化。移动终端的自动化也可在该框架基础上去构建补充。
总体框架
总体框架如下图:
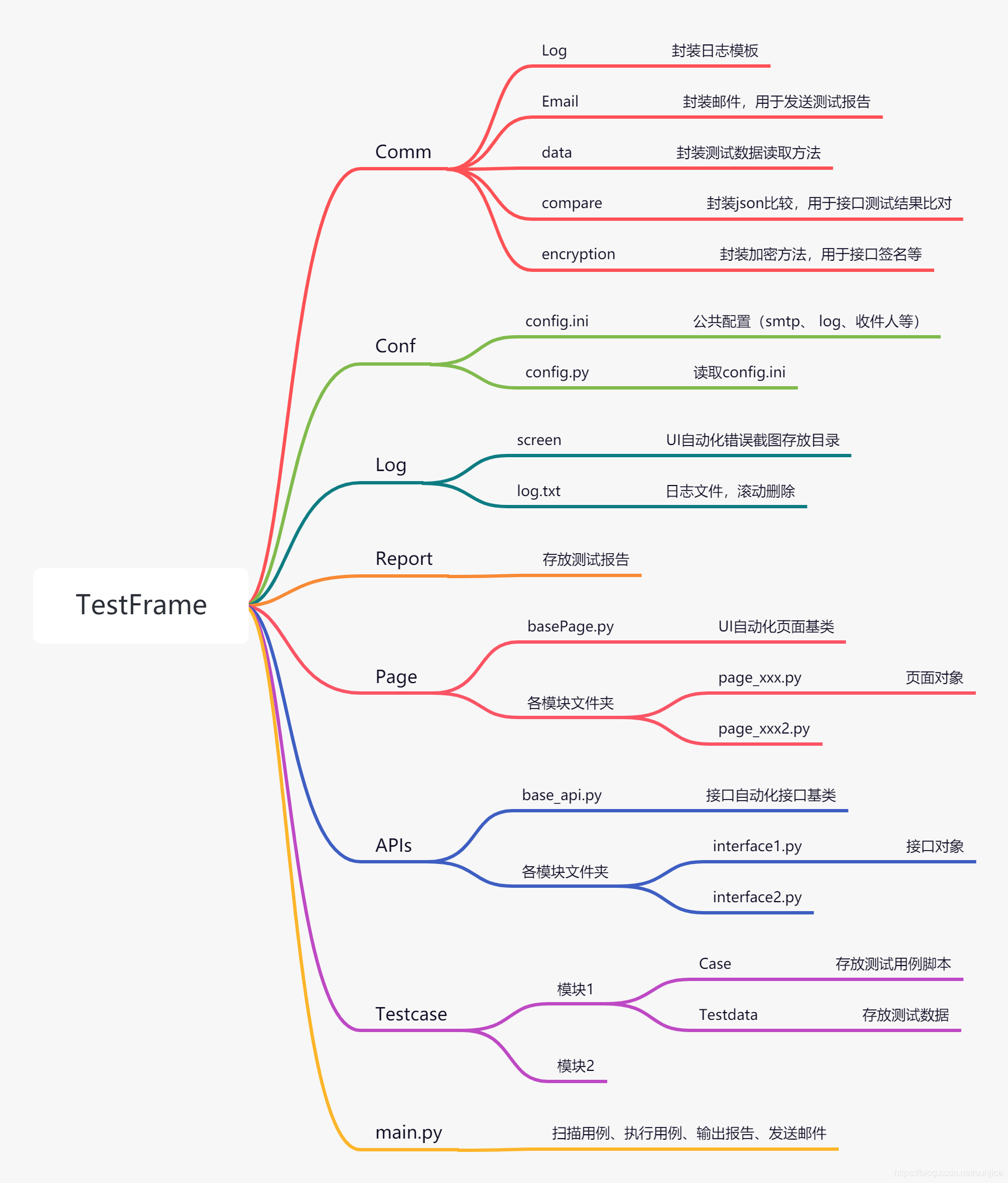
用例扫描、测试结果反馈,如要和其它项目管理系统或是用例管理系统对接(比如testlink),就需要单独出来进行处理。
对于大型的产品,用例数特别多的话,需要建设一个master节点,专门负责管理用例和脚本,分发测试脚本,指定测试环境,汇总测试结果等。各节点执行分给自己的测试用例即可。
PO模式、DDT数据驱动、关键字驱动
PO模式(Page Object)是UI自动化测试常采用的一种设计模式,用于解决开发频繁修改UI页面而导致的自动化脚本维护困难的问题。
PO模式中心思想:
- 每一个页面为一个对象;
- 每一个对象维护着页面中的各元素和操作方法;
- 用例测试脚本只需要聚集业务逻辑和测试数据;
- UI页面的变更,只需要修改对应的PO对象,无需修改测试脚本(理想情况下。实际上也很难100%做到,因为UI的变更很多时候意味着业务逻辑的变更)。
DDT(Data Driven Testing)数据驱动测试模式,用来解决部分自动化用例逻辑完全相同,只有测试数据和预期结果不同的问题。实际上就是同一测试脚本使用不同的测试数据来反复执行(但脚本只需要写一个),测试数据和测试行为完全分离。
DDT中心思想:
- 将测试数据分离出来,单独维护;
- 减少重复自动化用例的数量。
将以上两种思想进行结合,就可以做成 对象、数据、业务行为 三者分离的模型,再结合模块进行管理,为后续自动化用例脚本的长期维护打下基础。否则时间一长自动化就会乱成一团,维护成本越来越高,陷入自动化率不升反降的怪圈。
关键字驱动(Keyword Driven Testing),在前面的基础上,可以进一步实现关键字驱动。即将业务逻辑相同的部分,抽象成关键字库。这样在写自动化用例脚本时,只需要写关键字和对应测试数据即可,可以进一步减少工作量,减少测试人员对代码的学习和依赖。
如京东搜索商品时直接写脚本需要好多步:
- 定位到搜索框
- 输入关键字
- 定位到搜索按钮
- 点击搜索按钮
- 定位结果列表
- 获取结果并返回
以关键字驱动的思想,即将这6步抽象出一个方法jd_search(),测试人员只需要写一句话就能完成以上所有动作获得结果。如:
result = jd_search('电脑')
方便、省时省力,测试人员可聚焦于产品业务,而不是自动化脚本和语言学习。
甚至可以直接在设计测试用例的时候写关键字,由自动化平台去解析用例,都不需要写脚本。这方面最有名的自动化框架就是RobotFrameWork。但是RobotFrameWork过于笨重。建议大家适当抽象即可,不要过度抽象。
框架技术选择
大多数框架采用java语言或是python语言来实现,考虑到python容易掌握,各种库也比较全,所以采用python语言来实现。
python自动化框架最常用的有unittest和pytest,两者都可以,这里采用python自带的unittest。
对于WEB UI自动化测试,没有别的选择,基本都是采用selenium来驱动浏览器来完成。
对于接口自动化测试,可采用的办法较多,postman、jmeter都可以,但灵活性都不如直接采用python的request库。
数据驱动,由于unittest没有直接可用的dataprovider,采用常见的ddt来实现。
对于手机自动化,暂未实现,后续考虑加入,可采用appnium来实现。
测试数据,第1阶段采用excel管理,对于大型系统,建议直接采用数据库进行管理。
所以总的来讲,这个所谓的框架,就是东拼本凑,即没有新思想,也没有新技术,只是将一些常用的技术,按一定的思路组织起来、驱动起来而已。
框架运行结果
总共执行6个用例,4个为京东搜索并抓取结果(WEB UI自动化测试),2个为百度翻译通用接口(接口自动化测试)。
各用例对应的定义方式(PO/DDT)
页面定义方式
PO对象定义:京东主页面定义了搜索框和搜索按钮,以name为关键字,定义元素定位方式和执行的动作。
page_url = 'https://www.jd.com'
elements = [
{'name': 'search_ipt', 'desc': '搜索框', 'by': (By.ID, u'key'), 'action': 'send_keys()'},
{'name': 'search_btn', 'desc': '搜索按钮', 'by': (By.CLASS_NAME, u'button'), 'action': 'click()'},
]
测试数据定义方式:
API接口定义方式
直接采用大家接口测试时熟悉的json格式来定义。
# 接口地址信息
uri_scheme = 'http'
endpoint = 'api.fanyi.baidu.com'
resource_path = '/api/trans/vip/translate'
url = uri_scheme + u'://' + endpoint + resource_path
# 保持不变的参数
_from = 'en'
_to = 'zh'
# 请求消息参数模板
req_param = {
"q": "", # 请求翻译 query, UTF-8
"from": _from, # 翻译源语言
"to": _to, # 翻译目标语言
"appid": "", # APP ID
"salt": "", # 随机数
"sign": "", # 签名,app_id+q+salt+密钥 的MD5值
}
# 响应消息参数模板
res_param = {
"from": _from,
"to": _to,
"trans_result": [
{
"src": "Hello World! This is 1st paragraph.",
"dst": "你好,世界!这是第一段。"
},
{
"src": "This is 2nd paragraph.",
"dst": "这是第二段。"
}
]
}
对应的请求消息头headers等内容也可以定义在这里面。
主程序main.py
负责扫描用例,执行用例,并生成测试报告,发送邮件。
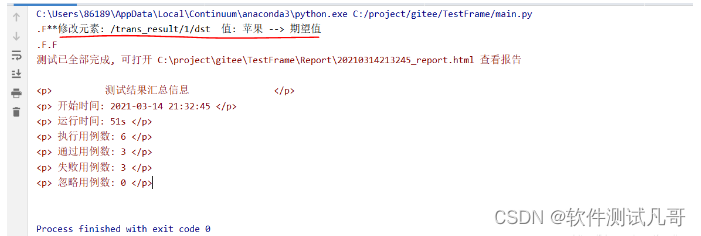
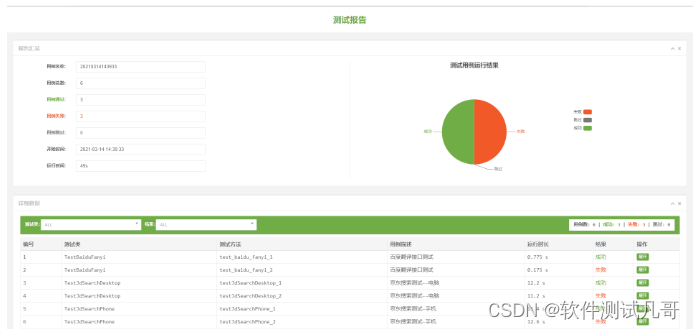
测试执行结果
3个脚本,每个脚本2条测试数据,共6个用例。运行main.py,执行测试,测试结果如下,3个失败的是故意修改了测试数据。
红线部分为接口测试时,自动比对的json差异,预期结果为“苹果”,实际结果为“期望值”。
测试报告邮件:
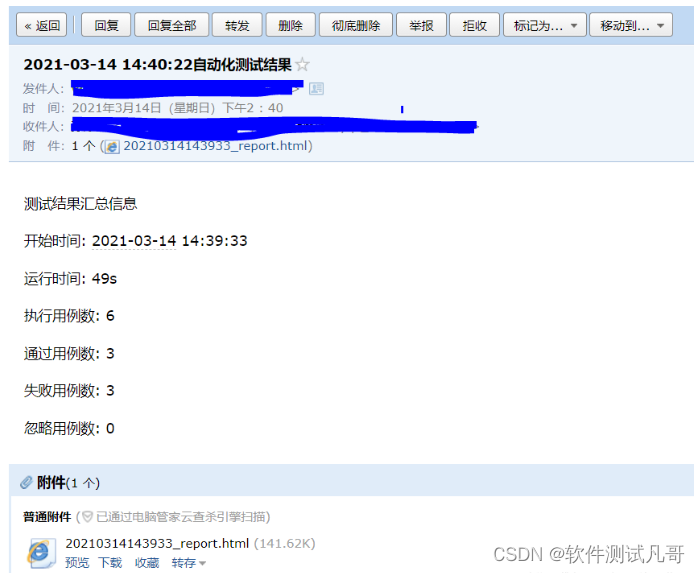
测试报告详情:
从零开始搭建项目
一、开发环境搭建
- 开发IDE: pycharm
- python: python 3
- 依赖库:anaconda 3(个人比较懒,懒得一个一个库的安装,这个库比较全)
基本上都是直接上对应官网,下载安装。准备好了以后,直接开干。
二、新建项目
