八大排序
- 🕯️前言
- 1. 常见排序算法
- 2. 常见排序算法实现
- 2.1. 冒泡排序
- 2.1.1. 基本思想
- 2.1.2. 代码实现
- 2.1.3. 特性
- 2.2. 快速排序
- 2.2.1. hoare法
- 基本思想
- 代码实现
- 2.2.2. 快速排序初步实现
- 2.2.3. 挖坑法
- 基本思想
- 代码实现
- 2.2.4. 前后指针法
- 基本思想
- 代码实现
- 2.2.5. 快速排序优化
- 三数取中
- 小区间优化
- 2.2.6. 快速排序的非递归实现
- 栈实现
- 队列实现
- 2.2.7. 特性
- 2.3. 归并排序
- 2.3.1. 基本思想
- 2.3.2. 代码实现
- 2.3.3. 非递归实现
- 2.3.4. 特性
- 2.4. 计数排序
- 2.4.1. 基本思想
- 2.4.2. 代码实现
- 2.4.3 特性
- 🗝️总结
八大排序
- 🕯️前言
- 1. 常见排序算法
- 2. 常见排序算法实现
- 2.1. 冒泡排序
- 2.1.1. 基本思想
- 2.1.2. 代码实现
- 2.1.3. 特性
- 2.2. 快速排序
- 2.2.1. hoare法
- 基本思想
- 代码实现
- 2.2.2. 快速排序初步实现
- 2.2.3. 挖坑法
- 基本思想
- 代码实现
- 2.2.4. 前后指针法
- 基本思想
- 代码实现
- 2.2.5. 快速排序优化
- 三数取中
- 小区间优化
- 2.2.6. 快速排序的非递归实现
- 栈实现
- 队列实现
- 2.2.7. 特性
- 2.3. 归并排序
- 2.3.1. 基本思想
- 2.3.2. 代码实现
- 2.3.3. 非递归实现
- 2.3.4. 特性
- 2.4. 计数排序
- 2.4.1. 基本思想
- 2.4.2. 代码实现
- 2.4.3 特性
- 🗝️总结
🕯️前言
啊还是国庆快乐!上节介绍了较为简单的插入排序、选择排序,今天我们上强度,学习交换排序、归并排序还有计数排序,开冲😎
1. 常见排序算法
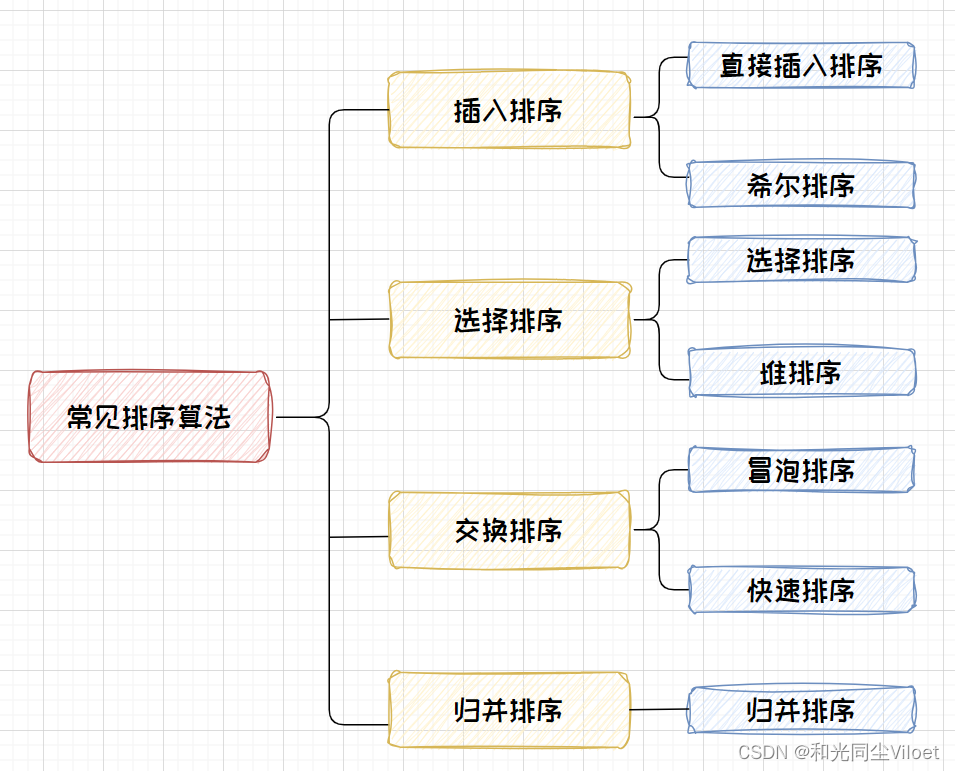
2. 常见排序算法实现
2.1. 冒泡排序
2.1.1. 基本思想
关于冒泡排序我们在C语言的学习中就有涉及
依次比较序列中相邻两个数据的大小,将较大的放在右边,每趟排序可以确定一个最大元素的位置,重复N(数据个数)次。

2.1.2. 代码实现
这不都小卡拉米?
