Redis Stream
Redis Stream 是 Redis 5.0 版本新增加的数据结构。
Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。
简单来说发布订阅 (pub/sub) 可以分发消息,但无法记录历史消息。
而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
Redis Stream 的结构如下所示,它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容:
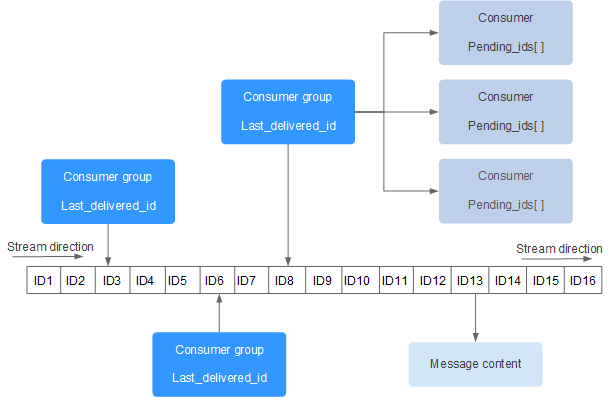
每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消息时自动创建。
上图解析:
- Consumer Group :消费组,使用 XGROUP CREATE 命令创建,一个消费组有多个消费者(Consumer)。
- last_delivered_id :游标,每个消费组会有个游标 last_delivered_id,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。
- pending_ids :消费者(Consumer)的状态变量,作用是维护消费者的未确认的 id。 pending_ids 记录了当前已经被客户端读取的消息,但是还没有 ack (Acknowledge character:确认字符)。
消息队列相关命令:
- XADD - 添加消息到末尾
- XTRIM - 对流进行修剪,限制长度
- XDEL - 删除消息
- XLEN - 获取流包含的元素数量,即消息长度
- XRANGE - 获取消息列表,会自动过滤已经删除的消息
- XREVRANGE - 反向获取消息列表,ID 从大到小
- XREAD - 以阻塞或非阻塞方式获取消息列表
消费者组相关命令:
- XGROUP CREATE - 创建消费者组
- XREADGROUP GROUP - 读取消费者组中的消息
- XACK - 将消息标记为"已处理"
- XGROUP SETID - 为消费者组设置新的最后递送消息ID
- XGROUP DELCONSUMER - 删除消费者
- XGROUP DESTROY - 删除消费者组
- XPENDING - 显示待处理消息的相关信息
- XCLAIM - 转移消息的归属权
- XINFO - 查看流和消费者组的相关信息;
- XINFO GROUPS - 打印消费者组的信息;
- XINFO STREAM - 打印流信息
XADD
使用 XADD 向队列添加消息,如果指定的队列不存在,则创建一个队列,XADD 语法格式:
XADD key ID field value [field value ...]
- key :队列名称,如果不存在就创建
- ID :消息 id,我们使用 * 表示由 redis 生成,可以自定义,但是要自己保证递增性。
- field value : 记录。
实例
redis> XADD mystream * name Sara surname OConnor
"1601372323627-0"
redis> XADD mystream * field1 value1 field2 value2 field3 value3
"1601372323627-1"
redis> XLEN mystream
(integer) 2
redis> XRANGE mystream - +
1) 1) "1601372323627-0"
2) 1) "name"
2) "Sara"
3) "surname"
4) "OConnor"
2) 1) "1601372323627-1"
2) 1) "field1"
2) "value1"
3) "field2"
4) "value2"
5) "field3"
6) "value3"
redis>
XTRIM
使用 XTRIM 对流进行修剪,限制长度, 语法格式:
XTRIM key MAXLEN [~] count
- key :队列名称
- MAXLEN :长度
- count :数量
实例
127.0.0.1:6379> XADD mystream * field1 A field2 B field3 C field4 D
"1601372434568-0"
127.0.0.1:6379> XTRIM mystream MAXLEN 2
(integer) 0
127.0.0.1:6379> XRANGE mystream - +
1) 1) "1601372434568-0"
2) 1) "field1"
2) "A"
3) "field2"
4) "B"
5) "field3"
6) "C"
7) "field4"
8) "D"
127.0.0.1:6379>
redis>
XDEL
使用 XDEL 删除消息,语法格式:
XDEL key ID [ID ...]