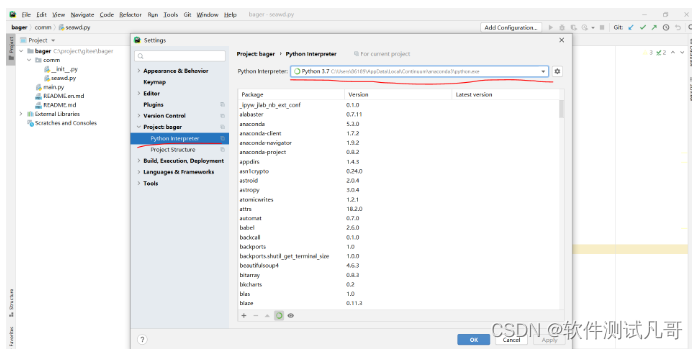
pycharm上新建项目TestFrame,选择好存放目录,并在TestFrame项目下新建各模块。注意除了Log和Report是新建Directory外,其它的都是新建Python Package,因为下面还要放py文件的。
pycharm上切换项目的python环境为anaconda,File—>Settings—>Project下面切换,如下图:
三、基础功能实现
1. 配置功能实现(Conf)
配置功能是项目的基础,所以先实现。在Conf目录下新建2个文件,分别为config.ini和config.py。
config.ini内容如下:
[sys]
base_url = https://www.jd.com
[smtp]
host = smtp.163.com
port = 465
user = example@163.com
passwd = password暂时先加这么多,后续需要再慢慢添加。
config.py文件实现config.ini文件的读取。
ini文件读取,python有ConfigParser库可以使用,那就直接用。
ConfigParser库传送门
但是每次取值都要用他的方法,比较麻烦,因此对它的方法进行了一个继承和改写,直接将配置文件中所有内容读出来字典形式,方便后续使用。
代码如下:
import os
from configparser import ConfigParser
# 使用相对目录确定文件位置
_conf_dir = os.path.dirname(__file__)
_conf_file = os.path.join(_conf_dir, 'config.ini')
# 继承ConfigParser,写一个将结果转为dict的方法
class MyParser(ConfigParser):
def as_dict(self):
d = dict(self._sections)
for k in d:
d[k] = dict(d[k])
return d
# 读取所有配置,以字典方式输出结果
def _get_all_conf():
_config = MyParser()
result = {}
if os.path.isfile(_conf_file):
try:
_config.read(_conf_file, encoding='UTF-8')
result = _config.as_dict()
except OSError:
raise ValueError("Read config file failed: %s" % OSError)
return result
# 将各配置读取出来,放在变量中,后续其它文件直接引用这个这些变量
config = _get_all_conf()
sys_cfg = config['sys']
smtp_cfg = config['smtp']
print(sys_cfg)
print(smtp_cfg)
print(smtp_cfg['host'])
运行结果:
{'base_url': 'https://www.jd.com'}
{'host': 'smtp.163.com', 'port': '465', 'user': 'example@163.com', 'passwd': 'password'}
smtp.163.com
后续其它文件就可以直接使用 sys_cfg 和 smtp_cfg 这两个字典,以key的方式访问需要的配置内容。
2. 日志功能实现(Log)
日志在项目中也是基础功能,所以接着做日志。
python自带logging库,可以定制日志的格式,就直接使用该库实现,没必要自己造。
先去我们的配置文件中config.ini添加日志相关的配置,这里先定义3个配置:日志级别、日志格式、日志路径。
[log]
log_level = logging.DEBUG
log_format = %(asctime)s - %(name)s - %(filename)s[line:%(lineno)d] - %(levelname)s - %(message)s
log_path = Log
再在config.py中最后面添加一行代码,把log相关的配置放在一个变量中,好直接使用。
log_cfg = config['log']
print(smtp_cfg)
打印出来看一下结果:
{'log_level': 'logging.DEBUG', 'log_format': '%(asctime)s - %(name)s - %(filename)s[line:%(lineno)d] - %(levelname)s - %(message)s', 'log_path': 'Log'}
日志级别有:DEBUG、INFO、WARN、ERROR、FATAL。一般调试都是DEBUG,上线就改为INFO。
这里简单介绍一下日志格式log_format的内容:
| 参数 | 意义 | 说明 |
|---|---|---|
| asctime | 时间 | 格式:2021-03-14 09:37:40,258 |
| name | logger的名称 | 简单理解就是将来把模块名称填到这里,区分是谁打的日志 |
| filename | 文件名 | 哪个文件打印的这条日志 |
| line | 行号 | 哪一行打印的这条日志 |
| levelname | 级别 | 日志的级别,注意是级别的name |
| message | 内容 | 我们打印的日志内容 |
| log_path | 日志文件 | 保存到哪个日志文件 |
再接着在Comm目录下,新建一个Log.py,开始定制日志。定制日志还有几个问题要提前考虑:
一是存放目录问题,我们这里使用了固定目录,所以问题不大。
二是日志分割、滚动问题,每天跑持续集成,大量用例生成大量日志,日志堆成山。如果觉得日志有用呢,就搞个ELK把日志取走存放起来做分析。如果觉得日志没用呢,保存几天后就删除掉。无论怎么讲,都要实现日志的分割和滚动。
幸好你想到的大佬们早就想到了,logging模块就有这个功能,只要配置一下就可以了。
下面开搞,引入logging库,把项目的根路径取出来,把上面config.ini中的日志配置取过来,最后拼接好日志文件存放的绝对路径:
import os
import logging
from Conf.Config import log_cfg
_BaseHome = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))
_log_level = eval(log_cfg['log_level'])
_log_path = log_cfg['log_path']
_log_format = log_cfg['log_format']
_log_file = os.path.join(_BaseHome, _log_path, 'log.txt')