void BubbleSort(int* a, int n)
{
for (int i = 0; i < n; i++)
{
int flag = 1;
//j要和后一个元素比较,防止越界j+1<n,
//又因为循环i次能确定最后i个数据的位置,可以让j+1<n-i
for (int j = 0; j < n - 1 - i; j++)
{
if (a[j] > a[j + 1])
{
flag = 0;
Swap(&a[j], &a[j + 1]);
}
}
if (flag == 1)
break;
}
}
- 其中flag的作用是假定数组有序,如果在某次遍历中没有发生交换,说明数组已经有序,可以跳出循环
2.1.3. 特性
- 冒泡排序是一种非常容易理解的排序(毕竟老面孔了😂)
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
- 稳定性:稳定
2.2. 快速排序
xdm,上强度了😵💫
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:
任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,(是不是挺像二叉树?)直到所有元素都排列在相应位置上为止。
在这个思想基础上的区间划分算法有三个版本:hoare法、挖坑法、前后指针法,我们逐个学习
2.2.1. hoare法
基本思想
为了方便表示,我们将基准值称为key,基准值的下标称为keyi
- 创建基准值key为最左边的元素,left、right分别指向序列首、尾
- right–,找比key值大的元素,找到后停下
- left++,找比key值小的元素,找到后停下
- 交换left和right指向的值
- 重复2~4步骤直到left==right,而后交换key和相遇位置的元素

- 通过上面的过程,我们最终确保了key左边都是小于等于key的值,key右边都是大于key的值
如何实现?
- 通过多次
right找的的较小值与left找到的较大值的交换,相遇位置左边的元素一定小于key,右边元素一定大于key

- 此时只要相遇位置的值小于key,就能保证交换后,key左边的值全部<key
那如何保证相遇位置也小于key?
通过right先找小
这样相遇就会有这两种情况:
- right- -,与left相遇:如果left还没有移动,指向key,则等于key;如果已经完成至少一次交换,left指针指向的元素是上一波交换过后的元素,该元素比key小。
- left++,与right相遇:right已经找到了小的元素,相遇后的值一定比key小。
代码实现
int PartSort1(int* a, int left, int right)
{
int keyi = left;
while (left < right)
{
//right先找小
while (left < right && a[right] >= a[keyi])
{
right--;
}
//left找大
while (left < right && a[left] <= a[keyi])
{
left++;
}
//交换left和right指向的值
Swap(&a[left], &a[right]);
}
//left和right相遇,交换key和交换位置的元素
Swap(&a[keyi], &a[left]);
