🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
基于机器学习的地震预测模型
数据可视化
拆分数据集
地震预测神经网络
在本文中,我将带您了解如何使用机器学习和 Python 编程语言为地震预测任务创建模型。预测地震是地球科学中尚未解决的重大问题之一。
随着技术使用的增加,许多地震监测站增加了,因此我们可以使用机器学习和其他数据驱动的方法来预测地震。
基于机器学习的地震预测模型
众所周知,如果一个地区发生灾难,很可能会再次发生。一些地区地震频繁,但这只是与其他地区相比的一个数量。
因此,根据以前的数据预测地震的日期和时间、纬度和经度并不是像其他事情那样遵循的趋势,它是自然发生的。
我将开始这项任务,通过导入必要的 Python 库来创建地震预测模型:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt现在让我们加载并读取数据集。我在这里使用的数据集可以在这里轻松下载:
data = pd.read_csv("database.csv")
data.columnsIndex(['Date', 'Time', 'Latitude', 'Longitude', 'Type', 'Depth', 'Depth Error',
'Depth Seismic Stations', 'Magnitude', 'Magnitude Type',
'Magnitude Error', 'Magnitude Seismic Stations', 'Azimuthal Gap',
'Horizontal Distance', 'Horizontal Error', 'Root Mean Square', 'ID',
'Source', 'Location Source', 'Magnitude Source', 'Status'],
dtype='object')
现在让我们看看地震数据的主要特征,并创建一个具有这些特征的对象,即日期、时间、纬度、经度、深度、震级:
data = data[['Date', 'Time', 'Latitude', 'Longitude', 'Depth', 'Magnitude']]
data.head()| date | Time | Latitude | Longitude | Depth | Magnitude | |
|---|---|---|---|---|---|---|
| 0 | 01/02/1965 | 13:44:18 | 19.246 | 145.616 | 131.6 | 6.0 |
| 1 | 01/04/1965 | 11:29:49 | 1.863 | 127.352 | 80.0 | 5.8 |
| 2 | 01/05/1965 | 18:05:58 | -20.579 | -173.972 | 20.0 | 6.2 |
| 3 | 01/08/1965 | 18:49:43 | -59.076 | -23.557 | 15.0 | 5.8 |
| 4 | 01/09/1965 | 13:32:50 | 11.938 | 126.427 | 15.0 | 5.8 |
由于数据是随机的,因此我们需要根据模型输入对其进行缩放。在此,我们将给定的日期和时间转换为以秒为单位的 Unix 时间和数字。这可以很容易地用作我们构建的网络的入口:
import datetime
import time
timestamp = []
for d, t in zip(data['Date'], data['Time']):
try:
ts = datetime.datetime.strptime(d+' '+t, '%m/%d/%Y %H:%M:%S')
timestamp.append(time.mktime(ts.timetuple()))
except ValueError:
# print('ValueError')
timestamp.append('ValueError')
timeStamp = pd.Series(timestamp)
data['Timestamp'] = timeStamp.values
final_data = data.drop(['Date', 'Time'], axis=1)
final_data = final_data[final_data.Timestamp != 'ValueError']
final_data.head()| Latitude | Longitude | Depth | Magnitude | Timestamp | |
|---|---|---|---|---|---|
| 0 | 19.246 | 145.616 | 131.6 | 6.0 | -1.57631e+08 |
| 1 | 1.863 | 127.352 | 80.0 | 5.8 | -1.57466e+08 |
| 2 | -20.579 | -173.972 | 20.0 | 6.2 | -1.57356e+08 |
| 3 | -59.076 | -23.557 | 15.0 | 5.8 | -1.57094e+08 |
| 4 | 11.938 | 126.427 | 15.0 | 5.8 | -1.57026e+08 |
数据可视化
现在,在我们创建地震预测模型之前,让我们在一张世界地图上可视化数据,该地图清楚地显示了地震频率更高的地方:
from mpl_toolkits.basemap import Basemap
m = Basemap(projection='mill',llcrnrlat=-80,urcrnrlat=80, llcrnrlon=-180,urcrnrlon=180,lat_ts=20,resolution='c')
longitudes = data["Longitude"].tolist()
latitudes = data["Latitude"].tolist()
#m = Basemap(width=12000000,height=9000000,projection='lcc',
#resolution=None,lat_1=80.,lat_2=55,lat_0=80,lon_0=-107.)
