数据库
什么是数据库, 数据库管理系统, 数据库系统, 数据库管理员?
- 数据库 : 数据库(DataBase 简称 DB)就是信息的集合或者说数据库是由数据库管理系统管理的数据的集合。
- 数据库管理系统 : 数据库管理系统(Database Management System 简称 DBMS)是一种操纵和管理数据库的大型软件,通常用于建立、使用和维护数据库。
- 数据库系统 : 数据库系统(Data Base System,简称 DBS)通常由软件、数据库和数据管理员(DBA)组成。
- 数据库管理员 : 数据库管理员(Database Administrator, 简称 DBA)负责全面管理和控制数据库系统。
什么是元组, 码, 候选码, 主码, 外码, 主属性, 非主属性?
- 元组:元组(tuple)是关系数据库中的基本概念,关系是一张表,表中的每行(即数据库中的每条记录)就是一个元组,每列就是一个属性。 在二维表里,元组也称为行。
- 码:码就是能唯一标识实体的属性,对应表中的列。
- 候选码:若关系中的某一属性或属性组的值能唯一的标识一个元组,而其任何、子集都不能再标识,则称该属性组为候选码。例如:在学生实体中,“学号”是能唯一的区分学生实体的,同时又假设“姓名”、“班级”的属性组合足以区分学生实体,那么{学号}和{姓名,班级}都是候选码。
- 主码 : 主码也叫主键。主码是从候选码中选出来的。 一个实体集中只能有一个主码,但可以有多个候选码。
- 外码 : 外码也叫外键。如果一个关系中的一个属性是另外一个关系中的主码则这个属性为外码。
- 主属性:候选码中出现过的属性称为主属性。比如关系 工人(工号,身份证号,姓名,性别,部门). 显然工号和身份证号都能够唯一标示这个关系,所以都是候选码。工号、身份证号这两个属性就是主属性。如果主码是一个属性组,那么属性组中的属性都是主属性。
- 非主属性: 不包含在任何一个候选码中的属性称为非主属性。比如在关系——学生(学号,姓名,年龄,性别,班级)中,主码是“学号”,那么其他的“姓名”、“年龄”、“性别”、“班级”就都可以称为非主属性。
什么是 ER 图?
我们做一个项目的时候一定要试着画 ER 图来捋清数据库设计,这个也是面试官问你项目的时候经常会被问到的。
ER 图 全称是 Entity Relationship Diagram(实体联系图),提供了表示实体类型、属性和联系的方法。
ER 图由下面 3 个要素组成:
- 实体:通常是现实世界的业务对象,当然使用一些逻辑对象也可以。比如对于一个校园管理系统,会涉及学生、教师、课程、班级等等实体。在 ER 图中,实体使用矩形框表示。
- 属性:即某个实体拥有的属性,属性用来描述组成实体的要素,对于产品设计来说可以理解为字段。在 ER 图中,属性使用椭圆形表示。
- 联系:即实体与实体之间的关系,在 ER 图中用菱形表示,这个关系不仅有业务关联关系,还能通过数字表示实体之间的数量对照关系。例如,一个班级会有多个学生就是一种实体间的联系。
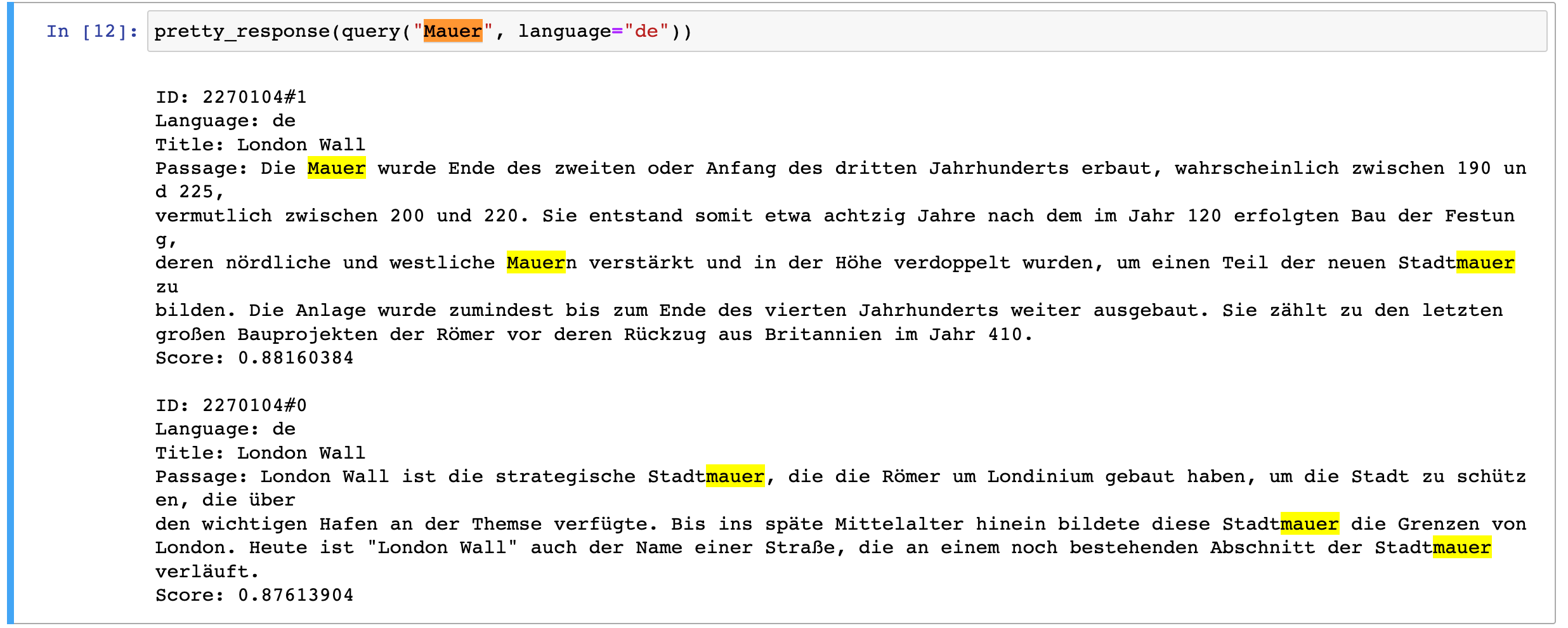
下图是一个学生选课的 ER 图,每个学生可以选若干门课程,同一门课程也可以被若干人选择,所以它们之间的关系是多对多(M: N)。另外,还有其他两种实体之间的关系是:1 对 1(1:1)、1 对多(1: N)。
数据库范式了解吗?
数据库范式有 3 种:
- 1NF(第一范式):属性不可再分。
- 2NF(第二范式):1NF 的基础之上,消除了非主属性对于码的部分函数依赖。
