CPU亲和性(CPU Affinity)是某一进程(或线程)绑定到特定的CPU核(或CPU集合),从而使得该进程(或线程)只能运行在绑定的CPU核(或CPU集合)上。进程(或线程)本质上并不与CPU核绑定。每次进程(或线程)被调度执行时,它都可以由其关联列表中的任何CPU核执行。如果未显式设置关联列表,则进程(或线程)可以在任何CPU核上运行。
一.查看CPU信息
1.通过命令,执行:
cat /proc/cpuinfo (1).processor:指明每个物理CPU中逻辑处理器信息,序号从0开始;
(2).cpu cores: 指明每个物理CPU中总核数;
2.查看物理CPU个数,执行:
cat /proc/cpuinfo | grep "physical id" | sort | uniq | wc -l3.查看每个物理CPU中core的个数(即核数),执行:
cat /proc/cpuinfo | grep "cpu cores" | uniq4.查看逻辑CPU的个数,执行:
cat /proc/cpuinfo | grep "processor" | wc -l5.通过代码:sysconf函数或get_nprocs函数
void get_cpu_cores()
{
// _SC_NPROCESSORS_CONF:系统配置的CPU核心数量
// _SC_NPROCESSORS_ONLN:当前系统实际可用的CPU核心数量,可能会因为系统的运行状态而变化
// 两个函数返回的值可能并不完全相同
std::cout << "cpu cores(_SC_NPROCESSORS_CONF): " << sysconf(_SC_NPROCESSORS_CONF) << "\n";
std::cout << "cpu cores(_SC_NPROCESSORS_ONLN): " << sysconf(_SC_NPROCESSORS_ONLN) << "\n";
// get_nprocs_conf:系统配置的CPU核心数量; get_nprocs:当前系统中可用的CPU核心数量,此值可能小于get_nprocs_conf返回的值
std::cout << "cpu cores(get_nprocs_conf): " << get_nprocs_conf() << "\n";
std::cout << "cpu cores(get_nprocs): " << get_nprocs() << "\n";
} 二.将进程绑定到指定的CPU核上
1.通过taskset:(-p:pid; -c:cpu list)
(1).查看执行程序(进程)运行在哪个CPU核上:taskset -p 进程ID(PID, 操作系统分配给每个进程的唯一标识符)
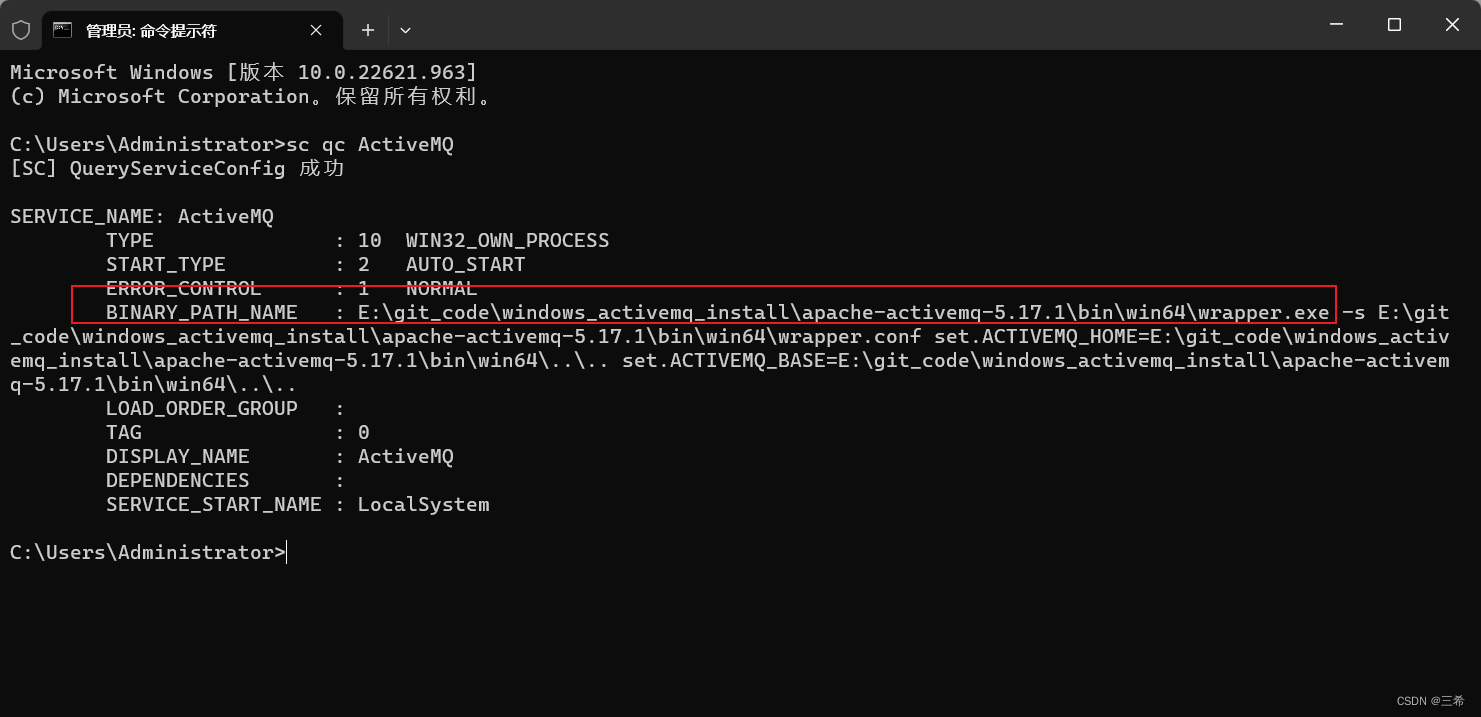
如查看gnome-shell运行在哪个CPU核上:通过top命令查看gnome-shell的PID为1246,输入:taskset -pc 1246 ,执行结果如下图所示:

(2).启动时指定:CPU标号从0开始,绑定多个CPU核,之间用逗号分隔
taskset -c CPU_标号 可执行程序
(3).启动后绑定:CPU标号从0开始,绑定多个CPU核,之间用逗号分隔
taskset -pc CPU_标号 PID
2.通过代码:sched_setaffinity和sched_setaffinity函数
(1).sched_setaffinity(pid_t pid, size_t cpusetsize, const cpu_set_t *mask): 将ID为pid的线程的CPU亲和性掩码(CPU affinity mask)设置为mask指定的值。如果pid为0,则使用调用线程。参数cpusetsize是 mask指向的数据的长度(以字节为单位)。通常该参数被指定为sizeof(cpu_set_t)。
(2).sched_getaffinity(pid_t pid, size_t cpusetsize, cpu_set_t *mask): 将ID为pid的线程的亲和性掩码写入mask指向的cpu_set_t结构中。cpusetsize参数指定掩码的大小(以字节为单位)。如果pid为零,则返回调用线程的掩码。
void set_processor_to_cpu_core()
{
{ // sched_getaffinity
cpu_set_t mask;
CPU_ZERO(&mask);
if (sched_getaffinity(0, sizeof(mask), &mask) != 0)
std::cerr << "Error: fail to sched_getaffinity\n";
