文章目录
- 默认值
- 更新规则
- 保留字段
- 未知字段
默认值
在反序列化时,若被反序列化的二进制序列中不包含某个字段,则在反序列化时,就会设置对应默认值。不同的类型默认值不同:
| 类型 | 默认值 |
|---|---|
| 字符串 | “” |
| 布尔型 | false |
| 数值类型 | 0 |
| 枚举型 | 0 |
| 设置了repeated的字段 | 空列表 |
- ps:对于消息字段,oneof字段,any字段,有 has_ 方法来检测字段值是否被设置。
更新规则
- 禁止修改任何已有字段的字段编号。
- 若是移除老字段,要保证不能再使用老字段使用过的编号。(正确做法是将其设为保留字段reserved)
- oneof
1.将一个单独的值更改为新oneof类型成员之一是安全和二进制兼容的
2.将任何字段移入已存在的oneof类型是不安全的。
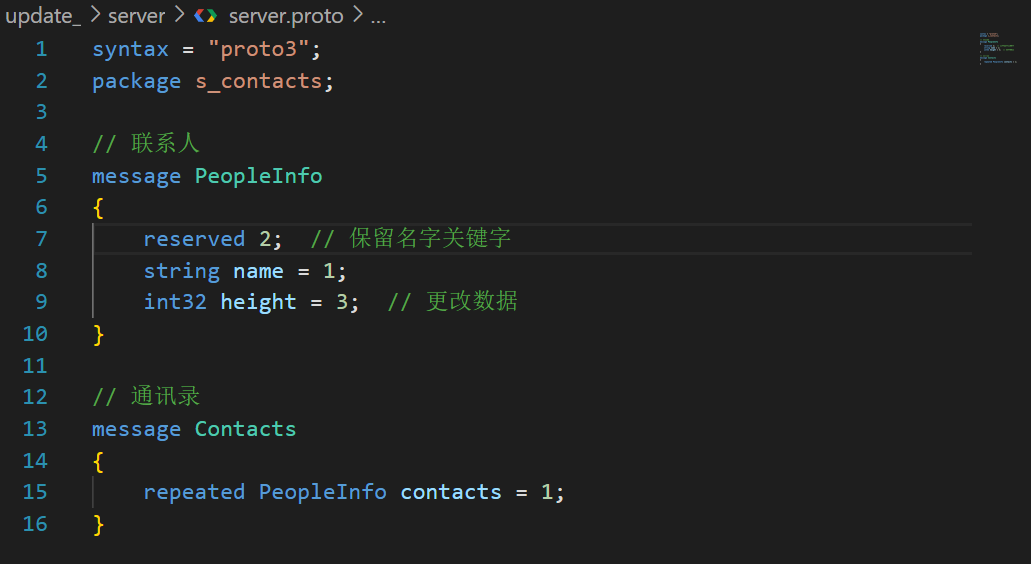
保留字段
message Reserved
{
reversed 100;
reversed 10 to 99;
reversed "hello", "field";
// 以上做法都可行
// 注意:不要在⼀⾏ reserved 声明中同时声明字段编号和名称。reserved 102, "field5"
// 设置保留项之后,下⾯代码会告警
int32 field1 = 100; //告警:Field 'field1' uses reserved number 100
int32 field2 = 11; //告警:Field 'field2' uses reserved number 101