- 3NF(第三范式):3NF 在 2NF 的基础之上,消除了非主属性对于码的传递函数依赖 。
- BCNF:在第三范式的基础上,消除主属性对主键的部分和传递依赖。
- 4NF: 在BCNF的基础上消除表的多值依赖,解决冗余
1NF(第一范式)
属性(对应于表中的字段)不能再被分割,也就是这个字段只能是一个值,不能再分为多个其他的字段了。1NF 是所有关系型数据库的最基本要求 ,也就是说关系型数据库中创建的表一定满足第一范式。
2NF(第二范式)
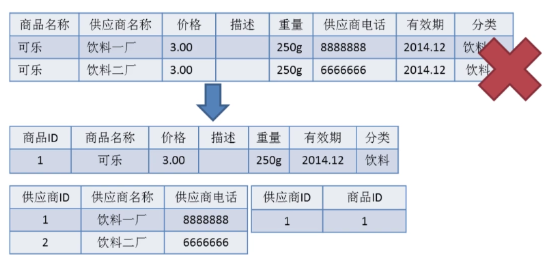
2NF 在 1NF 的基础之上,消除了非主属性对于码的部分函数依赖。如下图所示,展示了第一范式到第二范式的过渡。第二范式在第一范式的基础上增加了一个列,这个列称为主键,非主属性都依赖于主键。
一些重要的概念:
- 函数依赖(functional dependency):若在一张表中,在属性(或属性组)X 的值确定的情况下,必定能确定属性 Y 的值,那么就可以说 Y 函数依赖于 X,写作 X → Y。
- 部分函数依赖(partial functional dependency):如果 X→Y,并且存在 X 的一个真子集 X0,使得 X0→Y,则称 Y 对 X 部分函数依赖。比如学生基本信息表 R 中(学号,身份证号,姓名)当然学号属性取值是唯一的,在 R 关系中,(学号,身份证号)->(姓名),(学号)->(姓名),(身份证号)->(姓名);所以姓名部分函数依赖于(学号,身份证号);
- 完全函数依赖(Full functional dependency):在一个关系中,若某个非主属性数据项依赖于全部关键字称之为完全函数依赖。比如学生基本信息表 R(学号,班级,姓名)假设不同的班级学号有相同的,班级内学号不能相同,在 R 关系中,(学号,班级)->(姓名),但是(学号)->(姓名)不成立,(班级)->(姓名)不成立,所以姓名完全函数依赖与(学号,班级);
- 传递函数依赖:在关系模式 R(U)中,设 X,Y,Z 是 U 的不同的属性子集,如果 X 确定 Y、Y 确定 Z,且有 X 不包含 Y,Y 不确定 X,(X∪Y)∩Z=空集合,则称 Z 传递函数依赖(transitive functional dependency) 于 X。传递函数依赖会导致数据冗余和异常。传递函数依赖的 Y 和 Z 子集往往同属于某一个事物,因此可将其合并放到一个表中。比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖。
3NF(第三范式)
3NF 在 2NF 的基础之上,消除了非主属性对于码的传递函数依赖 。符合 3NF 要求的数据库设计,基本上解决了数据冗余过大,插入异常,修改异常,删除异常的问题。比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖,所以该表的设计,不符合 3NF 的要求。
主键和外键有什么区别?
- 主键(主码):主键用于唯一标识一个元组,不能有重复,不允许为空。一个表只能有一个主键。
- 外键(外码):外键用来和其他表建立联系用,外键是另一表的主键,外键是可以有重复的,可以是空值。一个表可以有多个外键。
为什么不推荐使用外键与级联?
【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
