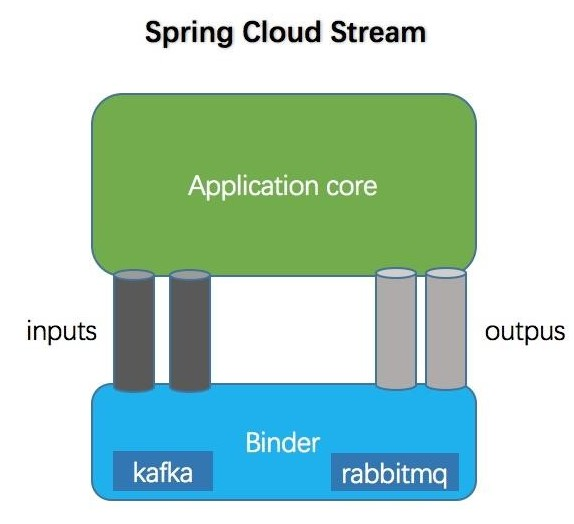
一、说明
这是一篇很长的文章,几乎讨论了人们需要了解的有关注意力机制的所有信息,包括自我注意、查询、键、值、多头注意力、屏蔽多头注意力和转换器,包括有关 BERT 和 GPT 的一些细节。因此,我将本文分为两部分。在本文中,我将介绍所有注意力块,在下一个故事中,我将深入探讨变压器网络架构。
二 RNN 的挑战以及转换器模型如何帮助克服这些挑战
注意力机制于2014年首次用于计算机视觉,试图理解神经网络在进行预测时正在查看的内容。这是尝试理解卷积神经网络(CNN)输出的第一步。2015年,注意力首先用于对齐机器翻译中的自然语言处理(NLP)。最后,在2017年,注意力机制被用于Transformer网络中的语言建模。此后,变压器已经超越了递归神经网络(RNN)的预测精度,成为NLP任务的最新技术。
2.1 RNN 问题 1 — 遇到长期依赖问题。
RNN 不适用于长文本文档。
变压器解决方案 — 变压器网络几乎只使用注意力块。注意力有助于在序列的任何部分之间建立连接,因此长期依赖不再是问题。对于变压器,长期依赖性与任何其他短程依赖性具有相同的可能性。
2.2. RNN 问题 2 — 遭受梯度消失和梯度爆炸。
变压器解决方案 — 几乎没有梯度消失或爆炸问题。在变压器网络中,整个序列是同时训练的,并且在此基础上仅添加几层。因此,梯度消失或爆炸很少成为问题。
2.3. RNN 问题 3 — RNN 需要更大的训练步骤才能达到局部/全局最小值。
RNN可以可视化为一个非常深的展开网络。网络的大小取决于序列的长度。这产生了许多参数,并且这些参数中的大多数是相互关联的。因此,优化需要更长的训练时间和很多步骤。
变压器解决方案 — 比 RNN 需要更少的训练步骤。
2.4. RNN 问题 4 — RNN 不允许并行计算。
GPU 有助于实现并行计算。但是RNN作为序列模型工作,也就是说,网络中的所有计算都是按顺序进行的,不能并行化。
变压器解决方案 — 变压器网络中没有重复出现,允许并行计算。因此,每一步都可以并行进行计算。
