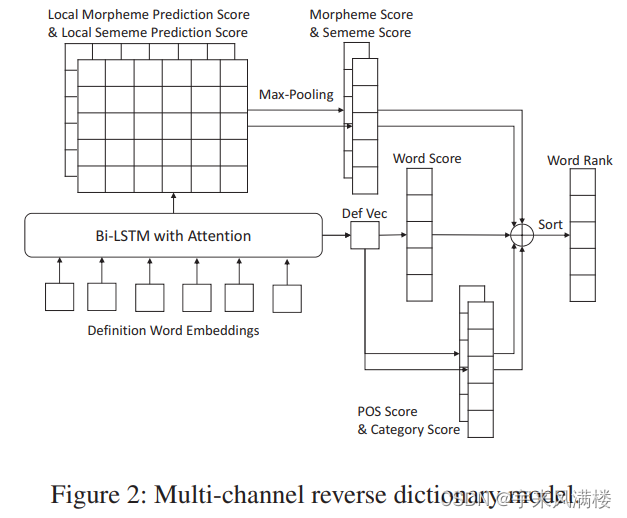
多通道反向字典模型
news2026/2/12 23:43:28
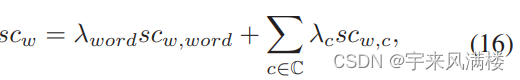
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1059879.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
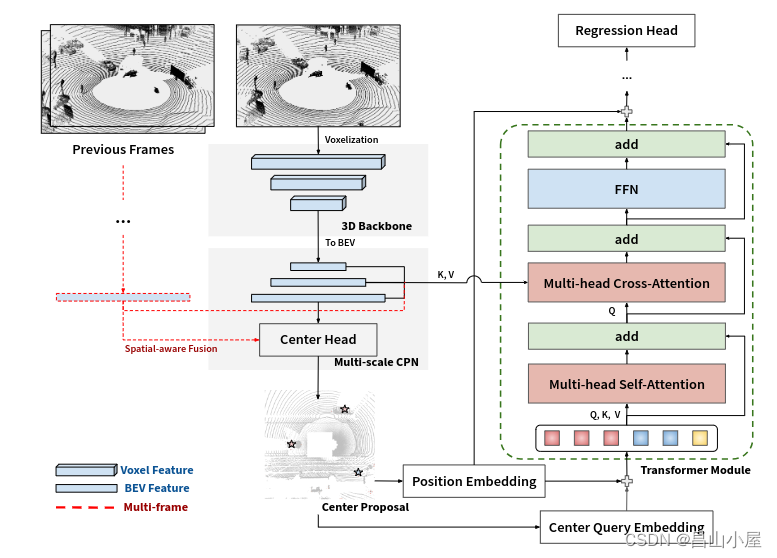
【多模态融合】TransFusion学习笔记(1)
工作上主要还是以纯lidar的算法开发,部署以及系统架构设计为主。对于多模态融合(这里主要是只指Lidar和Camer的融合)这方面研究甚少。最近借助和朋友们讨论论文的契机接触了一下这方面的知识,起步是晚了一点,但好歹是开了个头。下面就借助TransFusion论文…
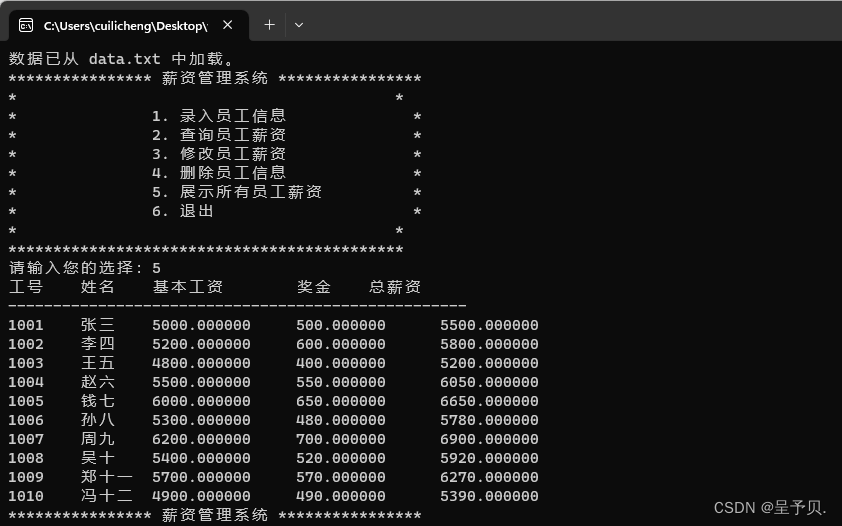
【项目开发 | C语言项目 | C语言薪资管理系统】