return left;
}
hoare方法存在几个要注意的地方:
- right找小和left找大的过程中,要保证
left < right,否则会造成数组越界- right找小和left找大的过程中,必须跳过等于key的值(等于key继续++/- -),如果
a[left] == a[right] == key,交换完后数组没有变化,left和right依然==key,进入死循环
区间算法可以算作单趟排序,有了它我们可以先实现一个完整的快速排序
2.2.2. 快速排序初步实现
前面我们说了,通过一次区间划分,剩下的区间要在进行划分,类似二叉树的前序遍历,那我们可以用递归的思路进行设计,下面是递归展开图

通过分析,可以发现终止递归的条件是只有一个数据或者没有数据,也就是left>=right
void QuickSort(int* a, int left, int right)
{
if (left >= right)
return;
int keyi = PartSort1(a,left,right);
//递归[left,keyi-1]区间
QuickSort(a, left, keyi - 1);
//递归[keyi-1,right]区间
QuickSort(a, keyi + 1,right);
}
有了这个框架,后面的区间划分算法替换PartSort1函数就可以使用了
2.2.3. 挖坑法
基本思想
挖坑法实在hoare法基础上的改进
- 创建基准值key为最左边的元素,保存key的值,该位置形成一个坑位
- 右边找小,找到后把值给坑位,该位置成为新的坑位。
- 左边找大,找到后把值给坑位,该位置成为新的坑位。
- 重复2~3。
- 左右相遇,相遇位置也是个坑位,key值填入坑位

代码实现
在实现过程中,我们将挪动替换为了覆盖以简化代码
int PartSort2(int* a, int left, int right)
{
//基准值
int key = a[left];
//坑的位置
int hole = left;
while (left < right)
{
while (left < right && a[right] >= key)
{
right--;
}
//填坑,产生新的坑
a[hole] = a[right];
hole = right;
while (left < right && a[left] <= key)
{
left++;
}
a[hole] = a[left];
hole = left;
}
a[hole] = key;
return hole;
}
2.2.4. 前后指针法
基本思想
- 创建基准值key为最左边的元素,设置
prev指针为left,cur指针为left+1。- cur找小,如果找到
prev++,交换a[prev]和a[cur];没找到cur继续++- 重复步骤2。
- cur走完以后,a[prev]和key交换。

上面的过程如何确保最终左边的值小于key,右边的值大于key?
如果初始
cur指向的值小于key,这时prev和cur只相差一个元素,prev++后和cur指向同一位置,交换结果不变,prev会跟着cur一起++,prev指向小于key的值

当
cur指向的值大于key时,只有cur++,prev依然指向小于key的值
当cur指向的值又小于key时,prev实际上指向最后一个小于key的值,这时prev++就指向了大于key的值,此时交换就会把较小值放在左边,较大值放在右边