说明: 以学生和成绩的关系为例,学生表中的 student_id 是主键,那么成绩表中的 student_id 则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新,即为级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风险;外键影响数据库的插入速度。
什么是存储过程?
我们可以把存储过程看成是一些 SQL 语句的集合,中间加了点逻辑控制语句。存储过程在业务比较复杂的时候是非常实用的,比如很多时候我们完成一个操作可能需要写一大串 SQL 语句,这时候我们就可以写有一个存储过程,这样也方便了我们下一次的调用。存储过程一旦调试完成通过后就能稳定运行,另外,使用存储过程比单纯 SQL 语句执行要快,因为存储过程是预编译过的。
存储过程在互联网公司应用不多,因为存储过程难以调试和扩展,而且没有移植性,还会消耗数据库资源。
drop、delete 与 truncate 区别?
用法不同
drop(丢弃数据):drop table 表名,直接将表都删除掉,在删除表的时候使用。truncate(清空数据) :truncate table 表名,只删除表中的数据,再插入数据的时候自增长 id 又从 1 开始,在清空表中数据的时候使用。delete(删除数据) :delete from 表名 where 列名=值,删除某一行的数据,如果不加where子句和truncate table 表名作用类似。
truncate 和不带 where子句的 delete、以及 drop 都会删除表内的数据,但是 truncate 和 delete 只删除数据不删除表的结构(定义),执行 drop 语句,此表的结构也会删除,也就是执行drop 之后对应的表不复存在。
属于不同的数据库语言
truncate 和 drop 属于 DDL(数据定义语言)语句,操作立即生效,原数据不放到 rollback segment 中,不能回滚,操作不触发 trigger。而 delete 语句是 DML (数据库操作语言)语句,这个操作会放到 rollback segment 中,事务提交之后才生效。
DML 语句和 DDL 语句区别:
- DML 是数据库操作语言(Data Manipulation Language)的缩写,是指对数据库中表记录的操作,主要包括表记录的插入、更新、删除和查询,是开发人员日常使用最频繁的操作。
- DDL (Data Definition Language)是数据定义语言的缩写,简单来说,就是对数据库内部的对象进行创建、删除、修改的操作语言。它和 DML 语言的最大区别是 DML 只是对表内部数据的操作,而不涉及到表的定义、结构的修改,更不会涉及到其他对象。DDL 语句更多的被数据库管理员(DBA)所使用,一般的开发人员很少使用。
另外,由于select不会对表进行破坏,所以有的地方也会把select单独区分开叫做数据库查询语言 DQL(Data Query Language)。
执行速度不同
一般来说:drop > truncate > delete(这个我没有实际测试过)。
delete命令执行的时候会产生数据库的binlog日志,而日志记录是需要消耗时间的,但是也有个好处方便数据回滚恢复。truncate命令执行的时候不会产生数据库日志,因此比delete要快。除此之外,还会把表的自增值重置和索引恢复到初始大小等。drop命令会把表占用的空间全部释放掉。
数据库设计通常分为哪几步?