注意上面log_level的写法,这里用了个eval,如果不加这个函数,log_level取过来是个字符串,没法直接用,通过eval执行后,就变成了logging定义的对象了。
再配置日志,引入TimedRotatingFileHandler这个东东,这是实现滚动日志的。
from logging.handlers import TimedRotatingFileHandler
def log_init():
logger = logging.getLogger('main')
logger.setLevel(level=_log_level)
formatter = logging.Formatter(_log_format)
handler = TimedRotatingFileHandler(filename=_log_file, when="D", interval=1, backupCount=7)
handler.setLevel(_log_level)
handler.setFormatter(formatter)
logger.addHandler(handler)
console = logging.StreamHandler()
console.setLevel(_log_level)
console.setFormatter(formatter)
logger.addHandler(console)
这个日志里面,加了两个输出,handler用于向日志文件打印日志,console 用于向终端打印日志,两个的定义方式不同。
TimedRotatingFileHandler的参数简介:
| 参数 | 意义 | 说明 |
|---|---|---|
| filename | 日志文件 | 没啥好说的 |
| when | 切割条件 | 按周(W)、天(D)、时(H)、分(M)、秒(S)切割 |
| interval | 间隔 | 就是几个when切割一次。when是W,interval是3的话就代表3周切割一次 |
| backupCount | 日志备份数量 | 就是保留几个日志文件,起过这个数量,就把最早的删除掉,从而滚动删除 |
我这里配置的是每天生成1个日志文件,保留7天的日志。
日志就做好了,试一下效果。
log_init()
logger = logging.getLogger('main')
logger.info('log test----------')
运行结果:
2021-03-15 21:53:41,972 - main - Log.py[line:49] - INFO - log test----------
其它文件使用日志:
先在main.py里面引入这个log_init(),在最开始的时候初始化一下,日志就配置好了。
再在各个要使用日志的文件中,直接按下面这种方式使用:
import logging
logger = logging.getLogger('main.jd')
注意各个模块自己getLogger的时候,直接main后面加上“.模块名”,就能使用同一个logger区分模块了。
到这里日志功能就完成了。
顺手做个截图的功能,供大家使用。截图可以直接在用例里面用selenium提供的截图功能,也可以自己做一个公共的。下面是用PIL里面的功能做的截图。
from PIL import ImageGrab
# 先定义截图文件的存放路径,这里在Log目录下建个Screen目录,按天存放截图
_today = time.strftime("%Y%m%d")
_screen_path = os.path.join(_BaseHome, _log_path, 'Screen', _today)
#再使用PIL的ImageGrab实现截图
def screen(name):
t = time.time()
png = ImageGrab.grab()
if not os.path.exists(_screen_path):
os.makedirs(_screen_path)
image_name = os.path.join(_screen_path, name)
png.save('%s_%s.png' % (image_name, str(round(t * 1000)))) # 文件名后面加了个时间戳,避免重名
运行这个方法就能截图了,大功告成。截图文件其实也需要一个滚动删除,后面有时间再写吧。
3. 读取EXCEL实现(data)
接着写一个读取EXCEL文件数据的功能吧,这个项目里面主要是用来读测试数据,以实现数据驱动。
python读取excel数据,我看大家都喜欢用xlrd和xlwt,还有用openpyxl的,对于我这种懒人来讲,都太麻烦了。
我们用pandas来干,一句话的事情,搞那么多干吗,用python就是要快。
在Comm目录下,新建一个data.py,专门来处理数据。引入pandas,直接用pandas的read_excel读excel,而且支持它原始的其它参数,只是最后将结果转了字典,方便使用:
import pandas as pd
def read_excel(file, **kwargs):
data_dict = []
try:
data = pd.read_excel(file, **kwargs)
data_dict = data.to_dict('records')
finally:
return data_dict
随便放一个excel在同一个目录下,填上数据,试一下效果。excel里面2页数据,Sheet1如下:

Sheet2如下:
调用我们写好的方法,打印数据:
sheet1 = read_excel('baidu_fanyi.xlsx')
sheet2 = read_excel('baidu_fanyi.xlsx', sheet_name='Sheet2')
print(sheet1)
print(sheet2)
运行结果如下:
[{'req.q': '计算机\n计算机', 'req.from': 'zh', 'req.to': 'en', 'res.from': 'zh', 'res.to': 'en', 'res.trans_result.0.src': '计算机', 'res.trans_result.0.dst': 'computer', 'res.trans_result.1.src': '计算机', 'res.trans_result.1.dst': 'computer'},
{'req.q': 'computer\nexpected value', 'req.from': 'en', 'req.to': 'zh', 'res.from': 'en', 'res.to': 'zh', 'res.trans_result.0.src': 'computer', 'res.trans_result.0.dst': '计算机', 'res.trans_result.1.src': 'expected value', 'res.trans_result.1.dst': '苹果'}]
