AUC的计算方法同时考虑了分类器对于正例和负例的分类能力,在样本不平衡的情况下,依然能够对分类器作出合理的评价。AUC代表模型预估样本之间的排序关系,即正负样本之间预测的gap越大,auc越大.
来自 https://blog.csdn.net/pearl8899/article/details/126129148

import numpy as np
from sklearn.metrics import roc_auc_score
y_true = np.array([1,1,0,0,1,1,0])
y_scores = np.array([0.8,0.7,0.5,0.5,0.5,0.5,0.3])
print "y_true is ",y_true
print "y_scores is ",y_scores
print "AUC is",roc_auc_score(y_true, y_scores)
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
print "y_true is ",y_true
print "y_scores is ",y_scores
print "AUC is ",roc_auc_score(y_true, y_scores)
以下图片截图自bilibili的https://www.bilibili.com/video/BV1H54y1D7or/?spm_id_from=333.337.search-card.all.click&vd_source=31b5f71a7c377ebe9d0311113f0f1586
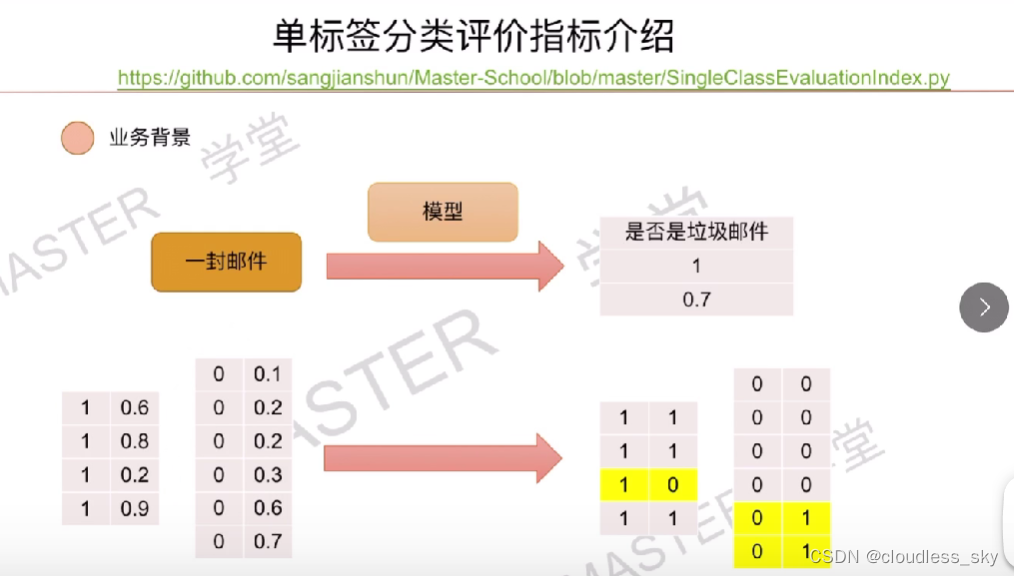

