目录
一、背景
二、介绍
2.1 MSR-VTT
2.2 MSVD
2.3 VATEX
三、参考文献
一、背景
Video Caption / 视频字幕:常用指标(BELU-4,ROUGE-L,METEOR,CIDEr,SPICE)和数据集总结-CSDN博客Video Caption / 视频字幕:常用指标(BELU-4,ROUGE-L,METEOR,CIDEr,SPICE)和数据集总结https://blog.csdn.net/Crystal_remember/article/details/133126871 上篇文章总结介绍了Video Caption / 视频字幕的常用指标,本文接着总结Video Caption / 视频字幕的常用数据集。
目前Video Caption / 视频字幕常用数据集主要有MSR-VTT[1]、MSVD[2]、VATEX[3]。下main进行分别介绍。
二、介绍
2.1 MSR-VTT
MSR-VTT是一个通用的视频字幕数据集,包括10000个视频片段,每个片段都注释有20个字幕。平均地,每个视频剪辑持续约15秒。标准情况下通常使用6153个片段进行训练,497个片段用于验证,2090个片段用于测试。
如下为MSR-VTT数据集中的6个片段和标注的语句。每个片段包含四个帧来表示视频片段和五个人类标记的句子。

2.2 MSVD
MSVD包含1970个视频,每个视频片段有40个字幕。每个视频片段的平均持续时间约为10秒。常见情况下,包括使用1200个视频进行训练,100个视频进行验证,670个视频进行测试。数据集示例如下。

2.3 VATEX
VATEX是一个包含约41250个视频剪辑的大规模数据集,和 82.5 万中英文视频描述,其中包括超过 20.6 万描述是中英平行翻译对。每个视频片段的持续时间在10秒之间,每个片段手动注释10个英文字幕。
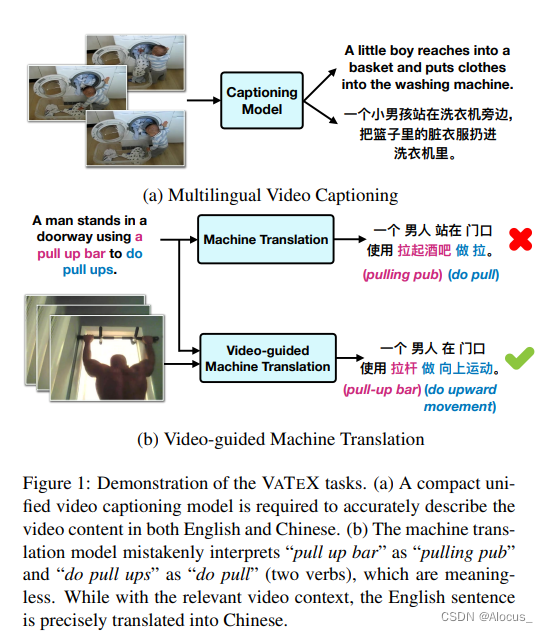

每个视频具备 10 个英文描述和 10 个中文描述,分别来自 20 个人类标注者。所有这些都描绘了相同的视频,因此彼此之间是平行的,而最后五个是彼此成对的翻译。
三、参考文献
[1]Jun Xu, Tao Mei, Ting Yao, and Yong Rui. MSR-VTT: A large video description dataset for bridging video and language. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5288–5296, 2016.
[2]David L. Chen and William B. Dolan. Collecting highly parallel data for paraphrase evaluation. In Annual Meeting of the Association for Computational Linguistics, 2011.
[3]Xin Wang, Jiawei Wu, Junkun Chen, Lei Li, Yuan-Fang Wang, and William Yang Wang. Vatex: A large-scale, highquality multilingual dataset for video-and-language research. In IEEE/CVF International Conference on Computer Vision, 2019