[{'req.q': '计算机', 'req.from': 'zh', 'req.to': 'en', 'res.from': 'zh', 'res.to': 'en'},
{'req.q': 'computer', 'req.from': 'en', 'req.to': 'zh', 'res.from': 'en', 'res.to': 'zh'}]
每页数据都读出来了,而且每一行都是字典形式,直接通过key就可以方便的使用。
pandas还能直接计算数据,如通过几个列算加密签名,写动态cookie等,使用方法也很简单。比如在数据中增加一列sign, 让它简单等于 req.from列 + ‘.aaaa.’ + req.to列,给大家演示一下。
data = pd.read_excel('baidu_fanyi.xlsx')
data['sign'] = data["req.from"] +'.aaaaa.' + data["req.to"]
data_dict = data.to_dict('records')
print(data_dict)
运行结果:
[{'req.q': '计算机\n计算机', 'req.from': 'zh', 'req.to': 'en', 'res.from': 'zh', 'res.to': 'en', 'res.trans_result.0.src': '计算机', 'res.trans_result.0.dst': 'computer', 'res.trans_result.1.src': '计算机', 'res.trans_result.1.dst': 'computer', 'sign': 'zh.aaaaa.en'},
{'req.q': 'computer\nexpected value', 'req.from': 'en', 'req.to': 'zh', 'res.from': 'en', 'res.to': 'zh', 'res.trans_result.0.src': 'computer', 'res.trans_result.0.dst': '计算机', 'res.trans_result.1.src': 'expected value', 'res.trans_result.1.dst': '苹果', 'sign': 'en.aaaaa.zh'}]
我们可以看到多了一列sign,值就是自动根据每一行的数据算出来的,这对于我们数据驱动来讲,去计算一些动态值非常有用。我这里没有用到动态的,只是读而已。大家如果要计算,就要自己写计算方法。
pandas还支持直接读各种主流数据库,后面扩展也很方便,我们一直都用它。
4. 邮件发送实现(Email)
实现邮件功能,用于发送测试报告。使用python的smtplib模块实现。
先在Conf目录下的config.ini中添加好邮件相关的配置:
[smtp]
host = smtp.163.com
port = 465
user = example@163.com
passwd = password
[email]
sender = example@163.com
receivers = example@qq.com, example@163.com
再在Config.py中将它们取到变量中放好:
smtp_cfg = config['smtp']
email_cfg = config['email']
然后在Comm目录下新建Email.py,开始撸代码。邮件支持了定义主题、正文和多个附件,控制了单个附件大小和附件总数。代码如下:
import smtplib
import os
import logging
from email.mime.text import MIMEText
from email.mime.application import MIMEApplication
from email.mime.multipart import MIMEMultipart
from email.header import Header
from Conf.Config import smtp_cfg, email_cfg
_FILESIZE = 20 # 单位M, 单个附件大小
_FILECOUNT = 10 # 附件个数
_smtp_cfg = smtp_cfg
_email_cfg = email_cfg
_logger = logging.getLogger('main.email')
class Email:
def __init__(self, subject, context=None, attachment=None):
self.subject = subject
self.context = context
self.attachment = attachment
self.message = MIMEMultipart()
self._message_init()
def _message_init(self):
if self.subject:
self.message['subject'] = Header(self.subject, 'utf-8') # 邮件标题
else:
raise ValueError("Invalid subject")
self.message['from'] = _email_cfg['sender'] # from
self.message['to'] = _email_cfg['receivers'] # to
if self.context:
self.message.attach(MIMEText(self.context, 'html', 'utf-8')) # 邮件正文内容
# 邮件附件
if self.attachment:
if isinstance(self.attachment, str):
self._attach(self.attachment)
if isinstance(self.attachment, list):
count = 0
for each in self.attachment:
if count <= _FILECOUNT:
self._attach(each)
count += 1
else:
_logger.warning('Attachments is more than ', _FILECOUNT)
break
def _attach(self, file):
if os.path.isfile(file) and os.path.getsize(file) <= _FILESIZE * 1024 * 1024:
attach = MIMEApplication(open(file, 'rb').read())
attach.add_header('Content-Disposition', 'attachment', filename=os.path.basename(file))
attach["Content-Type"] = 'application/octet-stream'
self.message.attach(attach)
else:
_logger.error('The attachment is not exist or more than %sM: %s' % (_FILESIZE, file))
def send_mail(self):
s = smtplib.SMTP_SSL(_smtp_cfg['host'], int(_smtp_cfg['port']))
result = True
try:
s.login(self._smtp_cfg['user'], self._smtp_cfg['passwd'])
s.sendmail(self._smtp_cfg['sender'], self._smtp_cfg['receivers'], self.message.as_string())
except smtplib.SMTPException as e:
result = False
_logger.error('Send mail failed', exc_info=True)
finally:
s.close()
return result
邮件初始化发送时的调用方式如下:
mail = Email(title, context, file)
send = mail.send_mail()
print(send)
返回结果为True则发送成功,否则发送失败。
四、WEB UI自动化
WEB UI自动化,采用 selenium来完成。通过PO对象、测试数据、业务逻辑三者分离的方式来实现。
另外一个主旨是尽量让测试人员使用selenium原生的各种方法,而不要做过多封装。原因很简单,不要让测试人员来学这个框架,而是去学selenium,这样以后他出去换工作才有饭吃。如果过度封装,就会让测试人员来学这个框架,他以后出去selenium都不会用,这不是害了别人么。框架的目的只是把对象、数据、业务逻辑三者驱动起来,让测试人员工作起来更快。
我们以京东搜索爬虫为例来看如何构建这三者的关系:在京东主页面,搜索“电脑”,再获取搜索结果,保存。
1. 页面PO对象配置
打开京东商城主页,找到搜索框元素、和搜索按钮元素,分别确定他们的定位方式,以及元素对应的操作。
然后建立这个页面对象,在Page下新建一个名为"jd"的python package,再在这个package下新建一个jd.py,用来定义京东商城的主页面对象。
from selenium.webdriver.common.by import By
page_url = 'https://www.jd.com'
elements = [
{'name': 'search_ipt', 'desc': '搜索框点击', 'by': (By.ID, u'key'), 'ec': 'presence_of_element_located', 'action': 'send_keys()'},
{'name': 'search_btn', 'desc': '搜索按钮点击', 'by': (By.CLASS_NAME, u'button'), 'ec': 'presence_of_element_located', 'action': 'click()'},
]
name: 每个元素+操作的唯一标识。一个元素可能由于操作不同,而要定义多个,但大部分只要定义一个。
desc:元素+操作的描述。
by:元素的定位方式,使用selenium的原生定位方式,不自己定义封装。
ec: 等待元素出现的方式,这个暂时未用。
action:元素的对应操作。使用原生的selenium动作方法,不自己定义封装。
京东商城主页面现在只用到这两个,就只定义这两个。
搜索结果页面,定义如下:
from selenium.webdriver.common.by import By
page_url = 'https://search.jd.com/'
elements = [
{'name': 'result_list', 'desc': '结果列表', 'by': (By.CLASS_NAME, u'gl-item'), 'ec': 'presence_of_all_elements_located', 'action': None},
{'name': 'price', 'desc': '价格', 'by': (By.XPATH, u".//div[@class='p-price']/strong/i"), 'ec': 'presence_of_element_located', 'action': 'text'},
{'name': 'pname', 'desc': '描述', 'by': (By.XPATH, u".//div[@class='p-name p-name-type-2']/a/em"), 'ec': 'presence_of_element_located', 'action': 'text'}
]
2. 实现basePage基类
basePage基类的实现思想是不做过多的封装,尽量让测试人员直接使用selenium原装的方法,而不像其它框架一样什么都封装在这里面。
所以我对basePage的定义是:根据业务逻辑(测试用例)指定的元素,输入的数据,协助它完成元素定位和操作,仅此而已。
当然如果去封装各种东西也是可以的,直接在里面加就行了。
在Page目录下,新建basePage.py,开始撸代码:
from selenium.webdriver.common.by import By
from selenium import webdriver
import os
import importlib
import logging
SimpleActions = ['clear()', 'send_keys()', 'click()', 'submit()', 'size', 'text', 'is_displayed()', 'get_attribute()']
logger = logging.getLogger('main.page')
class Page(object):
def __init__(self, driver, page):
self.driver = driver
self.page = page
self.elements = get_page_elements(page)
self.by = ()
self.action = None
def _get_page_elem(self, elem):
# 获取定位元素的 by,以及操作action
for each in self.elements:
if each['name'] == elem:
self.by = each['by']
if 'action' in each and each['action'] is not None:
self.action = each['action']
else:
self.action = None
def oper_elem(self, elem, args=None):
self._get_page_elem(elem)