for (auto i = 0; i < sysconf(_SC_NPROCESSORS_ONLN); ++i) {
if (CPU_ISSET(i, &mask))
std::cout << "CPU " << i << " is set\n";
}
}
{ // sched_setaffinity
cpu_set_t mask;
CPU_ZERO(&mask);
// 可以多次调用CPU_SET,以指定将多个CPU核添加到mask中
CPU_SET(0, &mask); // set affinity for core 0, set the bit that represents core 0
if (sched_setaffinity(0, sizeof(mask), &mask) != 0)
std::cerr << "Error: fail to sched_setaffinity\n";
}
} 三.将线程绑定到指定的CPU核上
1.通过代码:pthread_setaffinity_np函数和pthread_getaffinity_np
(1).pthread_setaffinity_np(pthread_t thread, size_t cpusetsize, const cpu_set_t *cpuset): 将线程thread的CPU亲和性掩码(CPU affinity mask)设置为cpuset指向的CPU集。如果调用成功,并且该线程当前未在cpuset中的某个CPU上运行,则它将迁移到这些CPU中的一个。
(2).pthread_getaffinity_np(pthread_t thread, size_t cpusetsize, cpu_set_t *cpuset): 获取cpuset指向的缓冲区中线程thread的CPU亲和性掩码。
void get_thread_id(int n)
{
std::cout << "thread id: " << std::this_thread::get_id() << ", on cpu: " << sched_getcpu() << "\n";
std::this_thread::sleep_for(std::chrono::seconds(n));
}
void set_thread_to_cpu_core()
{
// 最大的硬件并发线程数
std::cout << "Support concurrent threads: " << std::thread::hardware_concurrency() << "\n";
std::thread th1(get_thread_id, 5), th2(get_thread_id, 5);
{ // pthread_getaffinity_np
cpu_set_t cpuset;
CPU_ZERO(&cpuset);
if (pthread_getaffinity_np(th1.native_handle(), sizeof(cpuset), &cpuset) != 0)
std::cerr << "Error: fail to pthread_getaffinity_np\n";
// for (auto i = 0; i < sysconf(_SC_NPROCESSORS_ONLN); ++i) {
// if (CPU_ISSET(i, &cpuset))
// std::cout << "CPU " << i << " is set\n";
// }
}
{ // pthread_setaffinity_np
cpu_set_t cpuset;
CPU_ZERO(&cpuset);
// 可以多次调用CPU_SET,以指定将多个CPU核添加到cpuset中
CPU_SET(0, &cpuset); // set affinity for core 0, set the bit that represents core 0
if (pthread_setaffinity_np(th2.native_handle(), sizeof(cpuset), &cpuset) != 0)
std::cerr << "Error: fail to pthread_setaffinity_np\n";
}
th1.join();
th2.join();
}以上测试代码执行结果如下图所示:虚拟机

GitHub:https://github.com/fengbingchun/Linux_Code_Test
![洛谷题解 | P9690 [GDCPC2023] Programming Contest](https://img-blog.csdnimg.cn/img_convert/dbc83fac8c627c4a06ca028e2d697a47.png)