前言
AI换脸是指利用基于深度学习和计算机视觉来替换或合成图像或视频中的人脸。可以将一个人的脸替换为另一个人的脸,或者将一个人的表情合成到另一个人的照片或视频中。算法常常被用在娱乐目上,例如在社交媒体上创建有趣的照片或视频,也有用于电影制作、特效制作、人脸编辑工具和虚拟现实。但也有可能被滥用,用于欺骗、虚假信息传播或隐私侵犯。
随着AI换脸技术的广泛应用,这也引起很多的关注和担忧,因为它可以用于制造虚假的视频内容,可能导致社会和政治问题。AI换脸技术也会引发法律和伦理问题,包括隐私问题和身份验证问题。滥用这些技术可能导致个人的声誉受损,也可能用于欺骗和诈骗。
AI换脸技术不断发展,变得越来越先进的同时,也有研究人员和技术公司努力开发检测和防御AI换脸的方法,以应对滥用和虚假信息传播的问题。
这里结合实现了一些常用的AI换脸技术,从人脸检测到人脸关键点检测,再到AI换脸,然后使用算法进行人脸修复和超分,以便大家更好的了解AI换脸这个智能算法,只能全面的理解才能做到更好的防范。
一、AI换脸预处理
1.人脸检测
做人脸相关处理工作,首先需要获取图像或者视频中的人脸以及坐标,会用于人脸检测相关的算法,人脸检测算法提供人脸位置的矩形框
。以下是一些常用的人脸检测算法:
- Viola-Jones算法:Viola-Jones算法是一种经典的人脸检测算法,基于Haar特征和级联分类器。它具有快速的检测速度,通常用于实时应用。
- 卷积神经网络(CNN):深度学习中的卷积神经网络在人脸检测方面取得了显著的进展。许多现代的人脸检测器,如MTCNN(多任务卷积神经网络)和SSD(单发多框检测器),使用CNN来检测人脸。
- HOG特征和支持向量机(SVM):HOG(方向梯度直方图)特征通常与SVM分类器结合使用,用于人脸检测。这种方法在处理不同光照和尺度条件下的人脸时表现良好。
- 深度学习模型:一些基于深度学习的人脸检测器,如YOLO(You Only Look Once)和Faster R-CNN(区域卷积神经网络),已经被广泛应用于目标检测领域,包括人脸检测。
- 级联分类器:级联分类器是一种组合多个弱分类器的方法,以提高人脸检测的准确性。这种方法被Viola-Jones算法采用,以及其他一些基于AdaBoost的方法。
- 3D人脸检测:除了2D人脸检测,还存在用于检测和识别3D人脸的算法,这些算法通常使用深度传感器或多视角摄像头。
通常轮廓点检测也被称为 Face Alignment。本文的AI换脸实现就是建立在68个人脸轮廓点(Landmarks)的基础之上。而 Face Alignment 必须依赖一个人脸检测器,即 Face Detection。也就是说,本文所介绍的换脸或者其他精细化人脸操作的基础是 Face Detection + Face Alignment。但是,这两个技术并不需要我们亲自开发,dlib已经提供了效果不错、使用简便的第三方库。

2. 人脸关键特征点
人脸图像中的关键特征点(face-landmark),例如眼睛、鼻子、嘴巴、脸颊等。这些特征点通常用于面部识别、表情分析、面部姿势估计等应用。以下是一些常用的人脸关键点检测算法:
Dlib:Dlib 是一个流行的 C++ 库,提供了高效的人脸关键点检测功能。它使用了一种基于 HOG 特征的级联分类器,并使用回归方法来预测关键点位置。Dlib 还提供了 Python 绑定,因此可以方便地用于 Python 环境。
OpenCV:OpenCV 是一个广泛使用的计算机视觉库,它包含了一些用于人脸关键点检测的功能。OpenCV 的面部关键点检测器通常基于级联分类器和形状模型。
Face++:Face++ 是一个商业化的人脸识别平台,提供了人脸关键点检测服务。它使用深度学习技术,包括卷积神经网络(CNN),来检测和定位面部关键点。
dlib + 预训练模型:除了 Dlib 库本身,还可以使用预训练的深度学习模型,例如基于 TensorFlow 或 PyTorch 的模型,来进行面部关键点检测。这些模型通常在大规模数据集上进行训练,能够更准确地检测面部关键点。
MediaPipe Face Detection:Google 的 MediaPipe 框架提供了一种用于实时面部关键点检测的解决方案。它使用了深度学习模型来检测人脸并估计关键点位置,可用于实时应用和移动设备上的部署。
68-Point Facial Landmarks Model:这是一个常见的面部关键点检测模型,它能够检测到脸部的 68 个关键点,包括眼睛、嘴巴、鼻子、脸颊等部位。这种模型通常使用深度学习方法构建。

二、InsightFace算法
1、算法简介
InsightFace算法是一种用于人脸分析和识别任务的深度学习模型,它主要侧重于人脸识别和人脸验证。InsightFace是一个用于2D和3D人脸分析的集成Python库。 InsightFace 有效地实现了各种最先进的人脸识别、人脸检测和人脸对齐算法,并针对训练和部署进行了优化。它支持一系列主干架构,包括 IResNet、RetinaNet、MobileFaceNet、InceptionResNet_v2 和 DenseNet。 除了模型之外,它还可以使用 MS1M、VGG2 和 CASIA-WebFace 等面部数据集。InsightFace算法的基本解析:
骨干网络(Backbone Networks):InsightFace使用深度卷积神经网络(CNN)作为骨干网络,用于从输入图像中提取人脸特征。通常情况下,ResNet和MobileNet等网络结构被用作骨干网络,但InsightFace也支持其他网络结构。