本项目是一个简单的薪资管理系统,旨在为用户提供方便的员工薪资管理功能,如添加、查询、修改、删除员工薪资信息等。系统通过命令行交互界面与用户进行交互,并使用 txt 文件存储员工数据。 一,开发环境需求 操作系统:w…

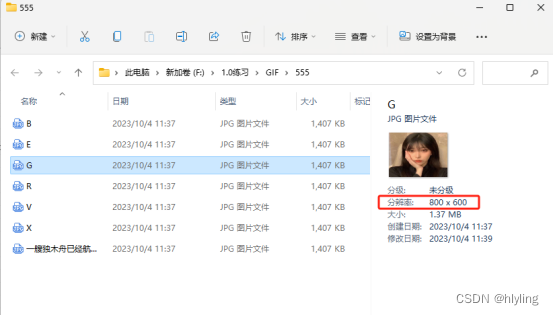
图片批量处理:轻松实现图片批量处理:按需缩放图片像素
在日常生活和工作中,我们经常需要处理大量的图片。有时候,我们需要对图片进行一些调整,以满足特定的需求。其中,缩放图片像素是一项非常常见的操作。但是,一张一张地处理图片不仅费时,还容易出错。幸运的是…

前端笔试题总结,带答案和解析(二)
前端笔试题总结,带答案和解析(二)
上一期: 前端笔试题总结,带答案和解析(1)
11.以下代码的执行后,str 的值是:
var str "Hellllo world";
str str.replac…

vertx学习总结5
这章我们讲回调,英文名:Beyond callbacks
一、章节覆盖:
回调函数及其限制,如网关/边缘服务示例所示 未来和承诺——链接异步操作的简单模型 响应式扩展——一个更强大的模型,特别适合组合异步事件流 Kotlin协程——…
【算法|动态规划No.10】leetcode LCR 089. 打家劫舍 LCR 090. 打家劫舍 II
个人主页:兜里有颗棉花糖 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创 收录于专栏【手撕算法系列专栏】【LeetCode】 🍔本专栏旨在提高自己算法能力的同时,记录一下自己的学习过程,希望…
Android---GC回收机制与分代回收策略
目录
GC 回收机制
垃圾回收(Garbage Collection, GC)
垃圾回收算法
JVM 分代回收策略
1. 新生代
2. 老年代
GC Log 分析
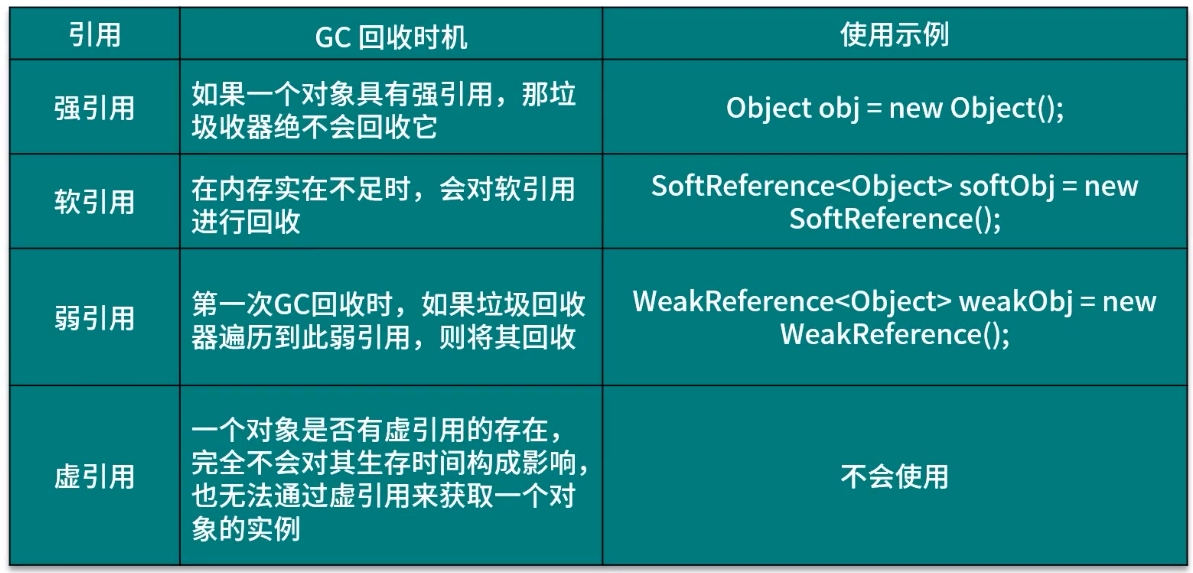
引用 GC 回收机制
垃圾回收(Garbage Collection, GC)
垃圾就是内存中已经没有用的对象,JVM 中的垃圾回收器(Garbage Collector)会自…
