实验篇——根据群体经纬度提取环境数据(数据降维)
文章目录
- 前言
- 一、先导
- 二、R语言实现
- 2.1. 分气温、降水、光照、风速、蒸汽压划分数据集
- 2.2. 对每个数据集降维处理
- 2.2.1. 气温
- 2.2.2. 降水
- 2.2.2. 光照
- 2.2.3. 风速
- 2.2.4. 蒸汽压
- 2.2.5.定义一个函数(额外)
- 2.3. 整理保存
- 总结
前言
前一篇文章中对环境数据进行了提取,提取了原始的数据后,根据所需要求对原始数据进行预处理,本章将介绍一下对得到的环境数据进行降维处理。
一、先导
从这几个环境文件来看,可大致分为气温、降水、太阳辐射、风速、蒸汽压这几个方面。
在biozong文件中,bio1–bio11都是与温度相关的环境因子,bio12–bio19则是与降水有关
二、R语言实现
2.1. 分气温、降水、光照、风速、蒸汽压划分数据集
#分气温、降水、光照、风速、蒸汽压划分数据集
#导入文件:
library(dplyr)
longla<- read.table("D:/Cja_location.txt",header = T) #读取经纬度文件
bio <- read.table("D:/huanjing_chuli/biozong.csv",sep = ",",header = TRUE) #
tmin <- read.table("D:/huanjing_chuli/tminzong.csv",sep = ",",header = TRUE) #
tmax <- read.table("D:/huanjing_chuli/tmaxzong.csv",sep = ",",header = TRUE) #
tavg <- read.table("D:/huanjing_chuli/tavgzong.csv",sep = ",",header = TRUE) #
elev <- read.table("D:/huanjing_chuli/elevzong.csv",sep = ",",header = TRUE)
prec <- read.table("D:/huanjing_chuli/preczong.csv",sep = ",",header = TRUE) #
srad <- read.table("D:/huanjing_chuli/sradzong.csv",sep = ",",header = TRUE)
wind <- read.table("D:/huanjing_chuli/windzong.csv",sep = ",",header = TRUE)
vapr <- read.table("D:/huanjing_chuli/vaprzong.csv",sep = ",",header = TRUE)
#整合为气温数据集
bio1_11 <- dplyr::select(bio,bio1:bio11) #因为bio1到bio11是有关气温的数据
data_tmp <- cbind(bio1_11,tmax,tmin,tavg)
#ncol(data_tmp)
data_tmp <- dplyr::mutate_all(data_tmp,as.numeric) #将所有数据转换为数值形式
rownames(data_tmp) <- longla$Population
#head(data_tmp)
#整合为降水数据(同理)
bio12_19 <- dplyr::select(bio,bio12:bio19) #因为bio12到bio19是有关降水的数据
data_prec <- cbind(bio12_19,prec)
#ncol(data_prec)
data_prec <- dplyr::mutate_all(data_prec,as.numeric)
rownames(data_prec) <- longla$Population
#head(data_prec)
#光照数据集:
data_srad <- dplyr::mutate_all(srad,as.numeric)
rownames(data_srad) <- longla$Population
#head(data_srad)
#风速数据集:
data_wind <- dplyr::mutate_all(wind,as.numeric)
rownames(data_wind) <- longla$Population
#head(data_srad)
# 蒸汽压数据集
data_vapr <- dplyr::mutate_all(vapr,as.numeric)
rownames(data_vapr) <- longla$Population
#head(data_vapr)
2.2. 对每个数据集降维处理
2.2.1. 气温
以气温类别为例
library("FactoMineR")
library("factoextra")
#对每个类别进行降维处理,挑选出解释度前99%的因子
#tmp:
bio.pca <- PCA(X = data_tmp,scale.unit = TRUE, ncp = 20, graph = TRUE) #scale.unit = TRUE设置了在进行PCA时自动进行归一化处理
biotem_pre <- bio.pca$ind$coord %>% as.data.frame
#head(biotem_pre)
write.table(biotem_pre,file = 'tmp_PCA.xls',sep="\t",col.names = TRUE,row.names = FALSE)
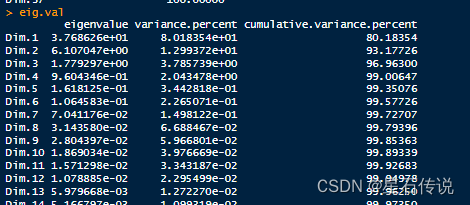
eig.val<- get_eigenvalue(bio.pca)
eig.val #查看方差贡献度
toplvector <- biotem_pre[,1:4]
colnames(toplvector) <- c("tmp1",'tmp2','tmp3','tmp4')
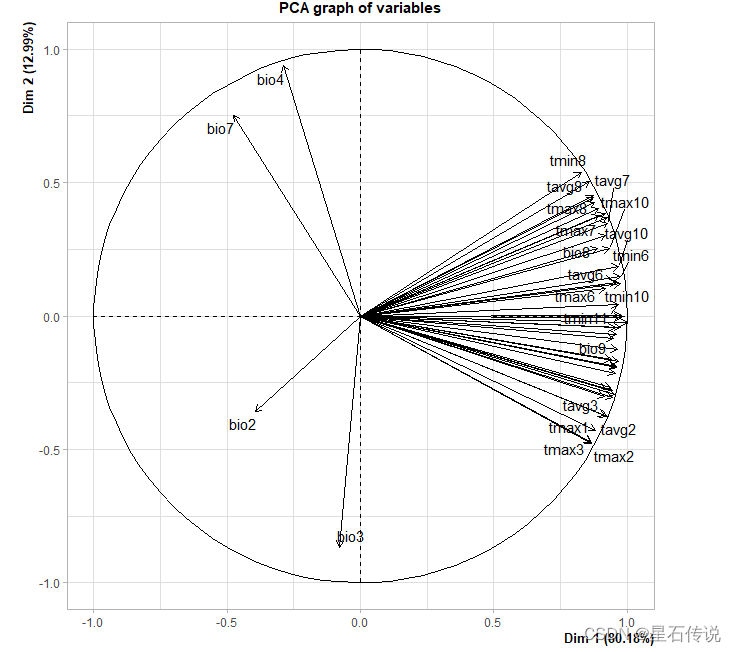
因为我们只挑选出解释度前99%的因子,所以我们只选取前四个因子
2.2.2. 降水
与上同理
#prec
bio.pca <- PCA(X = data_prec ,scale.unit = TRUE, ncp = 20, graph = TRUE)
biotem_pre <- bio.pca$ind$coord %>% as.data.frame
#head(biotem_pre)
write.table(biotem_pre,file = 'prec_PCA.xls',sep="\t",col.names = TRUE,row.names = FALSE)
eig.val<- get_eigenvalue(bio.pca)
eig.val
toplvector <- cbind(toplvector,biotem_pre[,1:7])
colnames(toplvector)[5:11] <- c("prec1",'prec2','prec3','prec4','prec5','prec6',"prec7")
2.2.2. 光照
#srad
bio.pca <- PCA(X = data_srad ,scale.unit = TRUE, ncp = 20, graph = TRUE)
biotem_pre <- bio.pca$ind$coord %>% as.data.frame
#head(biotem_pre)
write.table(biotem_pre,file = 'srad_PCA.xls',sep="\t",col.names = TRUE,row.names = FALSE)
eig.val<- get_eigenvalue(bio.pca)
eig.val
toplvector <- cbind(toplvector,biotem_pre[,1:6])
colnames(toplvector)[12:17] <- c("srad1",'srad2','srad3','srad4','srad5',"srad6")
2.2.3. 风速
#wind
bio.pca <- PCA(X = data_wind ,scale.unit = TRUE, ncp = 20, graph = TRUE)
biotem_pre <- bio.pca$ind$coord %>% as.data.frame
#head(biotem_pre)
write.table(biotem_pre,file = 'wind_PCA.xls',sep="\t",col.names = TRUE,row.names = FALSE)
eig.val<- get_eigenvalue(bio.pca)
eig.val
toplvector <- cbind(toplvector,biotem_pre[,1:5])
colnames(toplvector)[18:22] <- c("wind1",'wind2','wind3','wind4','wind5')
2.2.4. 蒸汽压
#vapr
bio.pca <- PCA(X = data_vapr ,scale.unit = TRUE, ncp = 20, graph = TRUE)
biotem_pre <- bio.pca$ind$coord %>% as.data.frame
#head(biotem_pre)
write.table(biotem_pre,file = 'vapr_PCA.xls',sep="\t",col.names = TRUE,row.names = FALSE)
eig.val<- get_eigenvalue(bio.pca)
eig.val
toplvector <- cbind(toplvector,biotem_pre[,1:3])
colnames(toplvector)[23:25] <- c("vapr1",'vapr2','vapr3')
2.2.5.定义一个函数(额外)
huangjing_PCA <- function(huangjing_wj,Name){
bio.pca <- PCA(X = huangjing_wj ,scale.unit = TRUE, ncp = 20, graph = TRUE)
biotem_pre <- bio.pca$ind$coord %>% as.data.frame
write.table(biotem_pre,file = paste0(Name ,"_PCA.xls"),sep="\t",col.names = TRUE,row.names = FALSE)
eig.val<- get_eigenvalue(bio.pca)
return(list(eig.val = eig.val, biotem_pre = biotem_pre))
}
#比如对气温数据进行降维
tmp_jiangwei<- huangjing_PCA(data_tmp,"tmp")
print(tmp_jiangwei)
toplvector <- tmp_jiangwei$biotem_pre[,1:4]
colnames(toplvector) <- c("tmp1",'tmp2','tmp3','tmp4')
#再比如降水数据集
prec_jiangwei<- huangjing_PCA(data_prec,"prec")
print(prec_jiangwei)
toplvector <- cbind(toplvector,prec_jiangwei$biotem_pre[,1:7])
colnames(toplvector)[5:11] <- c("prec1",'prec2','prec3','prec4','prec5','prec6',"prec7")
#其它数据集也类似
2.3. 整理保存
#转置保存
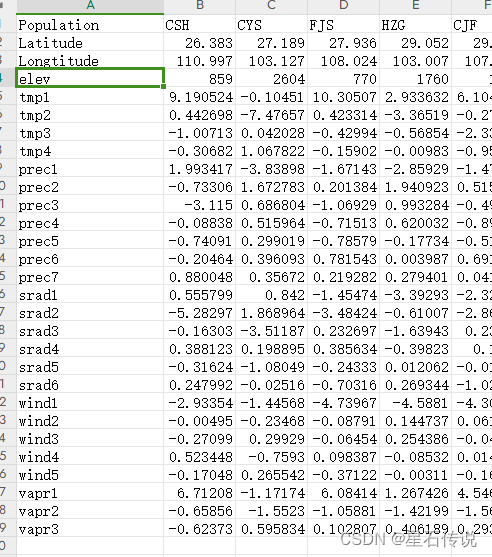
toplvector <- cbind(longla,elev,toplvector)
order <- row.names(toplvector)
trans_toplvector <- t(toplvector[order,]) %>% as.data.frame()
write.table(trans_toplvector,file = "降维后的环境数据文件.csv",sep = ",",col.names = FALSE)
总结
本章简单介绍了一下对先前得到的原始环境数据文件进行降维处理的操作。得到预处理后的数据后,就需要正式进入具体的分析了,根据要求的目的,利用这些数据进行专门的分析。
三十辐,共一毂(gŭ),当其无,有车之用。
–2023-9-29 实验篇