- 需求分析 : 分析用户的需求,包括数据、功能和性能需求。
- 概念结构设计 : 主要采用 E-R 模型进行设计,包括画 E-R 图。
- 逻辑结构设计 : 通过将 E-R 图转换成表,实现从 E-R 模型到关系模型的转换。
- 物理结构设计 : 主要是为所设计的数据库选择合适的存储结构和存取路径。
- 数据库实施 : 包括编程、测试和试运行
- 数据库的运行和维护 : 系统的运行与数据库的日常维护。
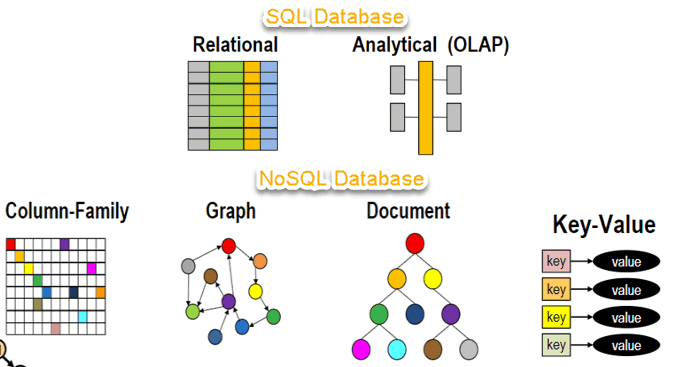
NoSQL 是什么?
NoSQL(Not Only SQL 的缩写)泛指非关系型的数据库,主要针对的是键值、文档以及图形类型数据存储。并且,NoSQL 数据库天生支持分布式,数据冗余和数据分片等特性,旨在提供可扩展的高可用高性能数据存储解决方案。
一个常见的误解是 NoSQL 数据库或非关系型数据库不能很好地存储关系型数据。NoSQL 数据库可以存储关系型数据—它们与关系型数据库的存储方式不同。
NoSQL 数据库代表:HBase、Cassandra、MongoDB、Redis。
SQL 和 NoSQL 有什么区别?
| SQL 数据库 | NoSQL 数据库 | |
|---|---|---|
| 数据存储模型 | 结构化存储,具有固定行和列的表格 | 非结构化存储。文档:JSON 文档,键值:键值对,宽列:包含行和动态列的表,图:节点和边 |
| 发展历程 | 开发于 1970 年代,重点是减少数据重复 | 开发于 2000 年代后期,重点是提升可扩展性,减少大规模数据的存储成本 |
| 例子 | Oracle、MySQL、Microsoft SQL Server、PostgreSQL | 文档:MongoDB、CouchDB,键值:Redis、DynamoDB,宽列:Cassandra、 HBase,图表:Neo4j、 Amazon Neptune、Giraph |
| ACID 属性 | 提供原子性、一致性、隔离性和持久性 (ACID) 属性 | 通常不支持 ACID 事务,为了可扩展、高性能进行了权衡,少部分支持比如 MongoDB 。不过,MongoDB 对 ACID 事务 的支持和 MySQL 还是有所区别的。 |
| 性能 | 性能通常取决于磁盘子系统。要获得最佳性能,通常需要优化查询、索引和表结构。 | 性能通常由底层硬件集群大小、网络延迟以及调用应用程序来决定。 |
| 扩展 | 垂直(使用性能更强大的服务器进行扩展)、读写分离、分库分表 | 横向(增加服务器的方式横向扩展,通常是基于分片机制) |
| 用途 | 普通企业级的项目的数据存储 | 用途广泛比如图数据库支持分析和遍历连接数据之间的关系、键值数据库可以处理大量数据扩展和极高的状态变化 |
| 查询语法 | 结构化查询语言 (SQL) | 数据访问语法可能因数据库而异 |
NoSQL 数据库有什么优势?