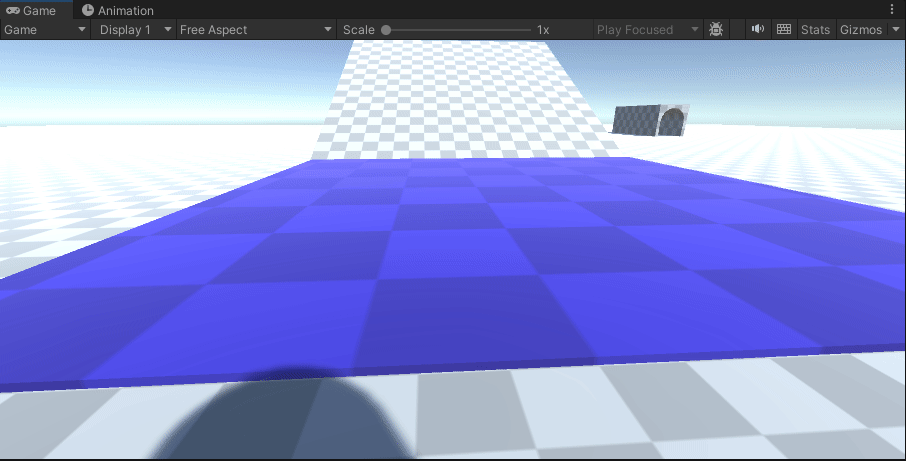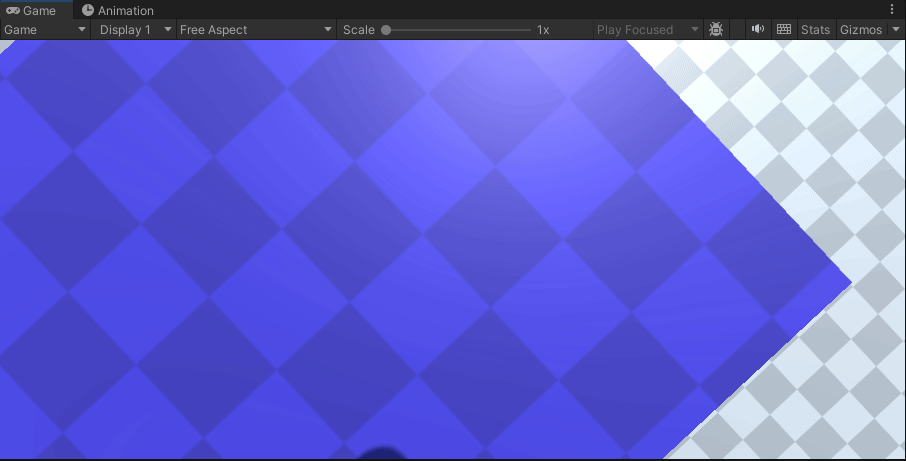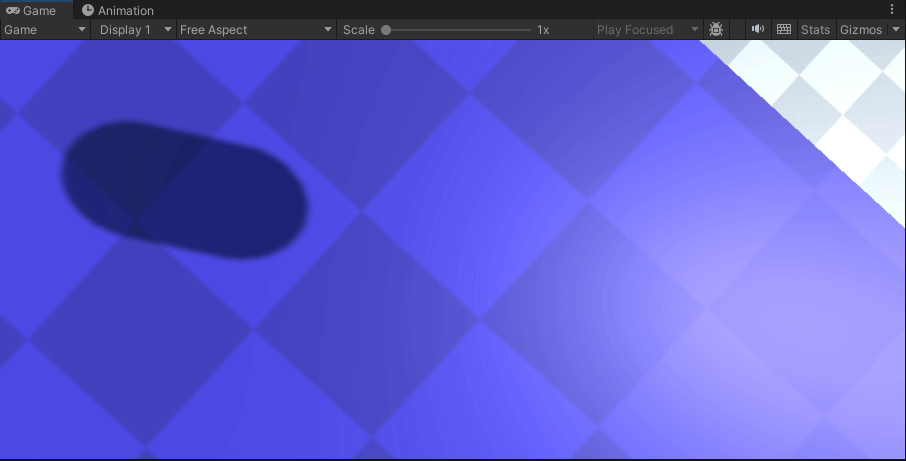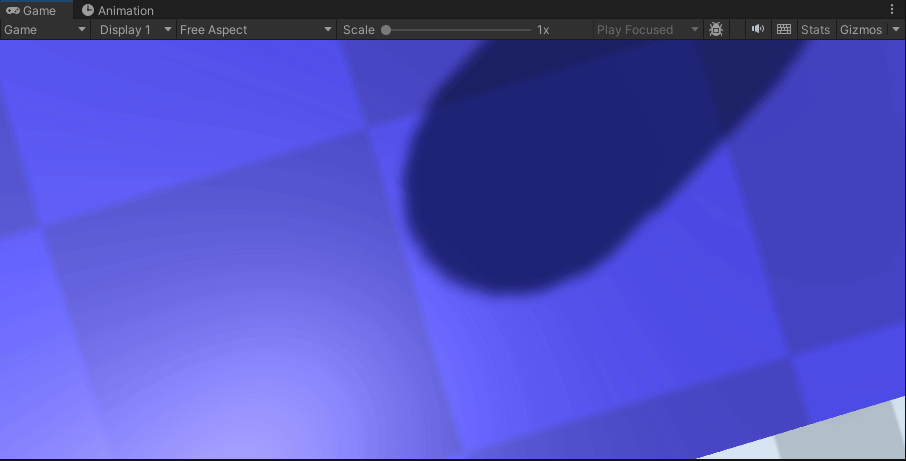
【Unity】两种方式实现弹跳平台/反弹玩家(玩家触发与物体自身触发事件实现蹦床的物理效果)
一、声明 只实现物理反弹的效果,不实现蹦床会有的视觉拉伸效果,请自行找相关代码 二、实现
经过我的实践,我发现要想实现一个平台反弹的效果,要么就选择给player添加一个物理材质(平台加了没用)࿰…
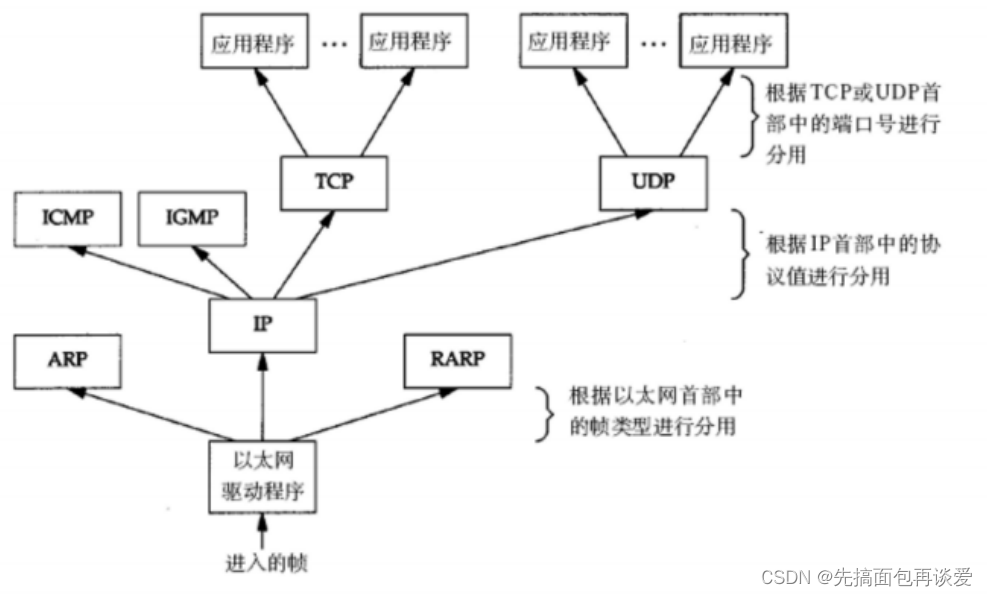
【网络】网络扫盲篇 ——用简单语言和图解带你入门网络
网络的一些名词和基础知识讲解 前言正式开始一些基础知识发展背景运营商和生产商 协议协议的分层TCP/IP五层(或四层)模型(可以不看,对新手来说太痛苦了,我这里只是为了让屏幕前的你过一遍就好,里面很多概念新手是不太懂的…
【多线程】进程与线程 并发编程 面试题总结
进程和线程