cur越界后,prev指向的就是数组中最后一个较小值,与key交换,最终左边的值小于key,右边的值大于key

代码实现
前后指针法比较难理解,但却是最好实现的
int PartSort3(int* a, int left, int right)
{
int prev = left, cur = left + 1;
int keyi = left;
while (cur <= right)
{
if (a[cur] < a[keyi] && prev++ != cur)
Swap(&a[cur], &a[prev]);
cur++;
}
Swap(&a[prev], &a[keyi]);
return prev;
}
- 为了省去无效交换,我们加了一个判断
prev++ != cur同时因为&&符号在第一个条件为真后才判断第二个条件,同时这个判断也完成了a[cur]<key时prev++的功能
2.2.5. 快速排序优化
三数取中
快排在面对一些极端数据时效率会明显下降;就比如完全有序的序列,这种序列的基准值key如果再取最左边的数,key值就是这个序列的最值,每次区间划分只会分出一个区域,复杂度会变成O(N^2)
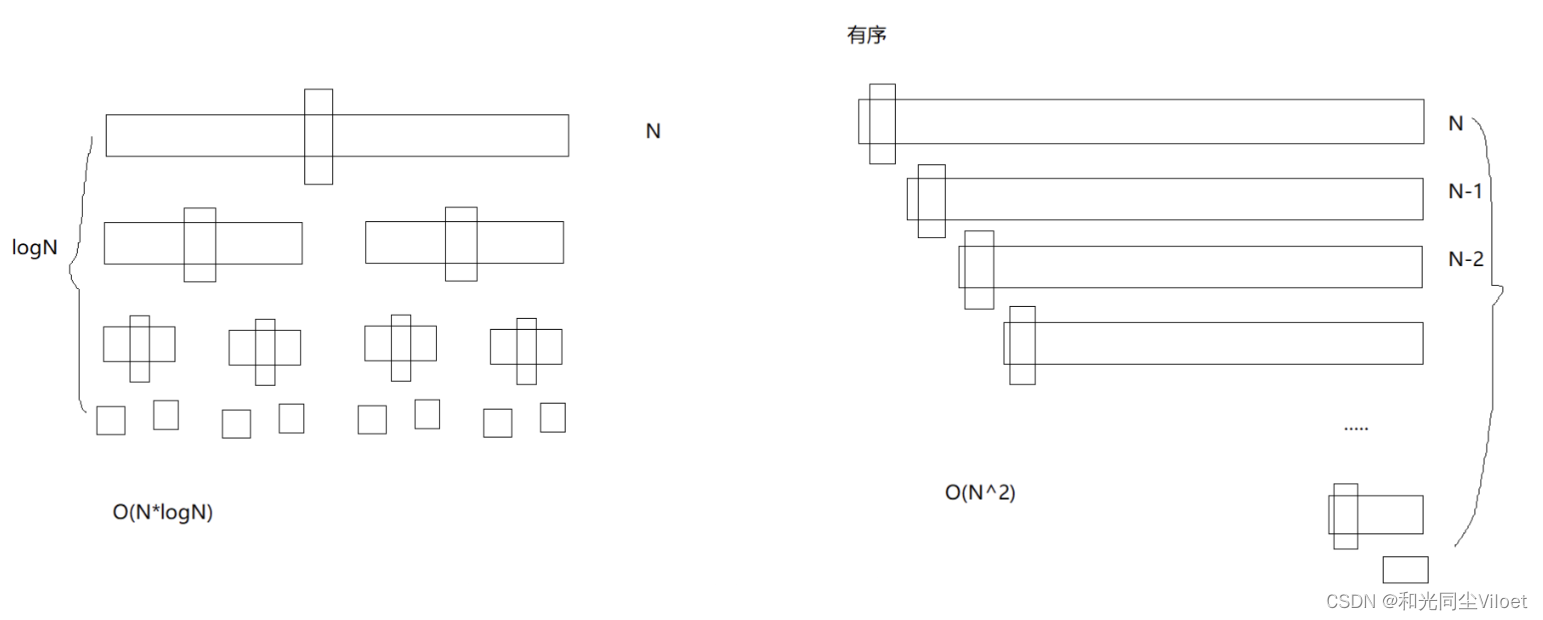
这时我们可以通过三数取中法来优化,三个数为:a[left],a[mid],a[right]
int GetMid(int* a, int left, int right)
{
int mid = (left + right) / 2;
if (a[mid] < a[left])
{
if (a[left] < a[right])
return left;
else if (a[right] < a[mid])
return mid;
else
return right;
}
else
{
if (a[left] > a[right])
return left;
else if (a[right] > a[mid])
return mid;
else
return right;
}
}
- 找到中间值后,把中间值和key值交换,让中间值成为新的key值
小区间优化
我们都知道,对于二叉树来说,深度越深,每层的节点数占比总结点数越高,相应递归次数越多;并且在快排递归过程中,一次递归只能减小一半的数据量,深度越深,递归处理的效率越低。由此我们可以递归到区间足够小的时候,直接调用插入排序,可以减少非常多的递归调用
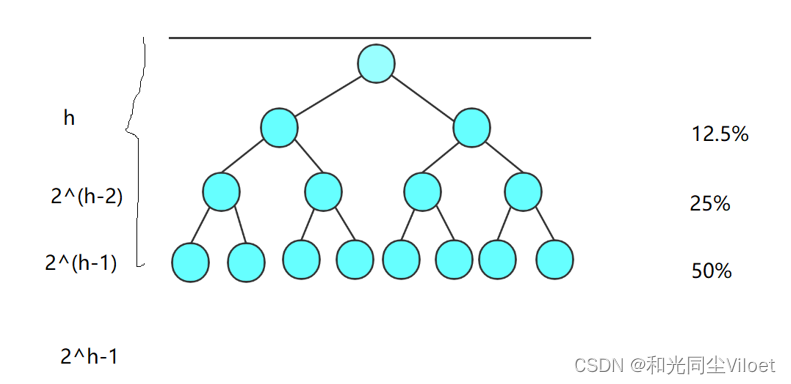
void QuickSort(int* a, int left, int right)
{
if (left >= right)
return;
//区间内元素个数 <= 10,调用直接插入排序
if (right - left <= 10)
{
//注意:起始地址是a + begin,不是a
InsertSort(a+left, right + 1);
}
int keyi = PartSort3(a,left,right);
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1,right);
}
2.2.6. 快速排序的非递归实现
首先我们要知道,为什么递归能解决的问题还要转化为非递归?