int32 hello = 102; //告警:Field name 'hello' is reserved
int32 field = 103; //告警:Field name 'field' is reserved
}
这里给出更新例子:
有两个文件夹,client,server
server端写数据,client端读数据
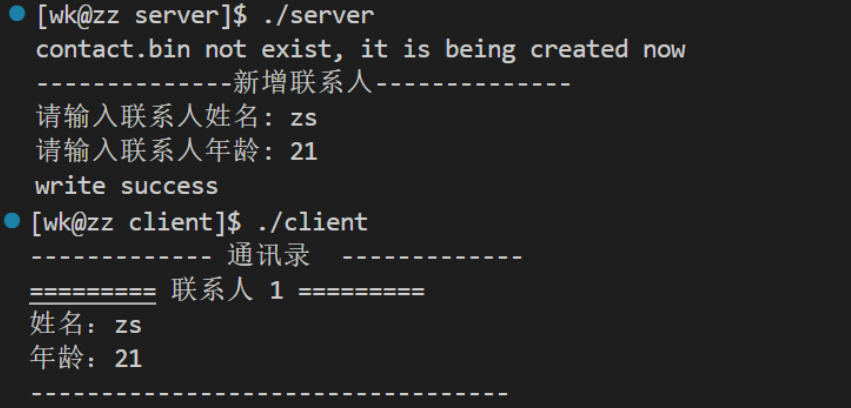
下面对.proto文件中的已存在字段进行修改
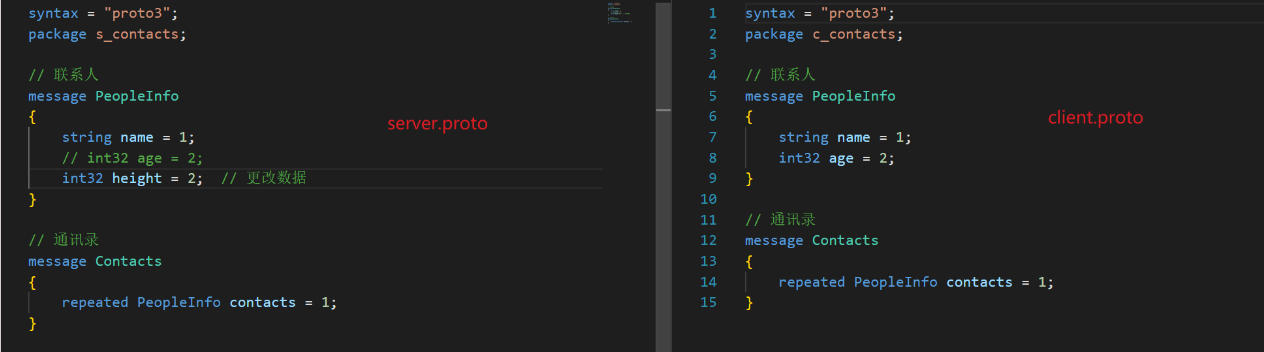
然后把serve.cc相应增加代码修改一下

之后再编译链接,添加数据