NoSQL 数据库非常适合许多现代应用程序,例如移动、Web 和游戏等应用程序,它们需要灵活、可扩展、高性能和功能强大的数据库以提供卓越的用户体验。
- 灵活性: NoSQL 数据库通常提供灵活的架构,以实现更快速、更多的迭代开发。灵活的数据模型使 NoSQL 数据库成为半结构化和非结构化数据的理想之选。
- 可扩展性: NoSQL 数据库通常被设计为通过使用分布式硬件集群来横向扩展,而不是通过添加昂贵和强大的服务器来纵向扩展。
- 高性能: NoSQL 数据库针对特定的数据模型和访问模式进行了优化,这与尝试使用关系数据库完成类似功能相比可实现更高的性能。
- 强大的功能: NoSQL 数据库提供功能强大的 API 和数据类型,专门针对其各自的数据模型而构建。
NoSQL 数据库有哪些类型?
NoSQL 数据库主要可以分为下面四种类型:
- 键值:键值数据库是一种较简单的数据库,其中每个项目都包含键和值。这是极为灵活的 NoSQL 数据库类型,因为应用可以完全控制 value 字段中存储的内容,没有任何限制。Redis 和 DynanoDB 是两款非常流行的键值数据库。
- 文档:文档数据库中的数据被存储在类似于 JSON(JavaScript 对象表示法)对象的文档中,非常清晰直观。每个文档包含成对的字段和值。这些值通常可以是各种类型,包括字符串、数字、布尔值、数组或对象等,并且它们的结构通常与开发者在代码中使用的对象保持一致。MongoDB 就是一款非常流行的文档数据库。
- 图形:图形数据库旨在轻松构建和运行与高度连接的数据集一起使用的应用程序。图形数据库的典型使用案例包括社交网络、推荐引擎、欺诈检测和知识图形。Neo4j 和 Giraph 是两款非常流行的图形数据库。
- 宽列:宽列存储数据库非常适合需要存储大量的数据。Cassandra 和 HBase 是两款非常流行的宽列存储数据库。
何为字符集?
字符是各种文字和符号的统称,包括各个国家文字、标点符号、表情、数字等等。 字符集 就是一系列字符的集合。字符集的种类较多,每个字符集可以表示的字符范围通常不同,就比如说有些字符集是无法表示汉字的。
计算机只能存储二进制的数据,那英文、汉字、表情等字符应该如何存储呢?
我们要将这些字符和二进制的数据一一对应起来,比如说字符“a”对应“01100001”,反之,“01100001”对应 “a”。我们将字符对应二进制数据的过程称为"字符编码",反之,二进制数据解析成字符的过程称为“字符解码”。
有哪些常见的字符集?