早期编译器对递归的优化不够好,所以非递归的效率会比比递归高,但是现在已经没有什么效率差异了
另一个原因是每次递归都要在栈上开辟新的空间,如果递归深度太深可能导致栈溢出。使用非递归就不会有这样的问题。
快速排序的非递归有两种途径实现,使用栈(深度优先遍历)或者使用队列(广度优先遍历)
栈实现
栈实现通过栈结构来模拟开辟栈空间,每次区间划分算法产生的左右区间分别入栈,再依次出栈进行排序,由于栈先入后出的特性,直到一个分支不再产生子区间时,才会进入下一个分支
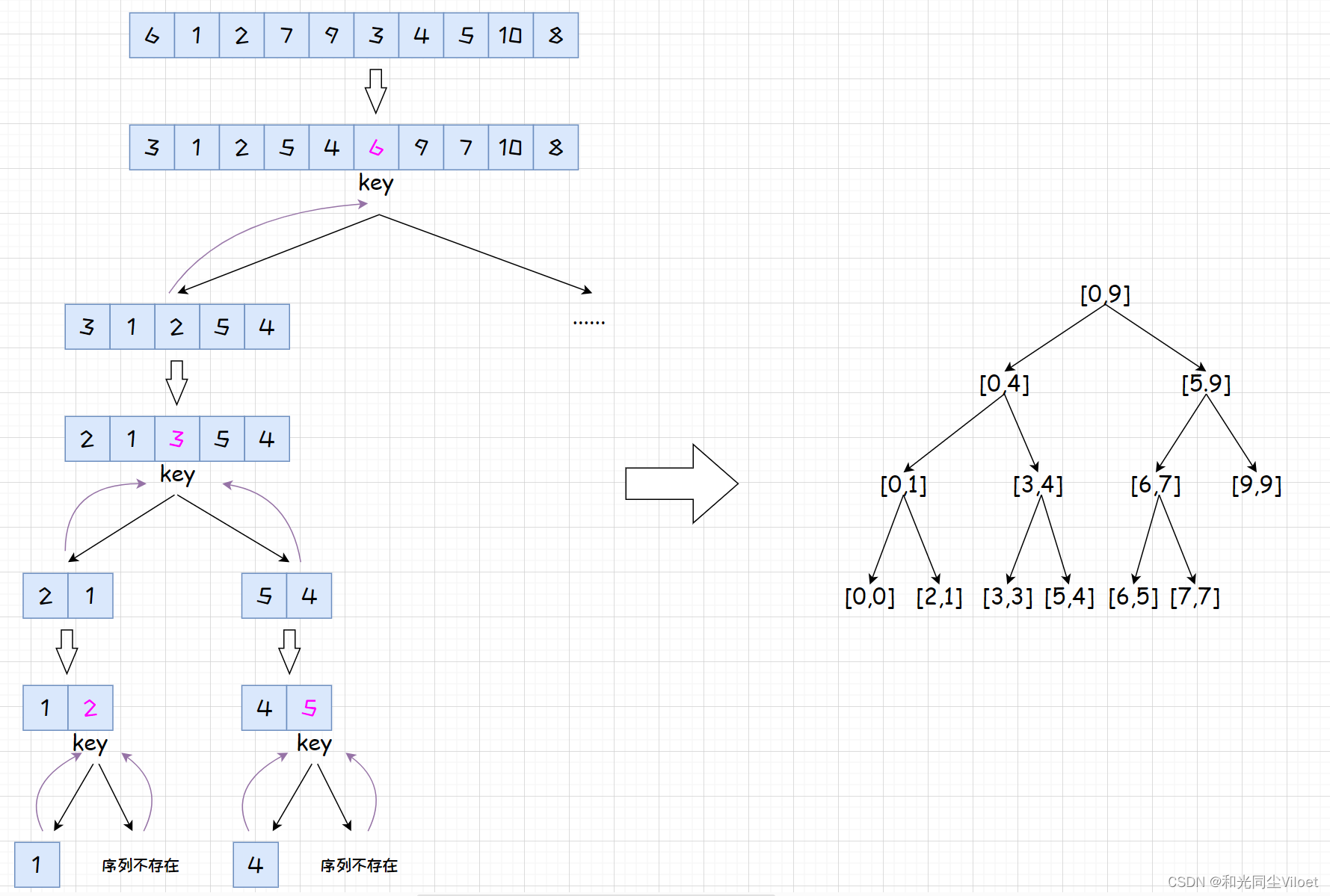
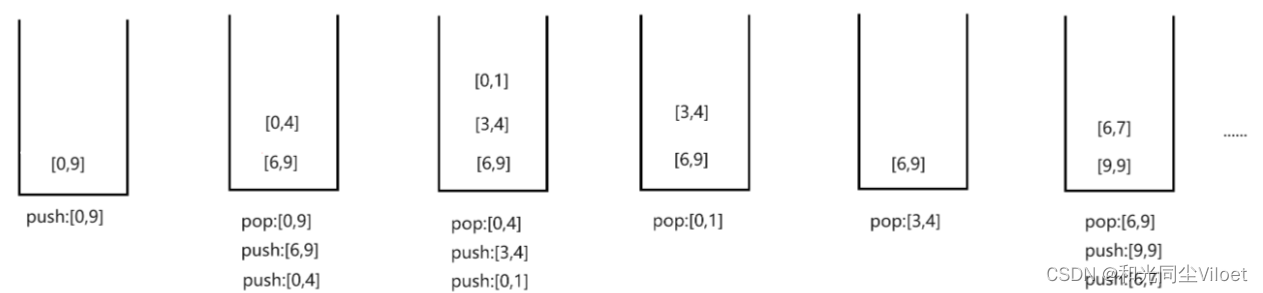
void QuickSortNonROnStack(int* a, int left, int right)
{
Stack st;
StackInit(&st);
//先Push右边界,在Push左边界
StackPush(&st, right);
StackPush(&st, left);
while (!StackEmpty(&st))
{
int left = StackTop(&st);
StackPop(&st);
int right = StackTop(&st);
StackPop(&st);
int keyi = PartSort3(a, left, right);
//产生[begin, keyi - 1],[keyi + 1, end]两个子区间
//停止入栈条件,同递归终止条件
if (right > keyi + 1)
{
//先递归左区间,所以右区间先入栈
StackPush(&st, right);
StackPush(&st, keyi + 1);
}
if (left < keyi - 1)
{
StackPush(&st, keyi - 1);
StackPush(&st, left);
}
}
StackDestory(&st);
}
队列实现
类似层序遍历,代码跟用栈实现差别不大
void QuickSortNonROnQueue(int* a, int left, int right)
{
Queue q;
QueueInit(&q);
QueuePush(&q, left);
QueuePush(&q, right);
while (!QueueEmpty(&q))
{
left = QueueFront(&q);
QueuePop(&q);
right = QueueFront(&q);
