文章目录
- 一、Kubernetes网络模型
- `设计原则`
- `IP-per-Pod模型`
- 二、Kubernetes的网络实现
- 容器到容器的通信
- Pod之间的通信
- 同一个Node内Pod之间的通信
- 不同Node上Pod之间的通信
- CNI网络模型
- CNM模型
- CNI模型
- 在Kubernetes中使用网络插件
- 开源的网络组件
- Flannel
- Flannel实现图
- Flannel特点
- Open vSwitch
- 网络架构
- 网络通信过程
- Open vSwitch特点
- 直接路由
- 通过静态路由实现
- 通过动态路由实现
- Calico容器网络和网络策略实战
- Calico简介
- Calico系统架构
- Calico主要组件
参考书籍:《k8s权威指南第4版》
一、Kubernetes网络模型
设计原则
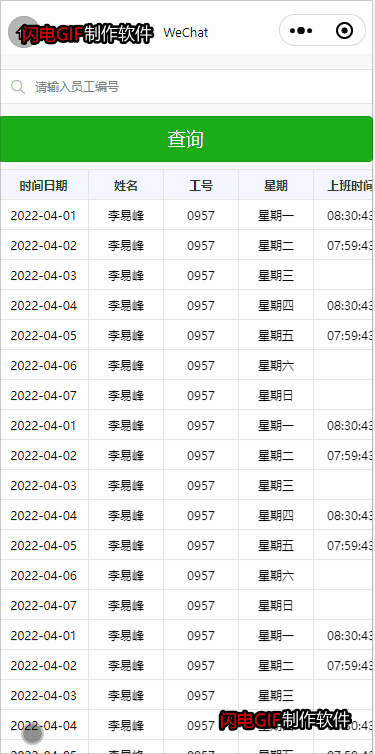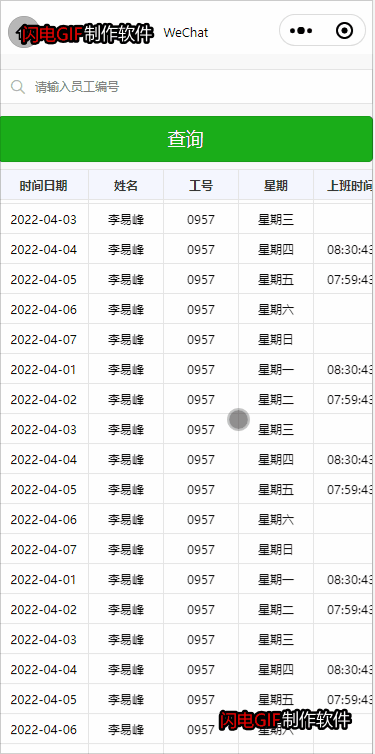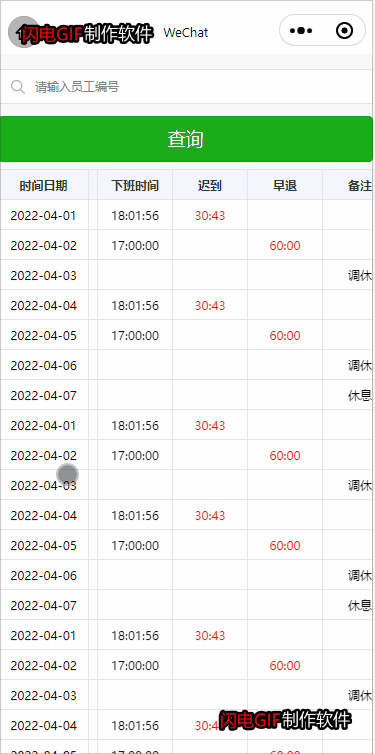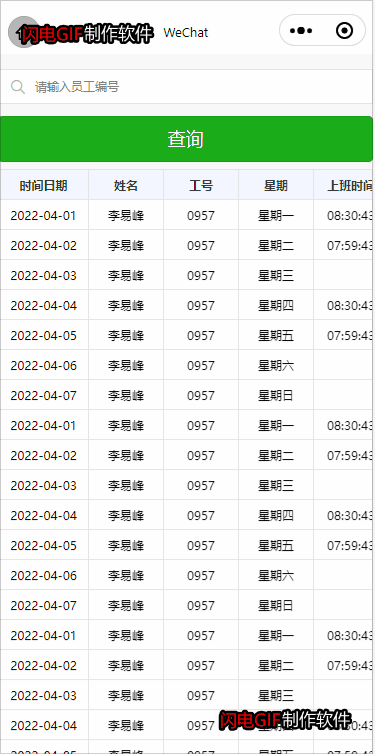
- 每个Pod都拥有一个独立的IP地址,且它们之间可以直接通过对方的IP地址进行访问(即使是在不同的Node中)
- 每个Pod内部的所有容器共享一个网络命名空间(它们的IP地址、网络设备、配置等都是共享的),它们之间可以通过localhost来连接对方的端口
IP-per-Pod模型
基于上述设计原则实现的模型被称之为IP-per-Pod模型
- 每个Pod可以被看作为一台独立的虚拟机或物理机
- 所有容器都可以通过Pod IP进行通信
- 所有节点都可以通过Pod IP与容器进行通信