cmd = self._selenium_cmd('find_element', args)
return eval(cmd)
def oper_elems(self, elem, args=None):
self._get_page_elem(elem)
cmd = self._selenium_cmd('find_elements', args)
return eval(cmd)
def _selenium_cmd(self, find_type='find_element', args=None):
# 拼接 selenium 查找命令, 查找单个元素时find_type为'find_element',多个元素时为'find_elements'
cmd = 'self.driver.' + find_type + '(*self.by)'
if self.action:
if self.action in SimpleActions:
cmd = cmd + '.' + self.action
if args:
cmd = cmd[:-1] + 'args' + ')'
return cmd
def get_page_elements(page):
"""动态加载页面定义文件,获取文件中定义的元素列表elements"""
elements = None
if page:
try:
m = importlib.import_module(page)
elements = m.elements
except Exception as e:
logger.error('error info : %s' %(e))
return elements
这里面主要的只包含3个方法,一个是动态加载指定的PO对象获取元素列表,一个是在获取的元素列表中去找到当前要操作的元素,最后一个就是拼接原生的selenium命令,将测试数据插入到动作里面去。
其它的就简单了,直接调用selenium运行拼接出来的命令,把结果返回出去。
这里要注意的是,有些复杂的selenium操作,不能这么简单的拼命令,要特殊处理,这里暂时没弄;简单的命令,也没有列全。后面再慢慢加。
3. 写业务测试用例
下面开始写测试用例。
在Testcase目录下,新建一个python package:Model1。在Model1下面再建一个目录:Testdata,用于放测试数据;建一个python package:Case,用于放用例脚本。目录结构如下: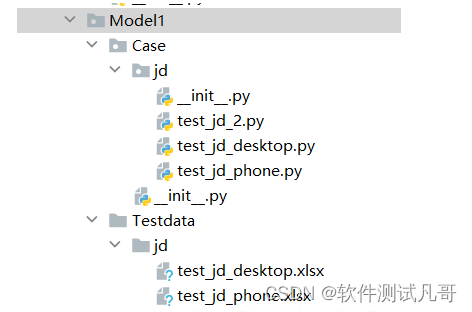
准备测试数据:
准备一份excel数据(test_jd_desktop.xlsx),存放在Model1/Testdata/jd下: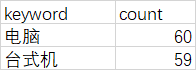
keyword:搜索的关键字
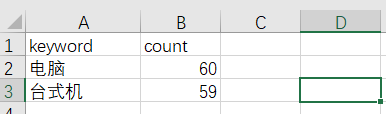
count:搜索结果总数,只抓了一页,应该是60个
实现业务用例:
在Model1/Case/jd下新建一个文件:test_jd_desktop.py,开始写用例脚本。
用例使用unittest结合DDT来实现,具体代码如下:
import os
import unittest
import ddt
import logging
from selenium import webdriver
from time import sleep
from Page.basePage import Page
from Comm.Log import screen
from Comm.data import read_excel
from main import TestCasePath
logger = logging.getLogger('main.jd')
# 读取测试数据
file = os.path.join(TestCasePath, 'Model1/Testdata/jd/test_jd_desktop.xlsx')
test_data = read_excel(file)
PO_jd = 'Page.jd.jd'
PO_search = 'Page.jd.search_jd'
@ddt.ddt # 数据驱动
class TestJdSearchDesktop(unittest.TestCase):
"""京东搜索测试"""
def setUp(self):
self.driver = webdriver.Chrome()
self.count = 0
self.result = []
@ddt.data(*test_data) # 数据驱动传具体数据
def testJdSearchDesktop(self, test_data):
"""京东搜索测试--电脑"""
url = 'https://www.jd.com'
keyword = test_data['keyword']
wait = self.driver.implicitly_wait(5)
try:
self.driver.get(url)
# 实例化jd主页面
jd = Page(self.driver, PO_jd)
# 实例化jd搜索结果页面
jd_search = Page(self.driver, PO_search)
wait
# jd主页面的搜索框元素中输入关键字
jd.oper_elem('search_ipt', keyword)
wait
# 操作jd主页面的搜索按钮元素
jd.oper_elem('search_btn')
sleep(1)
self.driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
sleep(1)
# jd搜索结果页面,获取结果列表
lis = jd_search.oper_elems('result_list')
# 在取到的结果列表中,循环获取商品价格和商品名称,结果存EXCEL就没写了
for each in lis:
self.count += 1
page_each = Page(each, PO_search)
price = page_each.oper_elem('price')
name = page_each.oper_elem('pname')
self.result.append([name, price])
sleep(1)
except Exception as E:
logger.error('error info : %s' % (E))
screen(test_data['keyword'])
# 判断是不是取到了60个商品
self.assertEqual(test_data['count'], self.count)
def tearDown(self):
self.driver.quit()
五、实现主程序
主程序的主要作用是 组织用例,执行用例,生成报告,发送测试报告邮件。
组织用例和执行用例都直接用unittest;
生成报告,采用BeautifulReport;
下面开始撸main.py的代码:
import unittest
import os
import time
import logging
from Comm.Email import Email
from Comm.Log import log_init
from BeautifulReport import BeautifulReport
# 定义各目录
ProjectHome = os.path.split(os.path.realpath(__file__))[0]
PageObjectPath = os.path.join(ProjectHome, "Page")
TestCasePath = os.path.join(ProjectHome, "Testcase")
ReportPath = os.path.join(ProjectHome, "Report")
#对测试结果关键信息进行汇总,做为邮件正文
def summary_format(result):
summary = "\n" + u"<p> 测试结果汇总信息 </p>" + "\n" + \
u"<p> 开始时间: " + result['beginTime'] + u" </p>" + "\n" + \
u"<p> 运行时间: " + result['totalTime'] + u" </p>" + "\n" + \
u"<p> 执行用例数: " + str(result['testAll']) + u" </p>" + "\n" + \
u"<p> 通过用例数: " + str(result['testPass']) + u" </p>" + "\n" + \
u"<p> 失败用例数: " + str(result['testFail']) + u" </p>" + "\n" + \
u"<p> 忽略用例数: " + str(result['testSkip']) + u" </p>" + "\n"
return summary
# 发送邮件
def send_email(file, context):
title = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) + '自动化测试结果'
mail = Email(title, context, file)
send = mail.send_mail()
if send:
print('测试报告邮件发送成功')
else:
print('测试报告邮件发送失败')
# 加载测试用例
def get_suite(case_path=TestCasePath, rule="test_*.py"):
"""加载所有的测试用例"""
unittest_suite = unittest.TestSuite()
discover = unittest.defaultTestLoader.discover(case_path, pattern=rule, top_level_dir=None)
for each in discover:
unittest_suite.addTests(each)
return unittest_suite
# 执行用例,生成测试报告,并返回报告附件路径、邮件正文内容
def suite_run(unittest_suite):
"""执行所有的用例, 并把结果写入测试报告"""
run_result = BeautifulReport(unittest_suite)
now = time.strftime("%Y%m%d%H%M%S", time.localtime())
filename = now + '_report.html'
run_result.report(filename=filename, description=now, report_dir=ReportPath)
rpt_summary = summary_format(run_result.fields)
return os.path.join(ReportPath, filename), rpt_summary
# 主程序,加载用例,执行用例,发送邮件
if __name__ == "__main__":
suite = get_suite()
report_file, report_summary = suite_run(suite)
print(report_summary)
send_email(report_file, report_summary)
API自动化,采用 request库来完成。还是通过PO对象、测试数据、业务逻辑三者分离的方式来实现。
这里以百度通用翻译接口为例,这个接口对个人用户是免费的,大家可以自己去申请。
1. API对象配置
在APIs下面新建python package:fanyi,再在fanyi下面建baidu.py。
将百度通用翻译接口定义在这里面,直接采用大家熟悉的json格式:
"""百度通用翻译接口"""
API_NAME = 'fanyi'
# 地址信息
uri_scheme = 'http'
endpoint = 'api.fanyi.baidu.com'
resource_path = '/api/trans/vip/translate'
url = uri_scheme + u'://' + endpoint + resource_path
# 保持不变的参数
_from = 'en'
_to = 'zh'
# 请求消息参数
req_param = {
"q": "", # 请求翻译 query, UTF-8
"from": _from, # 翻译源语言
"to": _to, # 翻译目标语言
"appid": "", # APP ID
"salt": "", # 随机数
"sign": "", # 签名,appid+q+salt+密钥 的MD5值
}
# 响应消息参数
res_param = {
"from": _from,
"to": _to,
"trans_result": [
{
"src": "Hello World! This is 1st paragraph.",
"dst": "你好,世界!这是第一段。"
},
{
"src": "This is 2nd paragraph.",
"dst": "这是第二段。"
}
]
}
2.实现base_api基类
base_api基类,主要是将数据、API对象、测试用例三者连起来;
在APIs目录下,新建base_api.py,代码如下:
import logging
import random
import importlib
import copy
import json
import unittest
from hashlib import md5
from ipaddress import ip_address
from Comm.compare import json_compare
logger = logging.getLogger('main.api')
req_prefix = 'req.'