ArcFace损失(ArcFace Loss):InsightFace的一个显著特点是在训练过程中使用ArcFace损失函数。ArcFace损失函数旨在增强特征嵌入的区分能力,使其适用于人脸识别任务。它通过在嵌入空间中对类别之间引入边界(margin)来实现,从而更好地区分不同的身份。
有效的训练(Efficient Training):InsightFace以高效的训练过程著称,包括大规模人脸识别和数据增强等技术。这些方法有助于提高模型的性能,特别是在处理大规模数据集时。
预训练模型(Pretrained Models):InsightFace提供了预训练模型,使开发人员能够轻松开始进行人脸识别任务,而无需从头开始训练模型。这些预训练模型经过大规模的人脸数据集训练,可以用于特定应用的微调。
开源(Open Source):InsightFace是一个开源框架,这意味着开发人员可以访问其代码库,并根据自己的需求进行定制。这导致了一个繁荣的研究和开发社区,不断为其发展做出贡献。
各种应用(Various Applications):InsightFace不仅仅可以用于基本的人脸识别,还可以应用于更广泛的任务,如情感分析、年龄估计、性别分类和人脸属性识别等。
2. 算法优势
InsightFace具有许多优势,使其在人脸识别和相关任务中备受欢迎。以下是InsightFace的主要优势总结:
高精度:InsightFace以其强大的深度学习模型和ArcFace损失函数而闻名,这使得其在人脸识别和人脸验证任务中能够实现高精度的识别结果。
高效性:InsightFace采用了有效的训练技巧,包括大规模人脸识别和数据增强,这有助于提高模型的性能并减少训练时间。
预训练模型:InsightFace提供了预训练模型,使开发人员可以快速开始人脸识别项目,无需从头开始训练模型。这提高了开发效率。
灵活性:InsightFace是一个开源框架,开发人员可以根据自己的需求进行自定义。这意味着它可以适应各种人脸分析任务和应用领域。
多用途:除了基本的人脸识别和验证,InsightFace还可以用于其他多种应用,如情感分析、年龄估计、性别分类和人脸属性识别等。
大规模支持:InsightFace具备处理大规模数据集的能力,因此适用于需要大量训练数据的项目,如人脸识别在大型身份数据库中的应用。
社区支持:由于是开源项目,InsightFace有一个积极的社区,不断贡献代码、文档和改进,使其保持活跃和更新。
强调隐私和安全:InsightFace的使用者可以自己加强安全和隐私措施,以确保合规性和数据保护。
3.算法概述
InsightFace提供用于深度识别的训练数据,网络设置和损失设计。 训练数据包括标准化的 MS1M,VGG2 和 CASIA-Webface 数据集,这些数据集已经以 MXNet 二进制格式打包。 网络主干包括 ResNet,MobilefaceNet,MobileNet,InceptionResNet_v2,DenseNet,DPN。 损失函数包括 Softmax,SphereFace,CosineFace,ArcFace 和 Triplet(Euclidean / Angular)Loss。
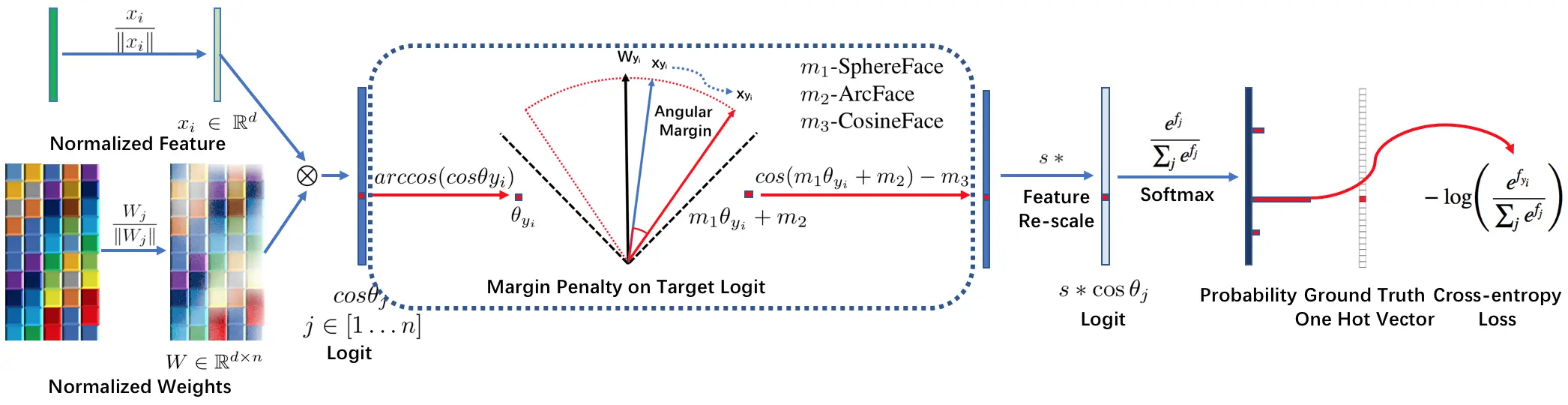
InsightFace的方法 ArcFace 最初在 arXiv 技术报告中描述。 通过使用此存储库,可以通过单个模型简单地实现 LFW 99.80%+ 和 Megaface 98%+。
3. 使用InsightFace实现人脸属性分析
import os
import cv2
import insightface
from sklearn import preprocessing
import numpy as np
import onnxruntime
from sklearn.metrics.pairwise import cosine_similarity, paired_distances
import gradio as gr
class DisposeFace:
def __init__(self,face_db,gpu_id=0, threshold=1.24,
det_thresh=0.50, det_size=(640, 640)):
self.gpu_id = gpu_id
self.threshold = threshold
self.det_thresh = det_thresh
self.det_size = det_size
self.face_db = face_db
# 初始化模型
providers = onnxruntime.get_available_providers()
self.face_model = insightface.app.FaceAnalysis(
name="buffalo_l", root="checkpoints", allowed_modules=None, providers=providers)
self.face_model.prepare(ctx_id=self.gpu_id, det_thresh=self.det_thresh, det_size=self.det_size)
# 人脸库的人脸特征
self.faces_embedding = list()
# # 加载人脸库中的人脸
self.load_db_faces(self.face_db)
