推荐:用 NSDT编辑器 快速搭建可编程3D场景
在我们进入技术细节之前,考虑一下,为什么要使用 U-Net? 你可能在搜索语义分割时遇到过这一点,我很快就会写一篇博客,然后再看看这个。 制作此架构的初衷是用于生物医学图像分割。 如今,它是任何形式的语义分割中最流行的网络,并且该技术也被广泛应用于各种 Kaggle 竞赛中,作为解决大量计算机视觉问题的极其可靠的方法。
1、什么是跳跃连接?
为了理解 U-Net,我们需要理解跳跃连接(skip connection)背后的直觉。 这只是为了更好地了解正在发生的情况,实际论文/模型中并未明确使用它。
跳跃连接,顾名思义,是从网络的较早部分到较晚部分建立的连接,并传输信息。 这背后的直觉非常简单:我们希望找回某些层上丢失的信息,以便为网络提供更好的上下文。 在多个卷积过程的过程中,当网络深入到较低级别的特征时,它会丢失较高级别特征的上下文。 通过跳跃连接发送丢失的信息,即在两层之间建立的连接不按照发送信息的实际顺序。
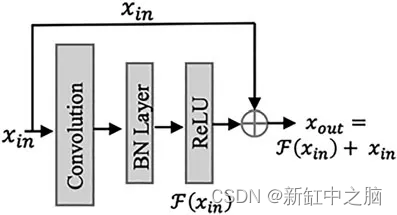
在这里我们可以看到如何将输入添加到网络的输出以获得新的输出
2、跳跃连接和U-Nets有什么关系?
简单:卷积过程背后的想法或直觉是双重的:提取特征,并减少较小图像上的计算时间。 然而,它会在此过程中丢失信息。 U-Net 充分利用了两个方面的优点,这样当我们对图像进行上采样或放大时,我们会将特征映射连接到相应的放大后的映射集。

现在这张图应该更有意义了!
观察跳跃连接如何工作。 对于第一个逆卷积过程,发送了最后一个卷积过程的特征图。 对于第二个逆卷积,倒数第二个,以此类推。 引用论文作者(Olaf Ronneberger、Philipp Fischer 和 Thomas Brox)的话:
为了预测图像边界区域中的像素,通过镜像输入图像来推断丢失的上下文。
正如作者所说的那样,该网络的一个重要特点是该网络能够在极少的数据上进行过度增强的训练,并且训练的准确性很高。
3、U-Net实现代码
我将使用 pytorch 来完成此操作,如果您想了解 TensorFlow/keras 的方法,请尝试这篇文章(一直在底部)。 让我们从定义一些辅助类开始。
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
首先,双卷积层,因为每个单独的块都使用其中之一,而不管上采样或下采样。
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
然后是使用我们之前制作的 Double Conv 的下采样模块。
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
else:
self.up = nn.ConvTranspose2d(in_channels // 2, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = torch.tensor([x2.size()[2] - x1.size()[2]])
diffX = torch.tensor([x2.size()[3] - x1.size()[3]])
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
return self.conv(x1)
现在是上采样模块,再次使用 DoubleConv。 请注意我们如何在双线性上采样和转置卷积过程之间进行选择。 我们选择双线性只是因为研究表明它能提供更好的结果,而且论文还提到可以尝试转置。
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
最后,最后一层的类,具有完成分割颜色图所需的输出通道数。
现在,让我们将其全部应用到模型本身中。 我在这里使用了一些来自之前项目的超参数,请随意根据你的需求进行调整。
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
self.down4 = Down(512, 512)
self.up1 = Up(1024, 256, bilinear)
self.up2 = Up(512, 128, bilinear)
self.up3 = Up(256, 64, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
应该很容易理解这里发生的事情(所有 pytorch 和它的 pythonic 代码风格)。 请密切注意我们如何将 x4、x3 等与其相应的上采样块一起传递,以模拟 U-Net 设计,并且它是跳过连接。 我们将该 x3 发送到两个位置:发送到下一个块以进行下采样,以及用于保存第二个上采样块上采样的数据。
4、U-Net应用领域
正如我们上面所讨论的,U-Net的最大用途是语义分割,并且迄今为止在该领域表现出色。
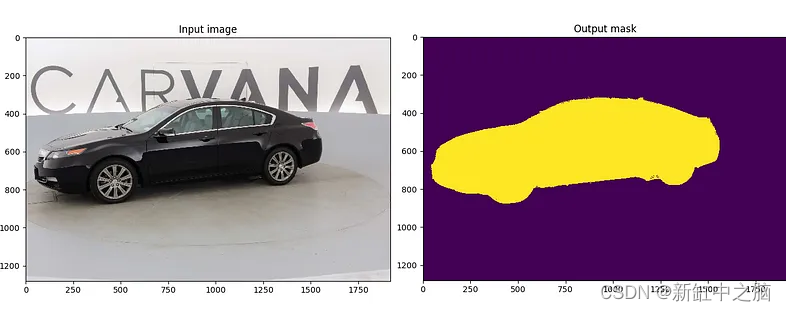
一项非常受欢迎的 Kaggle 竞赛,旨在创建这些汽车的掩码以便于提取
5、结束语
希望你对 unets 是什么以及它们如何工作有一个很好的了解,或者至少了解它们如何工作背后的直觉。 Good Day!
原文链接:U-Net简明教程 — BimAnt