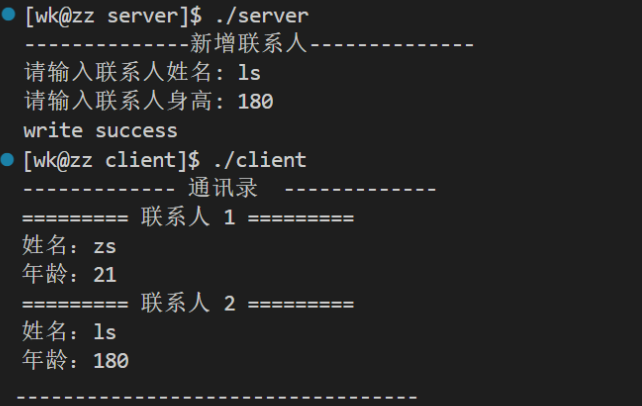
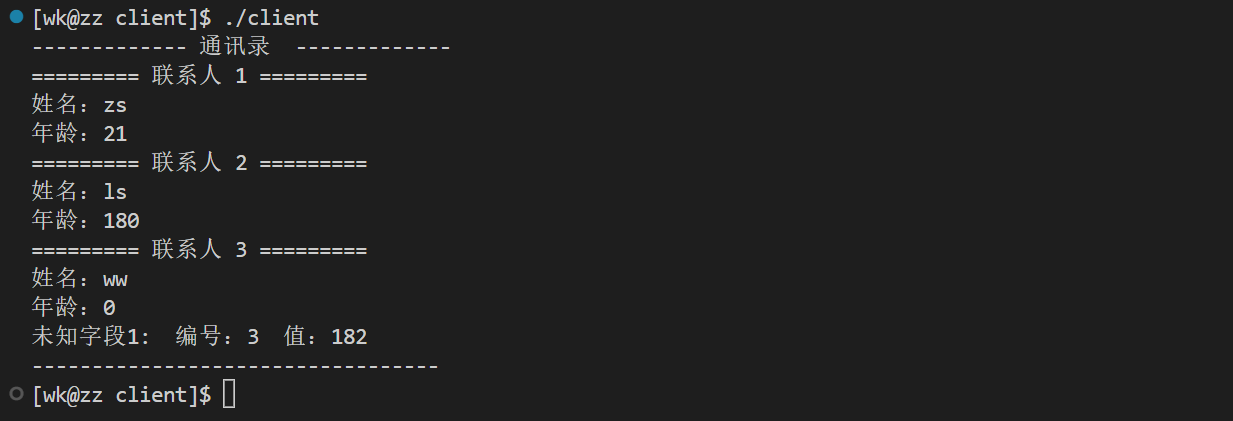
注意看,查询到的年龄数据是180,显然protobuf里的字段是根据编号来控制的。那么正确的做法是保留字段编号(reserved),以确保该编号将不能被重复使⽤
所以这就是为什么要引入reversed保留字的原因。
正确做法:
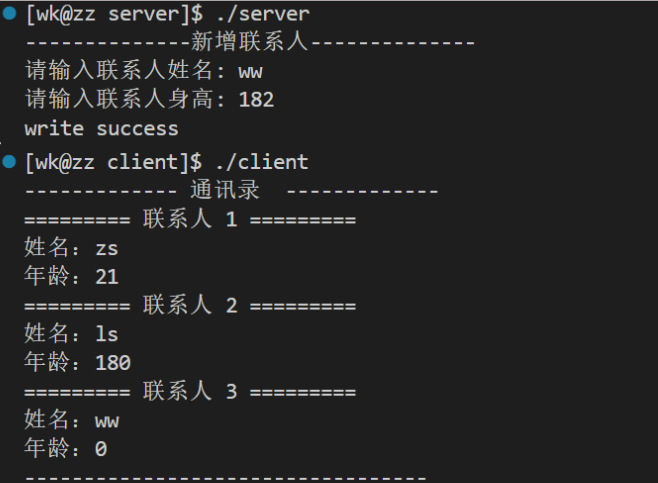
看到ww的年龄为0,这里就是本文开篇讲的类型默认值,那身高的数据跑哪里去了?
它在未知字段
未知字段
那么这里有个问题,什么是未知字段?
下面是类图
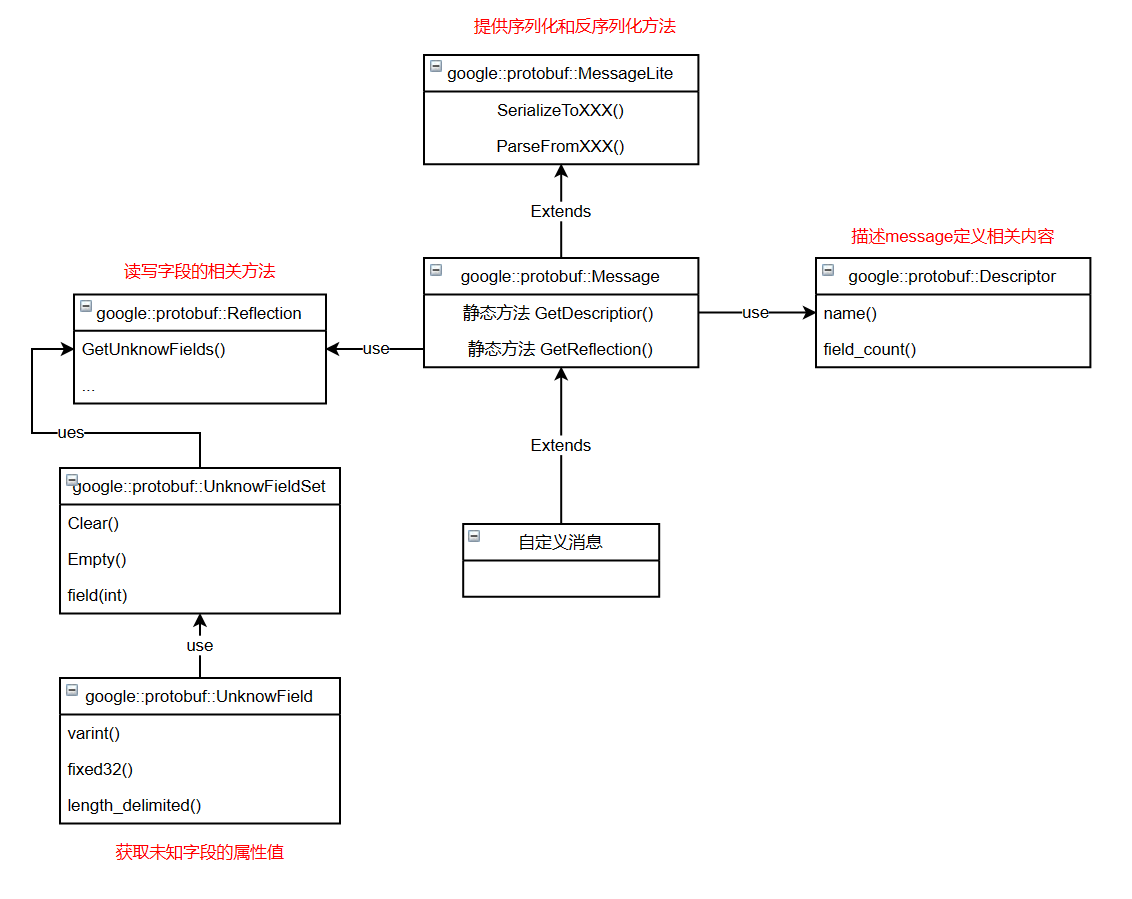
