文章目录
- 1 自回归模型AR Model
- 1.1 自回归模型 vs 多元线性回归模型
- 1.1.1 线性回归
- 1.1.2 AR(1)模型
- 1.1.3 AR(p)模型
- 1.2 AR建模问题
- 2 移动平均模型 MA Model
- 2.1 MA模型的数学表示
- 2.1.1 MA(1)模型
- 2.2.2 MA(q)模型
- 2.2 MA建模问题
ARIMA模型是AR模型(自回归模型)与MA模型(移动平均模型)结合后诞生的模型,因此在理解ARIMA之前,必须先理解AR与MA模型。由于ARIMA模型大多数时候只能处理单变量时间序列,因此AR与MA模型也只能够被用于单变量时间序列。
1 自回归模型AR Model
AR(自回归模型)是最早、最淳朴的时间序列模型之一,它适用于“时间-标签”一一对应的单变量时序数据。AR模型的基本思想可以被概括为一句谚语:罗马城不是一日建成的,今天的结果一定依赖于过去的积累,因此AR模型相信:一个时间点上的标签值一定是依赖于之前的时间点上的标签值而存在的。这一基本思想包含了两个假设:
- 不同时间点的标签值之间强相关(highly-correlated),位于时间点t的标签值一定强烈地受到t之前的标签值的影响。在数学上,这意味着两个时间点的标签值之间的相关系数会较大。
- 根据时间的基本属性,两个时间点之间相隔越远,相互之间的影响越弱(例如,昨天是否下雨对今天是否下雨的影响很大,但三个月前的某天是否下雨,对明天是否下雨的影响就相对较小)
在这两个前提假设下,AR模型将时间点之间的关系解构为:一个时间点上的标签值可以由过去某个时间段内的所有时间点上的标签值线性组合后构成(实际就是加权求和)。用数学公式表示则有:
y
t
=
c
+
β
1
y
t
−
1
+
β
2
y
t
−
2
+
β
3
y
t
−
3
+
…
β
p
y
t
−
p
+
z
t
(
公式条件:
β
p
≠
0
)
y_{t}=c+\beta_1y_{t-1}+\beta_2y_{t-2}+\beta_3y_{t-3}+…\beta_py_{t-p}+z_{t} \quad (公式条件:\beta_p≠0)
yt=c+β1yt−1+β2yt−2+β3yt−3+…βpyt−p+zt(公式条件:βp=0)
其中
y
t
y_{t}
yt表示在时间点𝑡时的标签(训练时这里使用真实标签,预测时这里输出预测标签),
y
t
−
1
y_{t-1}
yt−1则表示在时间点𝑡的前一个时间点𝑡−1时的标签值。我们可以根据不同的场景规定𝑡与𝑡−1之间具体的时间间隔大小,但在同一个时间序列中,𝑡与𝑡−1之间的间隔一定是等同于𝑡−𝑛与𝑡−(𝑛−1)之间的间隔的。在该公式中,不同的系数𝛽乘在每一个时间点的数值之前,表示不同历史时间点的真实标签值以不同的方式影响着当前/未来时间点𝑡的真实标签值。很明显,该公式与多元线性回归的方程非常类似,只不过系数𝛽的脚标逐渐上升(由1到p)的同时,标签𝑦的脚标在逐渐下降(由t-1到t-p,是从未来到过去)。
需要注意的是,该公式中包含两个常数项:𝑐和
z
t
z_{t}
zt。其中,𝑐是线性方程中惯例存在的常数项(可以为0),而
z
t
z_{t}
zt则代表当前时间点下无法被捕捉到的某些影响,也就是白噪音(White Noise)。在统计学/数据挖掘领域中,白噪音相当于是随机变量,独立于任何已经获取的样本或标签数据,因此在时间序列中,白噪音代表着当下时间点可能发生的一切影响标签数值的偶然事件。虽然白噪声序列在不同的统计场景下往往定义有些区别,在时间序列预测中,最严格的情况下,只有均值为0、方差为特定𝜎2、服从正态分布的序列才能被称之为白噪声序列,在现实中我们往往无法使用这么严格的条件。由于𝑐和
z
t
z_{t}
zt都是常数,因此我们往往将它们合并为一个对象
β
0
\beta_{0}
β0进行建模,因此你也有可能看到公式:
y
t
=
β
0
+
β
1
y
t
−
1
+
β
2
y
t
−
2
+
β
3
y
t
−
3
+
…
β
p
y
t
−
p
y_{t}=\beta_{0}+\beta_1y_{t-1}+\beta_2y_{t-2}+\beta_3y_{t-3}+…\beta_py_{t-p}
yt=β0+β1yt−1+β2yt−2+β3yt−3+…βpyt−p
这一公式被称之为是p阶的自回归模型,写作AR§且𝑝≠0。
1.1 自回归模型 vs 多元线性回归模型
1.1.1 线性回归
y
=
w
0
+
w
1
x
1
+
+
w
2
x
2
+
…
+
w
p
x
p
y=w_{0}+w_1x_{1}++w_2x_{2}+…+w_px_{p}
y=w0+w1x1++w2x2+…+wpxp
很明显,自回归模型的公式与多元线性回归相同,因此我们对自回归模型的建模几乎等同于对多元线性回归的建模。但稍有区别的是,多元线性回归中每个自变量都是一列数据,要求解的标签也是一列数据,但在自回归模型中每个自变量𝑦都是一个样本的数值,要求解的标签y也是一个样本的数值。即是说,一个自回归模型只能得出一个样本的结果。因此,使用AR完成一个时间序列预测,是需要建立多个AR模型的。因此在自回归模型中,需要不断地建模来求解“下一个”时间点上的数值,以构成序列数据——
1.1.2 AR(1)模型
AR(1)模型在时间区间[0,t]上进行训练,在时间区间[t+1,t+m]上进行预测,𝑡为现在的时间点,则有:
训练求解𝛽:
y
1
=
β
0
+
β
1
y
0
y
2
=
β
0
+
β
1
y
1
y
3
=
β
0
+
β
1
y
2
…
y
t
=
β
0
+
β
1
y
t
−
1
y_{1}=\beta_{0}+\beta_{1}y_{0}\\ y_{2}=\beta_{0}+\beta_{1}y_{1}\\ y_{3}=\beta_{0}+\beta_{1}y_{2}\\ …\\ y_{t}=\beta_{0}+\beta_{1}y_{t-1}\\
y1=β0+β1y0y2=β0+β1y1y3=β0+β1y2…yt=β0+β1yt−1
测试求解 [ y ( t + 1 ) , y ( t + 2 ) , … , y ( t + m ) ] [y_{(t+1)},y_{(t+2)},…,y_{(t+m)}] [y(t+1),y(t+2),…,y(t+m)]:
y ^ ( t + 1 ) = β 0 + β 1 y 0 y ^ ( t + 2 ) = β 0 + β 1 y ^ ( t + 1 ) y ^ ( t + 3 ) = β 0 + β 1 y ^ ( t + 2 ) … y ^ ( t + m ) = β 0 + y ^ ( t + m − 1 ) \hat{y}_{(t+1)}=\beta_{0}+\beta_{1}y_{0}\\ \hat{y}_{(t+2)}=\beta_{0}+\beta_{1}\hat{y}_{(t+1)}\\ \hat{y}_{(t+3)}=\beta_{0}+\beta_{1}\hat{y}_{(t+2)}\\ …\\ \hat{y}_{(t+m)}=\beta_{0}+\hat{y}_{(t+m-1)} y^(t+1)=β0+β1y0y^(t+2)=β0+β1y^(t+1)y^(t+3)=β0+β1y^(t+2)…y^(t+m)=β0+y^(t+m−1)
1.1.3 AR§模型
AR§模型在时间区间[0,t]上进行训练,在时间区间[t+1,t+m]上进行预测,𝑡为现在的时间点,则有:
训练求解𝛽:
y
1
=
β
0
+
β
1
y
0
+
β
2
y
−
1
+
…
+
β
p
y
(
1
−
p
)
y
2
=
β
0
+
β
1
y
1
+
β
2
y
0
+
…
+
β
p
y
(
2
−
p
)
y
3
=
β
0
+
β
1
y
2
+
β
2
y
1
+
…
+
β
p
y
(
3
−
p
)
…
y
t
=
β
0
+
β
1
y
t
−
1
+
β
2
y
t
−
2
+
…
+
β
p
y
(
t
−
p
)
y_{1}=\beta_{0}+\beta_{1}y_{0}+\beta_{2}y_{-1}+…+\beta_{p}y_{(1-p)}\\ y_{2}=\beta_{0}+\beta_{1}y_{1}+\beta_{2}y_{0}+…+\beta_{p}y_{(2-p)}\\ y_{3}=\beta_{0}+\beta_{1}y_{2}+\beta_{2}y_{1}+…+\beta_{p}y_{(3-p)}\\ …\\ y_{t}=\beta_{0}+\beta_{1}y_{t-1}+\beta_{2}y_{t-2}+…+\beta_{p}y_{(t-p)}\\
y1=β0+β1y0+β2y−1+…+βpy(1−p)y2=β0+β1y1+β2y0+…+βpy(2−p)y3=β0+β1y2+β2y1+…+βpy(3−p)…yt=β0+β1yt−1+β2yt−2+…+βpy(t−p)
测试求解
[
y
(
t
+
1
)
,
y
(
t
+
2
)
,
…
,
y
(
t
+
m
)
]
[y_{(t+1)},y_{(t+2)},…,y_{(t+m)}]
[y(t+1),y(t+2),…,y(t+m)]:
y
^
(
t
+
1
)
=
β
0
+
β
1
y
t
+
β
2
y
t
−
1
+
…
+
β
p
y
(
t
+
1
−
p
)
y
^
(
t
+
2
)
=
β
0
+
β
1
y
^
(
t
+
1
)
+
β
2
y
t
+
…
+
β
p
y
(
t
+
2
−
p
)
y
^
(
t
+
3
)
=
β
0
+
β
1
y
^
(
t
+
2
)
+
β
2
y
^
(
t
+
1
)
+
…
+
β
p
y
(
t
+
3
−
p
)
…
y
^
(
t
+
m
)
=
β
0
+
β
1
y
^
(
t
+
m
−
1
)
+
β
2
y
^
(
t
+
m
−
2
)
+
…
+
β
(
t
+
m
−
p
)
\hat{y}_{(t+1)}=\beta_{0}+\beta_{1}y_{t}+\beta_{2}y_{t-1}+…+\beta_{p}y_{(t+1-p)}\\ \hat{y}_{(t+2)}=\beta_{0}+\beta_{1}\hat{y}_{(t+1)}+\beta_{2}y_{t}+…+\beta_{p}y_{(t+2-p)}\\ \hat{y}_{(t+3)}=\beta_{0}+\beta_{1}\hat{y}_{(t+2)}+\beta_{2}\hat{y}_{(t+1)}+…+\beta_{p}y_{(t+3-p)}\\ …\\ \hat{y}_{(t+m)}=\beta_{0}+\beta_{1}\hat{y}_{(t+m-1)}+\beta_{2}\hat{y}_{(t+m-2)}+…+\beta_{(t+m-p)}
y^(t+1)=β0+β1yt+β2yt−1+…+βpy(t+1−p)y^(t+2)=β0+β1y^(t+1)+β2yt+…+βpy(t+2−p)y^(t+3)=β0+β1y^(t+2)+β2y^(t+1)+…+βpy(t+3−p)…y^(t+m)=β0+β1y^(t+m−1)+β2y^(t+m−2)+…+β(t+m−p)
当然,现在大部分时间序列库会自动帮我们完成这个流程,并不需要人为地多次建模来完成序列预测。观察上面的流程,不难发现自回归模型比多元线性回归多出了一个超参数𝑝。
1.2 AR建模问题
在自回归模型的建模过程中,需要回答三个问题:
-
为了要预测未来的一个时间点上的数据,需要收集过去多少时间点上的数据?即,𝑝是多少?
当确定𝑝是多少后,我们需要对应收集 y ( t − p ) y_{(t-p)} y(t−p)的数据。例如,如果模型是AR(1),那我们只需要保证要预测的第一个日期前面有一天的历史记录即可。如果模型是AR§,则需要保证要预测的第一个日期前面至少有p天的历史记录。在实际建模过程中,𝑝是一个超参数,需要人为进行选择和定义。
-
为什么在测试时,等号右边的𝑦有时是真实值𝑦,有时是预测值 y ^ \hat{y} y^?
在AR模型中,假设𝑝=5,那任意日期的预测标签都等于当前日期前5天的标签加权求和后的结果。假设当前日期为1,由于在建模之前我们可以保证收集到至少日期1之前5天已知的结果,因此在求解 y ^ 1 \hat{y}_{1} y^1时,等号右侧的所有标签都是收集到的、已知的真实历史数据,即真实标签。
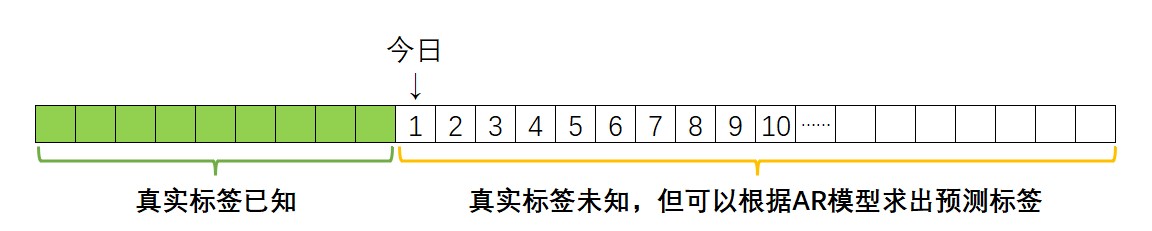
但当我们需要求解 y ^ 10 \hat{y}_{10} y^10时,很明显10这个日期前5天中都只有预测标签、没有真实标签,因此我们只能够使用预测出的 y ^ 5 \hat{y}_{5} y^5, y ^ 6 \hat{y}_{6} y^6, y ^ 7 \hat{y}_{7} y^7, y ^ 8 \hat{y}_{8} y^8, y ^ 9 \hat{y}_{9} y^9等5天的预测标签进行求解。因此在AR模型中,等号右侧一般会混合使用真实标签和预测标签,当预测标签占比更大时,预测也会更加不准确,故而在AR模型中预测离现在的日期越远的未来,错误的可能性越大。
-
每个时间点的值以什么方式影响着 y t y_{t} yt?也就是,{ β 0 , β 1 , β 2 , … , β p {\beta_{0},\beta_{1},\beta_{2},…,\beta_{p}} β0,β1,β2,…,βp}分别是多少?
在AR模型中,我们使用复杂的参数估计方法求解𝛽,需要强调的是,在对 y 1 , y 2 , … , y t y_{1},y_{2},…,y_{t} y1,y2,…,yt的计算过程中,所有 β 0 , β 1 , β 2 , … , β p {\beta_{0},\beta_{1},\beta_{2},…,\beta_{p}} β0,β1,β2,…,βp的值是一致的,因为𝛽衡量的是“1天前,2天前,……,p天前”的数值对今天的标签的影响,而不关心t具体是什么时间。
2 移动平均模型 MA Model
MA模型是不同于AR模型的、另一流派的时序模型。虽然与AR模型共同发源于经典统计学,但MA模型的基本思想和基本假设却与AR模型大不相同。MA模型的基本思想是:大部分时候时间序列应当是相对稳定的。在稳定的基础上,每个时间点上的标签值受过去一段时间内、不可预料的各种偶然事件影响而波动。即在一段时间内,时间序列应该是围绕着某个均值上下波动的序列,时间点上的标签值会围绕着某个均值移动,因此模型才被称为“移动平均模型 Moving Average Model”。
MA模型的思想中包含着统计学家们对时间维度更丰富的理解,该模型假设:
- 时间序列的(长期)趋势与时间序列的(短期)波动受不同因素的影响。从长期来看,时间序列可能呈现缓慢上升、缓慢下降或周期性变动的趋势,这种长时间展现出来的周期受历史标签、及标签本身属性的影响。但在一段较短时间内,时间序列一定是相对稳定的,令时间序列在短期内波动的因子不是历史标签、而是不可预料的各种偶然事件。
- 不同时间点的标签值之间是关联的,但各种偶然事件在不同时间点上产生的影响之间却是相互独立的。这一点与上面的假设是相辅相成的:历史标签影响着时间序列的长期趋势,那历史标签之间自然是相互关联的。相对的,不可预料的偶然事件之间却没有关联。
MA模型中引入的“偶然事件”这部分思想指出了一个非常关键的点:即时间只是我们用于记录数据的一种工具、一串锚点,并不能完全影响一段时间内的标签值,这与现代机器学习领域的理论非常相似。毕竟正如我们之前提过的,影响明日会不会下雨的真正因素并不是“今天”或“昨天”这些时间概念本身,而是风、云、日照等更加客观和科学的因素(这些其实就是MA模型认为的“偶然因素”)。不过我们也能够理解,随着季节的变化、时间自有自己的周期,因此天气也会存在季节性的周期,因此从长期来看时间序列的趋势是恒定的。MA模型的观点着重于某个时间点的值是被难以想象的复杂因素所主导的,而非只受到历史记录影响这一理。
2.1 MA模型的数学表示
基于MA模型的基本思想,可以用如下公式表示MA模型:
y
t
=
μ
+
ϵ
t
+
θ
1
ϵ
t
−
1
+
θ
2
ϵ
t
−
2
+
θ
3
ϵ
t
−
3
+
…
θ
q
ϵ
t
−
q
(
公式条件:
θ
q
≠
0
)
y_{t}=\mu+\epsilon_{t}+\theta_{1}\epsilon_{t-1}+\theta_{2}\epsilon_{t-2}+\theta_{3}\epsilon_{t-3}+…\theta_{q}\epsilon_{t-q}\quad (公式条件:\theta_q≠0)
yt=μ+ϵt+θ1ϵt−1+θ2ϵt−2+θ3ϵt−3+…θqϵt−q(公式条件:θq=0)
这一公式被称之为是q阶的移动平均模型,写作MA(q)且𝑞≠0。不难发现,这个公式虽然看上去也与线性回归非常相似,但建模思路明显有巨大的差别——
首先,公式中的
y
t
y_{t}
yt表示在时间点𝑡的标签值,𝜇表示当前时间序列标签的均值,
ϵ
t
\epsilon_{t}
ϵt则表示在时间点𝑡时、不可预料、不可估计的偶然事件的影响,
ϵ
t
−
1
\epsilon_{t-1}
ϵt−1则代表在时间点𝑡−1时不可预料的、不可估计的偶然事件的影响。不难发现,“偶然事件”这一定义与AR模型中白噪音的定义几乎一模一样,它们都是当前时间点下无法被捕捉到的某些影响,因此𝜖在MA模型中就代表当日的“白噪音”,而AR模型公式中的
z
t
z_{t}
zt也可使用
ϵ
t
\epsilon_{t}
ϵt来表示。在理想条件下,MA模型规定𝜖应当服从均值为0、标准差为1的正态分布,但在实际计算时,MA模型规定𝜖等同于模型的预测值
y
^
t
\hat{y}_{t}
y^t与真实标签
y
t
y_{t}
yt之间的差值(Residuals),即:
ϵ
t
=
y
t
−
y
^
t
\epsilon_{t}=y_{t}-\hat{y}_{t}
ϵt=yt−y^t
由于偶然事件是无法被预料的、偶然事件带来的影响也是无法被预估的,因此MA模型使用预测标签与真实标签之间的差异就来代表“无法被预料、无法被估计、无法被模型捕捉的偶然事件的影响”。MA模型相信这些影响累加起来共同影响下一个时间点的标签值,因此
y
t
y_{t}
yt等于所有𝜖的线性组合(加权求和)。
在公式中,不同的系数𝜃乘在每一个时间点的差值之前,表示不同时间点发生的各种偶然事件对真实标签值所产生的影响不同,需要注意的是,今天的“偶然事件” ϵ t \epsilon_{t} ϵt之前没有需要求解的系数(即默认系数为1),这可能代表今天的“偶然事件”对今天的标签的影响程度是100%。
在这一公式当中,𝜇和 ϵ t \epsilon_{t} ϵt都是常数项,因此在一些教材当中我们也会看到将这两项进行合并后、整理为 θ 0 \theta_{0} θ0来进行求解的情况,但这种写法其实是不严谨的。有以下两个理由:
1)MA模型与AR模型不同, ϵ t \epsilon_{t} ϵt虽然在结果上呈现为一个常数(而不是一个需要求解的参数),但它实际上是由标签 y t y_{t} yt和预测值 y ^ t \hat{y}_{t} y^t的差值计算出来的、并不是在模型估计过程中和常数一样被估计出来的,这一点令我们不能将 ϵ t \epsilon_{t} ϵt当做普通的常数来看待。
2)常数𝜇与常数𝜖对应了MA模型假设中的两个部分。MA模型假设时间序列的(长期)趋势与时间序列的(短期)波动受不同因素的影响,而在该公式中常数𝜇对应的是长期趋势,𝜖对应的是短期波动,因代表的含义不同因此不能一概而论。
2.1.1 MA(1)模型
MA(1)模型在时间区间[0,t]上进行训练,在时间区间[t+1,t+m]上进行预测,𝑡为现在的时间点,则有:
训练求解𝜃:
y
1
=
μ
+
ϵ
1
+
θ
1
ϵ
0
y
2
=
μ
+
ϵ
2
+
θ
1
ϵ
1
y
3
=
μ
+
ϵ
3
+
θ
1
ϵ
2
…
y
t
=
μ
+
ϵ
t
+
θ
1
ϵ
(
t
−
1
)
y_{1}=\mu+\epsilon_{1}+\theta_{1}\epsilon_{0}\\ y_{2}=\mu+\epsilon_{2}+\theta_{1}\epsilon_{1}\\ y_{3}=\mu+\epsilon_{3}+\theta_{1}\epsilon_{2}\\ …\\ y_{t}=\mu+\epsilon_{t}+\theta_{1}\epsilon_{(t-1)}\\
y1=μ+ϵ1+θ1ϵ0y2=μ+ϵ2+θ1ϵ1y3=μ+ϵ3+θ1ϵ2…yt=μ+ϵt+θ1ϵ(t−1)
测试求解
[
y
(
t
+
1
)
,
y
(
t
+
2
)
,
…
,
y
(
t
+
m
)
]
[y_{(t+1)},y_{(t+2)},…,y_{(t+m)}]
[y(t+1),y(t+2),…,y(t+m)]:
y ^ ( t + 1 ) = μ + θ 1 ϵ t y ^ ( t + 2 ) = μ + θ 1 ϵ ( t + 1 ) y ^ ( t + 3 ) = μ + θ 1 ϵ ( t + 2 ) … y ^ ( t + m ) = μ + θ 1 ϵ ( t + m − 1 ) \hat{y}_{(t+1)}=\mu+\theta_{1}\epsilon_{t}\\ \hat{y}_{(t+2)}=\mu+\theta_{1}\epsilon_{(t+1)}\\ \hat{y}_{(t+3)}=\mu+\theta_{1}\epsilon_{(t+2)}\\ …\\ \hat{y}_{(t+m)}=\mu+\theta_{1}\epsilon_{(t+m-1)}\\ y^(t+1)=μ+θ1ϵty^(t+2)=μ+θ1ϵ(t+1)y^(t+3)=μ+θ1ϵ(t+2)…y^(t+m)=μ+θ1ϵ(t+m−1)
观察上面的式子,一个很明显的点是,在训练的时候 y t y_{t} yt由𝜇、 ϵ t \epsilon_{t} ϵt、 θ 1 ϵ t − 1 \theta_{1}\epsilon_{t-1} θ1ϵt−1三项组成,但在测试的时候 y ^ ( t + 1 ) \hat{y}_{(t+1)} y^(t+1)却只由𝜇和 θ 1 ϵ t \theta_{1}\epsilon_{t} θ1ϵt两项组成。很明显,测试的时候并不存在与 y ^ ( t + 1 ) \hat{y}_{(t+1)} y^(t+1)的角标相匹配的 ϵ t + 1 \epsilon_{t+1} ϵt+1,在MA模型当中测试时的公式与训练时的公式有所不同。以 y 1 y_{1} y1的公式为例:
y
1
=
μ
+
ϵ
1
+
θ
1
ϵ
0
y_{1}=\mu+\epsilon_{1}+\theta_{1}\epsilon_{0}
y1=μ+ϵ1+θ1ϵ0
而根据𝜖的定义,有:
ϵ
1
=
y
1
−
y
^
1
\epsilon_{1}=y_{1}-\hat{y}_{1}
ϵ1=y1−y^1
将
ϵ
1
\epsilon_{1}
ϵ1的计算方式带入
y
1
y_{1}
y1的式子后,不难发现:
y
1
=
μ
+
ϵ
1
+
θ
1
ϵ
0
y
1
=
μ
+
(
y
1
−
y
^
1
)
+
θ
1
ϵ
0
y
^
1
=
μ
+
θ
1
ϵ
0
y_{1}=\mu+\epsilon_{1}+\theta_{1}\epsilon_{0}\\ y_{1}=\mu+(y_{1}-\hat{y}_{1})+\theta_{1}\epsilon_{0}\\ \hat{y}_{1}=\mu+\theta_{1}\epsilon_{0}
y1=μ+ϵ1+θ1ϵ0y1=μ+(y1−y^1)+θ1ϵ0y^1=μ+θ1ϵ0
因此在MA模型中,预测值
y
^
\hat{y}
y^和真实值𝑦的计算公式是不相同的。这一点也符合对𝜖的定义,身为当日的“白噪音”,即模型无法捕捉到、无法预测的偶然影响,我们只能记录历史的影响,而无法知晓今天的影响。因此,在使用历史数据进行训练时可以使用历史的𝜖,但在对未来进行预测时我们却无法使用未知的“未来偶然影响”。这一点可以被推广到q阶MA模型中。
2.2.2 MA(q)模型
MA(q)模型在时间区间[0,t]上进行训练,在时间区间[t+1,t+m]上进行预测,𝑡为现在的时间点,则有:
训练求解𝜃:
y 1 = μ + ϵ 1 + θ 1 ϵ 0 + θ 2 ϵ − 1 + … + θ q ϵ ( 1 − q ) y 2 = μ + ϵ 2 + θ 1 ϵ 1 + θ 2 ϵ 0 + … + θ q ϵ ( 2 − q ) y 3 = μ + ϵ 3 + θ 1 ϵ 2 + θ 2 ϵ 1 + … + θ q ϵ ( 3 − q ) … y t = μ + ϵ t + θ 1 ϵ ( t − 1 ) + θ 2 ϵ ( t − 2 ) + … + θ q ϵ ( t − q ) y_{1}=\mu+\epsilon_{1}+\theta_{1}\epsilon_{0}+\theta_{2}\epsilon_{-1}+…+\theta_{q}\epsilon_{(1-q)}\\ y_{2}=\mu+\epsilon_{2}+\theta_{1}\epsilon_{1}+\theta_{2}\epsilon_{0}+…+\theta_{q}\epsilon_{(2-q)}\\ y_{3}=\mu+\epsilon_{3}+\theta_{1}\epsilon_{2}+\theta_{2}\epsilon_{1}+…+\theta_{q}\epsilon_{(3-q)}\\ …\\ y_{t}=\mu+\epsilon_{t}+\theta_{1}\epsilon_{(t-1)}+\theta_{2}\epsilon_{(t-2)}+…+\theta_{q}\epsilon_{(t-q)}\\ y1=μ+ϵ1+θ1ϵ0+θ2ϵ−1+…+θqϵ(1−q)y2=μ+ϵ2+θ1ϵ1+θ2ϵ0+…+θqϵ(2−q)y3=μ+ϵ3+θ1ϵ2+θ2ϵ1+…+θqϵ(3−q)…yt=μ+ϵt+θ1ϵ(t−1)+θ2ϵ(t−2)+…+θqϵ(t−q)
测试求解 [ y ( t + 1 ) , y ( t + 2 ) , … , y ( t + m ) ] [y_{(t+1)},y_{(t+2)},…,y_{(t+m)}] [y(t+1),y(t+2),…,y(t+m)]:
y ^ ( t + 1 ) = μ + θ 1 ϵ t + θ 2 ϵ t − 1 + … + θ q ϵ ( t + 1 − q ) y ^ ( t + 2 ) = μ + θ 1 ϵ t + 1 + θ 2 ϵ t + … + θ q ϵ ( t + 2 − q ) y ^ ( t + 3 ) = μ + θ 1 ϵ t + 2 + θ 2 ϵ t + 1 + … + θ q ϵ ( t + 3 − q ) … y ^ ( t + m ) = μ + θ 1 ϵ ( t + m − 1 ) + θ 2 ϵ ( t + m − 2 ) + … + θ q ϵ ( t + m − q ) \hat{y}_{(t+1)}=\mu+\theta_{1}\epsilon_{t}+\theta_{2}\epsilon_{t-1}+…+\theta_{q}\epsilon_{(t+1-q)}\\ \hat{y}_{(t+2)}=\mu+\theta_{1}\epsilon_{t+1}+\theta_{2}\epsilon_{t}+…+\theta_{q}\epsilon_{(t+2-q)}\\ \hat{y}_{(t+3)}=\mu+\theta_{1}\epsilon_{t+2}+\theta_{2}\epsilon_{t+1}+…+\theta_{q}\epsilon_{(t+3-q)}\\ …\\ \hat{y}_{(t+m)}=\mu+\theta_{1}\epsilon_{(t+m-1)}+\theta_{2}\epsilon_{(t+m-2)}+…+\theta_{q}\epsilon_{(t+m-q)}\\ y^(t+1)=μ+θ1ϵt+θ2ϵt−1+…+θqϵ(t+1−q)y^(t+2)=μ+θ1ϵt+1+θ2ϵt+…+θqϵ(t+2−q)y^(t+3)=μ+θ1ϵt+2+θ2ϵt+1+…+θqϵ(t+3−q)…y^(t+m)=μ+θ1ϵ(t+m−1)+θ2ϵ(t+m−2)+…+θqϵ(t+m−q)
2.2 MA建模问题
在MA建模过程中,我们需要回答以下问题:
-
为了预测未来的一个时间点上的标签值,我们需要收集过去多少时间点上的“偶然事件的影响”?即𝑞是多少?
与AR模型中的p一样,MA模型中的q是我们需要定义的超参数,一般都设置为[1,5]之内的正整数,但偶尔也可能出现一些较大的数字。在统计学中,可以使用自相关系数ACF(Auto-correlation function)、偏相关系数PACF(Partial Auto-Correlation Function)或者相关的假设检验来帮助我们确定p、q等超参数的值,其中PACF用于确定AR模型的p值,ACF用于确定MA模型的q值,假设检验则可以同时用于两种模型。大部分时候p和q是可以被算法自主确定的,且p和q手动确定的流程较为复杂。
-
每个时间点的偶然事件对标签值产生了多大的影响?也就是{ ϵ 0 , ϵ 1 , ϵ 2 , … , ϵ q {\epsilon_{0},\epsilon_{1},\epsilon_{2},…,\epsilon_{q}} ϵ0,ϵ1,ϵ2,…,ϵq}分别是多少?同时,每个时间点的偶然事件以什么样的方式影响着 y t y_{t} yt?也就是{ μ , θ 1 , θ 2 , θ 3 , … , θ q {\mu,\theta_{1},\theta_{2},\theta_{3},…,\theta_{q}} μ,θ1,θ2,θ3,…,θq}分别是多少?
对大多数模型来说,这两个问题是应该分开提问的,但MA模型却需要在训练过程中一次性求解出所有的𝜖和𝜃。𝜖的求解是MA模型求解过程中会遇见的第一个难点,也是许多教材在具体描述时会避而不谈的地方。以MA(1)模型为假设,在训练过程中,我们有如下流程:
y 1 = μ + ϵ 1 + θ 1 ϵ 0 y 2 = μ + ϵ 2 + θ 1 ϵ 1 y 3 = μ + ϵ 3 + θ 1 ϵ 2 … y t = μ + ϵ t + θ 1 ϵ ( t − 1 ) y_{1}=\mu+\epsilon_{1}+\theta_{1}\epsilon_{0}\\ y_{2}=\mu+\epsilon_{2}+\theta_{1}\epsilon_{1}\\ y_{3}=\mu+\epsilon_{3}+\theta_{1}\epsilon_{2}\\ …\\ y_{t}=\mu+\epsilon_{t}+\theta_{1}\epsilon_{(t-1)}\\ y1=μ+ϵ1+θ1ϵ0y2=μ+ϵ2+θ1ϵ1y3=μ+ϵ3+θ1ϵ2…yt=μ+ϵt+θ1ϵ(t−1)
该公式看似简单,但其实存在着巨大的问题,因为在第一次训练时, y 1 y_{1} y1作为标签是已知的,但 y 1 y_{1} y1这一公式的等号右侧所有的元素都是未知的,更离奇的是,这些未知元素中的ϵ 1 = y 1 − y ^ 1 , ϵ 0 = y 0 − y ^ 0 \epsilon_{1}=y_{1}-\hat{y}_{1},\epsilon_{0}=y_{0}-\hat{y}_{0} ϵ1=y1−y^1,ϵ0=y0−y^0,但因为我们并不知道 y ^ 1 \hat{y}_{1} y^1、 y ^ 0 \hat{y}_{0} y^0和 y 0 y_{0} y0是多少,同时由于时间点是从1开始,因此根本没有时间点0处的真实标签,因此使用一般数学过程,两个𝜖
都无法被求解。此时应该怎么办呢?
-
首先,很明显现在一般数学过程无法完成对参数𝜇和𝜃的求解,因此我们需要使用带迭代过程的参数估计办法(如最小二乘、梯度下降等)对这些参数进行求解。这类求解方法会先假设一组初始参数值(一般为随机数),并在迭代过程中逐渐修正这些参数。因此我们可以假设最初的𝜇和 θ 1 \theta_{1} θ1是任意随机数。
-
假设一个初始化用的 ϵ 0 \epsilon_{0} ϵ0的值,通常是计算当前标签的均值、或设置为0.05之类的初始值。当然,也可以使用参数估计方式对 ϵ 0 \epsilon_{0} ϵ0进行估计,但现实中大部分时候是设置一个固定的初始值,毕竟根据MA模型的计算公式。 ϵ 0 \epsilon_{0} ϵ0只影响最初的一段时间。
-
在假设完 ϵ 0 \epsilon_{0} ϵ0、𝜇初始值和初始值 θ 1 \theta_{1} θ1的情况下,根据公式 y 1 = μ + ϵ 1 + θ 1 ϵ 0 y_{1}=\mu+\epsilon_{1}+\theta_{1}\epsilon_{0} y1=μ+ϵ1+θ1ϵ0求解唯一未知的数 ϵ 1 \epsilon_{1} ϵ1,这样 ϵ 1 \epsilon_{1} ϵ1就可以被用在 y 2 y_{2} y2的公式中,用于求解 ϵ 2 \epsilon_{2} ϵ2了。同理, ϵ 2 \epsilon_{2} ϵ2求解完毕后,就可以被用于求解 ϵ 3 \epsilon_{3} ϵ3,这样就可以在训练中求解出所有的𝜖。
-
在第一次求解出所有的𝜖后,需要根据当前𝜖值的情况按公式求解出 [ y ^ 1 , y ^ 2 , y ^ 3 , … … , y ^ t ] [\hat{y}_{1},\hat{y}_{2},\hat{y}_{3},……,\hat{y}_{t}] [y^1,y^2,y^3,……,y^t],计算该序列与真实标签 [ y 1 , y 2 , y 3 , … , y t ] [y_{1},y_{2},y_{3},…,y_{t}] [y1,y2,y3,…,yt]的差异,依赖该差异按最小二乘或梯度下降中的方法更新迭代𝜇和𝜃。
-
silon_{2} 求解完毕后,就可以被用于求解 求解完毕后,就可以被用于求解 求解完毕后,就可以被用于求解\epsilon_{3}$,这样就可以在训练中求解出所有的𝜖。
-
在第一次求解出所有的𝜖后,需要根据当前𝜖值的情况按公式求解出 [ y ^ 1 , y ^ 2 , y ^ 3 , … … , y ^ t ] [\hat{y}_{1},\hat{y}_{2},\hat{y}_{3},……,\hat{y}_{t}] [y^1,y^2,y^3,……,y^t],计算该序列与真实标签 [ y 1 , y 2 , y 3 , … , y t ] [y_{1},y_{2},y_{3},…,y_{t}] [y1,y2,y3,…,yt]的差异,依赖该差异按最小二乘或梯度下降中的方法更新迭代𝜇和𝜃。
-
迭代完毕后,再按照新的𝜇和𝜃重新计算𝜖,重复上述过程直至 [ y ^ 1 , y ^ 2 , y ^ 3 , … … , y ^ t ] [\hat{y}_{1},\hat{y}_{2},\hat{y}_{3},……,\hat{y}_{t}] [y^1,y^2,y^3,……,y^t],计算该序列与真实标签 [ y 1 , y 2 , y 3 , … , y t ] [y_{1},y_{2},y_{3},…,y_{t}] [y1,y2,y3,…,yt]的差异变得足够小为止。当迭代完成时,我们就能够求解出所有的𝜖以及所有的𝜇和𝜃。