三、注意力机制
3.1 自我注意
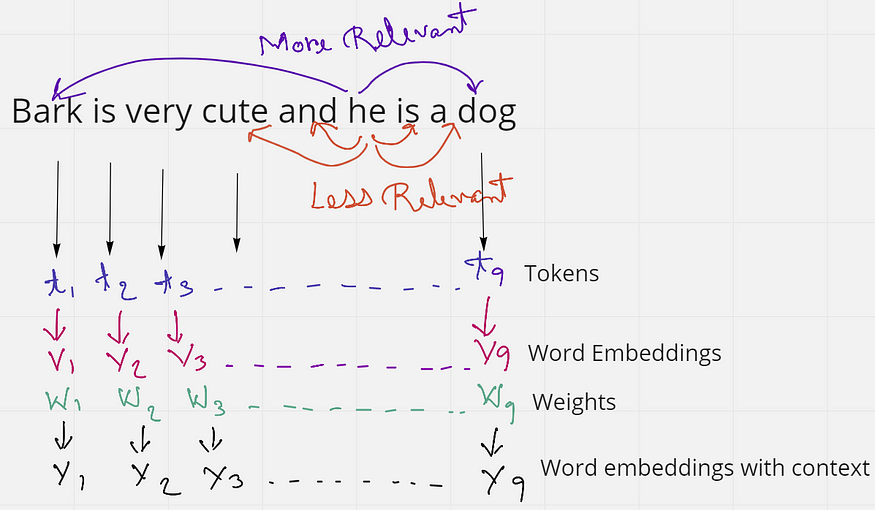
图2.解释自我注意的示例(来源:作者创建的图片)
考虑一下这句话——“吠叫很可爱,他是一只狗”。这句话有9个单词或标记。如果我们只考虑句子中的“他”这个词,我们会发现“和”是“是两个非常接近它的词。但这些词并没有给“他”这个词任何上下文。相反,“吠叫”和“狗”这两个词与句子中的“他”更相关。由此,我们了解到接近并不总是相关的,但上下文在句子中更相关。
当这个句子被馈送到计算机时,它将每个单词视为一个标记t,并且每个标记都有一个单词嵌入V。但是这些词嵌入没有上下文。因此,我们的想法是应用某种权重或相似性来获得最终的单词嵌入Y,它比初始嵌入V具有更多的上下文。
在嵌入空间中,相似的单词看起来更靠近或具有相似的嵌入。比如“国王”这个词会更与“女王”和“皇室”这个词相关,而不是与“斑马”这个词相关。同样,“斑马”与“马”和“条纹”的关系比与“情感”一词的关系更大。要了解有关嵌入空间的更多信息,请访问Andrew Ng(NLP和单词嵌入)的视频。
因此,直觉上,如果“国王”一词出现在句子的开头,而“女王”一词出现在句子的末尾,它们应该相互提供更好的上下文。我们使用这个想法来找到权重向量 W,通过将单词嵌入相乘(点积)以获得更多的上下文。所以,在句子中,Bark非常可爱,他是一只狗,而不是按原样使用单词嵌入,我们将每个单词的嵌入相乘。图 3 应该能更好地说明这一点。

图3.查找权重并获得最终嵌入(来源:作者创建的图像)
如图 3 所示,我们首先通过将第一个单词的初始嵌入乘以(点积)与句子中所有其他单词的嵌入来找到权重。这些权重(W11 到 W19)也归一化为总和为 1。接下来,将这些权重乘以句子中所有单词的初始嵌入。
W11 V1 + W12 V2 + ....W19 V9 = Y1
W11 到 W19 都是具有第一个单词 V1 上下文的权重。因此,当我们将这些权重乘以每个单词时,我们实际上是在将所有其他单词重新加权到第一个单词。因此,从某种意义上说,“吠叫”这个词现在更倾向于“狗”和“可爱”这两个词,而不是紧随其后的词。这在某种程度上提供了一些背景。