常见的字符集有 ASCII、GB2312、GBK、UTF-8…。
不同的字符集的主要区别在于:
- 可以表示的字符范围
- 编码方式
ASCII
ASCII (American Standard Code for Information Interchange,美国信息交换标准代码) 是一套主要用于现代美国英语的字符集(这也是 ASCII 字符集的局限性所在)。
为什么 ASCII 字符集没有考虑到中文等其他字符呢? 因为计算机是美国人发明的,当时,计算机的发展还处于比较雏形的时代,还未在其他国家大规模使用。因此,美国发布 ASCII 字符集的时候没有考虑兼容其他国家的语言。
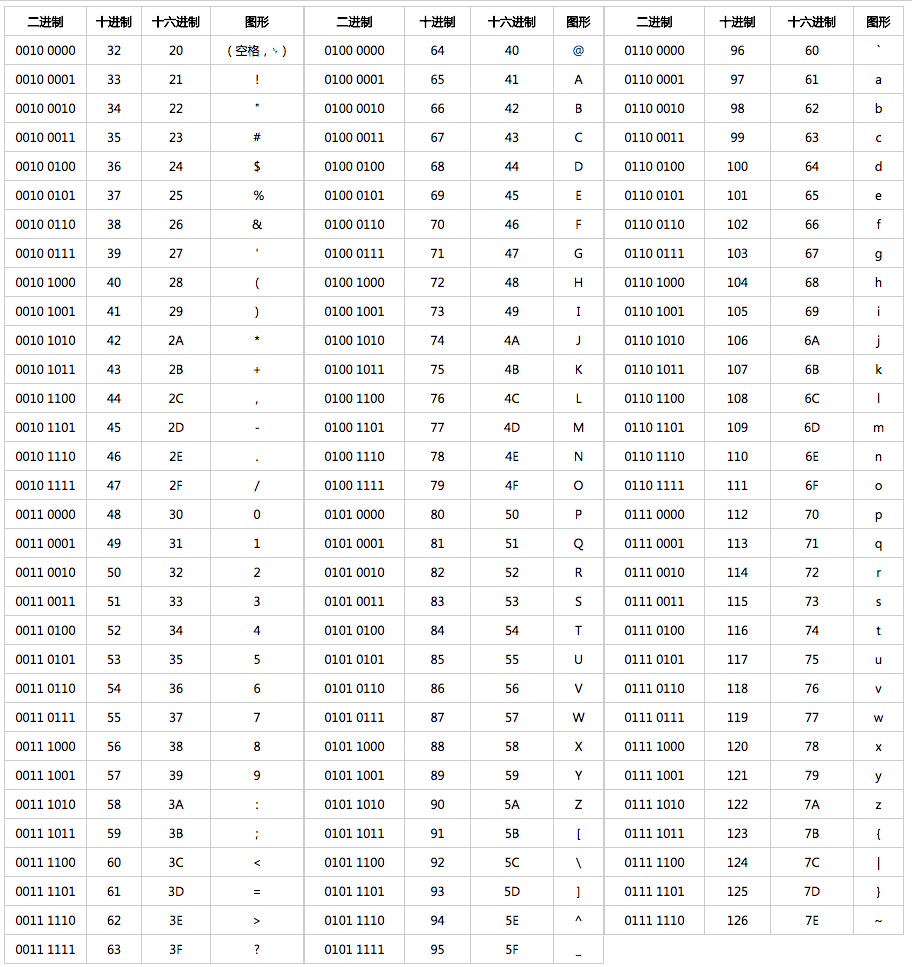
ASCII 字符集至今为止共定义了 128 个字符,其中有 33 个控制字符(比如回车、删除)无法显示。
一个 ASCII 码长度是一个字节也就是 8 个 bit,比如“a”对应的 ASCII 码是“01100001”。不过,最高位是 0 仅仅作为校验位,其余 7 位使用 0 和 1 进行组合,所以,ASCII 字符集可以定义 128(2^7)个字符。
由于,ASCII 码可以表示的字符实在是太少了。后来,人们对其进行了扩展得到了 ASCII 扩展字符集 。ASCII 扩展字符集使用 8 位(bits)表示一个字符,所以,ASCII 扩展字符集可以定义 256(2^8)个字符。
GB2312
我们上面说了,ASCII 字符集是一种现代美国英语适用的字符集。因此,很多国家都捣鼓了一个适合自己国家语言的字符集。
GB2312 字符集是一种对汉字比较友好的字符集,共收录 6700 多个汉字,基本涵盖了绝大部分常用汉字。不过,GB2312 字符集不支持绝大部分的生僻字和繁体字。
对于英语字符,GB2312 编码和 ASCII 码是相同的,1 字节编码即可。对于非英字符,需要 2 字节编码。
GBK
GBK 字符集可以看作是 GB2312 字符集的扩展,兼容 GB2312 字符集,共收录了 20000 多个汉字。
GBK 中 K 是汉语拼音 Kuo Zhan(扩展)中的“Kuo”的首字母。
GB18030
GB18030 完全兼容 GB2312 和 GBK 字符集,纳入中国国内少数民族的文字,且收录了日韩汉字,是目前为止最全面的汉字字符集,共收录汉字 70000 多个。
BIG5
BIG5 主要针对的是繁体中文,收录了 13000 多个汉字。
Unicode & UTF-8 编码
为了更加适合本国语言,诞生了很多种字符集。
我们上面也说了不同的字符集可以表示的字符范围以及编码规则存在差异。这就导致了一个非常严重的问题:使用错误的编码方式查看一个包含字符的文件就会产生乱码现象。
这样我们就搞懂了乱码的本质:编码和解码时用了不同或者不兼容的字符集 。
为了解决这个问题,人们就想:“如果我们能够有一种字符集将世界上所有的字符都纳入其中就好了!”。
然后,Unicode 带着这个使命诞生了。
Unicode 字符集中包含了世界上几乎所有已知的字符。不过,Unicode 字符集并没有规定如何存储这些字符(也就是如何使用二进制数据表示这些字符)。
然后,就有了 UTF-8(8-bit Unicode Transformation Format)。类似的还有 UTF-16、 UTF-32。
UTF-8 使用 1 到 4 个字节为每个字符编码, UTF-16 使用 2 或 4 个字节为每个字符编码,UTF-32 固定位 4 个字节为每个字符编码。
UTF-8 可以根据不同的符号自动选择编码的长短,像英文字符只需要 1 个字节就够了,这一点 ASCII 字符集一样 。因此,对于英语字符,UTF-8 编码和 ASCII 码是相同的。