进程是程序执行时的一个实例,即它是程序已经执行到何种程度的数据结构的汇集。从内核的观点看,进程的目的就是担当分配系统资源(CPU时间、内存等)的基本单位。线程是进程的一个执行流,是CPU调度和分派的基…
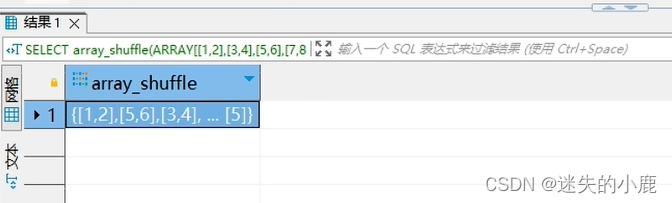
postgresql16-新特性
postgresql16-新特性 any_value数组抽样数组排序 any_value
any_value 返回任意一个值
select e.department_id ,count(*),
any_value(e.last_name)
from cps.public.employees e
group by e.department_id ;数组抽样
-- 从数组中随机抽取一个元素 array_sample(数组&#…
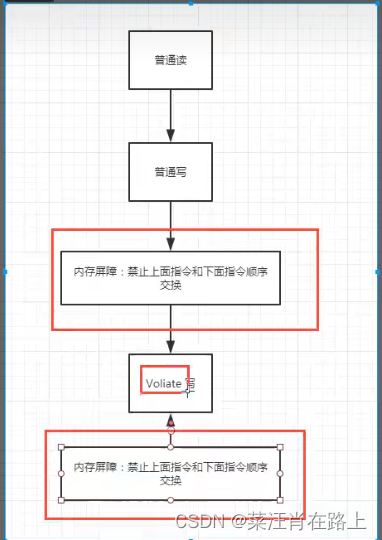
java的内存模型(概念)
在java中,设计之初就有了:主内存、线程工作内存,所以其实每一个线程执行时,都是将主线程copy一份到工作线程,执行修改后,再同步回去。 所以,就有四组内存操作方式: 1、读主内存&…