对所有单词重复此操作,以便每个单词从句子中的其他单词中获得一些上下文。
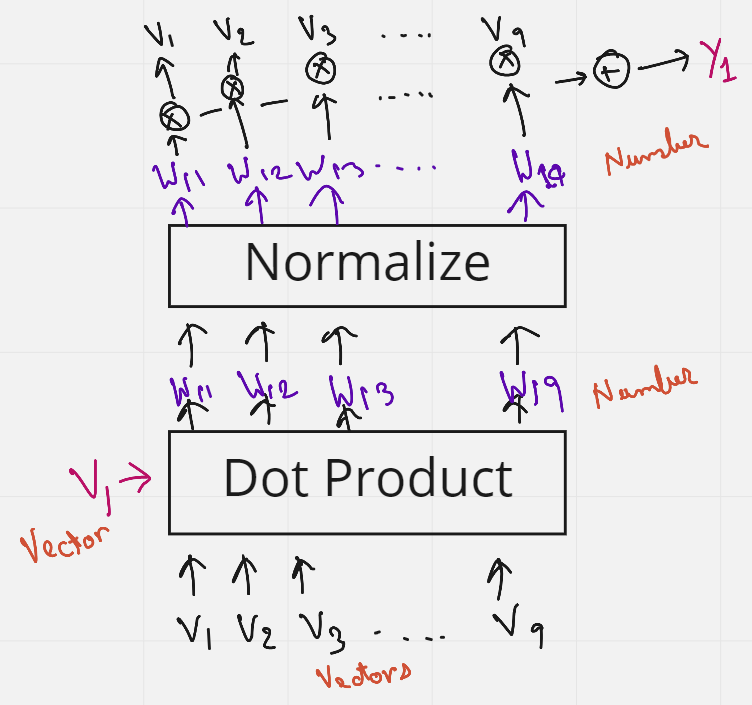
图4.上述步骤的图形表示(来源:作者创建的图像)
图4使用图形图更好地理解了获得Y1的上述步骤。
有趣的是,没有训练权重,单词的顺序或接近度彼此没有影响。此外,该过程不依赖于句子的长度,也就是说,句子中更多或更少的单词无关紧要。这种为句子中的单词添加一些上下文的方法称为自我注意。
3.2 查询、键和值
自我注意的问题在于没有任何东西被训练。但也许如果我们添加一些可训练的参数,网络就可以学习一些模式,从而提供更好的上下文。此可训练参数可以是训练其值的矩阵。因此,引入了查询、键和值的概念。
让我们再考虑一下前面的一句话——“吠叫很可爱,他是一只狗”。在自我注意的图 4 中,我们看到初始词嵌入 (V) 使用了 3 次。1st作为句子中第一个单词嵌入和所有其他单词(包括其自身,2nd)之间的点积以获得权重,然后再次将它们(第3次)乘以权重,以获得带有上下文的最终嵌入。这 3 个出现的 V 可以替换为三个术语查询、键和值。
假设我们想使所有单词与第一个单词 V1 相似。然后,我们将 V1 作为查询词发送。然后,这个查询词将对句子中的所有单词(V1 到 V9)做一个点积——这些就是键。因此,查询和键的组合为我们提供了权重。然后将这些权重再次与充当值的所有单词(V1 到 V9)相乘。我们有它,查询,键和值。如果您仍然有一些疑问,图 5 应该能够清除它们。
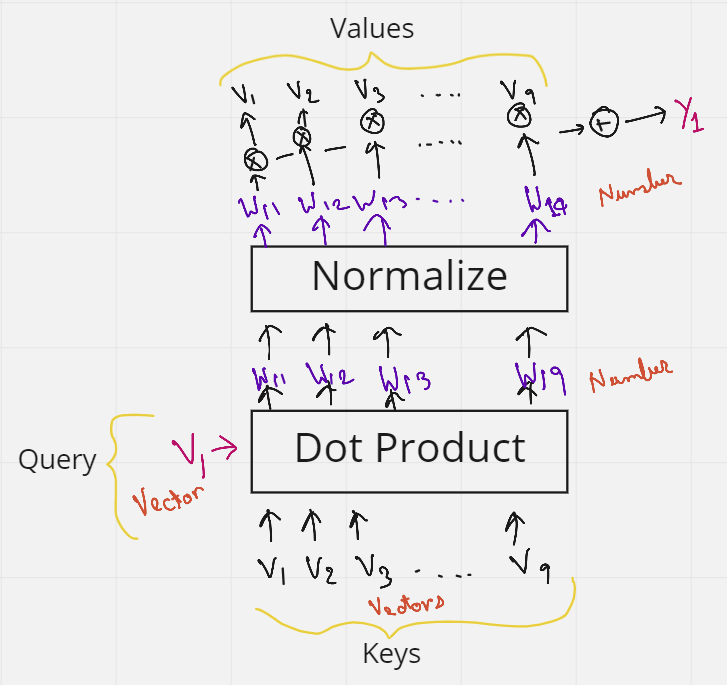
图5.表示查询、键和值(来源:作者创建的图像)
