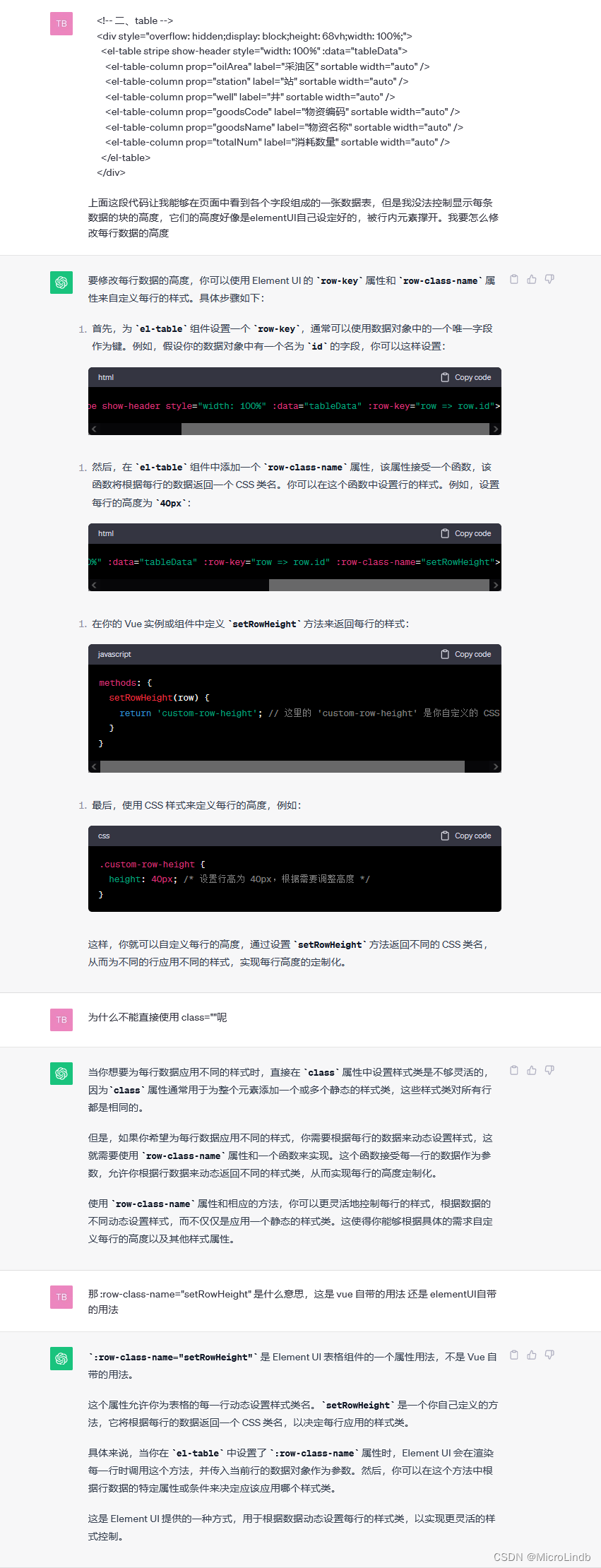
新的冷热数据方案是在整合了存算分离模型的基础上建立的,其核心思路是:DORIS本地存储作为热数据的载体,而外部集群(HDFS、S3等)作为冷数据的载体。数据在导入的过程中,先作为热数据存在,存储于BE节点的本地磁盘上。当数据需要转冷的时候,为该热数据分片创建一个冷数据的副本分片,然后将数据转储到冷数据指定的外部集群上,当冷数据副本生成完毕后,将热数据分片删除。
如下图所示,当数据变为冷数据后,BE本地将保留一个冷数据的元数据信息。当查询命中冷数据时,BE将通过这个元数据信息将冷数据缓存到本地使用。
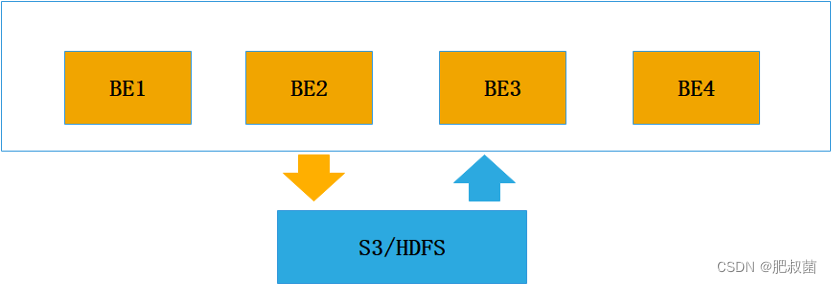
对于冷数据,其使用的频率是很低的,这样可以做到使用有限的BE节点来管理更多的数据,成本将远远低于纯本地存储的方案。
冷热数据转换规则 StoragePolicy 由 FE 的 PolicyMgr 进行管理,用来配置冷热数据的转换规则。该信息会随着心跳同步给每一个 BE(refreshStoragePolicy()),BE 将以此作为数据进行冷热数据转换的依据。
根据用户的使用习惯,以及数据的业务特性,冷热数据转换规则可分为两类:
第一类:明确指定冷却时间点:有些数据拥有时间特性,前一年的数据在后一年就已经失去了时效性,这种数据通过指定具体的时间来界定其转为冷数据的时间。
第二类:根据活跃时间指定数据冷却时间:有些数据有着固定的活跃时间,比如用户行为数据,每月生成的用户行为数据在当月是使用最频繁的,而随着时间的推移,这些数据的重要性逐步降低,最终转为不活跃数据。这种情况下可以对数据指定活跃时间,当数据活跃时间结束后,该数据转为冷数据。
冷热数据的调度流程,是从 TABLE 的冷热数据配置信息开始。在建表时指定所要使用的冷热数据规则名(storage_policy),映射为 StoragePolicy。
CREATE TABLE (
……
) PROPERTIES (
"storage_policy" = "storage_policy_name1"
);
上面的配置,可以为整个表指定冷热数据规则,而大多数情况下,我们的数据是拆分成多个PARTITION的,每个PARTITION所需要的冷热数据规则有可能是不同的,这时就需要针对PARTITION来进行配置:
ALTER TABLE TblPxy01 ADD PARTITION
p2 VALUES [("10000"), ("20000"))
("remote_storage_policy" = "testPolicy");
配置中的 storage_policy 信息存放在 PARTITION 的每个TABLET中,当创建及修改TABLET时,storage_policy 信息随着TABLET下发给 BE,由 BE 来判断该 TABLET 何时可以开始进行冷热数据转换。