- 容器中通过ifconfig看到的IP地址就是容器所在Pod的IP地址
二、Kubernetes的网络实现
容器到容器的通信
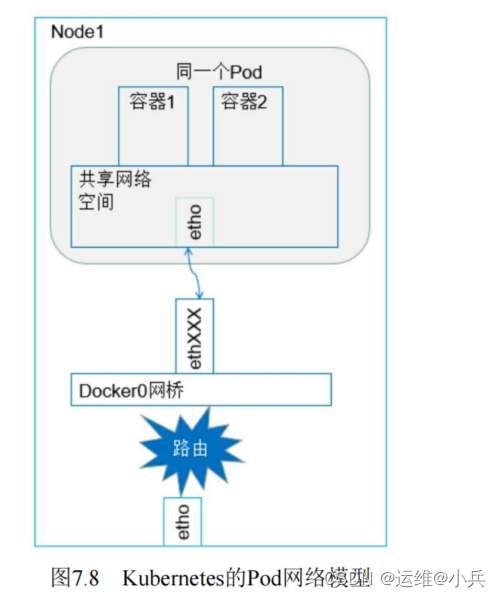
一个Pod中运行着两个容器,共享一个网络命名空间,它们就好像在一台机器上运行,可以直接通过localhost访问
Pod之间的通信
同一个Node内Pod之间的通信
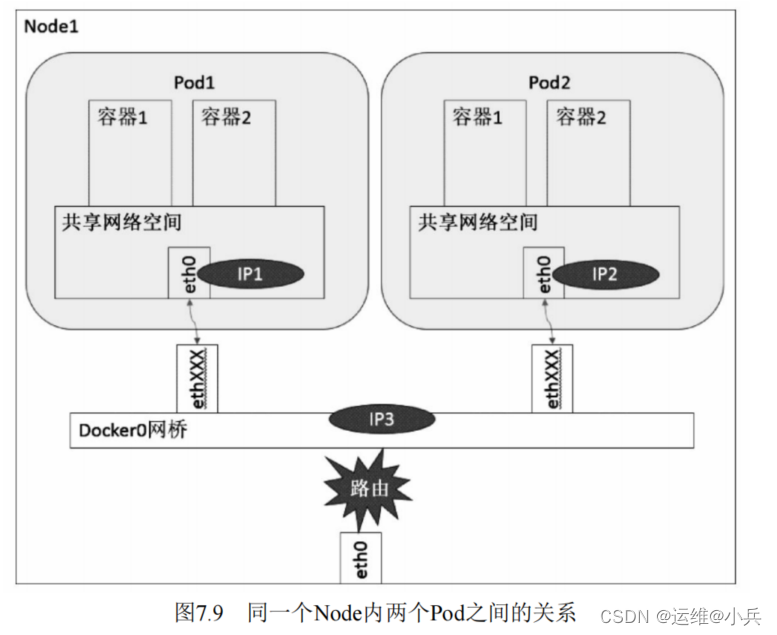
IP1、IP2、IP3均连接到docker0网桥上,网段相同,所以它们之间能直接通信
不同Node上Pod之间的通信
需满足两个条件:
1、在整个K8S集群中对Pod的IP分配进行规划,不能有冲突
2、找到一种办法,将Pod的IP和所在Node的IP关联起来,通过这个关联让Pod可以相互访问
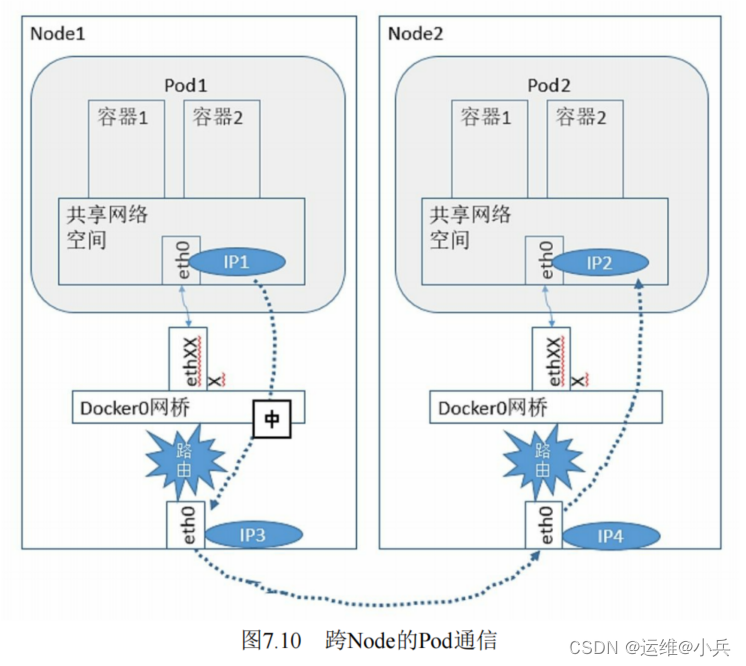
Pod1在访问Pod2时,首先要将数据从源Node的eth0发送出去,找到并到达Node2的eth0.
CNI网络模型
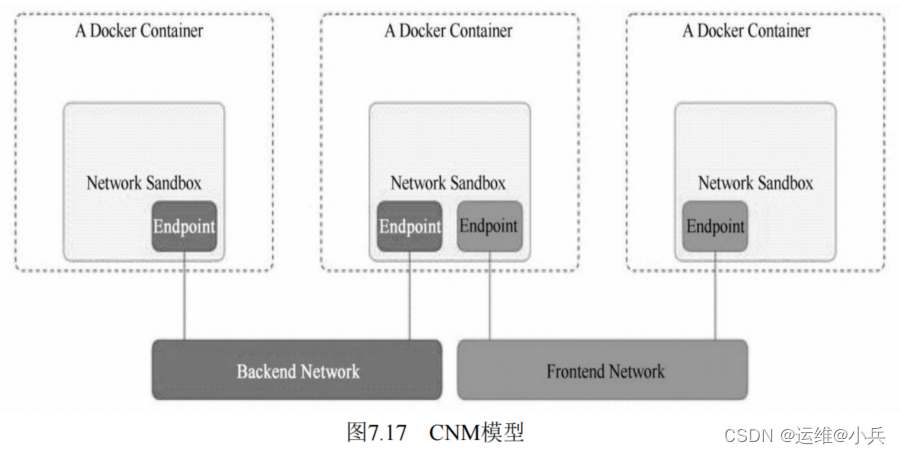
CNM模型
CNM(Container Network Model)模型由Docker公司提出的容器网络模型。主要通过Network Sandbox、Endpoint、Network这3个组件进行实现。
CNI模型
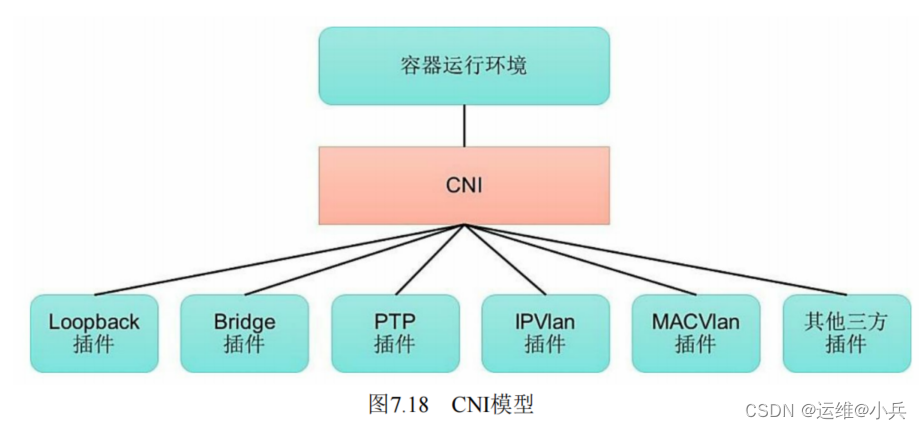
CNI(Container Network Interface)模型是由CoreOS公司提出的另一种容器网络规范。
CNI定义的是容器运行环境与网络插件之间的简单接口规范,通过一个JSON Schema定义CNI插件提供的输入和输出参数。
