一、背景
1.1、影响磁盘性能的因素:
主要受限于磁盘的寻道时间,优化磁盘数据访问的方法是尽量减少磁盘的IO次数。磁盘数据访问效率取决于磁盘IO次数,而磁盘IO次数又取决于数据在磁盘上的组织方式。磁盘数据存储大多采用B+树类型数据结构,这种数据结构针对磁盘数据的存储和访问进行了优化,减少访问数据时磁盘IO次数。
1.2、常用的数据结构
1.2.1、B+树
B+树是一种专门针对磁盘存储而优化的N叉排序树,以树节点为单位存储在磁盘中,从根开始查找所需数据所在的节点编号和磁盘位置,将其加载到内存中然后继续查找,直到找到所需的数据。
目前数据库多采用两级索引的B+树,树的层次最多三层。因此可能需要5次磁盘访问才能更新一条记录(三次磁盘访问获得数据索引及行ID,然后再进行一次数据文件读操作及一次数据文件写操作)。
但是由于每次磁盘访问都是随机的,而传统机械硬盘在数据随机访问时性能较差,每次数据访问都需要多次访问磁盘影响数据访问性能。
1.2.2、LSM树
LSM树可以看作是一个N阶合并树。LSM树本质上就是在读写之间取得平衡;
和B+树相比,它牺牲了部分读性能,用来大幅提高写性能。
它的原理是把一颗大树拆分成N棵小树, 它首先写入到内存中(内存没有寻道速度的问题,随机写的性能得到大幅提升),在内存中构建一颗有序小树,随着小树越来越大,内存的小树会flush到磁盘上。
当读时,由于不知道数据在哪棵小树上,因此必须遍历所有的小树,但在每颗小树内部数据是有序的。
数据写操作(包括插入、修改、删除)都在内存中进行,并且都会创建一个新记录(修改会记录新的数据值,而删除会记录一个删除标志),这些数据在内存中仍然还是一棵排序树,当数据量超过设定的内存阈值后,会将这棵排序树和磁盘上最新的排序树合并。当这棵排序树的数据量也超过设定阈值后,和磁盘上下一级的排序树合并。合并过程中,会用最新更新的数据覆盖旧的数据(或者记录为不同版本)。在需要进行读操作时,总是从内存中的排序树开始搜索,如果没有找到,就从磁盘上的排序树顺序查找。
在LSM树上进行一次数据更新不需要磁盘访问,在内存即可完成,速度远快于B+树。当数据访问以写操作为主,而读操作则集中在最近写入的数据上时,使用LSM树可以极大程度地减少磁盘的访问次数,加快访问速度。
Leveldb是Google开源的一个快速,轻量级的key-value存储引擎,以库的形式提供,没有提供上层c/s架构和网络通信的功能。Leveldb存储引擎的功能如下:
1、提供key-value存储,key和value是任意的二进制数据。数据是按照key有序存储的,可以修改排序规则。
2、只提供了Put/Get/Delete等基本操作接口,支持批量原子操作。
3、支持快照功能。
4、支持数据的正向和反向遍历访问。
5、支持数据压缩功能(Snappy压缩)。
6、支持多线程同步,但不支持多进程同时访问。
二、LevelDB的组成:
构成LevelDb静态结构的包括六个主要部分:内存中的MemTable和Immutable MemTable以及磁盘上的几种主要文件:Current文件、Manifest文件、log文件以及SSTable文件。如下图所示
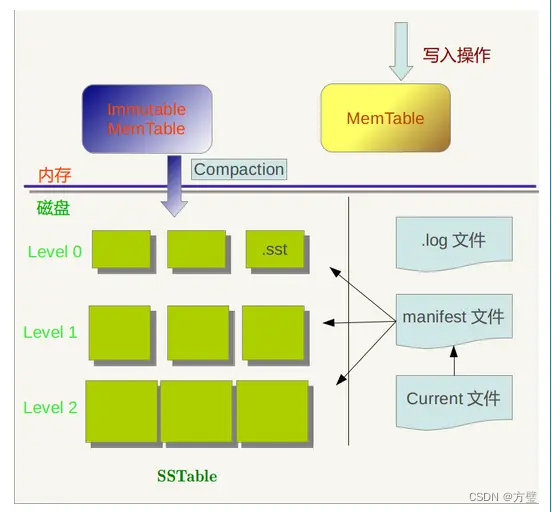
2.1、写操作:
我们通过写操作来综合了解下这几个文件:
当应用写入一条Key:Value记录的时候,LevelDb会先往log文件里追加写入,成功后将记录插进Memtable中,这样基本就算完成了写入操作,因为一次写入操作只涉及一次磁盘顺序写和一次内存写入,这是LevelDb写入速度极快的主要原因。
Log文件在系统中的作用主要是用于系统崩溃恢复而不丢失数据,假如没有Log文件,因为写入的记录刚开始是保存在内存中的,此时如果系统崩溃,内存中的数据还没有来得及Dump到磁盘,所以会丢失数据。为了避免这种情况,LevelDb在写入内存前先将操作记录到Log文件中,然后再记入内存中,这样即使系统崩溃,也可以从Log文件中恢复内存中的Memtable,不会造成数据的丢失。
当Memtable插入的数据占用内存到了一个界限后,需要将内存的记录导出到外存文件中,LevleDb会生成新的Log文件和Memtable,原先的Memtable就成为Immutable Memtable,顾名思义,就是说这个文件的内容是不可更改的。新到来的数据被记入新的Log文件和Memtable,LevelDb后台调度会将Immutable Memtable的数据导出到磁盘,形成一个新的SSTable文件。SSTable就是由内存中的数据不断导出并进行Compaction操作后形成的,而且SSTable的所有文件是一种层级结构,第一层为Level 0,第二层为Level 1,依次类推,层级逐渐增高,这也是为何称为LevelDb的原因。
SSTable中的文件是Key有序的,各个Level的SSTable都是如此,但是需要注意的是:Level 0的SSTable文件(后缀为.sst)和其它Level的文件相比有特殊性:这个层级内的.sst文件,两个文件可能存在key重叠,比如有两个level 0的sst文件,文件A和文件B,文件A的key范围是:{bar, car},文件B的Key范围是{blue,samecity},那么很可能两个文件都存在key=”blood”的记录。对于其它Level的SSTable文件来说,则不会出现同一层级内.sst文件的key重叠现象,就是说Level L中任意两个.sst文件,那么可以保证它们的key值是不会重叠的。这点需要特别注意。
SSTable中的某个文件属于特定层级,而且其存储的记录是key有序的,那么必然有文件中的最小key和最大key,这是非常重要的信息。Manifest就是记载SSTable各个文件的管理信息,比如属于哪个Level,文件名称叫什么,最小key和最大key各自是多少。
Current文件是记载当前的manifest文件名。因为在LevleDb的运行过程中,随着Compaction的进行,SSTable文件会发生变化,会有新的文件产生,老的文件被废弃,Manifest也会跟着反映这种变化,此时往往会新生成Manifest文件来记载这种变化,而Current则用来指出哪个Manifest文件才是我们关心的那个Manifest文件。
当某个level下的SSTable文件数目超过一定设置值后,levelDb会从这个level的SSTable中选择n个文件(level>0时,n=1;level=0时因key有重叠,n>=1),将其和高一层级的level+1的SSTable文件合并,这就是major compaction。 对于 compaction,下文具体分析。
另外,LevelDB的写操作是线程安全的:LevelDB Write 的线程安全是通过将所有的写入插入到一个队列中, 然后有且仅有一个线程去消费这个队列来做到的. 消费这个队列的线程会把队列头部的几个Batch合并成一个大的Batch 一起消费掉, 也是为了提高效率.
log文件内是key无序的,而Memtable中是key有序的,如何实现LevelDB的删除操作?对于levelDb来说,并不存在立即删除的操作,而是与插入操作相同的,区别是,插入操作插入的是Key:Value 值,而删除操作插入的是“Key:删除标记”,并不真正去删除记录,而是后台Compaction的时候才去做真正的删除操作。
2.2、读取记录
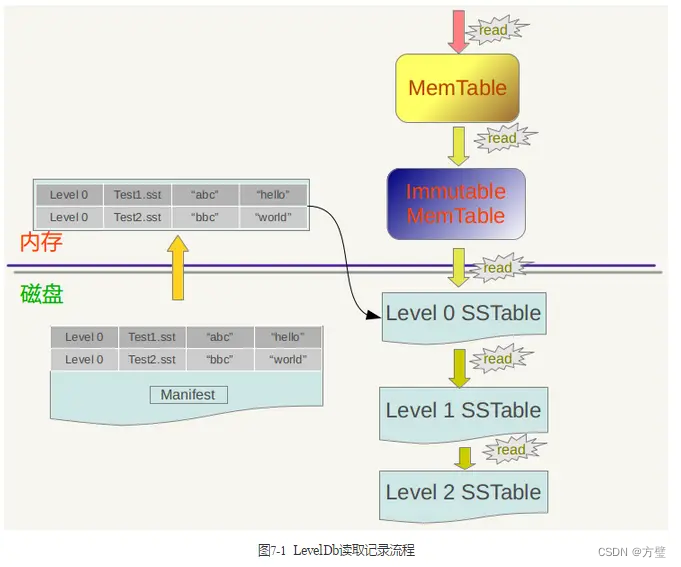
1、LevelDB首先会去查看内存中的Memtable,如果Memtable中包含key及其对应的value,则返回value值即可;
2、如果在Memtable没有读到key,则接下来到同样处于内存中的Immutable Memtable中去读取,类似地,如果读到就返回;
3、若是没有读到,那么只能万般无奈下从磁盘中的大量SSTable文件中查找。因为SSTable数量较多,而且分成多个Level,首先从属于level 0的文件中查找,如果找到则返回对应的value值,如果没有找到那么到level 1中的文件中去找,如此循环往复,直到在某层SSTable文件中找到这个key对应的value为止(或者查到最高level,查找失败,说明整个系统中不存在这个Key)。
2.2.1、为何选择是从低level到高level的查询路径
1、从信息的更新时间来说,很明显Memtable存储的是最新鲜的KV对;
2、Immutable Memtable中存储的KV数据对的新鲜程度次之;而所有SSTable文件中的KV数据新鲜程度一定不如内存中的Memtable和Immutable Memtable的。
3、对于SSTable文件来说,如果同时在level L和Level L+1找到同一个key,level L的信息一定比level L+1的要新。也就是说,上面列出的查找路径就是按照数据新鲜程度排列出来的,越新鲜的越先查找。同样的key,不同的value;逻辑上理解好像levelDb中只有一个存储记录,即最新的记录,但是在levelDb中很可能存在两条记录,比如记录分别存在Level L和Level L+1中。如果同时在level L和Level L+1找到同一个key,level L的信息一定比level L+1的要新。从道理上讲呢,Level L+1的数据是从Level L 经过Compaction后得到的,Level L比Level L+1的数据要新鲜。
2.2.2、SSTable文件很多,如何快速地找到key对应的value值
1、在LevelDb中,在level 0和其它level中查找某个key的过程是不一样的。
2、因为level 0下的不同文件可能key的范围有重叠,某个要查询的key有可能多个文件都包含,这样的话LevelDb的策略是先找出level 0中哪些文件包含这个key(manifest文件中记载了level和对应的文件及文件里key的范围信息,LevelDb在内存中保留这种映射表), 之后按照文件的新鲜程度排序,新的文件排在前面,之后依次查找,读出key对应的value。而如果是非level 0的话,因为这个level的文件之间key是不重叠的,所以只从一个文件就可以找到key对应的value。
3、如果给定一个要查询的key和某个key range包含这个key的SSTable文件,那么levelDb一般会先在内存中的Cache中查找是否包含这个文件的缓存记录,如果包含,则从缓存中读取;如果不包含,则打开SSTable文件,同时将这个文件的索引部分加载到内存中并放入Cache中。 这样Cache里面就有了这个SSTable的缓存项,但是只有索引部分在内存中,之后levelDb根据索引可以定位到哪个内容Block会包含这条key,从文件中读出这个Block的内容,在根据记录一一比较,如果找到则返回结果,如果没有找到,那么说明这个level的SSTable文件并不包含这个key,所以到下一级别的SSTable中去查找。
2.3、Compaction操作
LevelDB的compaction操作包含minor compaction和major compaction两种
Minor compaction 的目的是当内存中的memtable大小到了一定值时,将内容保存到磁盘文件中,如下图所示
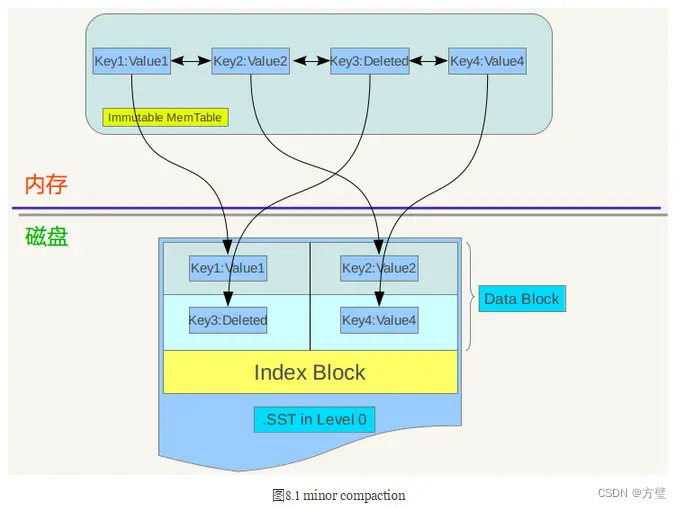
从上图可以看出,
1、当memtable数量到了一定程度会转换为immutable memtable,此时不能往其中写入记录,只能从中读取KV内容。immutable memtable其实是一个多层级队列SkipList,其中的记录是根据key有序排列的。按照immutable memtable中记录由小到大遍历,并依次写入一个level 0 的新建SSTable文件中,写完后建立文件的index 数据,这样就完成了一次minor compaction。从图中也可以看出,对于被删除的记录,在minor compaction过程中并不真正删除这个记录,原因也很简单,这里只知道要删掉key记录,但是这个KV数据在哪里?那需要复杂的查找,所以在minor compaction的时候并不做删除,只是将这个key作为一个记录写入文件中,至于真正的删除操作,在以后更高层级的compaction中会去做。
2、当某个level下的SSTable文件数目超过一定设置值后,levelDb会从这个level的SSTable中选择一个文件(level>0),将其和高一层级的level+1的SSTable文件合并,这就是major compaction。
在大于0的层级中,每个SSTable文件内的Key都是由小到大有序存储的,而且不同文件之间的key范围(文件内最小key和最大key之间)不会有任何重叠。但是因为level 0的文件是通过minor compaction直接生成的,所以任意两个level 0下的两个sstable文件可能再key范围上有重叠。所以在做major compaction的时候,对于大于level 0的层级,选择其中一个文件就行,但是对于level 0来说,指定某个文件后,本level中很可能有其他SSTable文件的key范围和这个文件有重叠,这种情况下,要找出所有有重叠的文件和level 1的文件进行合并,即level 0在进行文件选择的时候,可能会有多个文件参与major compaction。
levelDb在选定某个level进行compaction后,还要选择是具体哪个文件要进行compaction,levelDb采用轮流的方式,比如这次是文件A进行compaction,那么下次就是在key range上紧挨着文件A的文件B进行compaction,这样每个文件都会有机会轮流和高层的level 文件进行合并。
接着levelDb选择L+1层中和文件A在key range上有重叠的所有文件来和文件A进行合并。也就是说,选定了level L的文件A,之后在level L+1中找到了所有需要合并的文件B,C,D等。合并的过程如下:
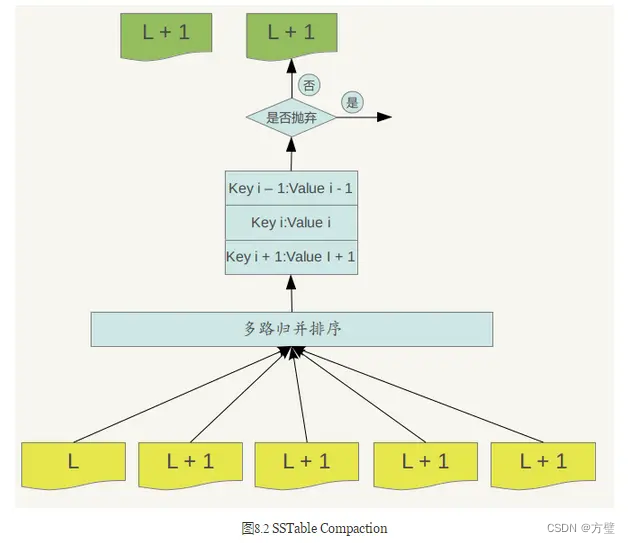
Major compaction的过程如下:对多个文件采用多路归并排序的方式,依次找出其中最小的Key记录,也就是对多个文件中的所有记录重新进行排序。之后采取一定的标准判断这个Key是否还需要保存,如果判断没有保存价值,那么直接抛掉,如果觉得还需要继续保存,那么就将其写入level L+1层中新生成的一个SSTable文件中。就这样对KV数据一一处理,形成了一系列新的L+1层数据文件,之前的L层文件和L+1层参与compaction 的文件数据此时已经没有意义了,所以全部删除。这样就完成了L层和L+1层文件记录的合并过程。在major compaction过程中,判断一个KV记录是否抛弃的其中一个标准是:对于某个key来说,如果在小于L层中存在这个Key,那么这个KV在major compaction过程中可以抛掉。因为对于层级低于L的文件中如果存在同一Key的记录,那么说明对于Key来说,有更新鲜的Value存在,那么过去的Value就等于没有意义了,所以可以删除。
大体了解了Level DB后,让我们来学习下Tair中的LDB。
ldb是基于leveldb开发的一款持久化产品,作为Tair的持久化存储引擎,适用于确实有持久化需求,richldb引擎内嵌Mdb作为内存KV级别cache,读写qps较高(万级别)的应用场景。ldb目前线上使用的ssd机型(SSD单机读10w qps 写2W tps (700B测试)),因此在成本上要比缓存型产品高出几倍。在支持的数据结构上和mdb相同,功能上ldb还支持范围查找,但基于性能考虑,需特别谨慎使用。
读流程
首先在MemTable文件中寻找,查看它的开始和结束是哪一部分,找到负责这个key的文件,从里面把这个数字给拿出来。对每一个LO都会去找,当然如果有一步能够找到就会提前返回。对于LeveIDB,会做一些聚合,尽量读一次盘能读少一些。
写流程
找到数据分区,存入操作指引,同时把结果插入到Mdb cache里。这样的话,持久化存储引擎的效率跟缓存性效率是一样的,如果数据有访问热点的话,访问的IP可以得到很好的保证。当memtable写满后dump成Level 0上的sstable,无数据合并。Level 会循环compact range。
Ldb的新功能
加入过期时间,嵌入一个datafilter逻辑,得到这个数据的时候会先过滤一下,比如设置一些过期数据,这个数据如果已经过期,它就会跳过去,就认为是不存在的。虽然持久化,但是就想把之前数据全部清掉,然后再写入新的,这样是有异步清理。它本身的compact是自己做的,有它内部自己的过程在level-n上做,这个过程当中现在主要做的工作就是把一些垃圾数据给清理了,在做机群变动的时候,因为Tair宕掉一台机器会做数据的重分布,导致数据备份的完整性和前端服务的可用性问题,这个过程可以把垃圾数据可以清理掉。如果按照自己的过程它不是很敏感,我们就要做高Levelcompact,我们会主动出发,加速一些range合并。使用binlog做异步跨集群数据同步。(这里还不是很清楚)
典型应用场景
1.存储黑白单数据,读qps很高,db无法承载。
2.计数器功能,更新非常频繁,且数据不可丢失。
RDB
名词解释:
Restful协议:(Representational State Transfer,资源是由URI来指定。对资源的操作包括获取、创建、修改和删除资源,这些操作正好对应HTTP协议提供的GET、POST、PUT和DELETE方法。通过操作资源的表现形式来操作资源。资源的表现形式则是XML或者HTML,取决于读者是机器还是人,是消费web服务的客户软件还是web浏览器。当然也可以是任何其他的格式。)
rdb是基于redis开发另一款内存型产品,tair抽取了redis内部存储引擎部分,支持redis所有数据结构,故rdb不仅支持key对应一个value的结构,同时也支持key对应多个value的结构,结构可以是list/map/set/zset。(注:很多同学会把value是一个map/list之类的对象和rdb支持的list/hash结构混为一谈。这里再强调一下,tair的key和value均为可序列化对象,因此如果value是map或者list之类的序列化之后的对象,这个还是属于key-value结构,而rdb支持的list/hash/set/zset,是指一个key对应多个value。比如:list就是key-{value1, value2, value3}。)设置限制内存quota,去除aof/vm,增加logiclock的概念,lazy清理db数据(比如想把area数据都清理掉,可能对当时运行会有影响,当后台再做的时候,可以根据前面访问的时候来比较一下logiclock,来确定这个数据是不是在它的生存周期里面,如果不在生存周期里面可以做清理,就是因为这个数据是不存在的。),特别适用容量小(一般在M级别,50G之内),读写qps高(万级别)的应用场景。由于是内存型产品,因此无法保证数据的安全性,对数据安全有要求的应用建议在后端加持久化数据源或使用ldb作为rdb的持久化。实现了Restful协议。

典型应用场景:
1.用list结构来显示最新的项目列表;
2.用sortedset来做排行榜,取Top N;
3.用set来做uniq操作,如页面访问者排重;
4.使用hset来做单key下多属性的项目,例如商品的基本信息,库存,价格等设置成多属性。
典型用法
- rdb集群应用,有复杂数据结构的需求。rdb不仅支持key对应一个value的结构,同时也支持key对应多个value的结构,结构可以是list/map/set/zset。
MDB
mdb是Tair最早的一款内存型产品,也是在公司内部应用最广泛的集中式缓存。特别适用容量小(一般在M级别,50G之内),读写QPS高(万级别)的应用场景。由于是内存型产品,因此无法保证数据的安全性,对数据安全有要求的应用建议在后端加持久化数据源(例如MySQL)
典型应用场景:
- 用于缓存,降低对后端数据库的访问压力。
- 临时数据存储,分钟级别后失效,偶尔部分数据丢失不会对业务产生较大影响。
- 读多写少,读qps达到万级别以上。
mdb是memche系统,在内存里面,真正内存管理使用page和slab。抽样出一个area的概念,有很多应用会共用,一个应用给第一个area,做一个逻辑分区,可以针对area获得配额,进行数据清除,不会影响其他的应用,做到逻辑分区。有些应用有些情况下,一些数据这段时间不想用,可以直接清掉,是可以支持的。
支持数据过期的应用,会有后台的一些逻辑来把它清理掉。它的内存使用率会是一个问题,所以会在一定时间去均衡slab,达到内存使用率优化。还对它各种操作、统计都做了很详细的监控,可以实时监控到这个集群的情况。
还有后台进程,后台进程能做两个事情,会定期对数据进行清理。另外一个为了内存利用率,会做一些均衡slab的管理,达到内存使用率的均衡。
典型用法
- session场景。这种场景一般访问量非常高,且对响应时间有很高的要求,对数据有一定的一致性要求。后端无数据源,数据丢失对应用影响不大。
作者:lxqfirst
链接:https://www.jianshu.com/p/91367e93612f
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。