冷热数据转换守护进程 cooldown_tasks_producer_thread 是 BE 的一条守护进程,其对本 BE 的所有存活的TABLET进行遍历,检查每个TABLET的配置信息。当发现该 TABLET 配置了 storage_policy,说明需要对其进行冷热数据转换。
根据 storage_policy 中的配置,BE 将从缓存信息中的 StoragePolicy 列表中获取对应的规则信息,然后根据这个规则,判断当前tablet是否需要进行冷热数据转换,将数据存放于远程存储集群上(如S3)。
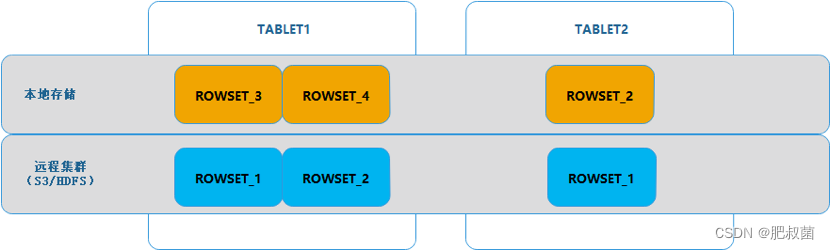
BE在存储TABLET数据的时候,TABLET下面还会有 ROWSET 和 SEGMENT 的划分。其中 ROWSET 代表着数据导入批次,同一个ROWSET 一般代表着一个批次的导入任务,比如一次 stream load,一个 begin/commit 事务等,都对应一个 ROWSET,ROWSET 的这种特性,意味着其具有着事务的特点,即是说,同一个rowset可以作为一个独立的数据单元存在,其中的数据要么全部有效,要么全部无效。
正因为如此,以 ROWSET 为基本单元对数据进行冷热转换,可以更容易的解决冷热数据迁移过程中有新数据写入的问题。
如下图所示,对于进入冷热数据转换状态的 TABLET,其 ROWSET 被分成两部分。
一部分在本地,这部分数据往往是新写入的数据,还未触发上传操作。
另一部分在远程存储集群(S3/HDFS),这部分数据相对较早,是在此前已经触发上传到了存储集群上的数据。
两部分合在一起才是完整的一个 TABLET。
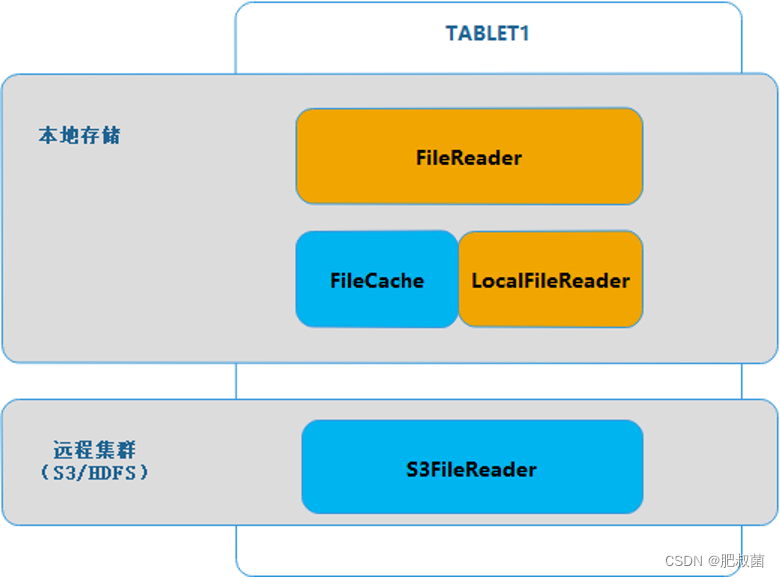
当冷数据需要读取的时候,由于数据已经被拆分成了两部分,需要从本地和远程存储集群(S3/HDFS)上分别读取数据。
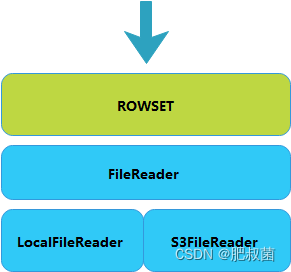
在数据读写中,IO 层将远程文件与本地文件抽象出 FileReader、FileWriter 层,将远程数据的读写与本地数据的读写统一,实现了最基本的冷热数据读写能力。
如下图所示,本地文件和远程文件的读取被封装成了一个跟 FileReader 的虚基类,实现两个派生类 LocalFileReader 和 S3FileReader,分别对应本地文件读取与 S3 文件读取。当有读取请求到达 TABLET 时,TABLET会根据条件找到对应的ROWSET,这些 ROWSET 有些是本地存储,有些是远程存储(S3)。通过映射关系,ROWSET 找到各自的 FileReader,完成数据读取,合并后即是完整的TABLET数据。