在Kubernetes中使用网络插件
CNI插件:根据CNI规范实现其接口,以与插件提供者进行对接
kubenet插件:使用bridge和host-local CNI插件实现一个基本的cbr0
开源的网络组件
Flannel
Flannel之所以可以搭建Kubernetes依赖的底层网络,是因为它能实现以下两点:
1、能协助Kubernetes给每一个Node上的Docker容器分配互不冲突的IP地址
2、能在这些IP地址之间建立一个覆盖网络,通过这个覆盖网络,将数据包原封不动地传递到目标容器内
Flannel实现图
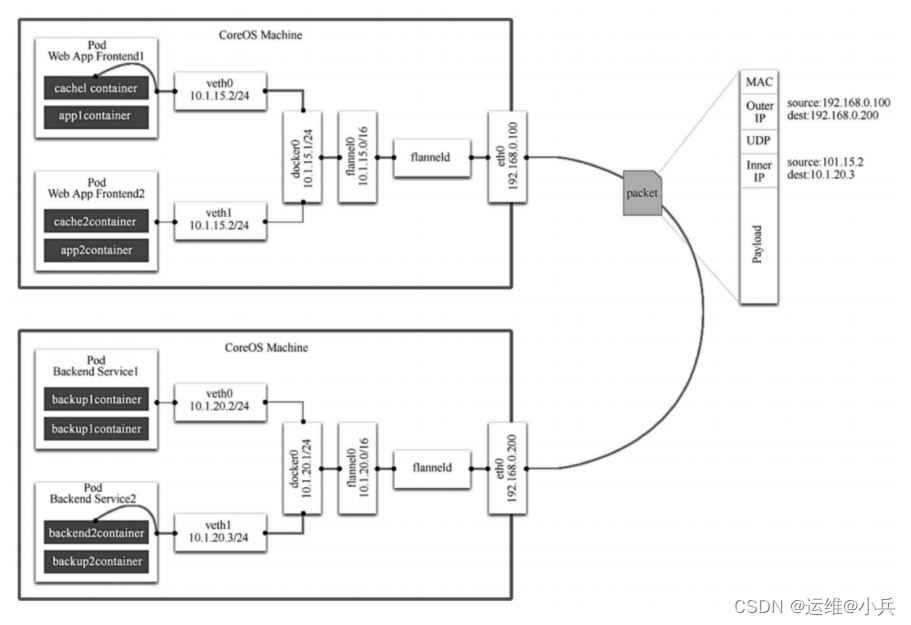
从图中可以看到,Flannel先创建一个名为flannel0的网桥(一端docker0网桥相连,另一端与flanneld的服务进程相连
flanneld进程上连etcd,利用etcd管理可分配的IP地址段资源,同时监控etcd中每个Pod的实际地址,并在内存中建立一个Pod节点路由表;下连docker0和物理网络,使用Pod节点路由表,将docker0发给它的数据包封装起来,利用物理网络将数据包投递到目标flanneld上,从而实现Pod到Pod之间的直接地址通信
flannel之间的底层通信协议包括UDP、VxLan、AWS VPC等多种方式。通过源flanneld封包、目标flanneld解包,最终docker0收到的就是原始的数据,对容器应用来说是透明的,感觉不到中间Flannel的存在
在Flannel分配好地址段后,后面的事情是由Docker完成的,Flannel通过修改Docker的启动参数将分配给它的地址段传递进去:
--bip=172.17.18.1/24
通过这些操作,Flannel就控制了每个Node上的docker0地址段的地址,也就保障了所有Pod的IP地址在同一个水平网络中且不产生冲突