x,y = m(longitudes,latitudes)
fig = plt.figure(figsize=(12,10))
plt.title("All affected areas")
m.plot(x, y, "o", markersize = 2, color = 'blue')
m.drawcoastlines()
m.fillcontinents(color='coral',lake_color='aqua')
m.drawmapboundary()
m.drawcountries()
plt.show()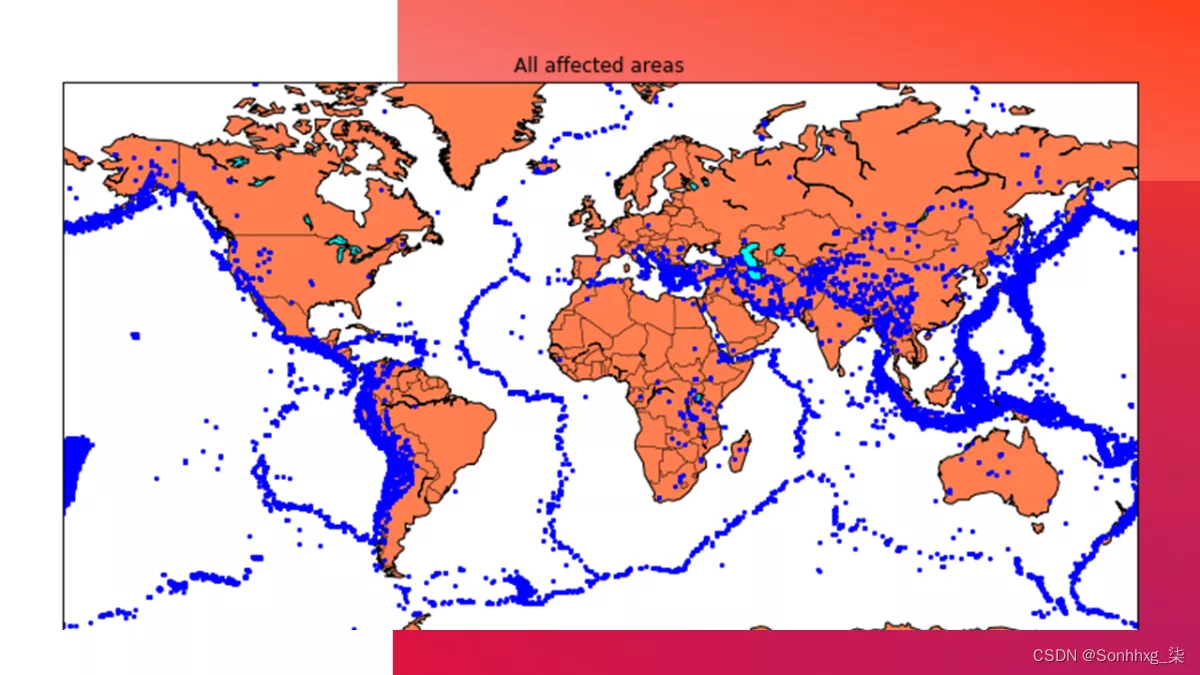
拆分数据集
现在,要创建地震预测模型,我们需要将数据分为 Xs 和 ys,分别作为输入输入到模型中,以接收模型的输出。
这里的输入是时间戳、纬度和经度,输出是幅度和深度。我将把 xs 和 ys 分成训练和测试验证。训练集包含80%,测试集包含20%:
X = final_data[['Timestamp', 'Latitude', 'Longitude']]
y = final_data[['Magnitude', 'Depth']]
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(X_train.shape, X_test.shape, y_train.shape, X_test.shape)(18727,3)(4682,3)(18727,2)(4682,3)
地震预测神经网络
现在我将创建一个神经网络来拟合训练集中的数据。我们的神经网络将由三个密集层组成,每个层有 16、16、2 个节点并重新读取。Relu 和 softmax 将用作激活函数:
from keras.models import Sequential
from keras.layers import Dense
def create_model(neurons, activation, optimizer, loss):
model = Sequential()
model.add(Dense(neurons, activation=activation, input_shape=(3,)))
model.add(Dense(neurons, activation=activation))
model.add(Dense(2, activation='softmax'))
model.compile(optimizer=optimizer, loss=loss, metrics=['accuracy'])
return model现在我将使用两个或更多选项来定义超参数以找到最合适的:
from keras.wrappers.scikit_learn import KerasClassifier
model = KerasClassifier(build_fn=create_model, verbose=0)
# neurons = [16, 64, 128, 256]
neurons = [16]
# batch_size = [10, 20, 50, 100]
batch_size = [10]
epochs = [10]
# activation = ['relu', 'tanh', 'sigmoid', 'hard_sigmoid', 'linear', 'exponential']
activation = ['sigmoid', 'relu']
# optimizer = ['SGD', 'RMSprop', 'Adagrad', 'Adadelta', 'Adam', 'Adamax', 'Nadam']
optimizer = ['SGD', 'Adadelta']
loss = ['squared_hinge']