在这里,远程数据文件为了保证读取效率,可以有多种优化的方向,比如加一层本地缓存,比如使用本地索引等。这些在后续文章中详细说明。
与冷数据读取相似,冷数据写入也封装了一个 FileWriter 虚基类,如下图所示:
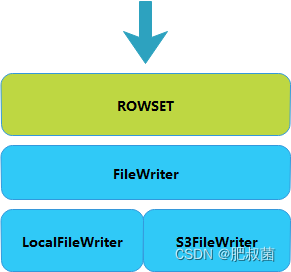
新写入的数据会在TABLET的本地存储部分新增一个ROWSET,这与普通的TABLET相同,也保证了冷数据也可写入的特性。而这部分写入到本地的数据在某个时间点会与远程的冷数据进行合并,并上传到远程存储集群。这一步骤则是由前文提到的守护进程 cooldown_tasks_producer_thread来 完成的。
FileCache 即是冷数据在本地的缓存层,其是远程数据在本地的镜像,当访问的Segment 是冷数据(存储在远程集群)时,会触发生成缓存层,将远程数据拉取到本地,生成缓存文件。这样在下一次访问时,可以直接读取缓存文件,而不需要从远程集群上拉取数据。
当一个查询请求到来时,SQL 被解析并重组成 PlanFragment ,通过元数据指定到 BE 里的Tablet 上,而 Tablet 本身是由多个 Segment 组成。当访问的 Segment 是热数据(本地文件)时,直接读取本地文件即可;当访问的 Segment 是冷数据(远程文件)时,直接读取远程文件代价是较高的,这时就会触发缓存机制,生成缓存文件。
缓存文件是远程文件的映射,缓存文件中每一条数据,在远程文件上都有对应的存在。但是这并不说缓存文件就等于是远程文件,两者之间是存在区别的。这是因为:
远程文件一般是比较大的,将这么大的文件整个拉取到本地的代价很高,反而会影响到查询的效率。
查询请求在下推时,往往只是读取Segment其中一部分数据,比如在 Select * from Table limit
1 这样的请求中,需要使用的往往只是其中几 KB 的数据,这时将几 GB 大小的文件全部拉到本地反而会增加不必要的时间开销。
同一个 Segment 中的缓存数据也存在着使用频率的差异,有可能只是 Segment 其中的一小部分数据被经常使用,当需要清理缓存数据时,我们更希望将使用不频繁的数据清除。
正因为如此,缓存文件采取了文件切割的方式,也即是说,远程的文件会被拆分成几个相对较小的子文件存放在本地作为缓存。当对 Segment 进行读取的时候,该请求会定位到远程文件指定位置的数据( offset +
length ),缓存机制将从远程文件中切分一部分出来,作为子文件写入到本地的缓存目录下。

根据缓存文件的重要性、磁盘的容量情况等,缓存文件的清理分成以下几种策略:
缓存文件在生成之后的一段时间内,用户再次访问该段数据的可能性是最高的,因此这时也是缓存数据最活跃的时期。随着时间的推移,用户访问该数据的可能性变小。当用户有较长的一段时间未访问时,该数据已经不活跃,即可对其进行清理。
BE 中使用 CacheManager 来对这些缓存进行管理,当用户的查询触发并生成了 Cache 文件时,这些 Cache 文件会注册到 CacheManager 中。
最后活跃时间是用于检查的重要指标,每当一个 Cache 被访问到时,其最后活跃时间即会更新,代表着该 Cache 近期有活跃动作。
CacheManager 会定时检查这些缓存文件的最后活跃时间,当某些 Cache 的最后活跃时间较早时,代表着该 Cache 已经不再活跃,CacheManager 将对这些 Cache 进行清除。
缓存文件占用的是本地磁盘空间。当占用的空间足够大的时候,可能会影响本地文件的读写,这就需要对这些缓存文件进行清理。
当缓存文件较多时,很可能很多缓存文件并没有达到活跃时间的阈值,而这时候其占用的磁盘空间已经过大了,这就需要提前将这些文件进行清理。
清理的时候,将缓存文件按最后活跃时间分成几个批次,从较早的文件开始,按时间逐步清理,直到降低到指定的磁盘占用空间上限。
由于BE本身有可能出现重启、IO 异常等情况,缓存文件也可能生成一些垃圾文件。例如:文件写到一半时 IO 异常、文件生成过程中BE重启等。这些文件并不处在 CacheManager 的管理之中,为了保证缓存层的干净,需要定期对这些文件进行清理。
由于在原本的逻辑中 Tablet 层已经有了一个垃圾文件清理的模块,会清理异常的 Tablet 。因此,缓存层的清理不需要再关注那些异常的 Tablet ,只需要关注 TabletManager 中管理的Tablet 即可。
缓存层垃圾清理对 TabletManager 中的 Tablet 目录进行遍历,查询每一个缓存目录,检查其是否在 CacheManager 中已经注册。如果在 CacheManager 中已经存在,这些 Cache 就不是垃圾文件,可以通过前面的两种缓存清理策略进行清理。如果在 CacheManager 中不存在,这些 Cache 则有可能是垃圾缓存,这时需要检查这些缓存文件的生成时间,根据生成时间来决定是否删除。
![[架构之路-228]:计算机硬件与体系结构 - 硬盘存储结构原理:如何表征0和1,即如何存储0和1,如何读数据,如何写数据(修改数据)](https://img-blog.csdnimg.cn/img_convert/ec8a420edd3c717b8212414255d52239.png)






![[架构之路-229]:计算机体硬件与系结构 - 计算机系统的矩阵知识体系结构](https://img-blog.csdnimg.cn/badf170c603942368ece3b5374cf9632.png)