但是等等,我们还没有添加任何可以训练的矩阵。这很简单。我们知道,如果将 1 x k 形向量乘以 k x k 形矩阵,我们得到一个 1 x k 形向量作为输出。记住这一点,让我们将每个键从 V1 乘以 V10 到 V1(每个形状为 6 x k),并乘以形状为 k x k 的矩阵 Mk(键矩阵)。类似地,查询向量乘以矩阵 Mq(查询矩阵),值向量乘以值矩阵 Mv。这些矩阵 Mk、Mq 和 Mv 中的所有值现在都可以由神经网络训练,并且比仅仅使用自我注意提供更好的上下文。同样,为了更好地理解,图 <> 显示了我刚才解释的内容的图形表示。

图6.键矩阵、查询矩阵和值矩阵(来源:作者创建的图像)
现在我们知道了键、查询和值的直觉,让我们看看数据库分析以及注意力背后的官方步骤和公式。
让我们通过查看数据库的示例来尝试理解注意力机制。因此,在数据库中,如果我们想根据查询 q 和键 k i 检索某个值 vi,可以执行一些操作,其中我们可以使用查询来识别对应于某个值的键。注意力可以被认为是与此数据库技术类似的过程,但以更概率的方式。下图对此进行了演示。
图 7 显示了在数据库中检索数据的步骤。假设我们将一个查询发送到数据库中,一些操作会找出数据库中哪个键与查询最相似。找到密钥后,它将发送与该密钥对应的值作为输出。在图中,该操作发现查询与键 5 最相似,因此为我们提供了值 5 作为输出。

图7.数据库中的值检索过程(来源:作者创建的图像)
注意力机制是一种模仿这种检索过程的神经架构。

- 注意力机制测量查询 q 和每个键值 k i 之间的相似性。
- 此相似性为每个键值返回一个权重。
- 最后,它生成一个输出,该输出是我们数据库中所有值的加权组合。
从某种意义上说,数据库检索和注意力之间的唯一区别是,在数据库检索中,我们只得到一个值作为输入,但在这里我们得到一个值的加权组合。在注意力机制中,如果查询与键 1 和键 4 最相似,那么这两个键将获得最多的权重,输出将是值 1 和值 4 的组合。
Figure 8 显示了从查询、键和值获取最终注意力值所需的步骤。下面将详细解释每个步骤。
(键值 k 是向量,相似性值 S 是标量,权重值 (softmax) 值 a 是标量,值 V 是向量)
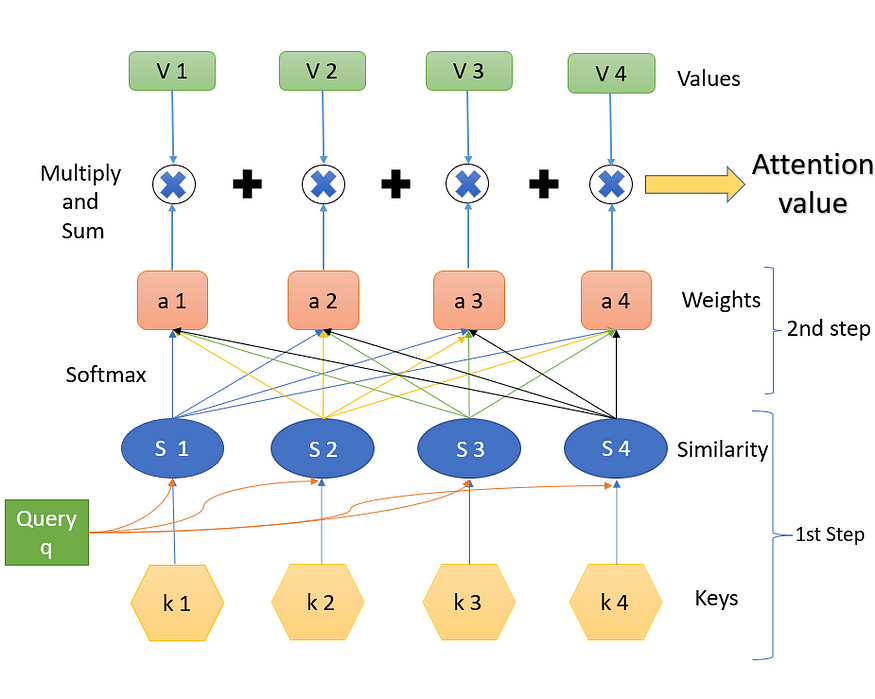
图 8. 获得注意力值的步骤(来源:作者创建的图片)
3.3 第 1 步。