使用AUC是因为,当样本分布不均衡的时候,比如全是1的时候,F1就很高,但是此时模型实际上很差,所以需要一个不受阈值选择影响的指标。
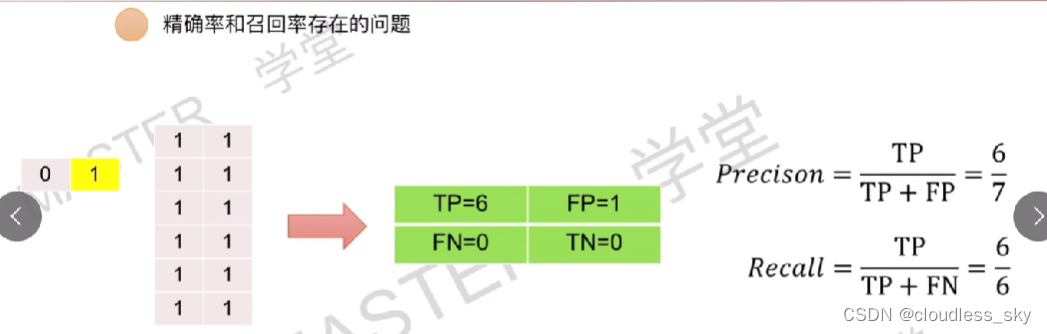
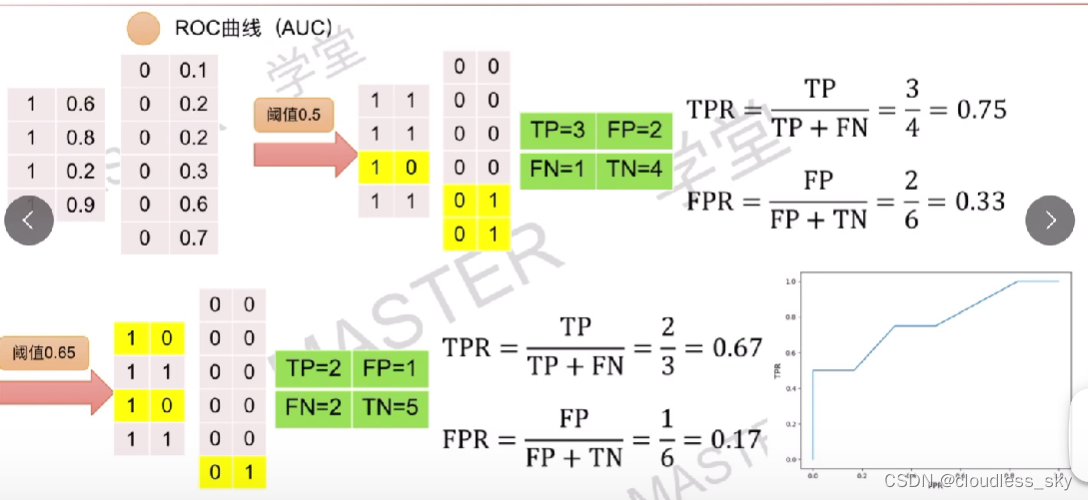
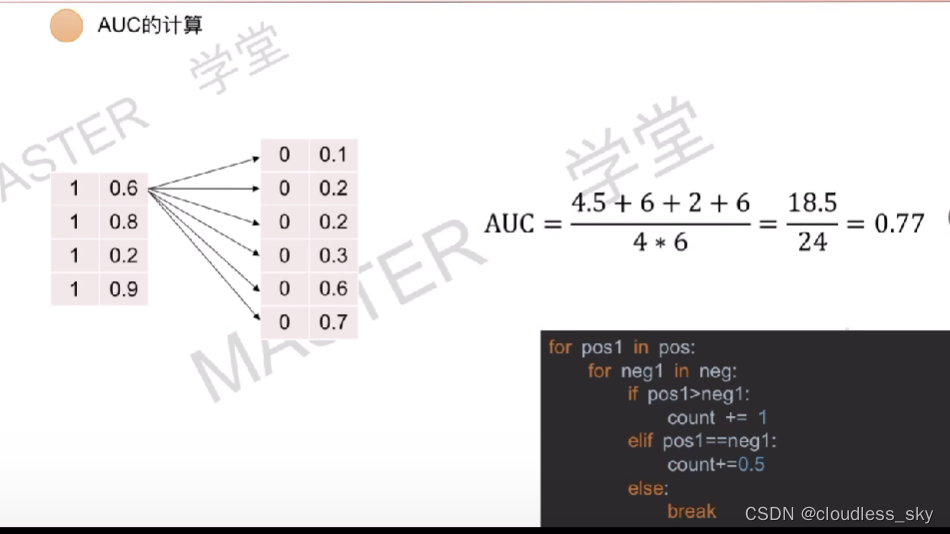
ROC曲线上的每一个点都是取不同阈值得到的,曲线下的面积就是AUC。由于面积不太好求,所以我们使用另一种简单的方法:



![[H5动画制作系列]帧代码运行顺序测试](https://img-blog.csdnimg.cn/cf87bef194dc46fdb11aaea8954dd7ed.png)