res_prefix = 'res.'
def _separate_data(data, prefix='req.'):
pfx = prefix
result = {}
for key, value in data.items():
if key.startswith(pfx):
req_key = key[len(pfx):]
result[req_key] = value
return result
def _get_cmd(key, dict_name='payload'):
separator = '.'
cmd = dict_name
if separator in key:
data_key = key.split(separator)
for each in data_key:
if each.isdigit():
cmd = cmd + '[' + each + ']'
else:
cmd = cmd + '[\'' + each + '\']'
cmd = cmd + ' = value'
else:
cmd = cmd + '[key] = value'
return cmd
def check_result(unittest_testcase, x, y):
# 只有x,y完全相同才能通过,任意不同则返回失败。建议自己在用例中做结果检查
testcase = unittest_testcase
diff = json_compare(x, y)
testcase.assertEqual(x, y)
class BaseAPI(object):
def __init__(self, api):
self.api = api
self.api_name = None
self.url = ''
self.req_template = {}
self.res_template = {}
self._get_api_param()
def _get_api_param(self):
"""动态加载API定义文件,获取文件中定义的API参数"""
try:
m = importlib.import_module(self.api)
self.api_name = m.API_NAME
self.url = m.url
self.req_template = m.req_param
self.res_template = m.res_param
except Exception as e:
logger.error('error info : %s' % e)
def payload(self, data=None):
payload = copy.deepcopy(self.req_template)
if data:
req_pre = '.'.join([self.api_name, req_prefix])
req_data = _separate_data(data, req_pre)
for key, value in req_data.items():
cmd = _get_cmd(key, 'payload')
exec(cmd)
return payload
def load_expected(self, data=None):
expected = copy.deepcopy(self.res_template)
if data:
res_pre = '.'.join([self.api_name, res_prefix])
res_data = _separate_data(data, res_pre)
for key, value in res_data.items():
cmd = _get_cmd(key, 'expected')
exec(cmd)
return expected
这里面的思路是:
- 动态加载API对象,获取API请求参数模板、和响应参数模板;
- payload的时候,从测试数据中,取出API请求相关的数据(以API名.req开头,如fanyi.req.q),填入模板,没有的就用模板数据;
- 加载预期结果的时候,从测试数据中,取出API响应相关的数据(以API名.res开头,如fanyi.res.trans_result.0.src),填入模板,没有的就用模板数据。
- 提供json比较的方法;
- 提供了一个随机handers。
具体的大家看一下就明白了。想进一步封装的还可以继续封装,比如生成hearders,数据配完了直接发送,取到结果直接比对什么的。但是建议不要过度封装。
附json比较的方法:
import json_tools
def json_compare(x, y):
diff = json_tools.diff(x, y)
if diff:
for action in diff:
if 'add' in action:
print('++增加元素:', action['add'], ' 值:', action['value'])
elif 'remove' in action:
print('--删除元素:', action['remove'], ' 值:', action['prev'])
elif 'replace' in action:
print('**修改元素:', action['replace'], ' 值:', action['prev'], '-->', action['value'])
return diff
3.测试用例
在Testcase下建API模块,API模块下建Case和Testdata,分别放用例和数据,目录如下: 
定义测试数据:
测试数据需要按一定的格式处理,即每个参数以api名称开头,用“.”连接,然后用res和req来区分响应还是请求,后面就是具体的参数了,多级参数以“.”连接。具体如下:
测试用例脚本:
仍然用unittest和ddt来实现。
import os
import unittest
import ddt
import random
import json
import requests
from time import sleep
from Comm.data import read_excel
from Comm.encryption import make_md5
from main import TestCasePath
from APIs.base_api import BaseAPI, check_result
# 开通普通个人的百度翻译接口,设置appid和appkey.
app_id = your appid
app_key = your appkey
# 获取测试数据
file = os.path.join(TestCasePath, 'API/TestData/baidu_fanyi.xlsx')
test_data = read_excel(file)
api = 'APIs.fanyi.baidu'
@ddt.ddt
class TestBaiduFanyi(unittest.TestCase):
"""百度翻译接口测试"""
def setUp(self):
self.api = BaseAPI(api)
@ddt.data(*test_data)
def test_baidu_fanyi(self, test_data):
"""百度翻译接口测试"""
api = self.api
# Build test_data,这是些动态参数,在这里计算
test_data['fanyi.req.appid'] = app_id
salt = random.randint(32768, 65536)
test_data['fanyi.req.salt'] = salt
sign = make_md5(app_id + test_data['fanyi.req.q'] + str(salt) + app_key)
test_data['fanyi.req.sign'] = sign
# Build request
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
payload = api.payload(test_data )
# Send request
r = requests.post(api.url, params=payload, headers=headers)
result = r.json()
expected = api.load_expected(test_data)
self.assertEqual(r.status_code, 200)
check_result(self, expected, result) # 简单的模板验证,大家最好自己写验证。
sleep(0.5)
然后运行主程序,API自动化测试也就可以跑起来了。
补:MD5函数
from hashlib import md5
def make_md5(s, encoding='utf-8'):
return md5(s.encode(encoding)).hexdigest()
结语
这篇贴子到这里就结束了,最后,希望看这篇帖子的朋友能够有所收获。
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!