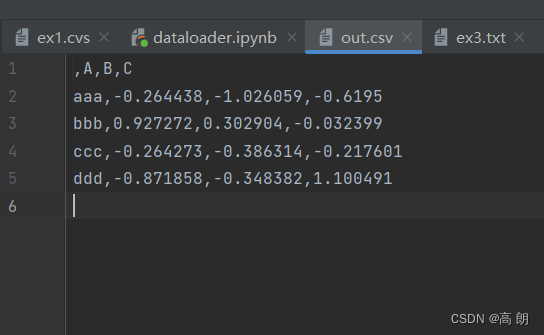
【python】数据加载与存储
文章目录 读取文本格式的数据逐块读取文本文件将数据写出到文本格式 读取文本格式的数据
pandas提供了一些用于将表格型数据读取为DataFrame对象的函数: 【read_csv和read_table最为重要】 这些函数在将文本数据转换为DataFrame时所用到的一些技术。这些函数的选项…
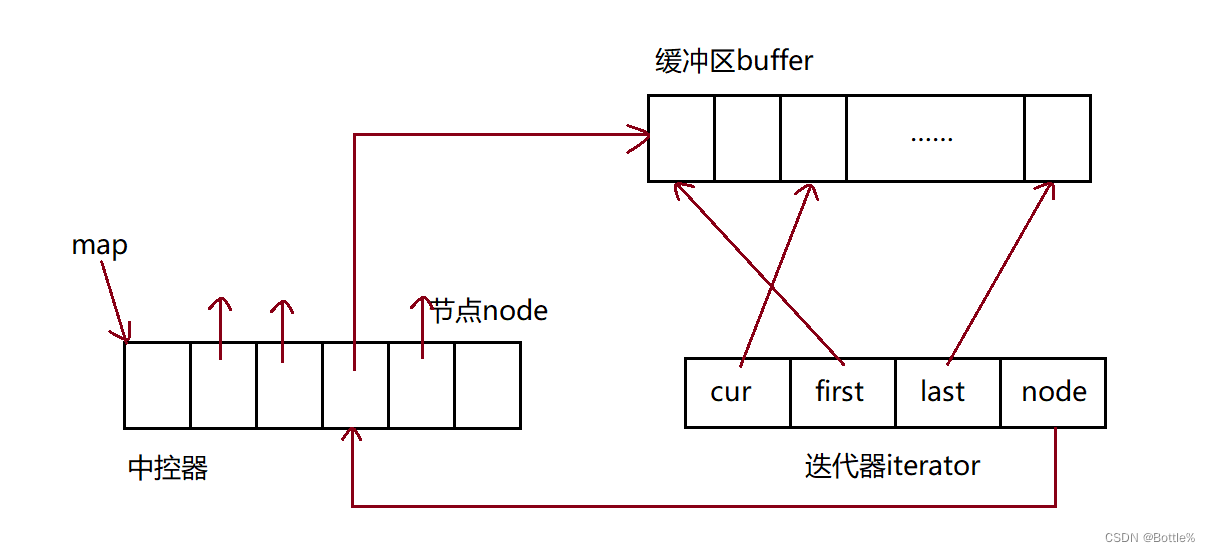
C++:stl:stack、queue、priority_queuej介绍及模拟实现和容量适配器deque介绍。
本文主要介绍c中stl的栈、队列和优先级队列并对其模拟实现,对deque进行一定介绍并在栈和队列的模拟实现中使用。
目录
一、stack的介绍和使用
1.stack的介绍
2.stack的使用
3.stack的模拟实现
二、queue的介绍和使用
1.queue的介绍
2.queue的使用
3.queue的…