- 我们定义好的Message类People,调用People里的静态函数
GetReflection(),获得读写字段reflection - 调用reflection中
GetUnknownFields()函数,获得Message的People未知字段集合set - 遍历set,获得未知字段
unknow_field - 最后根据未知字段的类型调用对应函数来打印对应值。
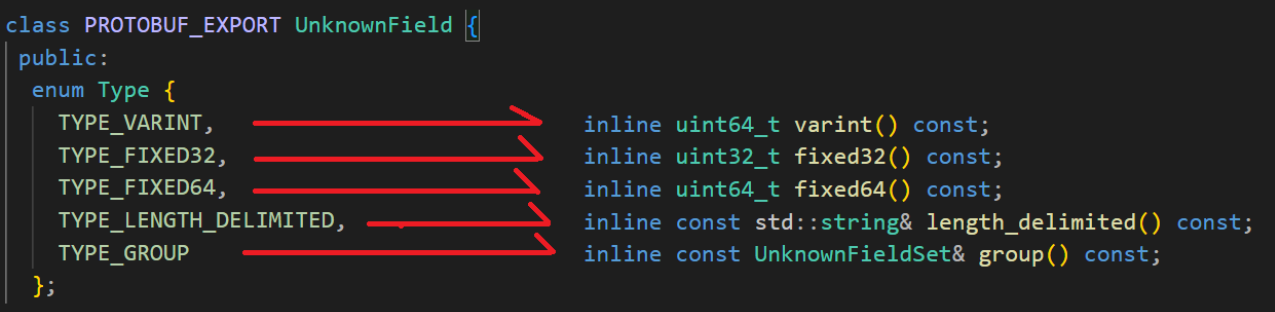
inline int number() const; // 返回未知字段的编号
inline Type type() const; // 返回未知字段的类型
下面对应代码
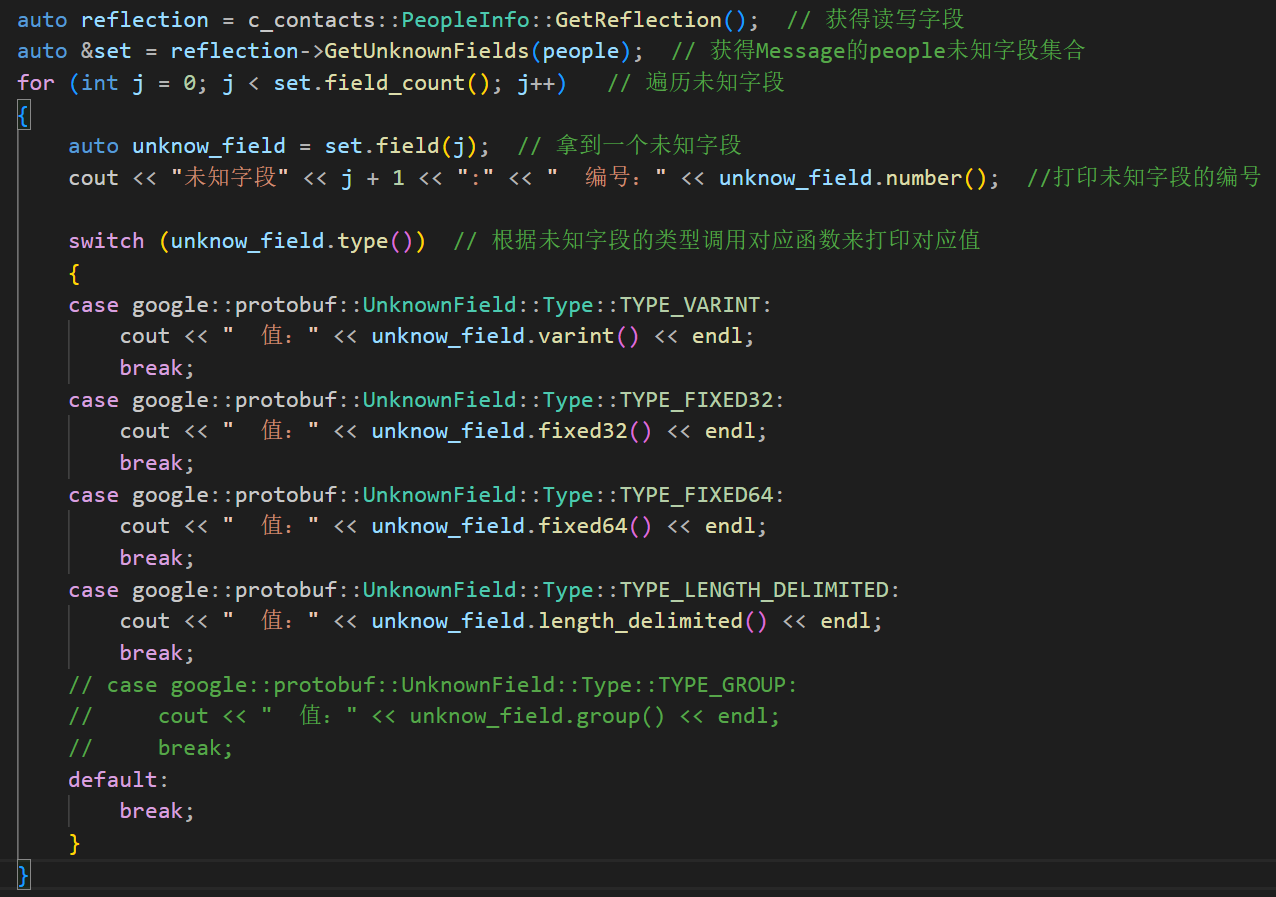
运行结果: