Page Cache是如何产生和释放的,通俗一点,就是它的“生”(分配)与“死”(释放),即 Page Cache 的生命周期。
Page Cache产生
Page Cache有两种产生的方式:
Buffered I/O(标准 I/O);
Memory-Mapped I/O(存储映射 I/O)。
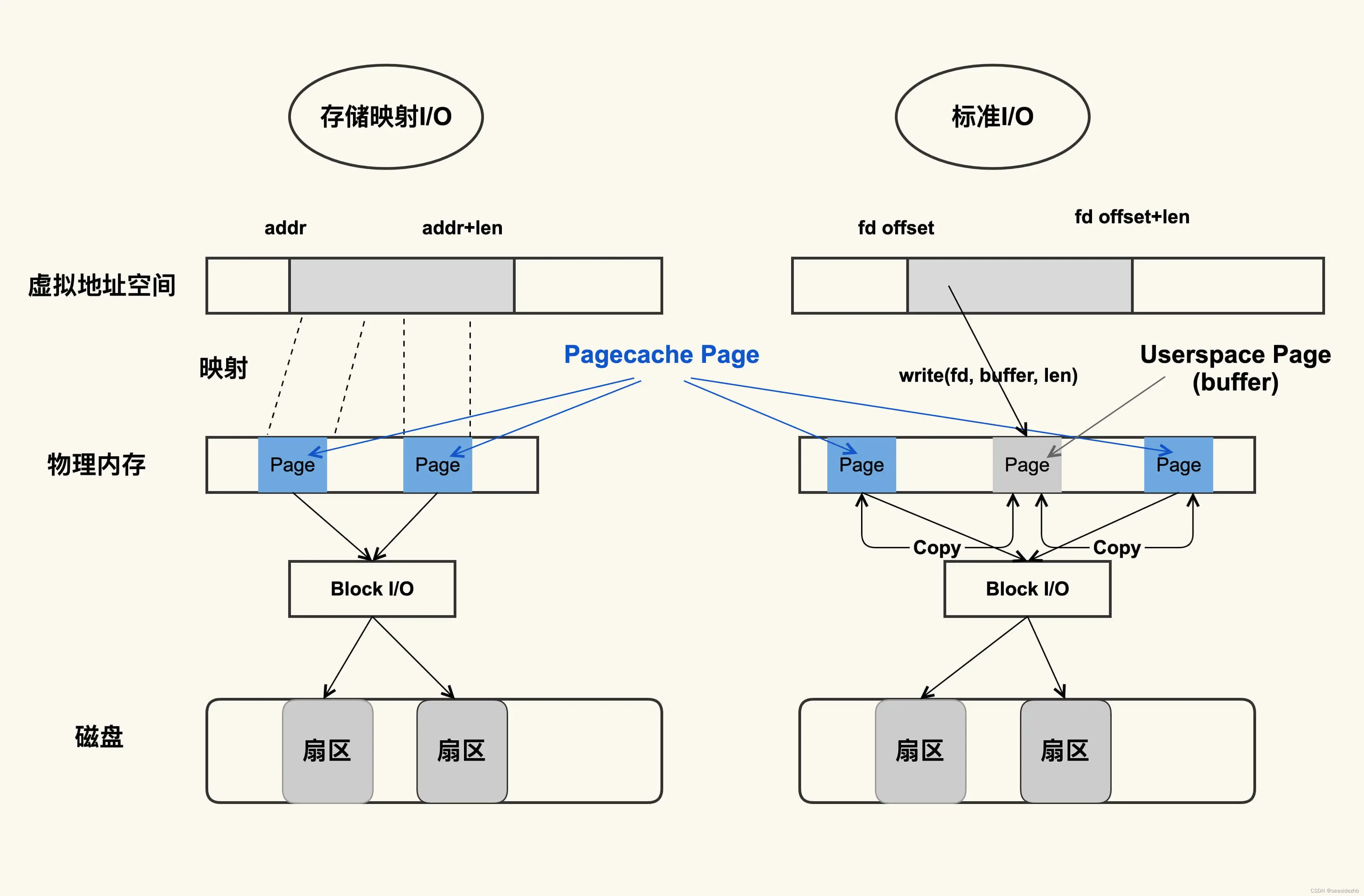
从图中可以看到,二者都可以产生Page Cache,但是两者产生的方式不同:
标准 I/O 是写的 (write(2)) 用户缓冲区 (Userpace Page 对应的内存),然后再将用户缓冲区里的数据拷贝到内核缓冲区 (Pagecache Page 对应的内存);如果是读的 (read(2)) 话则是先从内核缓冲区拷贝到用户缓冲区,再从用户缓冲区读数据,也就是 buffer 和文件内容不存在任何映射关系。
对于存储映射 I/O 而言,则是直接将 Pagecache Page 给映射到用户地址空间,用户直接读写 Pagecache Page 中内容。
显然,存储映射 I/O 要比标准 I/O 效率高一些,毕竟少了“用户空间到内核空间互相拷贝”的过程。这也是很多应用开发者发现,为什么使用内存映射 I/O 比标准 I/O 方式性能要好一些的主要原因。
接下来使用Shell脚本testPageCache.sh来演示一下Page Cache的产生。testPageCache.sh的内容如下所示:
#!/bin/sh
#这是我们用来解析的文件
MEM_FILE="/proc/meminfo"
#这是在该脚本中将要生成的一个新文件
NEW_FILE="/home/dd.write.out"
#我们用来解析的Page Cache的具体项
active=0
inactive=0
pagecache=0
IFS=' '
#从/proc/meminfo中读取File Page Cache的大小
function get_filecache_size()
{
items=0
while read line
do
if [[ "$line" =~ "Active:" ]]; then
read -ra ADDR <<<"$line"
active=${ADDR[1]}
let "items=$items+1"
elif [[ "$line" =~ "Inactive:" ]]; then
read -ra ADDR <<<"$line"
inactive=${ADDR[1]}
let "items=$items+1"
fi
if [ $items -eq 2 ]; then
break;
fi
done < $MEM_FILE
}
#读取File Page Cache的初始大小
get_filecache_size
let filecache="$active + $inactive"
#写一个新文件,该文件的大小为1048576 KB
dd if=/dev/zero of=$NEW_FILE bs=1024 count=1048576 &> /dev/null
#文件写完后,再次读取File Page Cache的大小
get_filecache_size
#两次的差异可以近似为该新文件内容对应的File Page Cache
#之所以用近似是因为在运行的过程中也可能会有其他Page Cache产生
let size_increased="$active + $inactive - $filecache"
#输出结果
echo "File size 1048576KB, File Cache increased" $size_increased
chmod u+x testPageCache.sh给testPageCache.sh当前用户加上可执行权限。

在这里提醒你一下,在运行该脚本前你要确保系统中有足够多的 free 内存(避免内存紧张产生回收行为)。
./testPageCache.sh执行。

通过这个脚本你可以看到,在创建一个文件的过程中,代码中 /proc/meminfo 里的 Active(file) 和 Inactive(file) 这两项会随着文件内容的增加而增加,它们增加的大小跟文件大小是一致的(这里之所以略有不同,是因为系统中还有其他程序在运行)。另外,如果你观察得很仔细的话,你会发现增加的 Page Cache 是 Inactive(File) 这一项。
这个过程看似简单,但是它涉及的内核机制还是很多的,换句话说,可能引起问题的地方还是很多的,我们用一张图简单描述下这个过程:
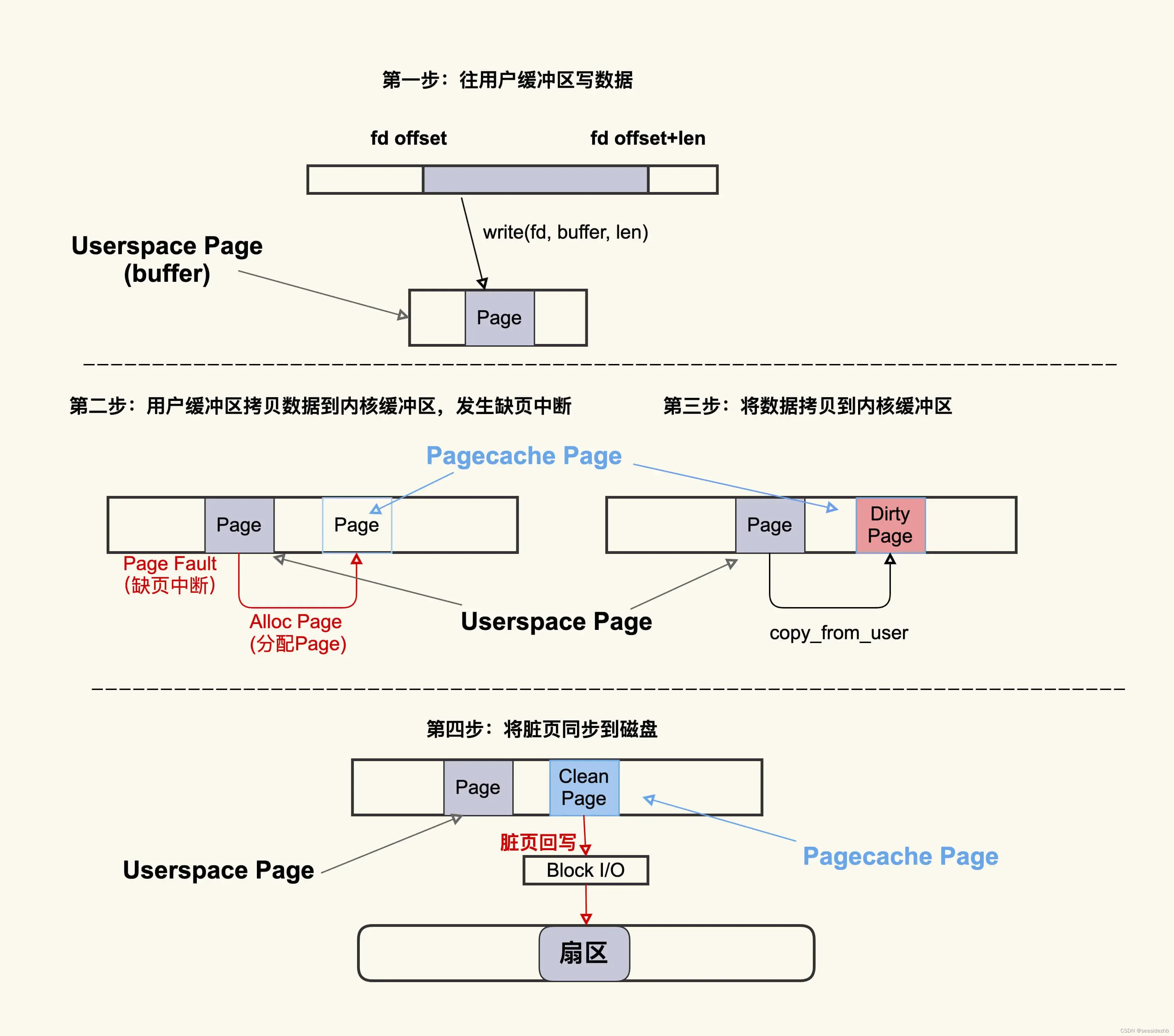
这个过程大致可以描述为:首先往用户缓冲区 buffer(这是 Userspace Page) 写入数据,然后 buffer 中的数据拷贝到内核缓冲区(这是 Pagecache Page),如果内核缓冲区中还没有这个 Page,就会发生 Page Fault 会去分配一个 Page,拷贝结束后该 Pagecache Page 是一个 Dirty Page(脏页),然后该 Dirty Page 中的内容会同步到磁盘,同步到磁盘后,该 Pagecache Page 变为 Clean Page 并且继续存在系统中。
可以将 Alloc Page 理解为 Page Cache 的“诞生”,将 Dirty Page 理解为 Page Cache 的婴幼儿时期(最容易生病的时期),将 Clean Page 理解为 Page Cache 的成年时期(在这个时期就很少会生病了)。
如果是读文件产生的 Page Cache,它的内容跟磁盘内容是一致的,所以它一开始是 Clean Page,除非改写了里面的内容才会变成 Dirty Page。
cat /proc/vmstat | egrep "dirty|writeback"可以用来监控Page Cache,nr_dirty 表示当前系统中积压了多少脏页,nr_writeback 则表示有多少脏页正在回写到磁盘中,他们两个的单位都是 Page(4KB)。

通常情况下,脏页积压不会有什么问题。如果积压得过多,在某些情况下也会容易引发问题。
Page Cache的回收
可以把 Page Cache 的回收行为 (Page Reclaim) 理解为 Page Cache 的“自然死亡”。
言归正传,我们知道,服务器运行久了后,系统中 free 的内存会越来越少,用 free 命令来查看,大部分都会是 used 内存或者 buff/cache 内存,free -g可以看一下内存使用情况。

free 命令中的 buff/cache 中的这些就是“活着”的 Page Cache,那它们什么时候会“死亡”(被回收)呢?我们来看一张图:
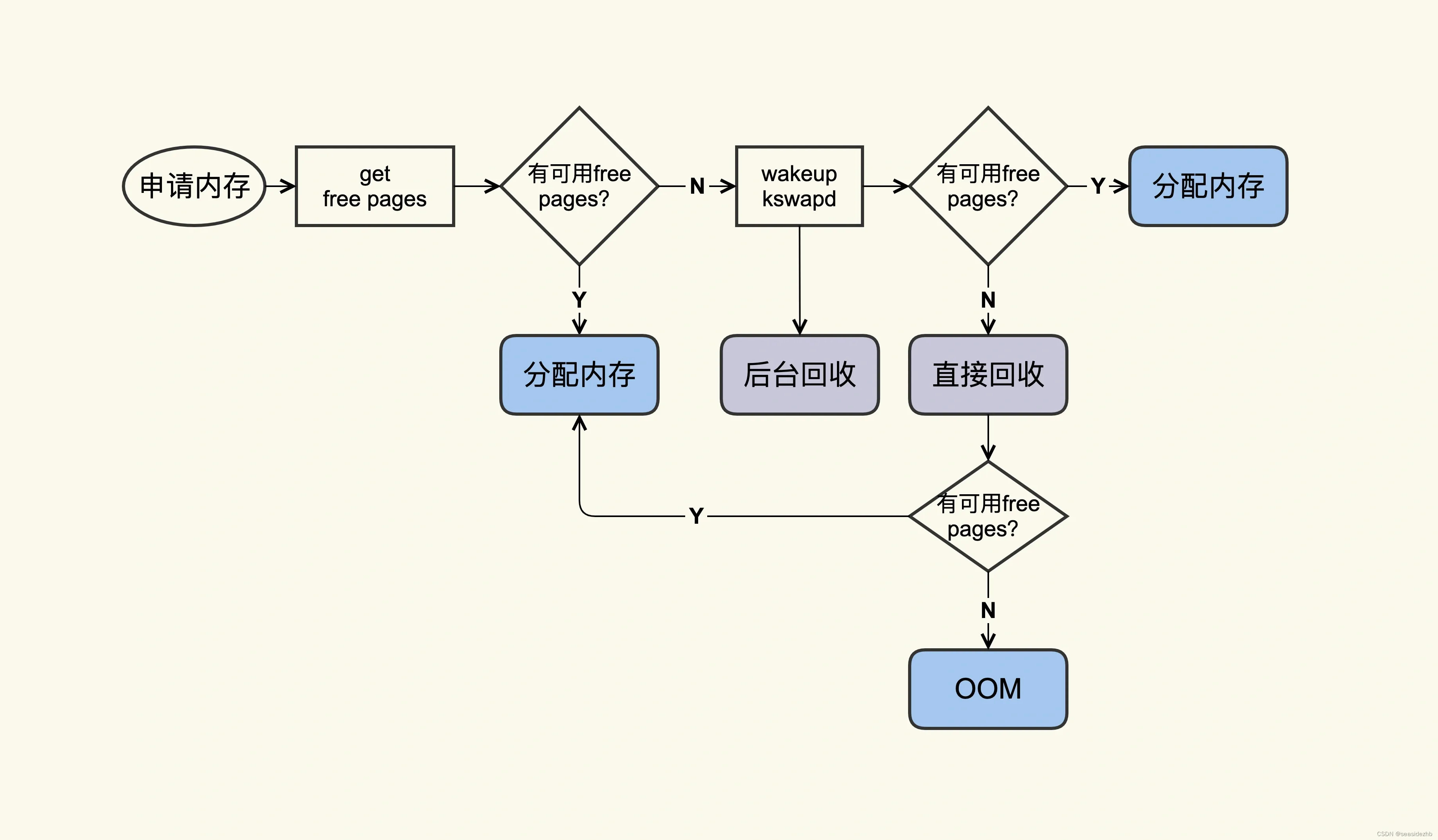
应用在申请内存的时候,即使没有 free 内存,只要还有足够可回收的 Page Cache,就可以通过回收 Page Cache 的方式来申请到内存,回收的方式主要是两种:直接回收和后台回收。
观察 Page Cache 直接回收和后台回收最简单方便的方式是使用 sar。sar -B 1就可以观察。
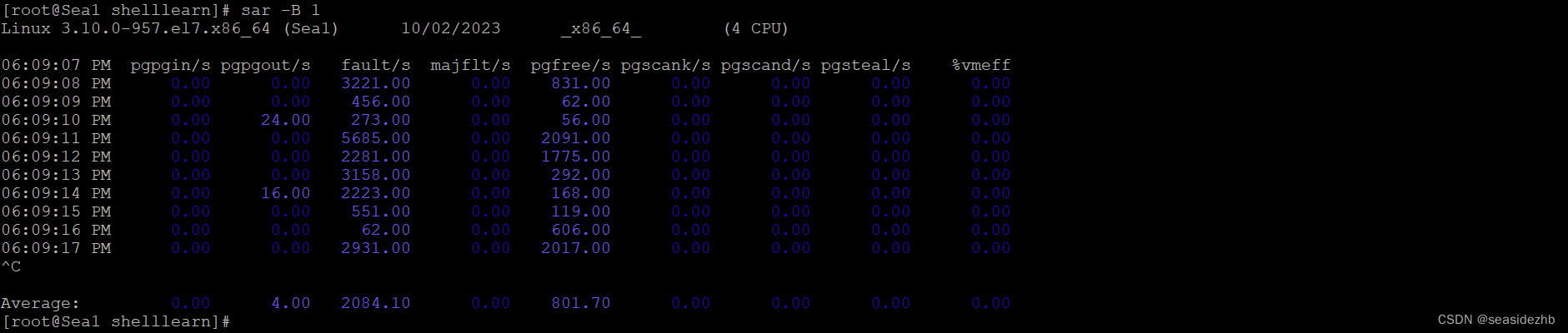
pgscank/s : kswapd(后台回收线程) 每秒扫描的 page 个数。
pgscand/s: Application 在内存申请过程中每秒直接扫描的 page 个数。
pgsteal/s: 扫描的 page 中每秒被回收的个数。
%vmeff: pgsteal/(pgscank+pgscand), 回收效率,越接近 100 说明系统越安全,越接近 0 说明系统内存压力越大。
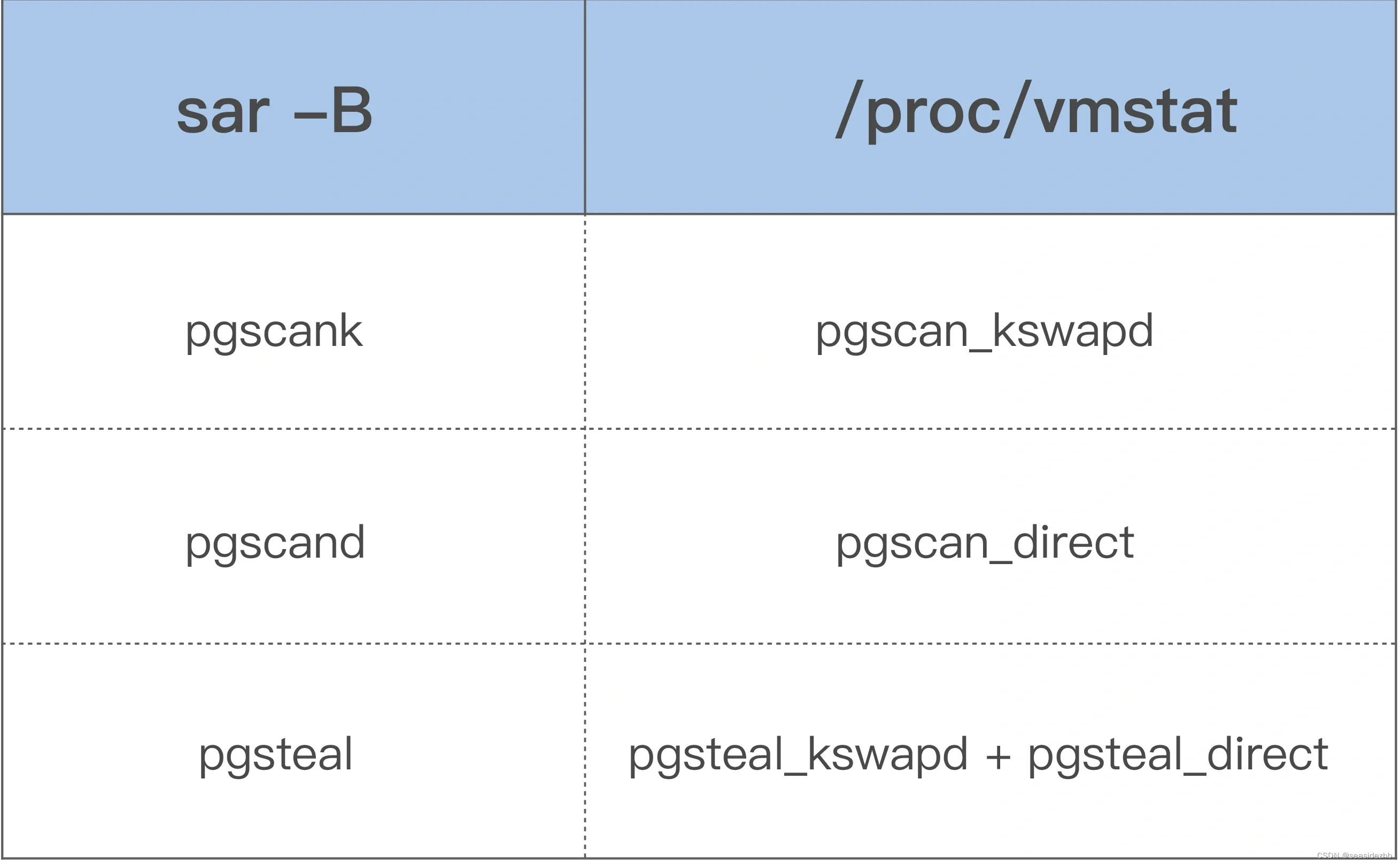
这几个指标也是通过解析 /proc/vmstat 里面的数据来得出的,对应关系如下:
此文章为10月Day 学习笔记,内容来源于极客时间《Linux 内核技术实战课》

![[BJDCTF2020]The mystery of ip](https://img-blog.csdnimg.cn/444d4f8816e948c98d008dd8c4c461da.png)