- key:队列名称
- ID :消息 ID
实例
> XADD mystream * a 1
1538561698944-0
> XADD mystream * b 2
1538561700640-0
> XADD mystream * c 3
1538561701744-0
> XDEL mystream 1538561700640-0
(integer) 1
127.0.0.1:6379> XRANGE mystream - +
1) 1) 1538561698944-0
2) 1) "a"
2) "1"
2) 1) 1538561701744-0
2) 1) "c"
2) "3"
XLEN
使用 XLEN 获取流包含的元素数量,即消息长度,语法格式:
XLEN key
- key:队列名称
实例
redis> XADD mystream * item 1
"1601372563177-0"
redis> XADD mystream * item 2
"1601372563178-0"
redis> XADD mystream * item 3
"1601372563178-1"
redis> XLEN mystream
(integer) 3
redis>
XRANGE
使用 XRANGE 获取消息列表,会自动过滤已经删除的消息 ,语法格式:
XRANGE key start end [COUNT count]
- key :队列名
- start :开始值, - 表示最小值
- end :结束值, + 表示最大值
- count :数量
实例
redis> XADD writers * name Virginia surname Woolf
"1601372577811-0"
redis> XADD writers * name Jane surname Austen
"1601372577811-1"
redis> XADD writers * name Toni surname Morrison
"1601372577811-2"
redis> XADD writers * name Agatha surname Christie
"1601372577812-0"
redis> XADD writers * name Ngozi surname Adichie
"1601372577812-1"
redis> XLEN writers
(integer) 5
redis> XRANGE writers - + COUNT 2
1) 1) "1601372577811-0"
2) 1) "name"
2) "Virginia"
3) "surname"
4) "Woolf"
2) 1) "1601372577811-1"
2) 1) "name"
2) "Jane"
3) "surname"
4) "Austen"
redis>
XREVRANGE
使用 XREVRANGE 获取消息列表,会自动过滤已经删除的消息 ,语法格式:
XREVRANGE key end start [COUNT count]
- key :队列名
- end :结束值, + 表示最大值
- start :开始值, - 表示最小值
- count :数量
实例
redis> XADD writers * name Virginia surname Woolf
"1601372731458-0"
redis> XADD writers * name Jane surname Austen
"1601372731459-0"
redis> XADD writers * name Toni surname Morrison
"1601372731459-1"
redis> XADD writers * name Agatha surname Christie
"1601372731459-2"
redis> XADD writers * name Ngozi surname Adichie
"1601372731459-3"
redis> XLEN writers
(integer) 5
redis> XREVRANGE writers + - COUNT 1
1) 1) "1601372731459-3"
2) 1) "name"
2) "Ngozi"
3) "surname"
4) "Adichie"
redis>
XREAD
使用 XREAD 以阻塞或非阻塞方式获取消息列表 ,语法格式:
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...]
- count :数量
- milliseconds :可选,阻塞毫秒数,没有设置就是非阻塞模式
- key :队列名
- id :消息 ID
实例
# 从 Stream 头部读取两条消息
> XREAD COUNT 2 STREAMS mystream writers 0-0 0-0
1) 1) "mystream"
2) 1) 1) 1526984818136-0
2) 1) "duration"
2) "1532"
3) "event-id"
4) "5"
5) "user-id"
6) "7782813"
2) 1) 1526999352406-0
2) 1) "duration"
2) "812"
3) "event-id"
4) "9"
5) "user-id"
6) "388234"
2) 1) "writers"
2) 1) 1) 1526985676425-0
2) 1) "name"
2) "Virginia"
3) "surname"
4) "Woolf"
2) 1) 1526985685298-0
2) 1) "name"
2) "Jane"
3) "surname"
4) "Austen"
XGROUP CREATE
使用 XGROUP CREATE 创建消费者组,语法格式:
XGROUP [CREATE key groupname id-or-$] [SETID key groupname id-or-$] [DESTROY key groupname] [DELCONSUMER key groupname consumername]
- key :队列名称,如果不存在就创建
- groupname :组名。
- $ : 表示从尾部开始消费,只接受新消息,当前 Stream 消息会全部忽略。
从头开始消费:
XGROUP CREATE mystream consumer-group-name 0-0
从尾部开始消费:
XGROUP CREATE mystream consumer-group-name $
XREADGROUP GROUP
使用 XREADGROUP GROUP 读取消费组中的消息,语法格式:
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
- group :消费组名
- consumer :消费者名。
- count : 读取数量。
- milliseconds : 阻塞毫秒数。
- key : 队列名。
- ID : 消息 ID。
XREADGROUP GROUP consumer-group-name consumer-name COUNT 1 STREAMS mystream >







![[架构之路-230]:计算机硬件与体系结构 - 可靠性、可用性、稳定性;MTTF、MTTR、MTBF](https://img-blog.csdnimg.cn/7f3a36c73b134a8f9f8763ee01450773.png)