param_grid = dict(neurons=neurons, batch_size=batch_size, epochs=epochs, activation=activation, optimizer=optimizer, loss=loss)现在我们需要找到上述模型的最佳拟合,并得到最佳拟合模型的平均测试分数和标准差:
grid = GridSearchCV(estimator=model, param_grid=param_grid, n_jobs=-1)
grid_result = grid.fit(X_train, y_train)
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))Best: 0.957655 using {'activation': 'relu', 'batch_size': 10, 'epochs': 10, 'loss': 'squared_hinge', 'neurons': 16, 'optimizer': 'SGD'} 0.333316 (0.471398) with: {'activation': 'sigmoid', 'batch_size': 10, 'epochs': 10, 'loss': 'squared_hinge', 'neurons': 16, 'optimizer': 'SGD'} 0.000000 (0.000000) with: {'activation': 'sigmoid', 'batch_size': 10, 'epochs': 10, 'loss': 'squared_hinge', 'neurons': 16, 'optimizer': 'Adadelta'} 0.957655 (0.029957) with: {'activation': 'relu', 'batch_size': 10, 'epochs': 10, 'loss': 'squared_hinge', 'neurons': 16, 'optimizer': 'SGD'} 0.645111 (0.456960) with: {'activation': 'relu', 'batch_size': 10, 'epochs': 10, 'loss': 'squared_hinge', 'neurons': 16, 'optimizer': 'Adadelta'}
在下面的步骤中,最佳拟合参数用于同一模型以计算训练数据和测试数据的分数:
model = Sequential()
model.add(Dense(16, activation='relu', input_shape=(3,)))
model.add(Dense(16, activation='relu'))
model.add(Dense(2, activation='softmax'))
model.compile(optimizer='SGD', loss='squared_hinge', metrics=['accuracy'])
model.fit(X_train, y_train, batch_size=10, epochs=20, verbose=1, validation_data=(X_test, y_test))
[test_loss, test_acc] = model.evaluate(X_test, y_test)
print("Evaluation result on Test Data : Loss = {}, accuracy = {}".format(test_loss, test_acc))所以我们可以在上面的输出中看到我们用于地震预测的神经网络模型表现良好。我希望您喜欢这篇关于如何使用机器学习和 Python 编程语言创建地震预测模型的文章。