def load_model(self):
return self.face_model
def load_db_faces(self,face_db_path):
if not os.path.exists(face_db_path):
os.makedirs(face_db_path) #创建人脸数据库
for root,dirs,files in os.walk(face_db_path):
for file in files:
input_image = cv2.imdecode(np.fromfile(os.path.join(root, file), dtype=np.uint8), 1)
user_name = file.split(".")[0]
face = self.face_model.get(input_image)[0]
embedding = np.array(face.embedding).reshape((1, -1))
embedding = preprocessing.normalize(embedding)
self.faces_embedding.append({
"user_name": user_name,"feature": embedding})
def detect_face(self,cv_src):
faces = self.face_model.get(cv_src)
faces_results = list()
for face in faces:
result = dict()
#获取人脸属性
result["bbox"] = np.array(face.bbox).astype(np.int32).tolist()
result["kps"] = np.array(face.kps).astype(np.int32).tolist()
result["landmark_3d_68"] = np.array(face.landmark_3d_68).astype(np.int32).tolist()
result["landmark_2d_106"] = np.array(face.landmark_2d_106).astype(np.int32).tolist()
result["pose"] = np.array(face.pose).astype(np.int32).tolist()
result["age"] = face.age
gender = 'man'
if face.gender == 0:
gender = 'female'
result["gender"] = gender
#人脸识别
embedding = np.array(face.embedding).reshape((1, -1))
embedding = preprocessing.normalize(embedding)
result["embedding"] = embedding
faces_results.append(result)
return faces_results
@staticmethod
def feature_compare(feature1, feature2, threshold):
diff = np.subtract(feature1, feature2)
dist = np.sum(np.square(diff), 1)
if dist < threshold:
return True
else:
return False
def face_recognition(self,cv_src):
faces = self.face_model.get(cv_src)
face_results = list()
for face in faces:
# 开始人脸识别
embedding = np.array(face.embedding).reshape((1, -1))
embedding = preprocessing.normalize(embedding)
user_name = "unknown"
for com_face in self.faces_embedding:
result = self.feature_compare(embedding,com_face["feature"],self.threshold)
if result:
user_name = com_face["user_name"]
face_results.append(user_name)
return face_results
def recognition(self,cv_face1,cv_face2):
faces1 = self.face_model.get(cv_face1)
faces2 = self.face_model.get(cv_face2)
if len(faces1) != 1 and len(faces2) != 1:
return "No face detected or multiple faces detected!"
embedding1 = np.array(faces1[0].embedding).reshape






![[架构之路-229]:计算机体硬件与系结构 - 计算机系统的矩阵知识体系结构](https://img-blog.csdnimg.cn/badf170c603942368ece3b5374cf9632.png)