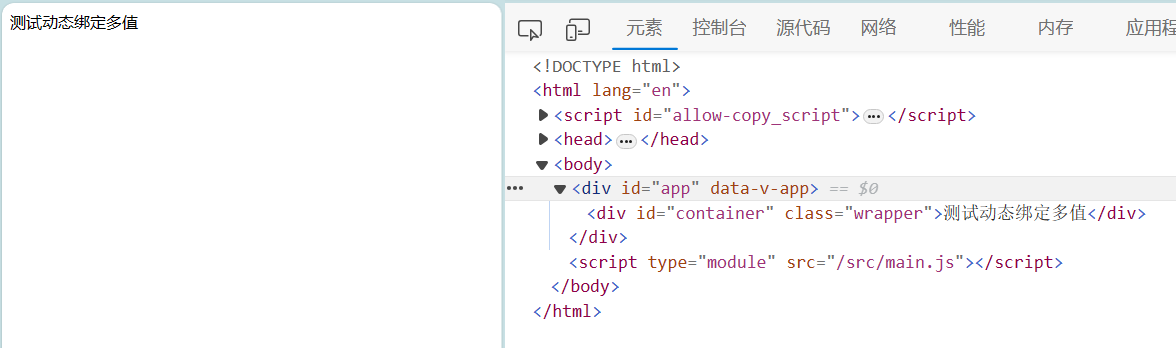
AI视野·今日CS.CV 计算机视觉论文速览
Mon, 2 Oct 2023 (showing first 100 of 112 entries)
Totally 100 papers
👉上期速览✈更多精彩请移步主页

Daily Computer Vision Papers
| Multi-task View Synthesis with Neural Radiance Fields Authors Shuhong Zheng, Zhipeng Bao, Martial Hebert, Yu Xiong Wang 多任务视觉学习是计算机视觉的一个重要方面。然而,目前的研究主要集中在多任务密集预测设置上,忽视了内在的3D世界及其多视图一致结构,缺乏通用的想象力。针对这些限制,我们提出了一种新颖的问题设置多任务视图合成 MTVS,它将多任务预测重新解释为一组针对多个场景属性(包括 RGB)的新颖视图合成任务。为了解决 MTVS 问题,我们提出了 MuvieNeRF,一个结合了多任务和交叉视图知识来同时合成多个场景属性的框架。 MuvieNeRF 集成了两个关键模块,即跨任务注意力 CTA 和跨视图注意力 CVA 模块,从而实现跨多个视图和任务的信息的高效利用。对合成和现实基准的广泛评估表明,MuvieNeRF 能够同时合成具有良好视觉质量的不同场景属性,甚至在各种设置中优于传统的判别模型。值得注意的是,我们表明 MuvieNeRF 在一系列 NeRF 主干中表现出普遍适用性。 |
| SMPLer-X: Scaling Up Expressive Human Pose and Shape Estimation Authors Zhongang Cai, Wanqi Yin, Ailing Zeng, Chen Wei, Qingping Sun, Yanjun Wang, Hui En Pang, Haiyi Mei, Mingyuan Zhang, Lei Zhang, Chen Change Loy, Lei Yang, Ziwei Liu 富有表现力的人体姿势和形状估计 EHPS 将身体、手和面部运动捕捉与众多应用相结合。尽管取得了令人鼓舞的进展,但当前最先进的方法仍然在很大程度上依赖于有限的训练数据集。在这项工作中,我们研究了将 EHPS 扩展到第一个名为 SMPLer X 的通用基础模型,以 ViT Huge 作为骨干,并使用来自不同数据源的多达 450 万个实例进行训练。凭借大数据和大模型,SMPLer X 在不同的测试基准中表现出强大的性能,甚至在未见过的环境中也具有出色的可移植性。 1 对于数据扩展,我们对 32 个 EHPS 数据集进行了系统调查,涵盖了在任何单个数据集上训练的模型无法处理的各种场景。更重要的是,利用从广泛的基准测试过程中获得的见解,我们优化了培训方案并选择了能够使 EHPS 能力实现重大飞跃的数据集。 2 对于模型缩放,我们利用视觉转换器来研究EHPS中模型尺寸的缩放规律。此外,我们的微调策略将 SMPLer X 转变为专业模型,使它们能够实现进一步的性能提升。 |
| LLM-grounded Video Diffusion Models Authors Long Lian, Baifeng Shi, Adam Yala, Trevor Darrell, Boyi Li 文本条件扩散模型已成为神经视频生成的有前途的工具。然而,当前的模型仍然难以应对复杂的时空提示,并且经常产生受限或不正确的运动,例如,甚至缺乏提示物体从左向右移动的能力。为了解决这些限制,我们引入了 LLM 接地视频扩散 LVD。 LVD 不是直接从文本输入生成视频,而是首先利用大型语言模型 LLM 基于文本输入生成动态场景布局,然后使用生成的布局来指导视频生成的扩散模型。我们表明,法学硕士能够仅从文本中理解复杂的时空动态,并生成与现实世界中通常观察到的提示和对象运动模式紧密结合的布局。然后,我们建议通过调整注意力图来指导使用这些布局的视频扩散模型。我们的方法是免费训练的,可以集成到任何允许分类器指导的视频扩散模型中。 |
| FACTS: First Amplify Correlations and Then Slice to Discover Bias Authors Sriram Yenamandra, Pratik Ramesh, Viraj Prabhu, Judy Hoffman 计算机视觉数据集经常包含任务相关标签和易于学习的潜在任务不相关属性之间的虚假相关性,例如语境 。在此类数据集上训练的模型会学习捷径,并且在相关性不成立的偏差冲突数据切片上表现不佳。在这项工作中,我们研究了识别此类切片的问题,以告知下游偏差缓解策略。我们提出首先放大相关性,然后切片以发现偏差事实,其中我们首先通过强正则化的经验风险最小化来放大相关性以适应简单的偏差对齐假设。接下来,我们通过偏差对齐特征空间中的混合建模执行相关性感知切片,以发现捕获不同相关性的表现不佳的数据切片。尽管很简单,但我们的方法在各种不同评估设置的相关偏差识别方面比之前的工作显着提高了 35 精度 10。 |
| Classification of Potholes Based on Surface Area Using Pre-Trained Models of Convolutional Neural Network Authors Chauhdary Fazeel Ahmad, Abdullah Cheema, Waqas Qayyum, Rana Ehtisham, Muhammad Haroon Yousaf, Junaid Mir, Nasim Shakouri Mahmoudabadi, Afaq Ahmad 坑洼是致命的,可能对车辆造成严重损坏,并可能导致致命事故。在南亚国家,由于路基条件差、地下排水缺乏和降雨过多,路面病害是主要原因。本研究比较了三种预训练的卷积神经网络 CNN 模型(即 ResNet 50、ResNet 18 和 MobileNet)的性能。首先,对路面图像进行分类,以确定图像是否包含坑洼,即坑洼或正常。其次,路面图像被分为三类,即小坑洼、大坑洼和正常。路面图像是从 3.5 英尺腰高和 2 英尺处拍摄的。 MobileNet v2 检测坑洼的准确度为 98。在 2 英尺高度拍摄的图像的分类对于大型、小型和普通路面的分类准确度分别为 87.33 、88.67 和 92 。 |
| The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision) Authors Zhengyuan Yang, Linjie Li, Kevin Lin, Jianfeng Wang, Chung Ching Lin, Zicheng Liu, Lijuan Wang 大型多模态模型 LMM 通过多感官技能(例如视觉理解)扩展大型语言模型 LLM,以实现更强大的通用智能。在本文中,我们分析了最新的模型 GPT 4V ision,以加深对 LMM 的理解。分析重点关注 GPT 4V 可以执行的有趣任务,包含测试样本来探究 GPT 4V 功能的质量和通用性、其支持的输入和工作模式以及提示模型的有效方法。在探索 GPT 4V 的方法中,我们策划和组织了一系列精心设计的定性样本,涵盖各个领域和任务。对这些样本的观察表明,GPT 4V 在处理任意交错的多模态输入方面具有前所未有的能力,其功能的通用性共同使 GPT 4V 成为强大的多模态通用系统。此外,GPT 4V 独特的理解输入图像上绘制的视觉标记的能力可以催生新的人机交互方法,例如视觉参考提示。我们在报告最后深入讨论了基于 GPT 4V 的系统的新兴应用场景和未来研究方向。 |
| Directly Fine-Tuning Diffusion Models on Differentiable Rewards Authors Kevin Clark, Paul Vicol, Kevin Swersky, David J Fleet 我们提出了直接奖励微调 DRaFT,这是一种简单有效的方法,用于微调扩散模型,以最大化可微分奖励函数,例如来自人类偏好模型的分数。我们首先证明,可以通过完整的采样过程反向传播奖励函数梯度,并且这样做可以在各种奖励上实现出色的性能,优于基于强化学习的方法。然后,我们提出了更有效的 DRaFT 变体 DRaFT K(将反向传播截断为采样的最后 K 个步骤)和 DRaFT LV(当 K 为 1 时获得较低方差梯度估计)。我们表明,我们的方法适用于各种情况奖励函数,可用于大幅提高稳定扩散 1.4 生成的图像的美学质量。 |
| IFAST: Weakly Supervised Interpretable Face Anti-spoofing from Single-shot Binocular NIR Images Authors Jiancheng Huang, Donghao Zhou, Shifeng Chen 单次人脸反欺骗 FAS 是保护人脸识别系统安全的一项关键技术,它只需要静态图像作为输入。然而,由于两个主要原因,单次 FAS 仍然是一个具有挑战性且尚未得到探索的问题:1 在数据方面,从 RGB 图像学习 FAS 在很大程度上依赖于上下文,并且没有附加注释的单次图像包含有限的语义信息。 2 在模型方面,现有的单次 FAS 模型无法为其决策提供适当的证据,并且基于深度估计的 FAS 方法需要昂贵的每像素注释。为了解决这些问题,构建并发布了大型双目近红外图像数据集 BNI FAS,其中包含超过 300,000 张真实人脸和平面攻击图像,并提出了可解释的 FAS Transformer IFAST,只需弱监督即可产生可解释的预测。我们的 IFAST 可以通过所提出的具有动态匹配注意力 DMA 块的视差估计 Transformer 生成像素级视差图。此外,采用精心设计的置信图生成器与所提出的双师蒸馏模块配合以获得最终的判别结果。 |
| Forward Flow for Novel View Synthesis of Dynamic Scenes Authors Xiang Guo, Jiadai Sun, Yuchao Dai, Guanying Chen, Xiaoqing Ye, Xiao Tan, Errui Ding, Yumeng Zhang, Jingdong Wang 本文提出了一种神经辐射场 NeRF 方法,用于使用前向扭曲对动态场景进行新颖的视图合成。现有方法通常采用静态 NeRF 来表示规范空间,并通过使用学习的后向流场将采样的 3D 点映射回规范空间来渲染其他时间步长的动态图像。然而,这种反向流场是非平滑且不连续的,很难用常用的平滑运动模型来拟合。为了解决这个问题,我们建议估计前向流场并将规范辐射场直接扭曲到其他时间步长。这种向前的流场在目标区域内是平滑且连续的,这有利于运动模型的学习。为了实现这一目标,我们用体素网格表示规范辐射场,以实现高效的前向扭曲,并提出一种可微的扭曲过程,包括平均泼溅操作和修复网络,以解决多对一和一对多映射问题。彻底的实验表明,我们的方法在新颖的视图渲染和运动建模方面都优于现有方法,证明了我们的前向流动运动建模的有效性。 |
| Prompt-based test-time real image dehazing: a novel pipeline Authors Zixuan Chen, Zewei He, Ziqian Lu, Zhe Ming Lu 现有方法试图通过探索精心设计的训练方案(例如,cycleGAN、先验损失)来提高模型对现实世界模糊图像的泛化能力。然而,他们中的大多数需要非常复杂的训练程序才能达到令人满意的结果。在这项工作中,我们提出了一种全新的测试管道,称为基于提示的测试时间去雾 PTTD,以帮助在推理阶段生成真实捕获的模糊图像的视觉上令人愉悦的结果。我们通过实验发现,给定一个在合成数据上训练的去雾模型,通过微调编码特征的统计数据,即平均值和标准差,PTTD 能够缩小域间隙,从而提高真实图像去雾的性能。因此,我们首先应用提示生成模块 PGM 来生成视觉提示,这是平均值和标准差的适当统计扰动的来源。然后,我们将特征适应模块FAM应用到现有的去雾模型中,在生成的提示的指导下调整原始统计数据。请注意,PTTD 与模型无关,并且可以配备在合成模糊清洁对上训练的各种最先进的去雾模型。 |
| Network Memory Footprint Compression Through Jointly Learnable Codebooks and Mappings Authors Edouard Yvinec, Arnaud Dapogny, Kevin Bailly 计算能力的增长引发了人们对用于计算机视觉和自然语言处理的深度神经网络 DNN 的巨大兴趣。然而,这导致内存占用增加,以至于在移动电话等商用设备上简单地加载模型可能具有挑战性。为了解决这一限制,量化是一种受欢迎的解决方案,因为它将高精度张量映射到低精度、内存高效的格式。在减少内存占用方面,其最有效的变体是基于密码本的。然而,这些方法有两个限制。首先,他们要么为每个张量定义一个码本,要么使用内存昂贵的映射到多个码本。其次,映射的梯度下降优化有利于跳向极值,因此不定义近端搜索。在这项工作中,我们建议解决这两个限制。首先,我们最初对分布相似的神经元进行分组,并利用重新排序的结构将不同的比例因子应用于不同的组,或者将这些组中的权重映射到多个码本,而无需任何映射开销。其次,源于这种初始化,我们提出了码本和权重映射的联合学习,其与最近基于梯度的后训练量化技术具有相似之处。第三,通过直接估计技术进行估计,我们引入了一种新颖的梯度更新定义,以实现码本及其映射的近端搜索。 |
| Towards Free Data Selection with General-Purpose Models Authors Yichen Xie, Mingyu Ding, Masayoshi Tomizuka, Wei Zhan 理想的数据选择算法可以有效地选择信息最丰富的样本,以最大限度地利用有限的注释预算。然而,以主动学习方法为代表的当前方法通常遵循繁琐的流程,反复迭代耗时的模型训练和批量数据选择。在本文中,我们通过设计一个独特的数据选择管道来挑战这一现状,该管道利用现有的通用模型通过单遍推理从各种数据集中选择数据,而无需额外的训练或监督。在此新流程之后,提出了一种新颖的自由数据选择 FreeSel 方法。具体来说,我们定义从通用模型的中间特征中提取的语义模式,以捕获每个图像中微妙的局部信息。然后,我们可以在细粒度语义模式级别通过基于距离的采样一次选择所有数据样本。 FreeSel 绕过了繁重的批量选择过程,实现了效率的显着提高,并且比现有的主动学习方法快 530 倍。大量实验验证了 FreeSel 在各种计算机视觉任务上的有效性。 |
| See Beyond Seeing: Robust 3D Object Detection from Point Clouds via Cross-Modal Hallucination Authors Jianning Deng, Gabriel Chan, Hantao Zhong, Chris Xiaoxuan Lu 本文提出了一种通过跨模态幻觉从点云进行鲁棒 3D 物体检测的新颖框架。我们提出的方法与 LiDAR 和 4D 雷达之间的幻觉方向无关。我们在空间和特征层面上引入多重对齐,以实现同时骨干细化和幻觉生成。具体来说,提出了空间对齐来处理几何差异,以实现 LiDAR 和雷达之间更好的实例匹配。特征对齐步骤进一步弥合了传感模式之间的内在属性差距并稳定了训练。即使在推理阶段仅使用单模态数据作为输入,经过训练的目标检测模型也可以更好地处理困难的检测情况。 |
| Efficient Anatomical labeling of Pulmonary Tree Structures via Implicit Point-Graph Networks Authors Kangxian Xie, Jiancheng Yang, Donglai Wei, Ziqiao Weng, Pascal Fua 肺部疾病在全世界主要死亡原因中名列前茅。除其他外,治愈它们需要更好地了解肺部系统内许多复杂的 3D 树形结构,例如气道、动脉和静脉。理论上,可以使用高分辨率图像堆栈对它们进行建模。不幸的是,在密集体素网格上运行的标准 CNN 方法成本高昂。为了解决这个问题,我们引入了一种基于点的方法,该方法保留树骨架的图连接性并结合隐式表面表示。它以较低的计算成本提供 SOTA 精度,并且生成的模型具有可用的表面。 |
| Efficient Large Scale Medical Image Dataset Preparation for Machine Learning Applications Authors Stefan Denner, Jonas Scherer, Klaus Kades, Dimitrios Bounias, Philipp Schader, Lisa Kausch, Markus Bujotzek, Andreas Michael Bucher, Tobias Penzkofer, Klaus Maier Hein 在快速发展的医学成像领域,机器学习算法已成为提高诊断准确性不可或缺的一部分。然而,这些算法的有效性取决于高质量医学成像数据集的可用性和组织。医学中的传统数字成像和通信 DICOM 数据管理系统不足以处理机器学习算法所需的数据规模和复杂性。本文介绍了一种创新的数据管理工具,该工具是 Kaapana 开源工具包的一部分,旨在简化大规模医学成像数据集的组织、管理和处理。该工具专为满足放射科医生和机器学习研究人员的需求而定制。它结合了先进的搜索、自动注释和高效的标记功能,以改进数据管理。此外,该工具还有助于质量控制和审查,使研究人员能够验证大型数据集中的图像和分割质量。它还通过聚合和可视化元数据来发现数据集中的潜在偏差,这对于开发强大的机器学习模型至关重要。此外,Kaapana 已集成到放射合作网络 RACOON 中,这是一项开创性举措,旨在创建一个全面的国家基础设施,用于在德国所有大学诊所聚合、传输和整合放射数据。 |
| Information Flow in Self-Supervised Learning Authors Zhiquan Tan, Jingqin Yang, Weiran Huang, Yang Yuan, Yifan Zhang 在本文中,我们提供了一个全面的工具箱,用于通过矩阵信息论的视角理解和增强自监督学习 SSL 方法。具体来说,通过利用矩阵互信息和联合熵的原理,我们为基于对比和特征去相关的方法提供了统一的分析。此外,我们提出了基于矩阵信息理论的矩阵变分掩蔽自动编码器 M MAE 方法,作为掩蔽图像建模的增强。 |
| Effect of structure-based training on 3D localization precision and quality Authors Armin Abdehkakha, Craig Snoeyink 本研究介绍了单分子定位显微镜 SMLM 和 3D 对象重建中基于 CNN 的算法的基于结构的训练方法。我们将这种方法与传统的基于随机的训练方法进行比较,利用 LUENN 包作为我们的 AI 管道。定量评估表明,基于结构的训练方法在检测率和定位精度方面有显着提高,特别是在不同的信噪比 SNR 方面。此外,该方法有效去除棋盘伪影,确保更准确的 3D 重建。 |
| A Foundation Model for General Moving Object Segmentation in Medical Images Authors Zhongnuo Yan, Tong Han, Yuhao Huang, Lian Liu, Han Zhou, Jiongquan Chen, Wenlong Shi, Yan Cao, Xin Yang, Dong Ni 医学图像分割旨在描绘感兴趣的解剖或病理结构,在临床诊断中发挥着至关重要的作用。大量高质量的标注数据对于构建高精度深度分割模型至关重要。然而,由于巨大的标签空间和较差的帧间一致性,医学注释非常繁琐且耗时,尤其是对于医学视频或 3D 体积。最近,一项名为“移动对象分割 MOS”的基本任务在自然图像方面取得了重大进展。其目标是在图像序列中从背景中描绘出移动物体,只需要最少的注释。在本文中,我们针对医学图像中的 MOS 提出了第一个基础模型,名为 iMOS。对大型多模态医学数据集的大量实验验证了所提出的 iMOS 的有效性。具体来说,通过仅对序列中的少量图像进行标注,iMOS可以在整个序列的双向上实现令人满意的运动物体跟踪和分割性能。 |
| Consistent123: One Image to Highly Consistent 3D Asset Using Case-Aware Diffusion Priors Authors Yukang Lin, Haonan Han, Chaoqun Gong, Zunnan Xu, Yachao Zhang, Xiu Li 在预训练的扩散模型的指导下,从单个图像重建 3D 对象已经证明了有希望的结果。然而,由于采用与案例无关的刚性策略,它们对任意案例的泛化能力和重建的3D一致性仍然很差。在这项工作中,我们提出了 Confluence123,这是一种案例感知的两阶段方法,用于从具有 2D 和 3D 扩散先验的一张图像进行高度一致的 3D 资产重建。在第一阶段,Constant123 仅利用 3D 结构先验来进行充分的几何利用,并在此过程中嵌入基于 CLIP 的案例感知自适应检测机制。在第二阶段,引入2D纹理先验并逐渐发挥主导指导作用,精细地雕刻3D模型的细节。 Consolidated123 更紧密地符合制导要求的发展趋势,自适应地为不同对象提供足够的 3D 几何初始化和合适的 2D 纹理细化。 Consolidated123可以获得高度3D一致的重建,并且在各种对象上表现出很强的泛化能力。定性和定量实验表明,我们的方法明显优于最先进的 3D 图像方法。 |
| A Survey on Deep Learning Techniques for Action Anticipation Authors Zeyun Zhong, Manuel Martin, Michael Voit, Juergen Gall, J rgen Beyerer 预测未来可能的人类行为的能力对于包括自动驾驶和人机交互在内的广泛应用至关重要。因此,近年来,人们引入了多种用于动作预测的方法,其中基于深度学习的方法尤其流行。在这项工作中,我们回顾了动作预期算法的最新进展,特别关注日常生活场景。此外,我们根据这些方法的主要贡献对其进行分类,并以表格形式进行总结,让读者一目了然地掌握细节。 |
| EGVD: Event-Guided Video Deraining Authors Yueyi Zhang, Jin Wang, Wenming Weng, Xiaoyan Sun, Zhiwei Xiong 随着深度学习的快速发展,视频去雨取得了长足的进步。然而,现有的视频去雨管道对于具有复杂时空分布的雨层的场景无法达到令人满意的性能。在本文中,我们通过使用事件摄像机来实现视频除雨。作为神经形态传感器,事件相机适合非匀速运动和动态光照条件的场景。我们提出了一种基于端到端学习的网络,以释放事件摄像机在视频除雨方面的潜力。首先,我们设计了一个事件感知运动检测模块,以使用事件感知掩模自适应地聚合多帧运动上下文。其次,我们设计了一个金字塔自适应选择模块,通过结合多模态上下文先验来可靠地分离背景层和雨层。此外,我们构建了一个由雨天视频和时间同步事件流组成的真实世界数据集。我们将我们的方法与合成和自我收集的现实世界数据集上最先进的方法进行比较,证明我们的方法具有明显的优越性。 |
| When Epipolar Constraint Meets Non-local Operators in Multi-View Stereo Authors Tianqi Liu, Xinyi Ye, Weiyue Zhao, Zhiyu Pan, Min Shi, Zhiguo Cao 基于学习的多视图立体 MVS 方法严重依赖于特征匹配,这需要独特的描述性表示。一个有效的解决方案是应用非局部特征聚合,例如 Transformer。尽管这些技术很有用,但会给 MVS 带来大量的计算开销。每个像素都密集地关注整个图像。相反,我们建议将非局部特征增强限制在一对线内,每个点仅关注相应的一对极线。我们的想法受到经典对极几何的启发,它表明具有不同深度假设的一个点将投影到另一个视图上的极线。此约束将立体匹配中的 2D 搜索空间减少到极线内。类似地,这表明MVS的匹配是为了区分位于同一条线上的一系列点。受点对线搜索的启发,我们设计了一种线对点非局部增强策略。我们首先设计了一种优化搜索算法,将 2D 特征图分割成极线对。然后,极线变压器 ET 在极线对之间执行非局部特征增强。我们将 ET 纳入基于学习的 MVS 基线,命名为 ET MVSNet。 ET MVSNet 在 DTU 和 Tanks and Temples 基准测试上以高效率实现了最先进的重建性能。 |
| Instant Complexity Reduction in CNNs using Locality-Sensitive Hashing Authors Lukas Meiner, Jens Mehnert, Alexandru Paul Condurache 为了降低在资源受限设备上使用的卷积神经网络 CNN 的计算成本,结构化剪枝方法已显示出可喜的结果,可大幅减少浮点运算 FLOP,而不会大幅降低精度。然而,大多数最新方法需要微调或特定的训练程序,以在保留的准确性和减少 FLOP 之间实现合理的权衡。这会带来计算开销形式的额外成本,并且需要提供可用的训练数据。为此,我们提出了 HASTE Hashing for Tractable Efficiency ,这是一个无参数、无数据的模块,可以作为任何常规卷积模块的即插即用替代品。它立即降低了网络的测试时间推理成本,无需任何训练或微调。通过使用局部敏感哈希 LSH 来检测通道维度中的冗余,我们能够在不牺牲太多准确性的情况下大幅压缩潜在特征图。相似的通道被聚合以同时减少输入和滤波器深度,从而实现更便宜的卷积。我们在流行的视觉基准 CIFAR 10 和 ImageNet 上展示了我们的方法。 |
| Towards Complex-query Referring Image Segmentation: A Novel Benchmark Authors Wei Ji, Li Li, Hao Fei, Xiangyan Liu, Xun Yang, Juncheng Li, Roger Zimmermann 参考图像理解 RIS 在过去十年中得到了广泛的研究,导致了先进算法的发展。然而,缺乏研究来调查现有算法如何与复杂的语言查询进行基准测试,其中包括对周围物体和背景的更多信息描述,例如给黑色汽车发短信。与发短信相比,黑色汽车停在道路上和公共汽车旁边。 。鉴于大型预训练模型的语义理解能力有了显着提高,通过结合类似于现实世界应用程序的复杂语言,在 RIS 中进一步迈出至关重要的一步。为了缩小这一差距,在现有的 RefCOCO 和 Visual Genome 数据集的基础上,我们提出了一个具有复杂查询的新 RIS 基准,即 textbf RIS CQ 。 RIS CQ数据集质量高、规模大,以丰富、具体、信息丰富的查询挑战现有的RIS,使RIS研究更加真实。 |
| PARF: Primitive-Aware Radiance Fusion for Indoor Scene Novel View Synthesis Authors Haiyang Ying, Baowei Jiang, Jinzhi Zhang, Di Xu, Tao Yu, Qionghai Dai, Lu Fang 本文提出了一种快速场景辐射场重建方法,具有强大的新颖视图合成性能和方便的场景编辑功能。其关键思想是充分利用语义解析和图元提取来约束和加速辐射场重建过程。为了实现这一目标,提出了一种基元感知混合渲染策略,以享受体积渲染和基元渲染的最佳效果。我们进一步贡献了一个重建管道,对每个输入帧迭代地进行基元解析和辐射场学习,成功地将语义、基元和辐射信息融合到单个框架中。 |
| TBD Pedestrian Data Collection: Towards Rich, Portable, and Large-Scale Natural Pedestrian Data Authors Allan Wang, Daisuke Sato, Yasser Corzo, Sonya Simkin, Aaron Steinfeld 社交导航和行人行为研究已转向基于机器学习的方法,并集中在行人交互和行人机器人交互建模的主题上。为此,需要包含丰富信息的大规模数据集。我们描述了一个便携式数据收集系统,加上半自主标签管道。作为管道的一部分,我们设计了一个标签校正网络应用程序,有助于人工验证自动行人跟踪结果。我们的系统能够在不同的环境中进行大规模数据收集并快速生产轨迹标签。与现有的行人数据收集方法相比,我们的系统包含三个组件,即自上而下和以自我为中心的视图、在社交适当的机器人存在下的自然人类行为以及基于度量空间的人类验证标签的组合。据我们所知,现有的数据收集系统还没有同时具备这三个组件的组合。 |
| TextField3D: Towards Enhancing Open-Vocabulary 3D Generation with Noisy Text Fields Authors Tianyu Huang, Yihan Zeng, Bowen Dong, Hang Xu, Songcen Xu, Rynson W.H. Lau, Wangmeng Zuo 最近的作品在文本 3D 指导下明确学习 3D 表示。然而,有限的文本3D数据限制了词汇规模和世代文本控制。生成器很容易陷入对某些文本提示的刻板概念,从而失去开放词汇生成能力。为了解决这个问题,我们引入了一种条件 3D 生成模型,即 TextField3D。具体来说,我们建议不要直接使用文本提示作为输入,而是将动态噪声注入给定文本提示的潜在空间,即噪声文本字段 NTF。通过这种方式,有限的 3D 数据可以映射到 NTF 扩展的文本潜在空间的适当范围。为此,提出了 NTFGen 模块来对噪声领域中的通用文本潜在代码进行建模。同时,提出了 NTFBind 模块,将视图不变图像潜在代码与噪声场对齐,进一步支持图像条件 3D 生成。为了指导几何和纹理中的条件生成,使用文本 3D 判别器和文本 2.5D 判别器构建了多模态判别器。与之前的方法相比,TextField3D具有三个优点:1词汇量大、2文本一致性、3低延迟。 |
| Domain-Adaptive Learning: Unsupervised Adaptation for Histology Images with Improved Loss Function Combination Authors Ravi Kant Gupta, Shounak Das, Amit Sethi 本文提出了一种针对 HE 染色组织学图像的无监督域适应 UDA 的新方法。现有的对抗域适应方法可能无法有效地对齐与分类问题相关的多模态分布的不同域。目标是通过利用这些域的独特特征来增强域对齐并减少这些域之间的域转移。我们的方法提出了一种新颖的损失函数以及精心挑选的现有损失函数,旨在解决组织学图像特有的挑战。这种损失组合不仅使模型准确、鲁棒,而且在训练收敛方面也更快。我们特别关注利用组织学特定特征,例如组织结构和细胞形态,以增强组织学领域的适应性能。所提出的方法在准确性、鲁棒性和泛化方面进行了广泛的评估,超越了组织学图像的最先进技术。 |
| Advances in Kidney Biopsy Structural Assessment through Dense Instance Segmentation Authors Zhan Xiong, Junling He, Pieter Valkema, Tri Q. Nguyen, Maarten Naesens, Jesper Kers, Fons J. Verbeek 肾活检是诊断肾脏疾病的金标准。肾脏病理学家专家做出的病变评分是半定量的,并且观察者之间的变异性很高。因此,自动获取每个分割的解剖对象的统计数据可以在减少劳动力和观察者之间的变异性方面带来显着的好处。然而,活检的实例分割一直是一个具有挑战性的问题,因为a平均有大约300到1000个密集接触的解剖结构,b具有至少3个的多个类,c具有不同的尺寸和形状。当前使用的实例分割模型无法以有效且通用的方式同时应对这些挑战。在本文中,我们提出了第一个无锚实例分割模型,该模型结合了扩散模型、变压器模块和 RCNN 区域卷积神经网络。我们的模型仅在一台 NVIDIA GeForce RTX 3090 GPU 上进行训练,但可以有效识别肾活检中 3 种常见解剖对象类别(即肾小球、肾小管和动脉)的 500 多个对象。我们的数据集由从 148 张琼斯银染肾全切片图像 WSI 中提取的 303 个斑块组成,其中 249 个斑块用于训练,54 个斑块用于评估。此外,无需调整或重新训练,该模型可以直接转移其域,从 PAS 染色的 WSI 中生成良好的实例分割结果。 |
| Retail-786k: a Large-Scale Dataset for Visual Entity Matching Authors Bianca Lamm 1 and 2 , Janis Keuper 1 1 IMLA, Offenburg University, 2 Markant Services International GmbH 实体匹配 EM 定义了通过将语义概念从示例组实体转移到看不见的数据来学习对对象进行分组的任务。尽管图像数据在许多 EM 问题中普遍可用,但当前大多数可用的 EM 算法仅依赖于文本元数据。在本文中,我们基于零售领域的生产级用例,介绍了第一个用于视觉实体匹配的公开可用的大规模数据集。使用多年来从不同欧洲零售商收集的扫描广告传单,我们提供了总共 786k 个手动注释的高分辨率产品图像,其中包含 18k 个不同的单独零售产品,这些产品被分组为 3k 个实体。这些产品实体的注释基于价格比较任务,其中每个实体形成可比产品的等价类。在第一次基线评估之后,我们表明所提出的视觉实体匹配构成了一个新的学习问题,使用基于标准图像的分类和检索算法无法充分解决该问题。相反,需要允许将基于示例的视觉等效类转移到新数据的新方法来解决所提出的问题。 |
| APNet: Urban-level Scene Segmentation of Aerial Images and Point Clouds Authors Weijie Wei, Martin R. Oswald, Fatemeh Karimi Nejadasl, Theo Gevers 在本文中,我们重点研究城市场景点云的语义分割方法。我们的基本概念围绕着协作利用不同的场景表示,以从不同的上下文信息和网络架构中受益。为此,所提出的网络架构(称为 APNet)分为两个分支:点云分支和航空图像分支,其输入是从点云生成的。为了利用每个分支的不同属性,我们采用了几何感知融合模块,该模块被学习以组合每个分支的结果。每个分支的额外单独损失避免了一个分支主导结果,确保每个分支单独获得最佳性能,并明确定义融合网络的输入域,确保其仅执行数据融合。我们的实验表明,融合输出始终优于各个网络分支,并且 APNet 在 SensatUrban 数据集上实现了 65.2 mIoU 的最先进性能。 |
| Prototype Generation: Robust Feature Visualisation for Data Independent Interpretability Authors Arush Tagade, Jessica Rumbelow 我们引入了原型生成,这是一种更严格、更稳健的特征可视化形式,用于图像分类模型的模型无关、数据独立的可解释性。我们展示了它生成导致自然激活路径的输入的能力,反驳了之前的说法,即特征可视化算法由于不自然的内部激活而不值得信赖。我们通过定量测量我们生成的原型和自然图像的内部激活之间的相似性来证实这些说法。 |
| Revisiting Cephalometric Landmark Detection from the view of Human Pose Estimation with Lightweight Super-Resolution Head Authors Qian Wu, Si Yong Yeo, Yufei Chen, Jun Liu 头影测量标志的精确定位在正畸和正颌学领域具有非常重要的意义,因为它具有自动化关键点标记的潜力。在地标检测的背景下,特别是在头影测量中,据观察,现有方法通常缺乏标准化的流程和精心设计的偏差减少流程,这会严重影响其性能。在本文中,我们重新审视了一项相关任务,即人体姿势估计 HPE,它与头影测量地标检测 CLD 有许多相似之处,并强调从前一个领域转移技术以使后者受益的潜力。受这一洞察的激励,我们基于成熟的 HPE 代码库(称为 MMPose)开发了一个强大且适应性强的基准测试。该基准可以作为实现卓越 CLD 性能的可靠基准。此外,我们在框架内引入了升级设计,以进一步提高性能。此增强功能涉及轻量级且高效的超分辨率模块的结合,该模块可生成高分辨率特征的热图预测,并受益于其减少量化偏差的能力,进一步改进性能。在 MICCAI CLDetection2023 挑战中,我们的方法在三个指标上获得第一名,在其余一个指标上获得第三名。 |
| HAvatar: High-fidelity Head Avatar via Facial Model Conditioned Neural Radiance Field Authors Xiaochen Zhao, Lizhen Wang, Jingxiang Sun, Hongwen Zhang, Jinli Suo, Yebin Liu 在轻量级设置下建模可动画 3D 人体头部头像的问题非常重要,但尚未得到很好的解决。现有的 3D 表示要么在人像图像合成的真实感方面表现良好,要么在表情控制的准确性方面表现良好,但无法两者兼而有之。为了解决这个问题,我们引入了一种新颖的混合显式隐式 3D 表示,面部模型条件神经辐射场,它集成了 NeRF 的表达能力和参数模板的先验信息。在我们表示的核心,提出了一种基于合成渲染的条件方法,将参数模型的先验信息融合到隐式场中,而不限制其拓扑灵活性。此外,基于混合表示,我们妥善克服了现有方法中出现的形状不一致问题,提高了动画的稳定性。此外,通过采用基于 GAN 的整体架构,使用图像到图像转换网络,我们实现了动态头部外观的高分辨率、逼真且视图一致的合成。 |
| Reconstruction of Patient-Specific Confounders in AI-based Radiologic Image Interpretation using Generative Pretraining Authors Tianyu Han, Laura igutyt , Luisa Huck, Marc Huppertz, Robert Siepmann, Yossi Gandelsman, Christian Bl thgen, Firas Khader, Christiane Kuhl, Sven Nebelung, Jakob Kather, Daniel Truhn 检测自动诊断辅助系统(例如人工智能驱动的系统)中的误导性模式对于确保其可靠性至关重要,特别是在医疗保健领域。当前评估深度学习模型的技术无法在诊断层面可视化混杂因素。在这里,我们提出了一种称为 DiffChest 的自调节扩散模型,并在来自美国和欧洲多个医疗中心的 194,956 名患者的 515,704 张胸片的数据集上对其进行训练。 DiffChest 解释了患者特定级别的分类,并可视化可能误导模型的混杂因素。在评估 DiffChest 识别治疗相关混杂因素的能力时,我们发现读者间高度一致,大多数成像结果中的 Fleiss Kappa 值为 0.8 或更高。以 11.1 至 100 的患病率准确捕获了混杂因素。此外,我们的预训练过程优化了模型,以从输入射线照片中捕获最相关的信息。 DiffChest 在诊断胸腔积液和心功能不全等 11 种胸部疾病时取得了出色的诊断准确性,并且对其余疾病至少具有足够的诊断准确性。 |
| Continual Action Assessment via Task-Consistent Score-Discriminative Feature Distribution Modeling Authors Yuan Ming Li, Ling An Zeng, Jing Ke Meng, Wei Shi Zheng 行动质量评估 AQA 是一项试图回答行动执行情况的任务。虽然已经取得了显着的进展,但 AQA 的现有工作假设所有训练数据一次性可见,但无法持续学习评估新技术行动。在这项工作中,我们解决了 AQA 中的持续学习问题,它敦促统一的模型顺序学习 AQA 任务而不会忘记。我们对连续 AQA 建模的想法是顺序学习任务一致的分数判别性特征分布,其中潜在特征表示与分数标签的强相关性,无论任务或动作类型如何。从这个角度来看,我们的目标是从两个方面减轻Continual AQA中的遗忘。首先,为了将新数据和先前数据的特征融合成分数判别分布,提出了一种新颖的特征分数相关性感知演练,以存储和重用来自先前任务且内存大小有限的数据。其次,开发了动作通用特定图来学习和解耦动作通用知识和动作特定知识,以便可以更好地在各种任务中提取任务一致分数判别特征。进行了大量的实验来评估所提出的组件的贡献。 |
| Prototype-guided Cross-modal Completion and Alignment for Incomplete Text-based Person Re-identification Authors Tiantian Gong, Guodong Du, Junsheng Wang, Yongkang Ding, Liyan Zhang 传统的基于文本的行人重新识别 ReID 技术严重依赖于完全匹配的多模态数据,这是一个理想的场景。然而,由于跨模态数据的收集和处理过程中不可避免的数据丢失和损坏,在实际应用中通常会遇到数据不完整的问题。因此,我们考虑一个更实际的任务,称为基于不完整文本的 ReID 任务,其中人物图像和文本描述不完全匹配,并且包含部分缺失的模态数据。为此,我们提出了一种新颖的原型引导跨模式完成和对齐 PCCA 框架来处理上述基于不完整文本的 ReID 问题。具体来说,我们无法根据缺失模态数据的文本查询直接检索人物图像。因此,我们通过计算现有图像和文本之间的跨模态相似性,提出了缺失数据的跨模态最近邻构建策略,为缺失模态特征的完成提供了关键指导。此外,为了有效地完成缺失模态特征,我们利用上述缺失模态数据的跨模态最近邻集和相应的原型构建关系图,这可以进一步增强生成的缺失模态特征。此外,为了图像和文本之间更紧密的细粒度对齐,我们提出了一种原型感知的跨模态对齐损失,它可以有效地减少模态异质性差距,从而在公共空间中实现更好的细粒度对齐。 |
| Guiding Instruction-based Image Editing via Multimodal Large Language Models Authors Tsu Jui Fu, Wenze Hu, Xianzhi Du, William Yang Wang, Yinfei Yang, Zhe Gan 基于指令的图像编辑通过自然命令提高了图像操作的可控性和灵活性,无需详细描述或区域掩模。然而,人类指令有时太简短,当前的方法无法捕获和遵循。多模态大语言模型 MLLM 在跨模态理解和通过 LM 生成视觉感知响应方面表现出了良好的能力。我们研究 MLLM 如何促进编辑指令并提出 MLLM 引导图像编辑 MGIE。 MGIE 学习导出表达性指令并提供明确的指导。编辑模型共同捕捉这种视觉想象力,并通过端到端训练进行操作。我们评估 Photoshop 风格修改、全局照片优化和本地编辑的各个方面。 |
| SegRCDB: Semantic Segmentation via Formula-Driven Supervised Learning Authors Risa Shinoda, Ryo Hayamizu, Kodai Nakashima, Nakamasa Inoue, Rio Yokota, Hirokatsu Kataoka 预训练是增强视觉模型的强大策略,可以使用有限数量的标记图像有效地训练它们。在语义分割中,创建注释掩码需要大量的人力和时间,因此,构建具有语义标签的大规模预训练数据集相当困难。此外,语义分割预训练中重要的因素尚未得到充分研究。在本文中,我们提出了分割径向轮廓数据库 SegRCDB,它首次将公式驱动的监督学习应用于语义分割。 SegRCDB 支持语义分割的预训练,无需真实图像或任何手动语义标签。 SegRCDB 基于对语义分割预训练中重要内容的洞察,并允许高效的预训练。在 ADE 20k 和 Cityscapes 上使用相同数量的训练图像进行微调时,使用 SegRCDB 进行预训练比使用 COCO Stuff 进行预训练获得了更高的 mIoU。 SegRCDB 通过无需手动注释即可创建大型数据集,在语义分割预训练和研究方面具有巨大的潜力。 SegRCDB 数据集将在允许研究和商业用途的许可下发布。 |
| GAIA-1: A Generative World Model for Autonomous Driving Authors Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, Gianluca Corrado 自动驾驶有望对交通带来革命性的改进,但构建能够安全地应对现实世界场景的非结构化复杂性的系统仍然具有挑战性。 |
| DeeDiff: Dynamic Uncertainty-Aware Early Exiting for Accelerating Diffusion Model Generation Authors Shengkun Tang, Yaqing Wang, Caiwen Ding, Yi Liang, Yao Li, Dongkuan Xu 扩散模型在生成多样化和高保真度图像方面取得了巨大成功。性能的提高伴随着每张图像的生成速度较低,这阻碍了实时场景中的应用扩散模型。虽然某些特定预测受益于每次样本迭代中模型的完整计算,但并非每次迭代都需要相同的计算量,这可能会导致计算浪费。在这项工作中,我们提出了 DeeDiff,这是一种早期存在的框架,可以在每个采样步骤中自适应地分配计算资源,以提高扩散模型的生成效率。具体来说,我们引入了用于扩散模型的时间步感知不确定性估计模块 UEM,该模块附加到每个中间层以估计每层的预测不确定性。不确定性被视为决定推理是否终止的信号。此外,我们提出了不确定性感知分层损失来填补完整模型和早期退出模型之间的性能差距。通过这种损失策略,我们的模型能够获得与全层模型相当的结果。在多个数据集上进行的类条件、无条件和文本引导生成的广泛实验表明,与扩散模型上现有的早期方法相比,我们的方法实现了最先进的性能和效率权衡。更重要的是,我们的方法甚至为基线模型带来了额外的好处,并在 CIFAR 10 和 Celeb A 数据集上获得了更好的性能。 |
| GSDC Transformer: An Efficient and Effective Cue Fusion for Monocular Multi-Frame Depth Estimation Authors Naiyu Fang, Lemiao Qiu, Shuyou Zhang, Zili Wang, Zheyuan Zhou, Kerui Hu 深度估计为自动驾驶中感知 3D 信息提供了另一种方法。单目深度估计,无论是单帧还是多帧输入,通过学习各种类型的线索并专门研究静态或动态场景,都取得了巨大的成功。最近,这些线索融合成为一个有吸引力的话题,旨在使组合的线索在两种类型的场景中都能表现良好。然而,自适应线索融合依赖于注意力机制,其中二次复杂度限制了线索表示的粒度。此外,显式线索融合依赖于精确的分割,这给掩模预测带来了沉重的负担。为了解决这些问题,我们提出了 GSDC Transformer,这是一种用于单目多帧深度估计中线索融合的高效且有效的组件。我们利用可变形注意力来学习精细尺度的线索关系,而稀疏注意力在粒度增加时减少了计算需求。为了补偿动态场景中精度的下降,我们以超级标记的形式表示场景属性,而不依赖于精确的形状。在归因于动态场景的每个超级标记中,我们收集其相关线索并学习局部密集关系以增强线索融合。 |
| Imagery Dataset for Condition Monitoring of Synthetic Fibre Ropes Authors Anju Rani, Daniel O. Arroyo, Petar Durdevic 在海上、风力涡轮机行业等领域,合成纤维绳索 SFR 的自动目视检查是一项具有挑战性的任务。SFR 中存在的任何缺陷都会损害其结构完整性并带来重大安全风险。由于这些绳索尺寸大、重量大,经常拆卸和检查它们通常是不切实际的。因此,迫切需要开发有效的缺陷检测方法来评估其剩余使用寿命RUL。为了应对这一挑战,我们生成了一个全面的数据集,其中总共包含 6,942 张原始图像,代表正常和有缺陷的 SFR。该数据集涵盖了在其整个使用寿命期间可能发生的各种缺陷场景,包括但不限于焊接缺陷、切断线、擦伤、压缩、芯子脱落和正常。该数据集作为支持计算机视觉应用的资源,包括目标检测、分类和分割,旨在检测和分析 SFR 中的缺陷。该数据集的可用性将有助于鲁棒缺陷检测算法的开发和评估。 |
| A 5-Point Minimal Solver for Event Camera Relative Motion Estimation Authors Ling Gao, Hang Su, Daniel Gehrig, Marco Cannici, Davide Scaramuzza, Laurent Kneip 基于事件的相机非常适合基于线的运动估计,因为它们主要响应场景中的边缘。然而,根据事件准确确定相机位移仍然是一个悬而未决的问题。这是因为在使用事件相机时,线特征提取和动力学估计是紧密耦合的,并且当前没有精确的模型可用于描述事件时空体积中线生成的复杂结构。我们通过导出此类流形(我们称之为事件尾)的正确非线性参数化来解决这个问题,并演示其在基于事件的线性运动估计中的应用,以及来自惯性测量单元的已知旋转。使用这种参数化,我们引入了一种新颖的最小 5 点求解器,可以联合估计线参数和线性相机速度投影,在考虑多条线时可以将其融合为单个平均线速度。我们在合成数据和真实数据上证明,我们的求解器比其他方法生成更稳定的相对运动估计,同时比基于时空平面的聚类捕获更多的内点。特别是,我们的方法在估计线速度方面始终达到 100 的成功率,而现有的封闭式求解器只能达到 23 到 70 之间。 |
| On Uniform Scalar Quantization for Learned Image Compression Authors Haotian Zhang, Li Li, Dong Liu 将不可微量化纳入基于梯度的网络训练时,学习图像压缩面临着独特的挑战。已经提出了几种量化替代方法来完成训练,但从理论角度来看,它们并没有系统地得到证明。我们通过对比均匀标量量化(最广泛使用的类别,舍入是最简单的情况)及其训练代理来填补这一空白。原则上,我们发现两个关键因素,一个是替代项和舍入之间的差异,导致训练测试不匹配,另一个是替代项造成的梯度估计风险,包括梯度估计的偏差和方差。我们的分析和模拟表明,训练测试不匹配和梯度估计风险之间存在权衡,并且权衡因不同的网络结构而异。受这些分析的启发,我们提出了一种基于随机均匀退火的方法,该方法具有可调节的温度系数来控制权衡。此外,我们的分析启发了我们两个微妙的技巧,一个是为估计的量化潜在分布的方差参数设置适当的下界,这有效地减少了训练测试失配,另一个是使用带有部分停止梯度的零中心量化,这减少了梯度估计方差,从而稳定了训练。 |
| Unveiling Document Structures with YOLOv5 Layout Detection Authors Herman Sugiharto, Yorissa Silviana, Yani Siti Nurpazrin 当前数字环境的特点是数据,特别是非结构化数据的广泛存在,这给金融、医疗和教育等领域带来了许多问题。传统的数据提取技术在处理非结构化数据固有的多样性和复杂性时遇到困难,因此需要采用更有效的方法。 |
| Scalable Multi-Temporal Remote Sensing Change Data Generation via Simulating Stochastic Change Process Authors Zhuo Zheng, Shiqi Tian, Ailong Ma, Liangpei Zhang, Yanfei Zhong 了解地球表面的时间动态是多时态遥感图像分析的一项任务,深度视觉模型及其燃料标记的多时态图像显着促进了这一任务。然而,大规模收集、预处理和注释多时相遥感图像并非易事,因为它既昂贵又知识密集。在本文中,我们通过生成建模提出了一种可扩展的多时相遥感变化数据生成器,该生成器廉价且自动化,从而缓解了这些问题。我们的主要想法是模拟随时间的随机变化过程。我们将随机变化过程视为概率语义状态转换,即生成概率变化模型GPCM,它将复杂的模拟问题解耦为两个更可跟踪的子问题,即变化事件模拟和语义变化综合。为了解决这两个问题,我们提出了变更生成器 Changen,这是一种基于 GAN 的 GPCM,能够生成可控的对象变更数据,包括可定制的对象属性和变更事件。 |
| HoloAssist: an Egocentric Human Interaction Dataset for Interactive AI Assistants in the Real World Authors Xin Wang, Taein Kwon, Mahdi Rad, Bowen Pan, Ishani Chakraborty, Sean Andrist, Dan Bohus, Ashley Feniello, Bugra Tekin, Felipe Vieira Frujeri, Neel Joshi, Marc Pollefeys 构建一个能够在现实世界中感知、推理并与人类协作的交互式人工智能助手一直是人工智能社区的长期追求。这项工作是更广泛的研究工作的一部分,旨在开发可以交互式指导人类在物理世界中执行任务的智能代理。作为朝这个方向迈出的第一步,我们引入了 HoloAssist,这是一个大规模的以自我为中心的人类交互数据集,两个人可以协作完成物理操作任务。任务执行者在佩戴混合现实耳机时执行任务,该耳机捕获七个同步数据流。任务指导员实时观看表演者以自我为中心的视频并进行口头指导。通过使用动作和对话注释来增强数据,并观察不同参与者的丰富行为,我们提出了关于人类助手如何纠正错误、干预任务完成过程以及将其指令落实到环境的关键见解。 HoloAssist 涵盖 350 个独特的教练表演者对捕获的 166 小时的数据。此外,我们构建并提出了错误检测、干预类型预测和手牌预测的基准,以及详细的分析。我们预计 HoloAssist 将为构建能够与现实世界中的人类流畅协作的人工智能助手提供重要资源。 |
| Segment Anything Model is a Good Teacher for Local Feature Learning Authors Jingqian Wu, Rongtao Xu, Zach Wood Doughty, Changwei Wang 局部特征检测和描述在许多计算机视觉任务中发挥着重要作用,这些任务旨在检测和描述任何场景和任何下游任务中的关键点。数据驱动的局部特征学习方法需要依赖像素级对应进行训练,这在大规模获取方面具有挑战性,从而阻碍了性能的进一步提高。在本文中,我们建议 SAMFeat 引入 SAM 分段任何模型,这是一种在 1100 万张图像上训练的基本模型,作为指导局部特征学习的老师,从而激发在有限数据集上的更高性能。为此,首先,我们构建了像素语义关系蒸馏 PSRD 的辅助任务,它将 SAM 编码器学习到的与类别无关的语义信息的特征关系蒸馏到局部特征学习网络中,以利用语义辨别来改进局部特征描述。其次,我们开发了一种称为基于语义分组 WSC 的弱监督对比学习的技术,该技术利用源自 SAM 的语义分组作为弱监督信号,来优化局部描述符的度量空间。第三,我们设计了边缘注意力引导EAG,通过促使网络更多地关注SAM引导的边缘区域,进一步提高局部特征检测和描述的准确性。 SAMFeat 在 HPatches 上的图像匹配、亚琛日夜的长期视觉定位等各种任务上的表现展示了其相对于之前的本地特征的优越性。 |
| SpikeMOT: Event-based Multi-Object Tracking with Sparse Motion Features Authors Song Wang, Zhu Wang, Can Li, Xiaojuan Qi, Hayden Kwok Hay So 与传统的 RGB 相机相比,事件相机卓越的时间分辨率使它们能够捕获帧之间的丰富信息,使其成为对象跟踪的主要候选者。然而在实践中,尽管具有理论上的优势,基于事件的多目标跟踪 MOT 的工作仍处于起步阶段,特别是在现实世界中,来自复杂背景和相机运动的事件很容易掩盖真实的目标运动。在这项工作中,提出了一种基于事件的多对象跟踪器(称为 SpikeMOT)来解决这些挑战。 SpikeMOT 利用尖峰神经网络从与对象相关的事件流中提取稀疏时空特征。生成的尖峰序列表示用于跟踪高频对象运动,同时对象检测器以等效帧速率提供这些对象的更新空间信息。为了评估 SpikeMOT 的有效性,我们引入了 DSEC MOT,这是第一个基于大规模事件的 MOT 基准,其中包含对现实世界环境中经历严重遮挡、频繁轨迹交叉和长期重新识别的对象的细粒度注释。 |
| Perceptual Tone Mapping Model for High Dynamic Range Imaging Authors Imran Mehmood, Xinye Shi, M. Usman Khan, Ming Ronnier Luo 色调映射的关键挑战之一是将高动态范围 HDR 图像映射到标准动态范围 SDR 显示器时保持高动态范围 HDR 图像的感知质量。传统色调映射算子 TMO 会压缩 HDR 图像的亮度,而不考虑周围环境和显示条件,从而导致结果不佳。当前的研究通过结合感知颜色外观属性来解决这一挑战。在这项工作中,我们提出了一个利用 CIECAM16 感知属性(即亮度、色彩度和色调)的 TMO TMOz。 TMOz 考虑了环绕声和显示条件的影响,以实现更优化的色彩再现。感知亮度被压缩,感知色阶,即色彩和色调是通过采用 CIECAM16 颜色适应方程从 HDR 图像中导出的。进行了心理物理学实验来自动化亮度压缩参数。该模型采用全自动和自适应方法,无需手动选择参数。 TMOz 根据对比度、色彩和整体图像质量进行评估。 |
| Synthetic Data Generation and Deep Learning for the Topological Analysis of 3D Data Authors Dylan Peek, Matt P. Skerritt, Stephan Chalup 这项研究使用深度学习来估计由稀疏、无序的 3D 点云场景表示的流形拓扑。合成了一个新的标记数据集来训练神经网络并评估它们估计这些流形的属的能力。该数据使用随机同胚变形来激发视觉拓扑特征的学习。我们证明深度学习模型可以提取这些特征,并讨论相对于基于持久同源性的现有拓扑数据分析工具的一些优势。语义分割用于结合拓扑标签提供额外的几何信息。通用点云多层感知器和变压器网络都用于比较这些方法的可行性。该试点研究的实验结果支持这样的假设:借助复杂的合成数据生成,神经网络可以执行基于分割的拓扑数据分析。 |
| nnSAM: Plug-and-play Segment Anything Model Improves nnUNet Performance Authors Yunxiang Li, Bowen Jing, Xiang Feng, Zihan Li, Yongbo He, Jing Wang, You Zhang 计算机视觉基础模型的最新发展,特别是 Segment Anything Model SAM,允许可扩展且与领域无关的图像分割作为通用分割工具。与此同时,医学图像分割领域也从像 nnUNet 这样的专门神经网络中受益匪浅,该网络在特定领域的数据集上进行训练,并且可以自动配置网络以适应特定的分割挑战。为了结合基础模型和领域特定模型的优点,我们提出了 nnSAM,它将 SAM 模型与 nnUNet 模型协同集成,以实现更准确和鲁棒的医学图像分割。 nnSAM模型利用SAM强大而稳健的特征提取功能,同时利用nnUNet的自动配置功能来促进数据集定制学习。我们对不同大小的训练样本对 nnSAM 模型的综合评估表明,它允许很少的镜头学习,这与医学图像分割高度相关,因为高质量的带注释数据可能稀缺且获取成本高昂。通过融合其前身的优势,nnSAM 将自己定位为医学图像分割领域潜在的新基准,提供了一种将广泛适用性与专业效率相结合的工具。 |
| AdaPose: Towards Cross-Site Device-Free Human Pose Estimation with Commodity WiFi Authors Yunjiao Zhou, Jianfei Yang, He Huang, Lihua Xie 基于WiFi的姿态估计是一项对于智能家居和虚拟虚拟形象生成的发展具有巨大潜力的技术。然而,当前基于 WiFi 的姿态估计方法主要是在受控实验室条件下使用复杂的视觉模型进行评估,以获取准确的标记数据。此外,WiFi CSI 对环境变量高度敏感,将预训练模型直接应用于新环境可能会因域转移而产生次优结果。在本文中,我们提出了一种域自适应算法 AdaPose,专为基于弱监督 WiFi 的姿态估计而设计。所提出的方法旨在识别对环境动态具有高度抵抗力的一致人体姿势。为了实现这一目标,我们引入了映射一致性损失,它根据映射级别输入和输出之间的内部一致性来对齐源域和目标域的域差异。我们使用我们自己收集的包含 WiFi CSI 帧的姿态估计数据集,在两个不同场景中对域适应进行了广泛的实验。 |
| COMNet: Co-Occurrent Matching for Weakly Supervised Semantic Segmentation Authors Yukun Su, Jingliang Deng, Zonghan Li 图像级弱监督语义分割是近年来深入研究的一项具有挑战性的任务。大多数常见解决方案利用类激活图 CAM 来定位对象区域。然而,分类网络生成的此类响应图通常关注有区别的对象部分。在本文中,我们提出了一种新颖的共现匹配网络 COMNet,它可以提高 CAM 的质量并强制网络关注对象的整个部分。具体来说,我们对包含公共类的配对图像进行帧间匹配以增强相应区域,并在单个图像上构建帧内匹配以在对象区域中传播语义特征。 |
| Model2Scene: Learning 3D Scene Representation via Contrastive Language-CAD Models Pre-training Authors Runnan Chen, Xinge Zhu, Nenglun Chen, Dawei Wang, Wei Li, Yuexin Ma, Ruigang Yang, Tongliang Liu, Wenping Wang 当前成功的 3D 场景感知方法依赖于大规模注释点云,获取这些点云既繁琐又昂贵。在本文中,我们提出了 Model2Scene,这是一种从计算机辅助设计 CAD 模型和语言中学习免费 3D 场景表示的新颖范例。主要挑战是CAD模型与真实场景对象之间的领域差距,包括从单一模型到场景的模型到场景以及从合成模型到真实场景对象的合成到真实。为了应对上述挑战,Model2Scene 首先通过混合数据增强 CAD 模型来模拟拥挤的场景。接下来,我们提出了一种新颖的特征正则化操作,称为深度凸包正则化 DCR,将点特征投影到统一的凸包空间中,从而减少域间隙。最终,我们对语言嵌入和 CAD 模型的点特征施加对比损失来预训练 3D 网络。大量实验验证了学习到的 3D 场景表示对于各种下游任务是有益的,包括无标签 3D 对象显着性检测、标签高效 3D 场景感知和零样本 3D 语义分割。值得注意的是,Model2Scene 产生了令人印象深刻的无标签 3D 对象显着性检测,在 ScanNet 和 S3DIS 数据集上的平均 mAP 分别为 46.08 和 55.49。 |
| CrossZoom: Simultaneously Motion Deblurring and Event Super-Resolving Authors Chi Zhang, Xiang Zhang, Mingyuan Lin, Cheng Li, Chu He, Wen Yang, Gui Song Xia, Lei Yu 尽管传统事件相机和神经形态事件相机之间的协作为基于帧事件的视觉应用带来了繁荣,但其性能仍然受到空间和时间域中两种模态的分辨率差距的限制。本文致力于通过分别提高图像的时间分辨率(即运动去模糊)和事件的空间分辨率(即事件超分辨率)来弥补这一差距。为此,我们引入了 CrossZoom,这是一种新颖的统一神经网络 CZ Net,可在模糊输入和相应的高分辨率 HR 事件的曝光期内联合恢复清晰的潜在序列。具体来说,我们提出了一种多尺度模糊事件融合架构,该架构利用尺度变量属性并有效融合交叉模态信息以实现交叉增强。设计基于注意力的自适应增强和交叉交互预测模块来减轻低分辨率LR事件固有的失真,并通过先前的模糊事件补充信息来增强最终结果。此外,我们提出了一个包含 HR 清晰模糊图像和相应的 HR LR 事件流的新数据集,以促进未来的研究。对合成数据集和现实世界数据集进行的广泛定性和定量实验证明了所提出方法的有效性和鲁棒性。 |
| Denoising Diffusion Bridge Models Authors Linqi Zhou, Aaron Lou, Samar Khanna, Stefano Ermon 扩散模型是强大的生成模型,它使用随机过程将噪声映射到数据。然而,对于许多应用程序(例如图像编辑),模型输入来自的分布不是随机噪声。因此,扩散模型必须依靠指导或预测采样等繁琐的方法来将这些信息纳入生成过程。在我们的工作中,我们提出了去噪扩散桥模型 DDBM,这是基于扩散桥的范式的自然替代方案,扩散桥是在作为端点给出的两个配对分布之间进行插值的一系列过程。我们的方法从数据中学习扩散桥的分数,并通过基于学习的分数求解随机微分方程,从一个端点分布映射到另一个端点分布。我们的方法自然地统一了几类生成模型,例如基于分数的扩散模型和 OT 流匹配,使我们能够根据更普遍的问题调整现有的设计和架构选择。根据经验,我们将 DDBM 应用于像素和潜在空间中具有挑战性的图像数据集。在标准图像转换问题上,DDBM 比基线方法取得了显着的改进,并且当我们通过将源分布设置为随机噪声来将问题简化为图像生成时,DDBM 实现了与最先进的方法相当的 FID 分数,尽管它是为更先进的方法而构建的。 |
| Robust Asynchronous Collaborative 3D Detection via Bird's Eye View Flow Authors Sizhe Wei, Yuxi Wei, Yue Hu, Yifan Lu, Yiqi Zhong, Siheng Chen, Ya Zhang 通过促进多个智能体之间的通信,协作感知可以极大地提高每个智能体的感知能力。然而,由于通信延迟、中断和时钟错位,代理之间的时间异步在现实世界中是不可避免的。该问题导致多智能体融合时信息不匹配,严重动摇协作的基础。为了解决这个问题,我们提出了 CoBEVFlow,一种基于鸟瞰 BEV 流的异步鲁棒协作 3D 感知系统。 CoBEVFlow 的关键直觉是补偿运动以对齐多个代理发送的异步协作消息。为了对场景中的运动进行建模,我们提出了 BEV 流,它是与每个空间位置相对应的运动向量的集合。基于BEV流,可以将异步感知特征重新分配到适当的位置,减轻异步的影响。 CoBEVFlow有两个优点:iCoBEVFlow可以处理以不规则、连续时间戳发送的异步协作消息,无需离散化;ii对于BEV流,CoBEVFlow仅传输原始感知特征,而不是生成新的感知特征,避免了额外的噪声。为了验证 CoBEVFlow 的功效,我们创建了 IRregular V2V IRV2V,这是第一个具有各种时间异步性的合成协作感知数据集,可模拟不同的现实世界场景。对 IRV2V 和现实世界数据集 DAIR V2X 进行的大量实验表明,CoBEVFlow 始终优于其他基线,并且在极其异步的设置中具有鲁棒性。 |
| PC-Adapter: Topology-Aware Adapter for Efficient Domain Adaption on Point Clouds with Rectified Pseudo-label Authors Joonhyung Park, Hyunjin Seo, Eunho Yang 由于不同的对象尺度、传感器角度和自遮挡导致数据分布发生变化,理解从现实世界捕获的点云具有挑战性。先前的工作通过结合最近的学习原理(例如自监督学习、自训练和对抗性训练)解决了这个问题,这会导致大量的计算开销。为了实现简洁而强大的点云域适应,我们重新审视点云数据的独特挑战在域转移场景下,发现源数据的全局几何形状的重要性以及偏向源标签分布的目标伪标签的趋势。受我们观察的启发,我们提出了一种适配器引导的域适应方法 PC Adapter,该方法使用基于注意力的适配器保留源域的全局形状信息,同时通过另一个配备图卷积的适配器学习目标域的局部特征。此外,我们提出了一种新颖的伪标记策略,通过使用类别置信度分布调整置信度分数来考虑相对置信度,从而适应分类器偏差。 |
| Incremental Rotation Averaging Revisited and More: A New Rotation Averaging Benchmark Authors Xiang Gao, Hainan Cui, Shuhan Shen 为了进一步提高基于增量参数估计的旋转平均方法的准确性和鲁棒性,本文引入了增量旋转平均IRA家族的新成员,称为IRAv4。作为 IRAv4 最重要的特征,提取了特定于任务的连接支配集,作为旋转全局对齐的更可靠和准确的参考。此外,为了进一步解决现有旋转平均基准依赖稍微过时的 Bundler 相机校准结果作为地面事实并仅关注旋转估计精度的局限性,本文提出了一种新的基于 COLMAP 的旋转平均基准,该基准结合了交叉检查COLMAP和Bundler之间的关系,并采用旋转和下游位置估计的准确性作为评估指标,旨在为旋转平均研究提供更可靠和更全面的评估工具。 |
| YOLOR-Based Multi-Task Learning Authors Hung Shuo Chang, Chien Yao Wang, Richard Robert Wang, Gene Chou, Hong Yuan Mark Liao 多任务学习 MTL 旨在使用单个模型学习多个任务,并在假设泛化和共享语义的情况下共同改进所有任务。减少联合学习期间任务之间的冲突很困难,通常需要仔细的网络设计和极大的模型。我们建议以 You Only Learn One Representation YOLOR 为基础,这是一种专为多任务处理而设计的网络架构。 YOLOR 分别利用来自数据观察和学习潜伏的显式和隐式知识来改进共享表示,同时最大限度地减少训练参数的数量。然而,YOLOR 及其后续产品 YOLOv7 一次只训练两个任务。在本文中,我们联合训练对象检测、实例分割、语义分割和图像描述。我们分析权衡并尝试最大化语义信息的共享。通过我们的架构和训练策略,我们发现我们的方法在所有任务上都实现了有竞争力的性能,同时保持较低的参数数量并且无需任何预训练。 |
| Investigating Shift Equivalence of Convolutional Neural Networks in Industrial Defect Segmentation Authors Zhen Qu, Xian Tao, Fei Shen, Zhengtao Zhang, Tao Li 在工业缺陷分割任务中,虽然像素精度和并集 IoU 交集是评估分割性能的常用指标,但输出一致性(也指模型的等效性)经常被忽视。即使输入图像发生很小的变化,分割结果也会产生显着的波动。现有的方法主要关注数据增强或抗锯齿,以增强网络对平移变换的鲁棒性,但它们的平移等价在测试集上表现不佳,或者容易受到非线性激活函数的影响。此外,由于输入图像的平移而导致的边界变化始终被忽略,从而对平移等价性施加了进一步的限制。为了应对这一特殊挑战,提出了一对称为组件注意多相采样 CAPS 的新型下采样层,作为 CNN 中传统采样层的替代品。为了减轻图像边界变化对等价性的影响,CAPS中设计了自适应加窗模块来自适应地滤除图像的边界像素。此外,提出了一个组件注意模块来融合所有下采样的特征以提高分割性能。 |
| On the Contractivity of Plug-and-Play Operators Authors Chirayu D. Athalye, Kunal N. Chaudhury, Bhartendu Kumar 在即插即用的 PnP 正则化中,ISTA 和 ADMM 等算法中的近端算子被强大的降噪器取代。这种形式上的替代在实践中效果出人意料地好。事实上,PnP 已被证明可以为各种成像应用提供最先进的结果。 PnP 的实证成功促使研究人员了解其理论基础,特别是其收敛性。先前的工作表明,对于诸如非局部均值之类的核降噪器,PnP ISTA 在前向模型的一些强假设下可证明收敛。目前的工作是由以下问题推动的 我们能否放宽对前向模型的假设 收敛分析能否扩展到 PnP ADMM 我们能否估计收敛率 在这封信中,我们使用对称降噪器的收缩映射定理 i 来解决这些问题,我们表明在温和条件下 PnP ISTA 和 PnP ADMM 表现出线性收敛,ii 对于核降噪器,我们表明 PnP ISTA 和 PnP ADMM 对于图像修复表现出线性收敛。 |
| Superpixel Transformers for Efficient Semantic Segmentation Authors Alex Zihao Zhu, Jieru Mei, Siyuan Qiao, Hang Yan, Yukun Zhu, Liang Chieh Chen, Henrik Kretzschmar 语义分割旨在对图像中的每个像素进行分类,是机器感知中的一项关键任务,在机器人和自动驾驶领域有许多应用。由于该任务的高维度,大多数现有方法使用局部操作(例如卷积)来生成每像素特征。然而,由于在密集图像上操作的计算成本很高,这些方法通常无法有效地利用全局上下文信息。在这项工作中,我们通过利用超像素的思想、图像的过度分割,并将其应用到现代变压器框架中,提出了解决这个问题的方案。特别是,我们的模型学习通过一系列局部交叉注意力将像素空间分解为空间低维超像素空间。然后,我们将多头自注意力应用于超像素,以利用全局上下文丰富超像素特征,然后直接为每个超像素生成类预测。最后,我们使用超像素和图像像素特征之间的关联将超像素类预测直接投影回像素空间。与基于卷积的解码器方法相比,超像素空间中的推理使我们的方法具有更高的计算效率。然而,由于全局自注意力机制生成的丰富的超像素特征,我们的方法在语义分割中实现了最先进的性能。 |
| LEF: Late-to-Early Temporal Fusion for LiDAR 3D Object Detection Authors Tong He, Pei Sun, Zhaoqi Leng, Chenxi Liu, Dragomir Anguelov, Mingxing Tan 我们提出了一种使用时间 LiDAR 点云进行 3D 对象检测的晚期到早期循环特征融合方案。我们的主要动机是将对象感知的潜在嵌入融合到 3D 对象检测器的早期阶段。与直接从原始点学习相比,这种特征融合策略使模型能够更好地捕获具有挑战性的物体的形状和姿势。我们的方法以循环方式进行后期到早期的特征融合。这是通过在时间校准和对齐的稀疏柱标记上强制执行基于窗口的注意力块来实现的。利用鸟瞰图前景柱分割,我们将模型需要融合到当前帧中的稀疏历史特征的数量减少了 10 倍。我们还提出了一种随机长度 FrameDrop 训练技术,该技术将模型推广到推理时的可变帧长度,以提高性能而无需重新训练。 |
| Stochastic Digital Twin for Copy Detection Patterns Authors Yury Belousov, Olga Taran, Vitaliy Kinakh, Slava Voloshynovskiy 复制检测模式 CDP 提供了一种有效的产品防伪技术。然而,研究 CDP 生产变异性的复杂性通常会导致程序耗时且成本高昂,从而限制了 CDP 的可扩展性。计算机建模的最新进展,特别是用于打印成像通道的数字孪生概念,可以增强可扩展性并优化认证系统。 |
| Preface: A Data-driven Volumetric Prior for Few-shot Ultra High-resolution Face Synthesis Authors Marcel C. B hler 1 and 2 , Kripasindhu Sarkar 2 , Tanmay Shah 2 , Gengyan Li 1 and 2 , Daoye Wang 2 , Leonhard Helminger 2 , Sergio Orts Escolano 2 , Dmitry Lagun 2 , Otmar Hilliges 1 , Thabo Beeler 2 , Abhimitra Meka 2 1 ETH Zurich, 2 Google NeRF 能够高度逼真地合成人脸,包括复杂的外观以及头发和皮肤的反射效果。这些方法通常需要大量的多视图输入图像,使得处理硬件密集且繁琐,限制了对无约束设置的适用性。我们提出了一种新颖的体积人脸先验,可以合成不属于先验训练分布的主题的超高分辨率新颖视图。该先前模型由身份条件 NeRF 组成,在已知相机校准的不同人类的低分辨率多视图图像数据集上进行训练。训练数据集的基于简单稀疏地标的 3D 对齐使我们的模型能够学习几何和外观的平滑潜在空间,尽管训练身份数量有限。通过对任意分辨率的 2 或 3 个摄像机视图进行模型拟合,可以获得新主题的高质量体积表示。 |
| Sketch2CADScript: 3D Scene Reconstruction from 2D Sketch using Visual Transformer and Rhino Grasshopper Authors Hong Bin Yang 现有的 3D 模型重建方法通常以体素、点云或网格的形式生成输出。然而,这些方法都有其局限性,可能并不适合所有场景。例如,生成的模型可能会表现出粗糙的表面和扭曲的结构,这使得手动编辑和后处理对人类来说具有挑战性。在本文中,我们介绍了一种旨在解决这些问题的新颖的 3D 重建方法。我们训练了一个视觉转换器来从单个线框图像中预测场景描述符。该描述符包含重要信息,包括对象类型和位置、旋转和大小等参数。根据预测的参数,可以使用 Blender 或 Rhino Grasshopper 等提供可编程接口的 3D 建模软件重建 3D 场景,从而生成精细且易于编辑的 3D 模型。为了评估所提出的模型,我们创建了两个数据集,一个具有简单场景,另一个具有复杂场景。 |
| Space-Time Attention with Shifted Non-Local Search Authors Kent Gauen, Stanley Chan 由于帧之间对象的运动,有效计算视频的注意力图具有挑战性。虽然标准非局部搜索对于每个查询点周围的窗口来说是高质量的,但窗口的小尺寸无法容纳运动。长距离运动的方法使用辅助网络来预测最相似的关键坐标作为距每个查询位置的偏移量。然而,即使对于大规模网络,准确预测偏移流场仍然具有挑战性。微小的空间误差会显着影响注意力模块的质量。本文提出了一种将非局部搜索的质量与预测偏移范围相结合的搜索策略。该方法名为“平移非局部搜索”,在预测偏移周围执行小网格搜索,以纠正小的空间误差。我们的方法就地计算消耗的内存减少了 10 倍,速度比以前的工作快了 3 倍以上。实验上,纠正小空间误差可将视频帧对齐质量提高 3 dB PSNR 以上。我们的搜索升级了现有的时空注意力模块,将视频去噪结果提高了 0.30 dB PSNR,总体运行时间增加了 7.5 倍。 |
| Propagation and Attribution of Uncertainty in Medical Imaging Pipelines Authors Leonhard F. Feiner, Martin J. Menten, Kerstin Hammernik, Paul Hager, Wenqi Huang, Daniel Rueckert, Rickmer F. Braren, Georgios Kaissis 不确定性估计为医学成像应用提供了一种构建可解释神经网络的方法,主要针对专注于特定任务的单一深度学习模型进行研究。在本文中,我们提出了一种通过医学成像管道中的深度学习模型级联传播不确定性的方法。这使我们能够汇总管道后期阶段的不确定性,并为后续模型的预测获得联合不确定性度量。此外,我们可以单独报告管道中每个组件的任意、基于数据的不确定性的贡献。我们展示了我们的方法在真实成像管道上的实用性,该管道重建欠采样的大脑和膝盖磁共振 MR 图像,并随后预测图像中的定量信息,例如大脑体积、膝盖侧或患者性别。 |
| SatDM: Synthesizing Realistic Satellite Image with Semantic Layout Conditioning using Diffusion Models Authors Orkhan Baghirli, Hamid Askarov, Imran Ibrahimli, Ismat Bakhishov, Nabi Nabiyev 地球观测领域的深度学习模型在很大程度上依赖于大规模精确标记卫星图像的可用性。然而,获取和标记卫星图像是一项资源密集型工作。虽然生成模型为解决数据稀缺问题提供了一种有前景的解决方案,但其潜力仍未得到充分开发。最近,去噪扩散概率模型 DDPM 在从语义布局合成真实图像方面展现出了巨大的前景。本文实现了一种条件 DDPM 模型,该模型能够获取语义地图并生成高质量、多样化且相应准确的卫星图像。此外,还提供了优化动态的全面说明。所提出的方法集成了方差学习、无分类器指导和改进的噪声调度等尖端技术。自适应归一化和自注意力机制的结合进一步补充了去噪网络架构,增强了模型的能力。我们提出的模型的有效性使用本研究背景下引入的精心标记的数据集进行了验证。验证包括 Frechet Inception Distance FID 和 Intersection over Union IoU 等算法方法,以及人类意见研究。我们的研究结果表明,生成的样本与真实样本的偏差最小,为数据增强等实际应用打开了大门。我们期待在更广泛的环境和数据模式中进一步探索 DDPM。 |
| Granularity at Scale: Estimating Neighborhood Well-Being from High-Resolution Orthographic Imagery and Hybrid Learning Authors Ethan Brewer, Giovani Valdrighi, Parikshit Solunke, Joao Rulff, Yurii Piadyk, Zhonghui Lv, Jorge Poco, Claudio Silva 由于现有数据收集方法的限制,世界许多地区没有居住人口福祉的基本信息。从卫星或飞机等远程获得的俯视图像可以作为了解地面生命状况的窗口,并有助于填补社区信息稀疏的空白,而在较小的地理尺度上进行估计需要更高分辨率的传感器。随着传感器分辨率的提高,机器学习和计算机视觉的最新进展使得快速提取图像数据中的特征并检测图像数据中的模式成为可能,在此过程中将这些特征与其他信息相关联。在这项工作中,我们探讨了两种方法(监督卷积神经网络和基于视觉词包的半监督聚类)如何从公开的城市高分辨率图像中估计人口密度、家庭收入中位数和各个社区的教育程度。美国。结果和分析表明,从图像中提取的特征可以准确估计邻里密度 R 2 高达 0.81,监督方法能够解释人口收入和教育方面大约一半的变化。 |
| Ultra-low-power Image Classification on Neuromorphic Hardware Authors Gregor Lenz, Garrick Orchard, Sadique Sheik 尖峰神经网络 SNN 通过利用时间和空间稀疏性有望实现超低功耗应用。二进制激活的数量(称为峰值)与在神经形态硬件上执行时消耗的功率成正比。对于主要依赖于空间特征的视觉任务,使用时间反向传播来训练此类 SNN 的计算成本很高。对于图像识别数据集而言,训练无状态人工神经网络 ANN 然后将权重转换为 SNN 是一种简单的替代方案。大多数转换方法依赖于 SNN 中的速率编码来表示 ANN 激活,这使用大量的尖峰,因此需要能量来编码信息。最近,时间转换方法已经显示出有希望的结果,需要显着减少每个神经元的尖峰,但有时需要复杂的神经元模型。我们提出了一种时间 ANN 到 SNN 的转换方法,我们称之为 Quartz,它基于第一个尖峰的时间 TTFS 。 Quartz 实现了很高的分类精度,并且可以轻松地在神经形态硬件上实现,同时使用最少量的突触操作和内存访问。与之前的时间转换方法相比,它会导致每个神经元增加两个突触的成本,这些方法在神经形态硬件上很容易获得。我们在 MNIST、CIFAR10 和 ImageNet 上对 Quartz 进行模拟基准测试,以展示我们方法的优势,并跟进在 Intel 的神经拟态芯片 Loihi 上的实现。我们提供的证据表明,对于类似的分类精度,时间编码在功耗、吞吐量和延迟方面具有优势。 |
| Photonic Accelerators for Image Segmentation in Autonomous Driving and Defect Detection Authors Lakshmi Nair, David Widemann, Brad Turcott, Nick Moore, Alexandra Wleklinski, Darius Bunandar, Ioannis Papavasileiou, Shihu Wang, Eric Logan 与传统数字硬件相比,光子计算有望实现更快、更节能的深度神经网络 DNN 推理。光子计算的进步可以对自动驾驶和缺陷检测等依赖于图像分割模型的快速、准确和节能执行的应用产生深远的影响。在本文中,我们研究了光子加速器上的图像分割,以探索最适合光子加速器的图像分割 DNN 架构类型,以及在光子加速器上执行不同图像分割模型的吞吐量和能源效率,以及其中涉及的权衡。具体来说,我们证明了在光子加速器上执行时,某些分割模型与数字 float32 模型相比,精度损失可以忽略不计,并探索了其稳健性的经验推理。我们还讨论了在模型表现不佳的情况下恢复准确性的技术。此外,我们还比较了光子加速器上不同图像分割工作负载的每秒吞吐量推断和能耗估计。 |
| STIR: Surgical Tattoos in Infrared Authors Adam Schmidt, Omid Mohareri, Simon DiMaio, Septimiu E. Salcudean 量化内窥镜环境中跟踪和绘制组织的方法的性能对于实现医疗干预和手术的图像引导和自动化至关重要。迄今为止开发的数据集要么使用严格的环境、可见的标记,要么要求注释者在收集后标记视频中的显着点。这些分别是不通用的、对算法可见的、或者成本高昂且容易出错的。我们引入了一种新颖的标记方法以及使用该方法的数据集,即红外 STIR 中的外科纹身。 STIR 具有持久性但对可见光谱算法不可见的标签。这是通过用红外荧光染料、吲哚菁绿 ICG 标记组织点,然后收集可见光视频剪辑来完成的。 STIR 包含数百个体内和离体场景的立体视频剪辑,并在红外光谱中标记了起点和终点。 STIR 拥有 3,000 多个标记点,将有助于量化并更好地分析跟踪和绘图方法。介绍 STIR 后,我们使用 3D 和 2D 端点误差和准确性指标来分析 STIR 上多种不同的基于帧的跟踪方法。 |
| Intriguing properties of generative classifiers Authors Priyank Jaini, Kevin Clark, Robert Geirhos 快速识别对象的最佳范式是什么 判别推理 快速但可能容易进行捷径学习或使用生成模型 缓慢但可能更稳健 我们以生成模型的最新进展为基础,将文本到图像模型转变为分类器。这使我们能够研究他们的行为并将其与歧视模型和人类心理物理数据进行比较。我们报告了生成分类器的四个有趣的新兴特性,它们在 Imagen 中显示出破纪录的类人形状偏差 99,分布精度接近人类水平,与人类分类错误保持最先进的一致性,并且它们理解某些感知错觉。 |
| XVO: Generalized Visual Odometry via Cross-Modal Self-Training Authors Lei Lai, Zhongkai Shangguan, Jimuyang Zhang, Eshed Ohn Bar 我们提出了 XVO,一种半监督学习方法,用于训练广义单目视觉里程计 VO 模型,在不同的数据集和设置中具有鲁棒的自我操作能力。与通常研究单个数据集中的已知校准的标准单目 VO 方法相比,XVO 有效地学习从视觉场景语义中恢复与现实世界比例的相对姿势,即不依赖于任何已知的相机参数。我们通过 YouTube 上提供的大量无约束和异构行车记录仪视频进行自我训练来优化运动估计模型。我们的主要贡献是双重的。首先,我们凭经验证明半监督训练对于学习通用直接 VO 回归网络的好处。其次,我们演示了多模态监督,包括分割、流、深度和音频辅助预测任务,以促进 VO 任务的广义表示。具体来说,我们发现音频预测任务可以显着增强半监督学习过程,同时减轻噪声伪标签,特别是在高度动态和域外视频数据中。尽管没有多帧优化或不了解相机参数,我们提出的教师网络在常用的 KITTI 基准上实现了最先进的性能。 |
| ELIP: Efficient Language-Image Pre-training with Fewer Vision Tokens Authors Yangyang Guo, Haoyu Zhang, Liqiang Nie, Yongkang Wong, Mohan Kankanhalli 在有限的计算预算下,学习通用的语言图像模型在计算上是令人望而却步的。本文深入研究了高效的语言图像预训练,尽管该领域在降低计算成本和占用空间方面很重要,但受到的关注相对较少。为此,我们提出了一种视觉令牌修剪和合并方法,即ELIP,以基于语言输出的监督来去除影响力较小的令牌。我们的方法设计具有多种优势,例如计算效率高、内存效率高、可训练参数自由,并且与之前的仅视觉标记修剪方法的区别在于其与任务目标的一致性。我们使用几个连续的块以逐步修剪的方式实现此方法。为了评估其泛化性能,我们将 ELIP 应用于三种常用的语言图像预训练模型,并利用公共图像标题对和 4M 图像进行预训练。我们的实验表明,通过删除 12 个 ViT 层中的 30 个视觉标记,ELIP 在各种下游任务(包括跨模态检索、VQA、图像字幕等)上保持了与基线 sim 平均准确度下降 0.32 显着可比的性能。我们的 ELIP 提供的 GPU 资源使我们能够扩展更大的批量大小,从而加速模型预训练,有时甚至增强下游模型性能。 |
| MV-DeepSDF: Implicit Modeling with Multi-Sweep Point Clouds for 3D Vehicle Reconstruction in Autonomous Driving Authors Yibo Liu, Kelly Zhu, Guile Wu, Yuan Ren, Bingbing Liu, Yang Liu, Jinjun Shan 从噪声和稀疏的部分点云中重建3D车辆对于自动驾驶具有重要意义。大多数现有的 3D 重建方法不能直接应用于这个问题,因为它们经过精心设计,可以处理具有微不足道噪声的密集输入。在这项工作中,我们提出了一种称为 MV DeepSDF 的新颖框架,该框架从多扫描点云估计最佳符号距离函数 SDF 形状表示,以在野外重建车辆。虽然已经有一些基于SDF的隐式建模方法,但它们只关注基于单视图的重建,导致保真度较低。相反,我们首先分析潜在特征空间中的多次扫描一致性和互补性,并提出将隐式空间形状估计问题转化为元素集特征提取问题。然后,我们设计了一种新的架构来提取各个元素级别的表示并将它们聚合以生成一组级别的预测潜在代码。该集合级潜在代码是隐式空间中最佳 3D 形状的表达,并且可以随后解码为车辆的连续 SDF。通过这种方式,我们的方法可以在 3D 车辆重建的多次扫描中学习一致且互补的信息。 |
| General Lipschitz: Certified Robustness Against Resolvable Semantic Transformations via Transformation-Dependent Randomized Smoothing Authors Dmitrii Korzh, Mikhail Pautov, Olga Tsymboi, Ivan Oseledets 随机平滑是构建图像分类器的最先进方法,该分类器对于有界幅度的加性对抗性扰动具有鲁棒性。然而,针对语义转换(例如图像模糊、平移、伽马校正及其组合)构建合理的证书更加复杂。在这项工作中,我们提出了 emph General Lipschitz GL,这是一个新框架,用于验证神经网络免受可组合可解析语义扰动的影响。在该框架内,我们分析了平滑分类器与变换相关的 Lipschitz 连续性。变换参数并导出相应的鲁棒性证书。 |
| Automatic Cadastral Boundary Detection of Very High Resolution Images Using Mask R-CNN Authors Neda Rahimpour Anaraki, Alireza Azadbakht, Maryam Tahmasbi, Hadi Farahani, Saeed Reza Kheradpisheh, Alireza Javaheri 最近,对加速和改进自动地籍测绘检测的需求很高。由于这个问题还处于起步阶段,还有很多计算机视觉和深度学习的方法还没有考虑到。在本文中,我们专注于深度学习,并提供了三种提高工作质量的几何后处理方法。我们的框架包括两个部分,每个部分都由几个阶段组成。我们解决这个问题的方法是使用实例分割。在第一部分中,我们使用 Mask R CNN 和在 ImageNet 数据集上预训练的 ResNet 50 为骨干网。在第二阶段,我们对第一部分的输出应用了三种几何后处理方法,以获得更好的整体输出。在这里,我们还使用计算几何来介绍一种简化直线的新方法,我们称之为基于口袋的简化算法。为了评估我们解决方案的质量,我们使用该领域流行的公式,即召回率、精度和 F 分数。我们获得的最高召回率为 95%,同时也保持了 72% 的高精度。结果 F 分数为 82%。使用 Mask R CNN 对其输出进行一些几何后处理来实现实例分割,为我们在该领域带来了有希望的结果。 |
| Decoding Imagery: Unleashing Large Language Models Authors David Noever, Samantha Elizabeth Miller Noever 在一项挑战响应研究中,我们对 Google Bard 进行了 64 项视觉挑战,旨在探索多模式大型语言模型法学硕士。挑战跨越不同的类别,包括视觉情境推理、视觉文本推理和下一场景预测等,以辨别巴德在融合视觉和语言分析方面的能力。我们的研究结果表明,巴德倾向于依赖对视觉效果做出有根据的猜测,尤其是在从图像中确定线索时。与 GPT4 等其他模型不同,Bard 似乎并不依赖于 Tesseract 等光学字符识别库,而是像 Google Lens 和 Visual API 等深度学习模型一样识别复杂图像中的文本。值得注意的是,Bard 可以直观地解决 ChatGPT 无法理解的验证码,推荐 Tesseract 解决方案。此外,虽然巴德模型提出了基于视觉输入的解决方案,但它无法重新创建或修改原始视觉对象来支持其结论。 Bard 未能重新绘制 ASCII 艺术,文本可以描述或捕获一个简单的 Tic Tac Toe 网格,它声称可以分析下一步的动作。 |
| MVMR: Evaluating Natural Language Video Localization Bias over Multiple Reliable Videos Pool Authors Nakyeong Yang, Minsung Kim, Seunghyun Yoon, Joongbo Shin, Kyomin Jung 近年来,随着多媒体内容的爆炸式增长,自然语言视频本地化(重点是检测与给定自然语言查询匹配的视频时刻)已成为一个关键问题。然而,之前的研究都没有探索从存在多个正面和负面视频的大型语料库中定位某个时刻。在本文中,我们提出了 MVMR 海量视频时刻检索任务,其目的是在给定文本查询的情况下从大量视频中定位视频帧。对于此任务,我们提出了通过对现有视频定位数据集采用相似性过滤来构建数据集的方法,并引入了三个 MVMR 数据集。具体来说,我们采用基于嵌入的文本相似性匹配和视频语言基础技术来计算目标查询和视频之间的相关性得分,以定义正集和负集。对于提出的 MVMR 任务,我们进一步开发了一个强大的模型,即可靠相互匹配网络 RMMN,它采用对比学习方案,有选择地过滤可靠且信息丰富的负数,从而使模型在 MVMR 任务上更加稳健。 |
| Framework and Model Analysis on Bengali Document Layout Analysis Dataset: BaDLAD Authors Kazi Reyazul Hasan 1 , Mubasshira Musarrat 1 , Sadif Ahmed 1 , Shahriar Raj 1 1 Bangladesh University of Engineering and Technology 本研究的重点是使用先进的计算机程序 Detectron2、YOLOv8 和 SAM 来理解孟加拉语文档布局。我们在研究中查看了许多不同的孟加拉语文献。 Detectron2 非常擅长查找和分离文档的不同部分,例如文本框和段落。 YOLOv8 擅长计算不同的表格和图片。我们还尝试了 SAM,它可以帮助我们理解棘手的布局。我们测试了这些程序,看看它们的效果如何。通过比较它们的准确性和速度,我们了解了哪一种适合不同类型的文档。 |
| Mechanical Artifacts in Optical Projection Tomography: Classification and Automatic Calibration Authors Yan Liu, Jonathan Dong, Thanh An Pham, Francois Marelli, Michael Unser 光学投影断层扫描 OPT 是生物医学研究的强大工具。它使用传统的断层扫描重建算法实现了具有高空间分辨率的介观生物样本的 3D 可视化。然而,由于 OPT 仪器的实验缺陷,各种伪影降低了重建图像的质量。尽管已经做出了许多努力来表征和纠正这些伪影,但它们都集中于一种特定类型的伪影。这项工作有两个贡献。首先,我们基于使用一组角度和平移参数的成像系统的 3D 描述,系统地记录机械工件的目录。然后,我们引入了一种校准算法,该算法可以恢复输入到最终 3D 迭代重建算法中的未知系统参数,以获得无失真体积图像。 |
| Neural Lithography: Close the Design-to-Manufacturing Gap in Computational Optics with a 'Real2Sim' Learned Photolithography Simulator Authors Cheng Zheng, Guangyuan Zhao, Peter T.C. So 我们引入神经光刻来解决计算光学中从设计到制造的差距。具有较大设计自由度的计算光学器件可实现超越传统光学器件的先进功能和性能。然而,现有的设计方法常常忽视制造过程的数值建模,这可能导致设计和制造的光学器件之间出现显着的性能偏差。为了弥补这一差距,我们首次提出了一种完全可微分的设计框架,该框架将预先训练的光刻模拟器集成到基于模型的光学设计循环中。我们的光刻模拟器利用物理信息建模和数据驱动训练的结合,使用实验收集的数据集,作为设计过程中制造可行性的调节器,补偿光刻过程中引入的结构差异。 |
| MixQuant: Mixed Precision Quantization with a Bit-width Optimization Search Authors Eliska Kloberdanz, Wei Le 量化是一种创建高效深度神经网络 DNN 的技术,涉及以低于 f32 浮点精度的位宽执行计算和存储张量。量化可减少模型大小和推理延迟,因此允许将 DNN 部署在计算资源和实时系统受限的平台上。然而,量化可能会因舍入误差而导致数值不稳定,从而导致计算不准确,从而降低量化模型的精度。与之前的工作类似,这些工作表明偏差和激活都对量化更敏感,并且最好保持全精度或以更高的位宽度进行量化,我们表明某些权重比其他权重更敏感,这应该反映在其量化位上宽度。为此,我们提出了 MixQuant,这是一种搜索算法,可以根据舍入误差找到每个层权重的最佳自定义量化位宽,并且可以与任何量化方法结合作为预处理优化的一种形式。我们证明,将 MixQuant 与 BRECQ(一种最先进的量化方法)相结合,可以比单独使用 BRECQ 产生更好的量化模型精度。 |
| Improving Trajectory Prediction in Dynamic Multi-Agent Environment by Dropping Waypoints Authors Pranav Singh Chib, Pravendra Singh 轨迹固有的多样性和不确定性给精确建模带来了巨大的挑战。运动预测系统必须有效地学习过去的空间和时间信息,以预测智能体的未来轨迹。许多现有方法通过堆叠模型中的单独组件来学习时间运动以捕获时间特征。本文介绍了一种名为 Temporal Waypoint Dropping TWD 的新颖框架,该框架通过路点丢弃技术促进显式时间学习。通过路径点丢弃进行学习可以迫使模型提高对代理之间时间相关性的理解,从而显着增强轨迹预测。轨迹预测方法通常假设观测到的轨迹航路点序列是完整的,而忽略了可能出现缺失值的现实场景,这可能会影响其性能。此外,这些模型在进行预测时经常表现出对特定航路点序列的偏差。我们的TWD有能力有效解决这些问题。它结合了随机和固定过程,通过基于时间序列战略性地删除航路点来规范预测的过去轨迹。通过大量的实验,我们证明了 TWD 在迫使模型学习代理之间复杂的时间相关性方面的有效性。我们的方法可以补充现有的轨迹预测方法,以提高预测精度。 |
| Multi-Depth Branches Network for Efficient Image Super-Resolution Authors Huiyuan Tian, Li Zhang, Shijian Li, Min Yao, Gang Pan 超分辨率 SR 领域已经取得了重大进展,但许多基于 CNN 的 SR 模型主要侧重于恢复高频细节,往往忽略了关键的低频轮廓信息。基于 Transformer 的 SR 方法虽然结合了全局结构细节,但经常带有大量参数,导致计算开销较高。在本文中,我们通过引入多深度分支网络 MDBN 来应对这些挑战。该框架通过集成一个捕获图像重要结构特征的附加分支来扩展 ResNet 架构。我们提出的多深度分支模块 MDBM 涉及在不同分支内不同深度处堆叠相同大小的卷积核。通过对特征图进行全面分析,我们观察到不同深度的分支可以分别提取轮廓和细节信息。通过整合这些分支,整体架构可以在高频视觉元素的恢复过程中保留必要的低频语义结构信息,这与人类视觉认知更加接近。与类似 GoogLeNet 的模型相比,我们的基本多深度分支结构具有更少的参数、更高的计算效率和更高的性能。我们的模型优于最先进的 SOTA 轻量级 SR 方法,推理时间更短。 |
| Development of a Deep Learning Method to Identify Acute Ischemic Stroke Lesions on Brain CT Authors Alessandro Fontanella, Wenwen Li, Grant Mair, Antreas Antoniou, Eleanor Platt, Paul Armitage, Emanuele Trucco, Joanna Wardlaw, Amos Storkey 计算机断层扫描 CT 通常用于对急性缺血性中风 AIS 患者进行成像,但放射科医生对其进行解释非常耗时,并且容易受到观察者间差异的影响。深度学习 DL 技术可以提供自动化 CT 脑部扫描评估,但通常需要带注释的图像。为了使用来自 AIS 患者的标记但未注释的 CT 脑部扫描来开发用于 AIS 的 DL 方法,我们使用从第三次国际中风试验 IST 3 中常规收集的 CT 脑部扫描来设计一种基于卷积神经网络的 DL 算法,这些扫描不是使用严格的研究协议。 DL 模型旨在检测 AIS 病变并对受影响的大脑一侧进行分类。我们探讨了 AIS 病变特征、背景大脑外观和时间对 DL 性能的影响。根据专家标记,对 2347 名平均年龄为 82 岁的 AIS 患者进行了 5772 次独特的 CT 扫描,其中 54 名患者存在可见的 AIS 病变。我们性能最佳的 DL 方法在病变存在和侧面方面达到了 72 的准确度。两个病变的准确度为 80 或多个 87 的准确度较大,三个或更多的准确度为 100 的病变可以更好地检测到。后续扫描的准确度为 76,而基线扫描的准确度为 67。慢性脑部疾病降低了准确性,特别是非中风病变和陈旧性中风病变的错误率分别为 32 和 31。可以使用大量常规收集的 CT 脑部扫描数据来设计 DL 方法,用于 CT 上的 AIS 病变检测。 |
| Unpaired Optical Coherence Tomography Angiography Image Super-Resolution via Frequency-Aware Inverse-Consistency GAN Authors Weiwen Zhang, Dawei Yang, Haoxuan Che, An Ran Ran, Carol Y. Cheung, Hao Chen 对于光学相干断层扫描血管造影 OCTA 图像,有限的扫描速率导致在视场 FOV 和成像分辨率之间进行权衡。尽管较大的视场图像可能会揭示更多的中心凹旁血管病变,但由于分辨率较低,其应用受到很大限制。为了提高分辨率,以前的工作仅通过使用配对数据进行训练来获得令人满意的性能,但现实世界的应用受到收集大规模配对图像的挑战的限制。因此,非常需要一种不配对的方法。生成对抗网络 GAN 常用于未配对的环境中,但它可能很难准确保留细粒度的毛细血管细节,而这些细节是 OCTA 的关键生物标志物。在本文中,我们的方法希望通过利用频率信息来保留这些细节,频率信息将细节表示为高频 textbf hf ,将粗粒度背景表示为低频 textbf lf 。总的来说,我们针对 OCTA 图像提出了一种基于 GAN 的不成对超分辨率方法,并通过双路径生成器特别强调 textbf hf 细毛细血管。为了促进重建图像的精确频谱,我们还为鉴别器提出了频率感知的对抗性损失,并引入了频率感知的焦点一致性损失以进行端到端优化。 |
| Glioma subtype classification from histopathological images using in-domain and out-of-domain transfer learning: An experimental study Authors Vladimir Despotovic, Sang Yoon Kim, Ann Christin Hau, Aliaksandra Kakoichankava, Gilbert Georg Klamminger, Felix Bruno Kleine Borgmann, Katrin B. M. Frauenknecht, Michel Mittelbronnf, Petr V. Nazarov 我们在本文中对成人型弥漫性胶质瘤的计算机辅助分类的各种迁移学习策略和深度学习架构进行了全面比较。我们评估了组织病理学图像目标域的域外 ImageNet 表示的泛化性,并使用自监督和多任务学习方法研究域内适应的影响,以使用中大规模组织病理学图像数据集预训练模型。此外还提出了一种半监督学习方法,其中利用微调模型来预测整个幻灯片图像 WSI 的未注释区域的标签。随后使用上一步中确定的地面实况标签和弱标签对模型进行重新训练,与领域迁移学习的标准相比,提供了卓越的性能,平衡精度为 96.91,F1 分数为 97.07,并最大限度地减少了病理学家的注释工作。 |
| Robots That Can See: Leveraging Human Pose for Trajectory Prediction Authors Tim Salzmann, Lewis Chiang, Markus Ryll, Dorsa Sadigh, Carolina Parada, Alex Bewley 预测家庭和办公室等动态环境中所有人的运动对于实现安全有效的机器人导航至关重要。这些空间仍然具有挑战性,因为人类不遵循严格的运动规则,并且通常存在多个封闭的入口点,例如角落和门,为突然相遇创造了机会。在这项工作中,我们提出了一种基于 Transformer 的架构,可根据输入特征(包括来自船上野外感官信息的人体位置、头部方向和 3D 骨骼关键点)来预测以人为中心的环境中人类未来的轨迹。由此产生的模型捕获了未来人类轨迹预测的固有不确定性,并在通用预测基准和从适合预测任务的移动机器人捕获的人类跟踪数据集上实现了最先进的性能。 |
| An Investigation Into Race Bias in Random Forest Models Based on Breast DCE-MRI Derived Radiomics Features Authors Mohamed Huti, Tiarna Lee, Elinor Sawyer, Andrew P. King 最近的研究表明,人工智能模型在使用受保护属性不平衡的数据进行训练时可能会表现出性能偏差。迄今为止,大多数工作都集中在深度学习模型上,但利用手工制作的特征的经典人工智能技术也可能容易受到这种偏见的影响。在本文中,我们研究了使用放射组学特征训练的随机森林 RF 模型中存在种族偏见的可能性。我们的应用是通过乳腺癌患者的动态对比增强磁共振成像 DCE MRI 来预测肿瘤分子亚型。我们的结果表明,从 DCE MRI 数据导出的放射组学特征确实包含种族可识别信息,并且可以训练 RF 模型根据这些数据预测白人和黑人种族,准确度为 60 到 70,具体取决于所使用的特征子集。 |
| A Survey of Incremental Transfer Learning: Combining Peer-to-Peer Federated Learning and Domain Incremental Learning for Multicenter Collaboration Authors Yixing Huang, Christoph Bert, Ahmed Gomaa, Rainer Fietkau, Andreas Maier, Florian Putz 由于数据隐私的限制,多个临床中心之间的数据共享受到限制,这阻碍了多中心协作高性能深度学习模型的开发。朴素的权重转移方法在没有原始数据的情况下共享中间模型权重,因此可以绕过数据隐私限制。然而,当模型从一个中心转移到下一个中心时,由于遗忘问题,通常会观察到性能下降。增量迁移学习结合了点对点联邦学习和领域增量学习,可以克服数据隐私问题,同时通过使用持续学习技术来保持模型性能。在这项工作中,传统的领域任务增量学习框架适用于增量迁移学习。对不同的基于正则化的持续学习方法在多中心协作中的有效性进行了全面调查。数据异构性、分类器头设置、网络优化器、模型初始化、中心顺序和权重传递类型的影响已得到彻底研究。 |
| RTFS-Net: Recurrent time-frequency modelling for efficient audio-visual speech separation Authors Samuel Pegg, Kai Li, Xiaolin Hu 视听语音分离方法旨在集成不同的模态以生成高质量的分离语音,从而提高语音识别等下游任务的性能。大多数现有的最先进的 SOTA 模型都在时域中运行。然而,他们过于简单化的声学特征建模方法通常需要更大、计算量更大的模型才能实现 SOTA 性能。在本文中,我们提出了一种新颖的时频域视听语音分离方法循环时频分离网络RTFS Net,该方法将其算法应用于短时傅立叶变换产生的复杂时频箱。我们使用多层 RNN 沿着每个维度独立地建模和捕获音频的时间和频率维度。此外,我们引入了一种独特的基于注意力的融合技术,用于音频和视觉信息的有效集成,以及一种新的掩模分离方法,该方法利用声学特征的固有频谱性质来实现更清晰的分离。 RTFS Net 仅使用 10 个参数和 18 个 MAC,性能优于之前的 SOTA 方法。 |
| A Vision-Guided Robotic System for Grasping Harvested Tomato Trusses in Cluttered Environments Authors Luuk van den Bent, Tom s Coleman, Robert Babuska 目前,桁架番茄称重和包装需要大量的手工工作。自动化的主要障碍在于难以为已经收获的桁架开发可靠的机器人抓取系统。我们提出了一种方法来抓取堆放在相当杂乱的板条箱中的桁架,这也是它们在收获后通常储存和运输的方式。该方法由基于深度学习的视觉系统组成,首先识别板条箱中的各个桁架,然后确定杆上合适的抓取位置。为此,我们引入了具有在线学习功能的抓取姿势排名算法。选择最有希望的抓取姿势后,机器人无需触摸传感器或几何模型即可执行捏握。使用配备有手眼 RGB D 相机的机器人操纵器进行的实验室实验显示,当任务从一堆桁架中拾取所有桁架时,清除率达到 100。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com