QueuePop(&q);
int keyi = Partion3(a, left, right);
if (left < keyi - 1)
{
QueuePush(&q, left);
QueuePush(&q, keyi - 1);
}
if (keyi + 1 < right)
{
QueuePush(&q, keyi + 1);
QueuePush(&q, right);
}
}
QueueDestory(&q);
}
2.2.7. 特性
1. 快速排序整体的综合性能和使用场景都是比较好的,所以才叫快速排序
2. 时间复杂度:O(N*logN)
3. 空间复杂度:O(logN)
4. 稳定性:不稳定
2.3. 归并排序
2.3.1. 基本思想
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide andConquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
归并排序核心步骤:
- 将待排序数组递归分成两个子数组,直到每个数组有序
- 递归合并两个有序子数组,直到整个数组有序。
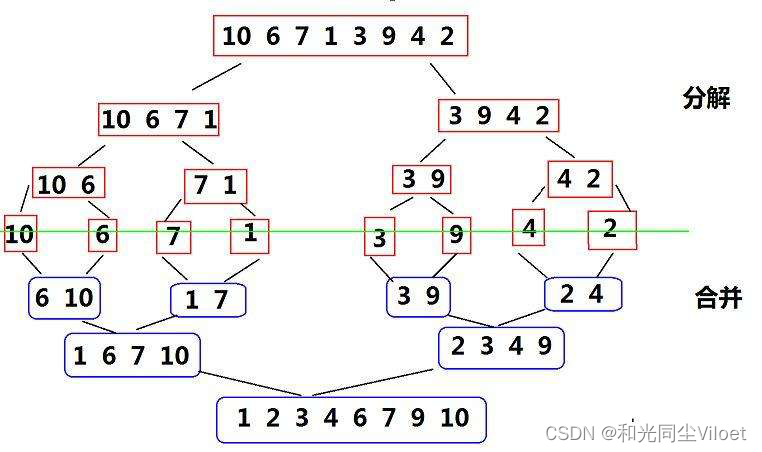

2.3.2. 代码实现
从上面的动图也可以看出,归并排序需要单独开辟空间
void _MergeSort(int* a,int*tmp, int left, int right)
{
//递归子区间到只有一个数或者不存在,返回
if (left >= right)
return;
int mid = (left + right) / 2;
//递归[left, mid]和[mid + 1, right]子区间
_MergeSort(a, tmp, left, mid);
_MergeSort(a, tmp, mid + 1, right);
//合并两个有序区间
int begin1 = left, end1 = mid;
int begin2 = mid+1, end2 = right;
int index = left;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
tmp[index++] = a[begin1++];
else
tmp[index++] = a[begin2++];
}
//没有复制完的子区间继续复制
while (begin1 <= end1)
