GPT系列
GPT(Generative Pre-trained Transformer)是一系列基于Transformer架构的预训练语言模型,由OpenAI开发。以下是GPT系列的主要模型:
-
GPT:GPT-1是于2018年发布的第一个版本,它使用了12个Transformer编码器层和1.5亿个参数。GPT-1的训练数据包括了互联网上的大量文本。
-
GPT-2:GPT-2于2019年发布,是GPT系列的第二个版本。它比GPT-1更大更强大,使用了24个Transformer编码器层和1.5亿到15亿个参数之间的不同配置。GPT-2在生成文本方面表现出色,但由于担心滥用风险,OpenAI最初选择限制了其训练模型的发布。
-
GPT-3:GPT-3于2020年发布,是GPT系列的第三个版本,也是目前最先进和最强大的版本。它采用了1750亿个参数,拥有1750亿个可调节的权重。GPT-3在自然语言处理(NLP)任务中表现出色,可以生成连贯的文本、回答问题、进行对话等。
-
GPT-3.5:GPT-3.5是在GPT-3基础上进行微调和改进的一个变种,它是对GPT-3的进一步优化和性能改进。
GPT系列的模型在自然语言处理领域取得了巨大的成功,并在多个任务上展示出了强大的生成和理解能力。它们被广泛用于文本生成、对话系统、机器翻译、摘要生成等各种应用中,对自然语言处理和人工智能领域的发展有着重要的影响。
GPT系列是当前自然语言处理领域下最流行,也是商业化效果最好的自然语言大模型,并且他的论文也对NLP的领域产生巨大影响,GPT首次将预训练-微调模型真正带入NLP领域,同时提出了多种具有前瞻性的训练方法,被后来的BERT等有重大影响的NLP论文所借鉴。
目录
- GPT系列
- 前言
- Zero-Shot
- 贡献
- GPT-2提出的方法
- 训练数据集
- 输入表示
- 模型架构
前言
BERT的横空出世,利用与GPT相似的思路,使用Transformer编码器训练了更大的模型,得到了比GPT更好的效果,但是GPT的作者Alec Radford仍然坚定Transformer解码器在此类任务中的效果同样好,几个月后发表了GPT-2,Alec Radford训练一个比BERT更大的模型,,但他发现将GPT-1模型在更大的数据集训练一个更大的模型(15亿参数)仍然与BERT模型对比优势不太明显,提到了Zero-Shot的概念(当然这个概念在GPT-1中就提到了,在GPT-2论文将其作为主要卖点)
Zero-Shot
“Zero-shot” 是一个术语,通常用于机器学习和自然语言处理领域。这个术语指的是模型在没有事先接受相关任务的训练数据的情况下执行任务的能力。换句话说,这是模型能够在未见过的情境中进行推理和处理的能力。
在自然语言处理中,zero-shot 学习通常指的是模型能够处理未知词汇或主题的能力。例如,如果一个文本分类模型在训练时没有见过关于某个特定主题的样本,但在测试时却能够正确分类相关文本,那么我们就可以说这个模型具有 zero-shot 学习能力。
这种能力的实现通常涉及到使用预训练的模型,这些模型在大量数据上进行了训练,从而学到了通用的语言和知识表示。这样的模型能够泛化到新领域或任务,即使它们在训练时没有见过相关的数据。
在这篇论文中,Zero-shot指的是在使用GPT来完成一些下游任务的时候,不需要下游任务任何标注的信息,也不需要训练模型,最终他们也得到了一些有说服力的结果。
贡献
我们先说GPT-2的贡献:
我们都知道自然语言处理任务,例如问答、机器翻译、阅读理解和摘要,通常通过对特定任务数据集的监督学习来完成。
作者证明了GPT模型可以在没有任何有标签的数据(也就是上面讲的Zero-shot)进行训练后就可以在多个任务中取得良好的效果。他们在包含数百万个网页(称为 WebText)的新数据集上进行训练时,语言模型开始在没有任何显式监督的情况下学习这些任务。当以文档加问题为条件时,语言模型生成的答案在 CoQA 数据集上达到 55 F1 - 在不使用 127,000 多个训练示例的情况下,匹配或超过 4 个基线系统中的 3 个的性能。语言模型的容量对于零样本任务迁移的成功至关重要,增加它的容量可以提高跨任务的对数线性方式的性能。我们最大的模型 GPT-2 是一个 1.5B 参数 Transformer,它在零样本设置下的 8 个测试语言建模数据集中的 7 个上取得了最先进的结果,但仍然不适合 WebText。模型中的示例反映了这些改进并包含连贯的文本段落。这些发现为构建语言处理系统提供了一条有希望的道路,该系统可以从自然发生的演示中学习执行任务。
GPT-2提出的方法
下面我们讲讲GPT-2做了什么事情:
GPT团队有很大野心,他们认为自己开发的通用系统框架应该能够执行不同的任务,即使对于相同的输入,它不仅以输入为条件,也要以执行的任务为条件。简单来说我们知道一般的语言模型都基于下面的公式:
P
(
输出
∣
输入
)
P(输出|输入)
P(输出∣输入)
但是GPT-2对于下面的公式建模:
P
(
输出
∣
输入
,
任务
)
P(输出|输入,任务)
P(输出∣输入,任务)
举个例子:
对于翻译任务,训练集的形式应为如下:
( 翻译为法语 , 中文文本 , 法语文本 ) (翻译为法语, 中文文本,法语文本) (翻译为法语,中文文本,法语文本)
对于阅读理解的任务,训练集的形式应为如下:
( 回答问题 , 段落 , 问题 , 答案 ) (回答问题,段落,问题,答案) (回答问题,段落,问题,答案)
训练数据集
一般以任务为驱动的模型训练都是基于一个特定领域的数据集上的,但是GPT想要做的是通用的模型,所以在数据集上,他们选择的是网络爬虫。
GPT团队创建了一个强调文档质量的新的网页抓取方法。为了做到这一点,他们只抓取了经人工筛选/过滤的网页。手动筛选完整的网页抓取将非常昂贵,因此作为起点,我们抓取了所有来自社交媒体平台Reddit的外部链接,这些链接至少获得了3个赞(karma)。这可以被视为一个启发式指标,用于判断其他用户是否认为该链接有趣、有教育意义或仅仅是好笑的。
简单介绍一下Reddit:
Reddit是一个社交新闻聚合、讨论和内容分享的网站。它是由史蒂夫·霍夫曼(Steve Huffman)和亚伦·斯沃茨(Aaron Swartz)于2005年创建的。Reddit的用户可以在各种主题的论坛(称为"subreddit")上发布文本、链接、图像和视频等内容,并与其他用户进行讨论和互动。
利用上面的方法抓取出了4500万个链接,GPT团队获取其HTML响应,经过一些预处理后,提出其中有自然语言意义的内容,创建了WebText数据集,它包含超过800万个文档,总共40GB的文本。
论文中给出在WebText数据集中部分有关法语和英语翻译的自然发生的演示示例:

输入表示
GPT团队认为:通用语言模型(LM)应该能够计算(并生成)任何字符串的概率。当前的大规模 LM 包括预处理步骤,例如小写、标记化和词汇表外标记,这些步骤限制了可建模字符串的空间。
