.
- 1.分析视频请求
- 1
- 2
- 3
- 2.数据获取和拼接
1.分析视频请求
1
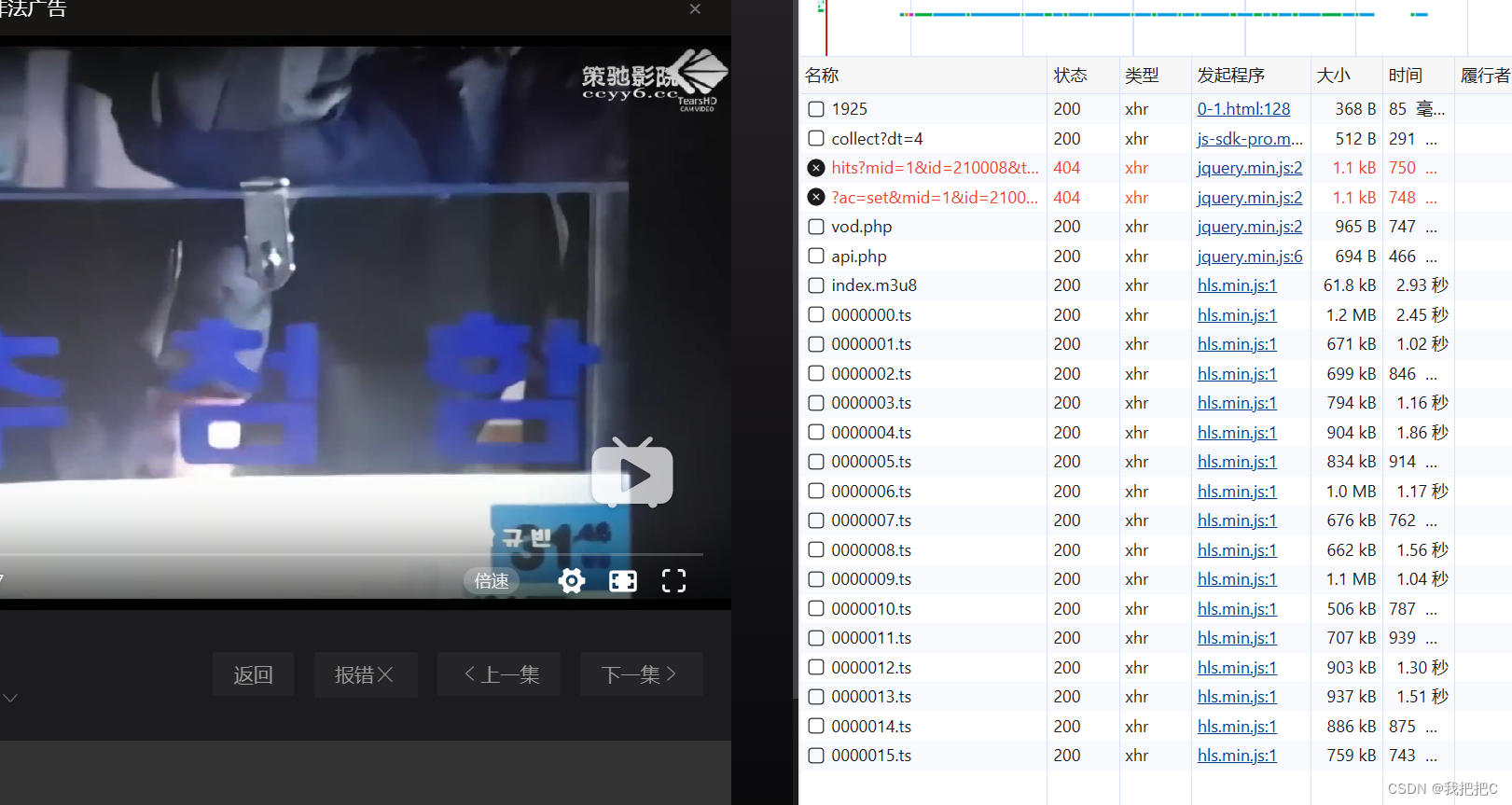
通过抓包观察我们发现视频是由.ts文件拼接成的每一个.ts文件代表一小段
2
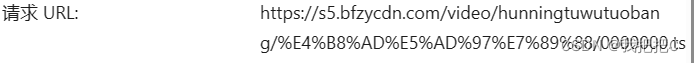

通过观察0.ts和1.ts的url我们发现他们只有最后一段不同我们网上找到url获取的包
3
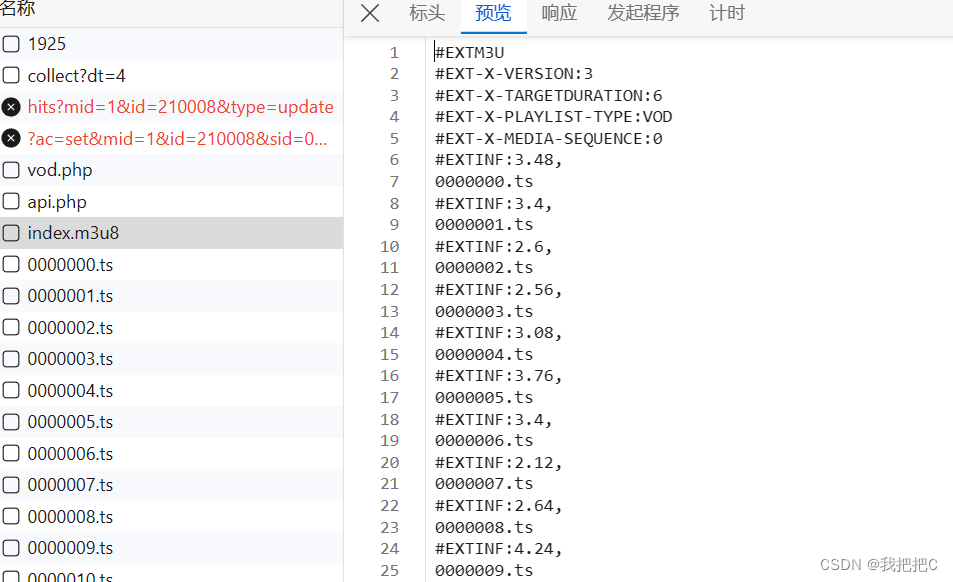
我们发现index.m3u8中储存着所有的.ts文件名在拼接上前面固定的url就可以获取到.ts文件
2.数据获取和拼接
import shutil
import requests
import re
import os
from multiprocessing.dummy import Pool
url ='https://vip.lz-cdn.com/20221109/37176_faf59775/1200k/hls/mixed.m3u8' # m3u8网址
res = requests.get(url).text
print(res)
# 正则提取内容
ts=re.findall(r",\n(.*?)\d+.ts",res,flags=re.S)[0]
print(ts)
ts2=re.findall(r"(\d+).ts",res,flags=re.S)
print(ts2)
start=int(ts2[0])
end=int(ts2[-1])
def xlx(i):
i=ts+str(i)
# 拼接完整的ts文件下载链接
u = 'https://vip.lz-cdn.com/20221109/37176_faf59775/1200k/hls/' + i + ".ts"#拼接url
r = requests.get(url=u).content
print(i, u)
# 二进制写入到本地
with open('./nihao/' + i + '.ts', mode="wb") as file:
file.write(r)
if not os.path.exists('./nihao'):
os.mkdir('./nihao')
else:
shutil.rmtree('./nihao')
os.mkdir('./nihao')
pool = Pool(100) #开启线程池
# 定义循环数
origin_num = [ x for x in range(start,end+1)]
pool.map(xlx, origin_num)
os.system('copy /b ' + r'E:\python\xinfadi\nihao\*.ts ' + r'E:\python\xinfadi\new.mp4')
print("合并成功")



![[C++_containers]10分钟让你掌握vector](https://img-blog.csdnimg.cn/2061eb2ab5e14341aee0189b14c35bbd.png)