tmp[index++] = a[begin1++];
while (begin2 <= end2)
tmp[index++] = a[begin2++];
//memcpy时目标数组和源数组都要从left开始,长度为right - left + 1
memcpy(a + left, tmp + left, sizeof(int) * (right - left + 1));
}
// 归并排序递归实现
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc failed");
exit(-1);
}
_MergeSort(a, tmp, 0, n-1);
}
2.3.3. 非递归实现
归并排序由于其类似后序的遍历方式,不能通过栈或者队列实现,我们通过手动控制归并个数的方法实现非递归:
假设数组个数为8,先令一个数据和一个数据归并,然后两个数据和两个数据归并,然后四个数据和四个数据归并,完成排序。
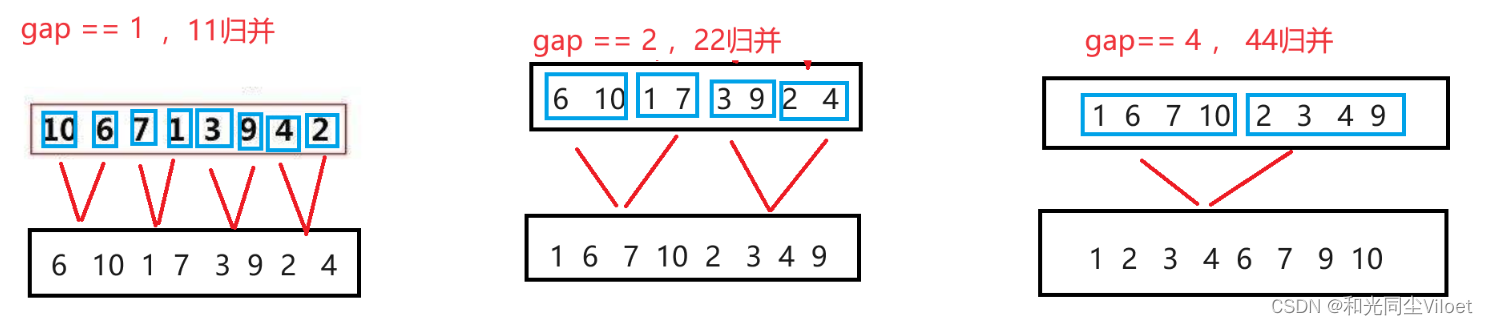
// 归并排序非递归实现
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc failed");
exit(-1);
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += gap * 2)
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + gap * 2 - 1;
//[i,i+gap-1] [i+gap,i+gap*2-1],每个区间2*gap个数据
int index = i;
//归并
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
tmp[index++] = a[begin1++];
else
tmp[index++] = a[begin2++];
}
while (begin1 <= end1)
tmp[index++] = a[begin1++];
while (begin2 <= end2)
tmp[index++] = a[begin2++];
//将每组归并的数据返回原数组
memcpy(a + i, tmp + i, sizeof(int) * gap * 2);
}
gap *= 2;
}
free(tmp);
}
看起来非常美好?