步骤 1 包含键和查询以及相应的相似性度量。查询 q 会影响相似性。我们拥有的是查询和键,并计算相似性。相似性是查询 q 和键 k 的某些函数。查询和键都是一些嵌入向量。相似性 S 可以使用各种方法计算,如图 9 所示。

图9.计算相似性的方法(Souce:作者创建的图像)
相似性可以是查询和键的简单点积。它可以是缩放点积,其中q和k的点积除以每个键的维数d的平方根。 这是查找相似性最常用的两种技术。
通常,使用权重矩阵 W 将查询投影到新空间中,然后使用键 k 创建点积。内核方法也可以用作相似性。
3.4 第 2 步。
第 2 步是查找权重 a。这是使用“SoftMax”完成的。公式如下所示。(exp 是指数级的)
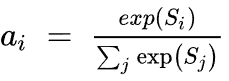
相似性像完全连接的层一样与权重相连。
3.5 第 3 步。
步骤 3 是 softmax (a) 的结果与相应值 (V) 的加权组合。a 的第一个值乘以 V 的第一个值,然后与 a 的第 1 个值与值 V 的第 2 个值的乘积相加,依此类推。我们获得的最终输出是所需的结果注意力值。
![]()
三个步骤的摘要:
W在查询 q 和键 k 的帮助下,我们获得注意值,它是值 V 的加权和/线性组合,权重来自查询和键之间的某种相似性。
3.6 注意力的神经网络表示
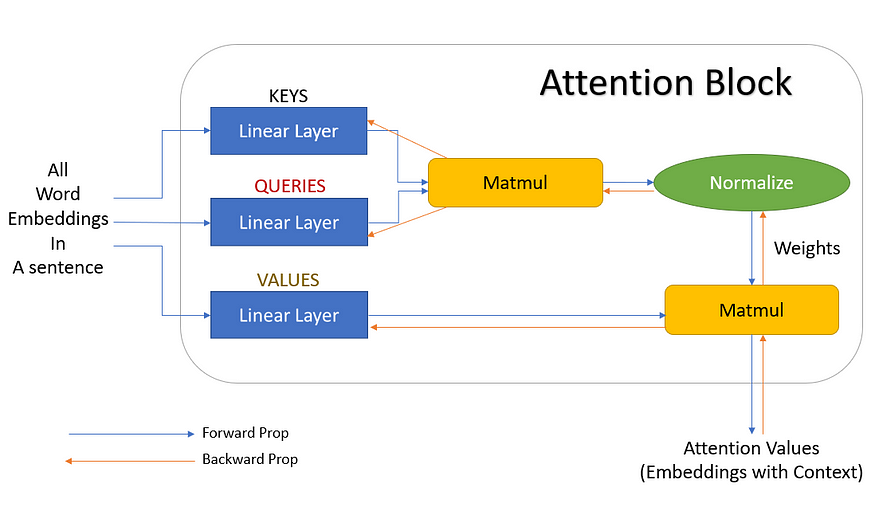
图 10.注意力块的神经网络表示(来源:作者创建的图像)
图 10 显示了注意力块的神经网络表示。词嵌入首先传递到一些线性层中。这些线性层没有“偏差”项,因此只不过是矩阵乘法。其中一个层表示为“键”,另一个表示为“查询”,最后一个层表示为“值”。如果在键和查询之间执行矩阵乘法,然后进行规范化,我们将得到权重。然后将这些权重乘以值并相加,得到最终的注意力向量。这个块现在可以在神经网络中使用,被称为注意力块。可以添加多个这样的注意力块以提供更多上下文。最好的部分是,我们可以获得梯度反向传播来更新注意力块(键、查询、值的权重)。
3.7 多头注意力