Vue中如何进行分布式路由配置与管理
Vue中的分布式路由配置与管理
随着现代Web应用程序的复杂性不断增加,分布式路由配置和管理成为了一个重要的主题。Vue.js作为一种流行的前端框架,提供了多种方法来管理Vue应用程序的路由。本文将深入探讨在Vue中如何进行分布式路由配置与管理࿰…
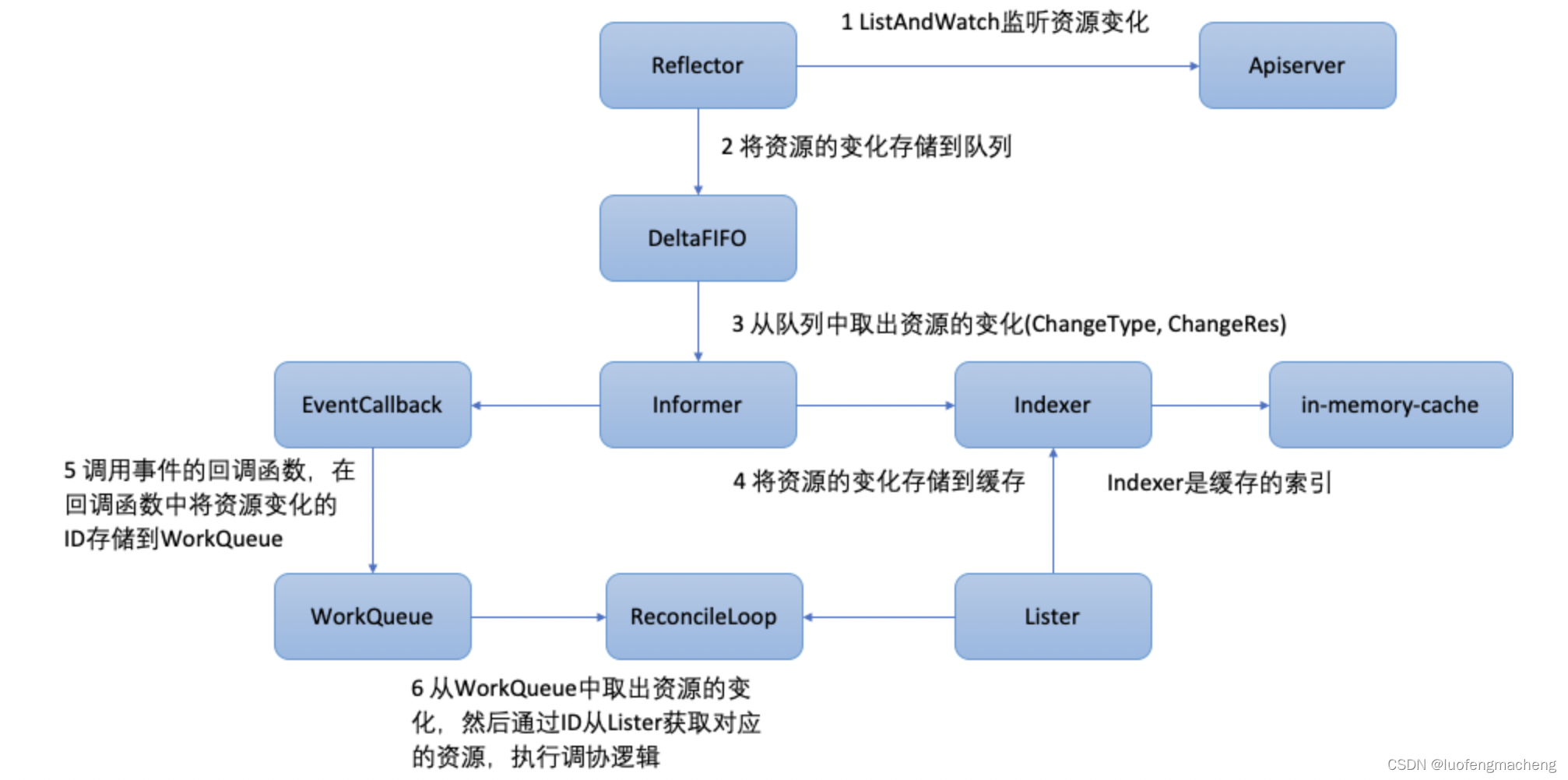
【kubernetes】kubernetes中的Controller
1 什么是Controller?
kubernetes采用了声明式API,与声明式API相对应的是命令式API:
声明式API:用户只需要告诉期望达到的结果,系统自动去完成用户的期望命令式API:用户需要关注过程,通过命令一…

EdgeView 4 for Mac:重新定义您的图像查看体验
您是否厌倦了那些功能繁杂、操作复杂的图像查看器?您是否渴望一款简单、快速且高效的工具,以便更轻松地浏览和管理您的图像库?如果答案是肯定的,那么EdgeView 4 for Mac将是您的理想之选!
EdgeView 4是一款专为Mac用户…