Flannel特点
优点:
1、能够感知Kubernetes的Service,动态维护自己的路由表
2、通过etcd来协助Docker对整个Kubernetes集群中的docker0的子网地址分配。
不足:
1、引入了多个网络组件,在网络通信时需要转到flannel0网络接口,再转到用户态的flanneld程序,到对端后还需要走这个过程的反过程,所以会引入一些网络的时延损耗
2、Flannel默认采用UDP作为底层传输协议,UDP本身是不可靠协议,虽然两端的TCP实现了可靠传输,但在大流量、高并发的应用场景下还需要反复测试,确保没有问题。
Open vSwitch
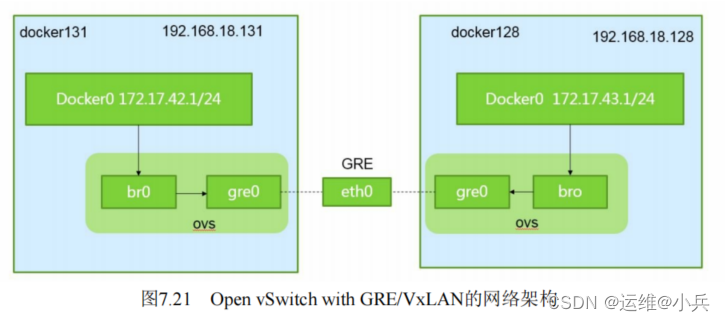
Open vSwitch是一个开源的虚拟交换机软件,有点像Linux中的bridge。
Open vSwitch的网桥可以直接建立多种通信通道(隧道),例如Open vSwitch with GRE/VxLAN。
在K8S、Docker场景下,主要是建立L3到L3的隧道
网络架构
网络通信过程
当容器内的应用访问另一个容器的地址时,数据包会通过容器内的默认路由发送给docker0网桥。
ovs的网桥作为docker0网桥的端口,会将数据发送给ovs网桥;
ovs网络已经通过配置建立了和其他ovs网桥的GRE/VxLAN隧道,自然能将数据送达对端的Node,并送往docker0及Pod
Open vSwitch特点
优势:
作为开源虚拟交换机,它相对成熟和稳定,而且支持各类网络隧道协议
不足:
1、有很多工作需要手工完成(如创建GRE隧道),当集群较大时,比较麻烦
2、无论是OVS还是Flannel,通过覆盖网络提供Pod到Pod的通信,都会引入一些额外的通信开销
直接路由
通过静态路由实现
缺乏灵活性、配置量大