为了克服使用单头注意力的一些陷阱,使用了多头注意力。让我们回到那句话——“吠叫很可爱,他是一只狗”。在这里,如果我们使用“狗”这个词,从语法上我们理解“吠叫”、“可爱”和“他”应该与“狗”这个词有某种意义或相关性。这些话说,狗的名字叫树皮,是公狗,是一只可爱的狗。仅凭一种注意力机制未必能正确识别出这三个词与“狗”相关,我们可以说,这里用“狗”这个词来表示这三个词更好。这减少了一个注意力查找所有重要单词的负担,也增加了轻松找到更多相关单词的机会。
因此,让我们添加更多的线性层作为键、查询和值。这些线性层是并行训练的,并且彼此具有独立的权重。所以现在,每个值、键和查询都为我们提供了三个输出,而不是一个。这 3 个键和查询现在提供三种不同的权重。然后用矩阵乘以这三个值,得到三个倍数输出。这三个注意力块最终连接起来,给出一个最终的注意力输出。此表示如图 11 所示。
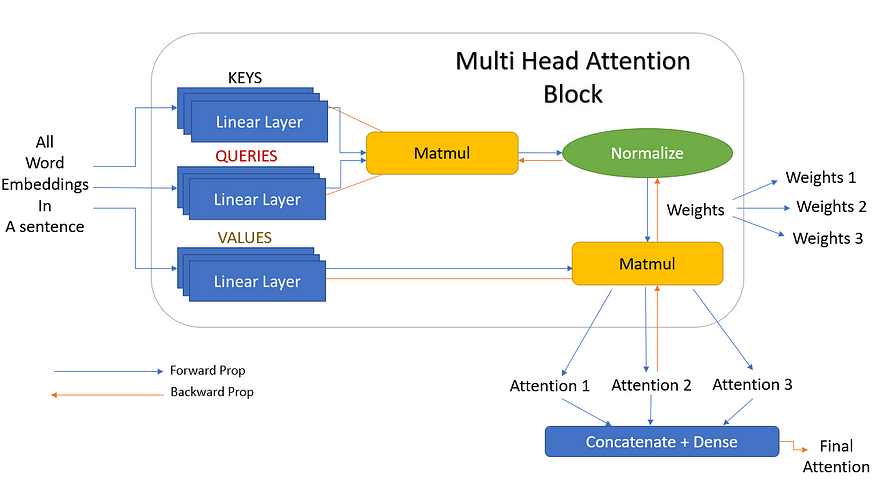
图 11.具有3个线性层的多头注意力(来源:作者创建的图像)
但 3 只是我们选择的随机数。在实际场景中,这些可以是任意数量的线性层,这些层称为头部(h)。也就是说,可以有 h 个线性层,给出 h 个注意力输出,然后将其连接在一起。这正是它被称为多头注意力(多头)的原因。图 11 的简化版本,但头部数量为 h 如图 12 所示。

图 12.具有“h”层的多头注意力(来源:作者创建的图片)
N由于我们了解了注意力、查询、键、值和多头注意力背后的机制和思想,我们已经涵盖了变压器网络的所有重要构建块。在下一个故事中,我将讨论所有这些块如何堆叠在一起形成变压器网络,并讨论一些基于变压器的网络,例如BERT和GPT。
四、引用
阿希什·瓦斯瓦尼、诺姆·沙泽尔、尼基·帕尔马、雅各布·乌什科雷特、莱昂·琼斯、艾丹·戈麦斯、武卡什·凯撒和伊利亚·波洛苏欣。2017. 注意力就是你所需要的一切。第31届神经信息处理系统国际会议论文集(NIPS'17)。Curran Associates Inc.,Red Hook,NY,USA,6000–6010。