字节对编码(Byte Pair Encoding,简称BPE)是一种介于字符级和词级语言建模之间的实用方法,它有效地在常见符号序列使用词级输入,在不常见符号序列使用字符级输入之间进行插值。尽管其名称中包含"byte"(字节),但参考的BPE实现通常是基于Unicode代码点而不是字节序列进行操作的。为了对所有Unicode字符串进行建模,这些实现需要包含完整的Unicode符号空间。这将导致基本词汇量超过130,000个,在添加任何多符号标记之前就已经非常庞大。相比之下,通常使用BPE的标记词汇量为32,000到64,000个,这是可以接受的范围。
与此相反,字节级的BPE版本只需要一个大小为256的基本词汇表。然而,直接将BPE应用于字节序列会导致合并的次优选择,因为BPE使用基于频率的贪心启发式方法来构建标记词汇表。我们观察到BPE会包含许多常见单词的多个变体,比如dog、dog!、dog?、dog.等。这导致词汇表有限的位置和模型容量分配不够优化。为了避免这种情况,我们阻止BPE在任何字节序列中跨字符类别进行合并。我们对空格(space)做了一个例外,这显著提高了压缩效率,同时只对一些单词在多个词汇标记之间进行了最小程度的分割。
这种输入表示使我们能够将字级 LM 的经验优势与字节级方法的通用性结合起来。由于我们的方法可以为任何 Unicode 字符串分配概率,因此这使我们能够在任何数据集上评估 LM,而不管预处理、标记化或词汇大小如何。
模型架构
GPT-2模型很大程度上遵循 OpenAI GPT-1模型的细节,。对于GPT-1的架构,这里我们不过多介绍,只放出架构图供读者复习,想了解具体的细节请看之前文章:点击此处
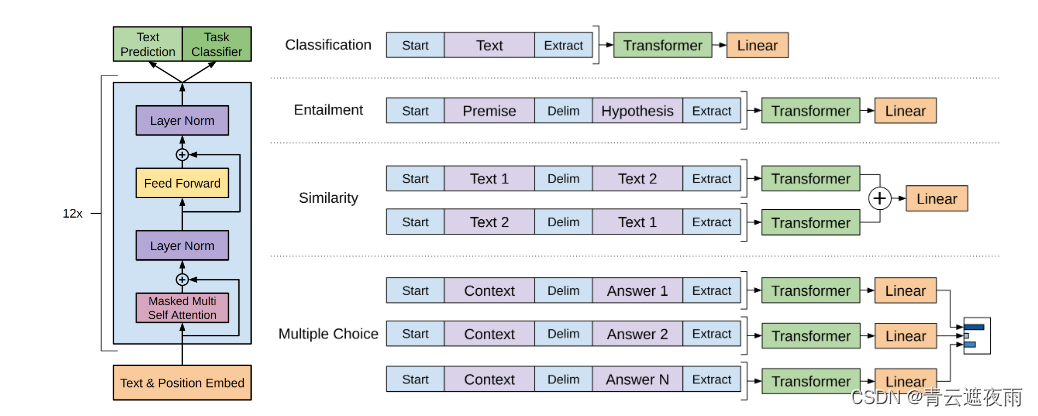
有如下的细节调整:
- 层归一化(Ba et al., 2016)被移至每个子块的输入,类似于预激活残差网络。
- 在最终的自注意力块之后添加了额外的层归一化。
- 使用了修改后的初始化,该初始化考虑了残差路径上随模型深度的累积。我们在初始化时将残差层的权重缩放为 1 / N 1/\sqrt{N} 1/N,其中 N 是残差层的数量。词汇量扩大到50,257个。我们还将上下文大小从 512 个标记增加到 1024 个标记,并使用更大的批量大小 512。
以上就是所有GPT-2的改动,看似改动不大,但是它却奠定了整个LLM的发展方向,给出了自然语言通用架构的解决方法,并设计了超大高质量的自然语言模型无监督训练数据集,论文主要在讨论在没有给出明确任务的情况下,使用大量语料训练出来的语言模型不需要额外的微调,也可以完成许多自然语言任务,得到比较满意的结果。
![[极客大挑战 2019]FinalSQL - 异或盲注](https://img-blog.csdnimg.cn/85c921ec7b414127b7ff7a691c76c142.png)
![[CISCN 2019华北Day2]Web1 - 布尔盲注](https://img-blog.csdnimg.cn/4f322eb6651d4f81a554ab475e74e5cd.png)

![[GXYCTF2019]禁止套娃 无回显 RCE 过滤__FILE__ dirname等](https://img-blog.csdnimg.cn/dd03457a238e4220bb64d03848383733.png)
![[图论]哈尔滨工业大学(哈工大 HIT)学习笔记23-31](https://img-blog.csdnimg.cn/15079b8ae58545e5afd9f5fd5abf8b0c.png)