通过动态路由实现
在运行动态路由发现协议代理的Node时,会将本机LOCAL路由表的IP地址通过组播协议发布出去,同时监听其他Node的组播包。
通常使用Quagga、Zebra等动态路由协议来实现
Calico容器网络和网络策略实战
Calico简介
Calico是一个基于BGP的纯三层网络方案;
Calico在每个计算节点都利用Linux Kernel实现了一个高效的vRouter来负责数据转发。每个vRouter都通过BGP1协议把本节点上运行的容器的路由信息向整个Calico网络广播,并自动设置
到达其他节点的路由转发规则;
Calico节点组网时可以直接利用数据中心的网络结构,不需要额外的NAT、隧道或者Overlay Network,没有额外的封包解包,能够节约CPU运算,提高网络效率
Calico在小规模集群中可以直接互联,在大规模集群中可以通过额外的BGP route reflector来完成
Calico基于iptables还提供了丰富的网络策略, 实现了Kubernetes的Network Policy策略, 提供容器间网络可达性限制的功能
Calico系统架构
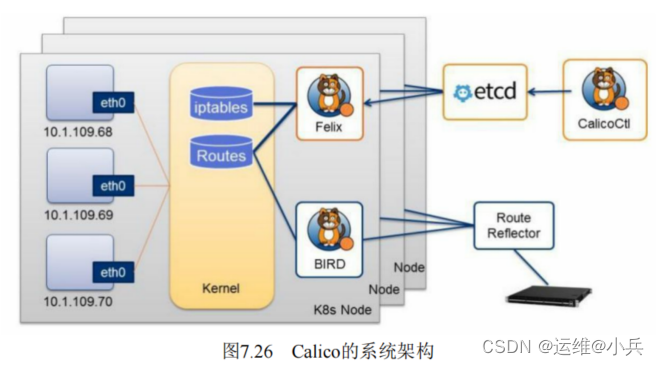
Calico主要组件
Felix: Calico Agent, 运行在每个Node上, 负责为容器设置网络资源(IP地址、 路由规则、 iptables规则等) , 保证跨主机容器网络互通。
etcd: Calico使用的后端存储。
BGP Client: 负责把Felix在各Node上设置的路由信息通过BGP协议广播到Calico网络。
Route Reflector: 通过一个或者多个BGP Route Reflector来完成大规模集群的分级路由分发。
CalicoCtl: Calico命令行管理工具。