UTF-32 的规则最简单,不过缺陷也比较明显,对于英文字母这类字符消耗的空间是 UTF-8 的 4 倍之多。
UTF-8 是目前使用最广的一种字符编码。
MySQL 字符集
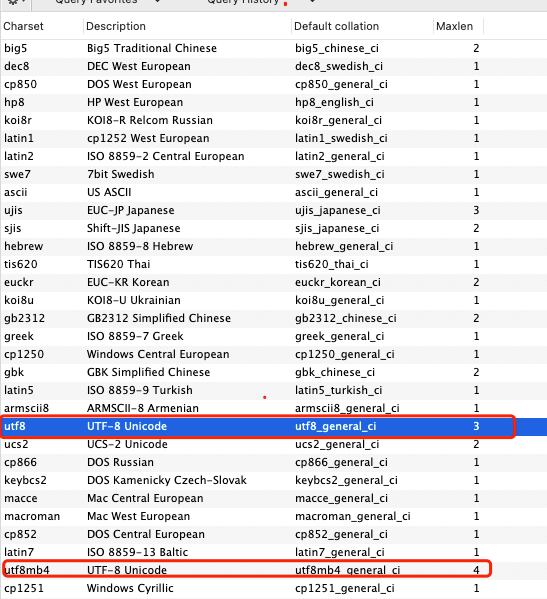
MySQL 支持很多种字符编码的方式,比如 UTF-8、GB2312、GBK、BIG5。
查看支持的字符集
你可以通过 SHOW CHARSET 命令来查看,支持 like 和 where 子句。
默认字符集
在 MySQL5.7 中,默认字符集是 latin1 ;在 MySQL8.0 中,默认字符集是 utf8mb4
字符集的层次级别
MySQL 中的字符集有以下的层次级别:
server(MySQL 实例级别)database(库级别)table(表级别)column(字段级别)
它们的优先级可以简单的认为是从上往下依次增大,也即 column 的优先级会大于 table 等其余层次的。如指定 MySQL 实例级别字符集是utf8mb4,指定某个表字符集是latin1,那么这个表的所有字段如果不指定的话,编码就是latin1。
server
不同版本的 MySQL 其 server 级别的字符集默认值不同,在 MySQL5.7 中,其默认值是 latin1 ;在 MySQL8.0 中,其默认值是 utf8mb4 。
当然也可以通过在启动 mysqld 时指定 --character-set-server 来设置 server 级别的字符集。
mysqld
mysqld --character-set-server=utf8mb4
mysqld --character-set-server=utf8mb4 \
--collation-server=utf8mb4_0900_ai_ci
server 级别的字符集是 MySQL 服务器的全局设置,它不仅会作为创建或修改数据库时的默认字符集(如果没有指定其他字符集),还会影响到客户端和服务器之间的连接字符集,具体可以查看 MySQL Connector/J 8.0 - 6.7 Using Character Sets and Unicodeopen in new window
database
database 级别的字符集是我们在创建数据库和修改数据库时指定的:
CREATE DATABASE db_name
[[DEFAULT] CHARACTER SET charset_name]
[[DEFAULT] COLLATE collation_name]
ALTER DATABASE db_name
[[DEFAULT] CHARACTER SET charset_name]
[[DEFAULT] COLLATE collation_name]
如前面所说,如果在执行上述语句时未指定字符集,那么 MySQL 将会使用 server 级别的字符集。
可以通过下面的方式查看某个数据库的字符集:
USE db_name;
SELECT @@character_set_database, @@collation_database;
SELECT DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME
FROM INFORMATION_SCHEMA.SCHEMATA WHERE SCHEMA_NAME = 'db_name';
table
table 级别的字符集是在创建表和修改表时指定的:
CREATE TABLE tbl_name (column_list)
[[DEFAULT] CHARACTER SET charset_name]
[COLLATE collation_name]]
ALTER TABLE tbl_name
[[DEFAULT] CHARACTER SET charset_name]