但这只是我们举的一个特例
- 在更多情况下,我们不能保证
[begin1, end1],[begin2, end2]这两个区间都存在,可能存在越界,我们可以肯定的是begin1一定不会越界,因为begin1 == i,而i < n,所以可能越界的变量有:end1,begin2,end2
对此可以分两种情况讨论:
end1和begin2越界:这种情况下[begin2, end2]不存在,不需要归并- 只有
end2越界:这种情况下[begin2, end2]存在,我们需令end2 = n - 1即可保证不越界
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc failed");
exit(-1);
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += gap * 2)
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + gap * 2 - 1;
//[i,i+gap-1] [i+gap,i+gap*2-1],每个区间2*gap个数据
int index = i;
//end1和begin2越界,不需要归并
if (end1 >= n )
break;
//只有end2越界
if (end2 >= n)
end2 = n - 1;
//归并
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
tmp[index++] = a[begin1++];
else
tmp[index++] = a[begin2++];
}
while (begin1 <= end1)
tmp[index++] = a[begin1++];
while (begin2 <= end2)
tmp[index++] = a[begin2++];
//将每组归并的数据返回原数组,归并大小即end2-i+1,
memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));
}
gap *= 2;
}
free(tmp);
}
2.3.4. 特性
1. 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
2. 时间复杂度:O(N*logN)
3. 空间复杂度:O(N)
4. 稳定性:稳定
2.4. 计数排序
2.4.1. 基本思想
计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用,是一种非比较排序。
原理是统计相同元素出现次数,然后根据统计的结果将序列回收到原来的序列中。
- 实现步骤:
- 遍历数组找到最大值和最小值,确定数据大小范围range=max-min+1
- 创建一个用于计数的数组,大小为range,同时初始化为1
- 遍历原数组,将数据减去min后的结果映射到计数数组的下标,让此下标的值++
- 根据计数结果依次回收到原来的数组中
2.4.2. 代码实现
void CountSort(int* a, int n)
{
//找最大值和最小值
int min = a[0], max = a[0];
for (int i = 0; i < n; i++)
{
if (a[i] < min)
min = a[i];
if (a[i] > max)
max = a[i];
}
//根据范围创建数组并初始化(也可以malloc后memset)
int range = max - min + 1;
int* tmp = (int*)calloc(range,sizeof(int));
if (tmp == NULL)
{
perror("malloc failed");
exit(-1);
}
//将数据映射到的计数数组下标值++
for (int i = 0; i < n; i++)
{
tmp[a[i] - min]++;
}
//根据计数结果依次回收到原来的数组中
int i = 0;
for (int index = 0; index < range; index++)
{
while (tmp[index]--)
{
a[i++] = index + min;
}
}
free(tmp);
}
2.4.3 特性
- 计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。
- 时间复杂度:O(MAX(N,范围))
- 空间复杂度:O(范围)
🗝️总结
- 以上就是关于排序的一切了,希望可以帮到你~😎
| 本节完~~,如果你在实现过程中遇到任何问题,欢迎在评论区指出或者私信我!💕 |
新人博主创作不易,如果有收获可否👍点赞✍评论⭐收藏一下?O(∩_∩)O

| THANKS FOR WATCHING |