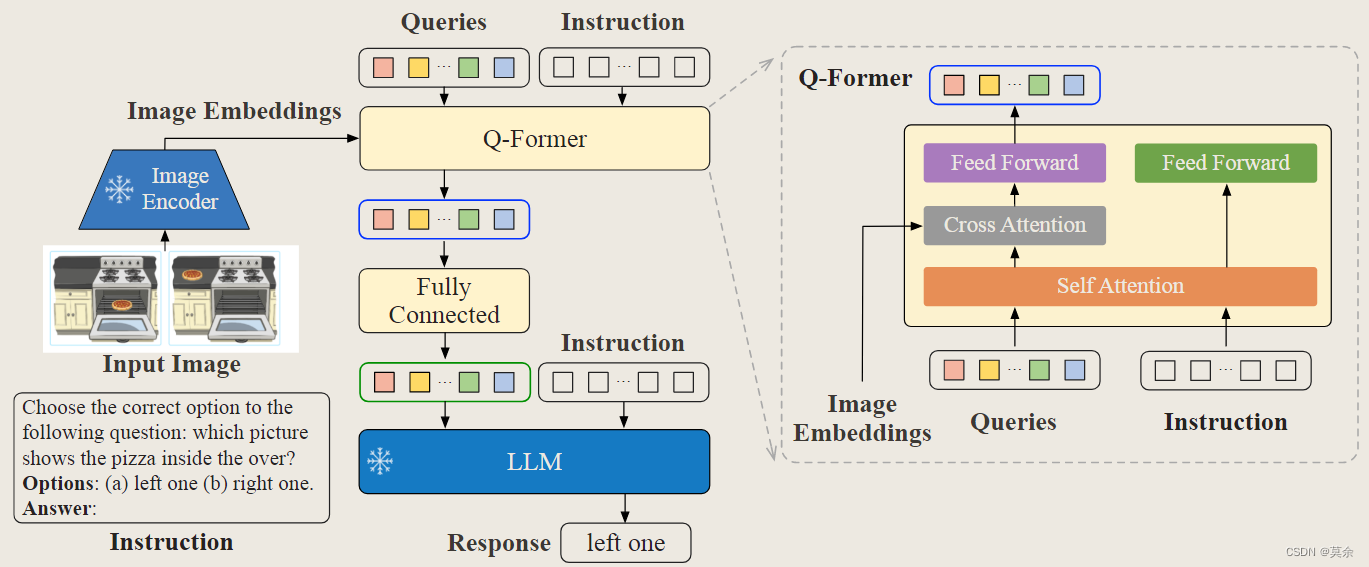
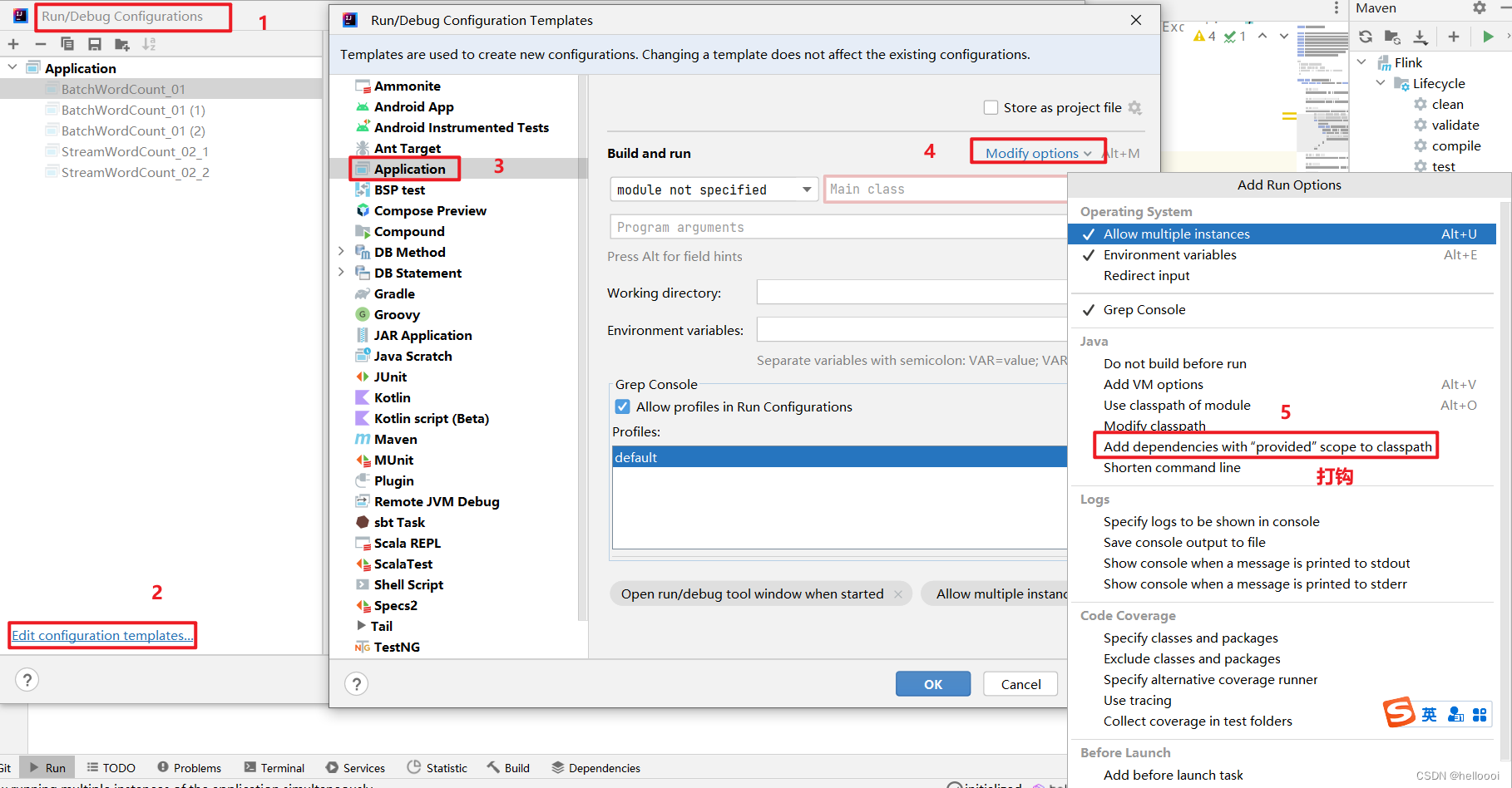



![[论文笔记]UNILM](https://img-blog.csdnimg.cn/img_convert/2d1261c204cbcbe50002d7933098b7ce.png)