[COLLATE collation_name]
如果在创建表和修改表时未指定字符集,那么将会使用 database 级别的字符集。
column
column 级别的字符集同样是在创建表和修改表时指定的,只不过它是定义在列中。下面是个例子:
CREATE TABLE t1
(
col1 VARCHAR(5)
CHARACTER SET latin1
COLLATE latin1_german1_ci
);
如果未指定列级别的字符集,那么将会使用表级别的字符集。
连接字符集
前面说到了字符集的层次级别,它们是和存储相关的。而连接字符集涉及的是和 MySQL 服务器的通信。
连接字符集与下面这几个变量息息相关:
character_set_client:描述了客户端发送给服务器的 SQL 语句使用的是什么字符集。character_set_connection:描述了服务器接收到 SQL 语句时使用什么字符集进行翻译。character_set_results:描述了服务器返回给客户端的结果使用的是什么字符集。
它们的值可以通过下面的 SQL 语句查询:
SELECT * FROM performance_schema.session_variables
WHERE VARIABLE_NAME IN (
'character_set_client', 'character_set_connection',
'character_set_results', 'collation_connection'
) ORDER BY VARIABLE_NAME;
SHOW SESSION VARIABLES LIKE 'character\_set\_%';
如果要想修改前面提到的几个变量的值,有以下方式:
如果要想修改前面提到的几个变量的值,有以下方式:
1、修改配置文件
[mysql]
# 只针对MySQL客户端程序
default-character-set=utf8mb4
2、使用 SQL 语句
set names utf8mb4
# 或者一个个进行修改
# SET character_set_client = utf8mb4;
# SET character_set_results = utf8mb4;
# SET collation_connection = utf8mb4;
jdbc 对连接字符集的影响
不知道你们有没有碰到过存储 emoji 表情正常,但是使用类似 Navicat 之类的软件的进行查询的时候,发现 emoji 表情变成了问号的情况。这个问题很有可能就是 jdbc 驱动引起的。
根据前面的内容,我们知道连接字符集也是会影响我们存储的数据的,而 jdbc 驱动会影响连接字符集。
mysql-connector-java (jdbc 驱动)主要通过这几个属性影响连接字符集:
characterEncodingcharacterSetResults
TF-8 使用
通常情况下,我们建议使用 UTF-8 作为默认的字符编码方式。
不过,这里有一个小坑。
MySQL 字符编码集中有两套 UTF-8 编码实现:
utf8:utf8编码只支持1-3个字节 。 在utf8编码中,中文是占 3 个字节,其他数字、英文、符号占一个字节。但 emoji 符号占 4 个字节,一些较复杂的文字、繁体字也是 4 个字节。utf8mb4:UTF-8 的完整实现,正版!最多支持使用 4 个字节表示字符,因此,可以用来存储 emoji 符号。
为什么有两套 UTF-8 编码实现呢? 原因如下:

因此,如果你需要存储emoji类型的数据或者一些比较复杂的文字、繁体字到 MySQL 数据库的话,数据库的编码一定要指定为utf8mb4 而不是utf8 ,要不然存储的时候就会报错了。
作者声明
如有问题,欢迎指正!