🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
使用机器学习预测迁移
将数据拆分为训练集和测试集
预测迁移
在本文中,我将带您完成机器学习任务的真实世界任务,以预测国家之间的人类迁移。人类迁徙是人类流动的一种,其中一次旅行涉及一个人移动以改变他们的住所。
尽可能准确地预测人类迁移对于城市规划应用、国际贸易、传染病传播、保护规划和公共决策制定非常重要。
使用机器学习预测迁移
我将通过导入所有必要的库来开始这项预测迁移的任务:
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn import svm
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
import numpy as np
from sklearn.naive_bayes import GaussianNB我在此任务中用于预测迁移的数据集可以从此处轻松下载。让我们看看数据是什么样的:我想请您注意“Measure”、“Country”和“CitizenShip”列。如果我们想要得到一个预测结果,我们需要将这些字符串值全部转换为一个整数:
data = pd.read_csv('migration_nz.csv')
data.head(10)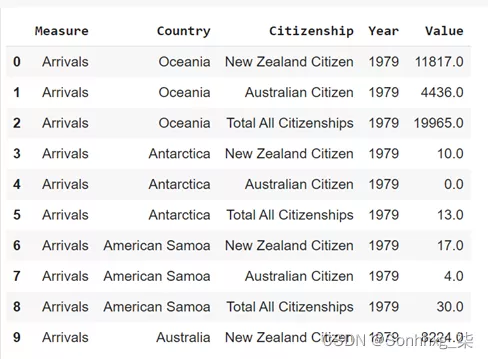
但首先,让我们看看“Measure”列中的唯一值:
array(['Arrivals', 'Departures', 'Net'], dtype=object)现在我们需要为每个唯一的字符串值赋予其唯一的整数值:如果值不多,可以使用“替换”函数:
ata['Measure'].replace("Arrivals",0,inplace=True)
data['Measure'].replace("Departures",1,inplace=True)
data['Measure'].replace("Net",2,inplace=True)现在让我们检查是否所有内容都已正确分配:
array([0, 1, 2])
在这种情况下,我们有大约 250 个独特的国家:
data['Country'].unique()array(['Oceania', 'Antarctica', 'American Samoa', 'Australia',
'Cocos Islands', 'Cook Islands', 'Christmas Island', 'Fiji',
'Micronesia', 'Guam', 'Kiribati', 'Marshall Islands',
'Northern Mariana Islands', 'New Caledonia', 'Norfolk Island',
'Nauru', 'Niue', 'New Zealand', 'French Polynesia',
'Papua New Guinea', 'Pitcairn Island', 'Palau', 'Solomon Islands',
'French Southern Territories', 'Tokelau', 'Tonga', 'Tuvalu',
'Vanuatu', 'Wallis and Futuna', 'Samoa', 'Asia', 'Afghanistan',
'Armenia', 'Azerbaijan', 'Bangladesh', 'Brunei Darussalam',
'Bhutan', 'China', 'Georgia', 'Hong Kong', 'Indonesia', 'India',
'Japan', 'Kyrgyzstan', 'Cambodia', 'North Korea', 'South Korea',
'Kazakhstan', 'Laos', 'Sri Lanka', 'Myanmar', 'Mongolia', 'Macau',
'Maldives', 'Malaysia', 'Nepal', 'Philippines', 'Pakistan',
'Singapore', 'Thailand', 'Tajikistan', 'Timor-Leste',
'Turkmenistan', 'Taiwan', 'Uzbekistan', 'Vietnam', 'Europe',
'Andorra', 'Albania', 'Austria', 'Bosnia and Herzegovina',
'Belgium', 'Bulgaria', 'Belarus', 'Switzerland', 'Czechoslovakia',
'Cyprus', 'Czechia', 'East Germany', 'Germany', 'Denmark',
'Estonia', 'Spain', 'Finland', 'Faeroe Islands', 'France', 'UK',
'Gibraltar', 'Greenland', 'Greece', 'Croatia', 'Hungary', 'Ireland',
'Iceland', 'Italy', 'Kosovo', 'Liechtenstein', 'Lithuania',
'Luxembourg', 'Latvia', 'Monaco', 'Moldova', 'Montenegro',
'Macedonia', 'Malta', 'Netherlands', 'Norway', 'Poland', 'Portugal',
'Romania', 'Serbia', 'Russia', 'Sweden', 'Slovenia', 'Slovakia',
'San Marino', 'USSR', 'Ukraine', 'Vatican City',
'Yugoslavia/Serbia and Montenegro', 'Americas',
'Antigua and Barbuda', 'Anguilla', 'Netherlands Antilles',
'Argentina', 'Aruba', 'Barbados', 'Bermuda', 'Bolivia', 'Brazil',
'Bahamas', 'Belize', 'Canada', 'Chile', 'Colombia', 'Costa Rica',
'Cuba', 'Curacao', 'Dominica', 'Dominican Republic', 'Ecuador',
'Falkland Islands', 'Grenada', 'French Guiana', 'Guadeloupe',
'South Georgia and the South Sandwich Islands', 'Guatemala',
'Guyana', 'Honduras', 'Haiti', 'Jamaica', 'St Kitts and Nevis',
'Cayman Islands', 'St Lucia', 'Martinique', 'Montserrat', 'Mexico',
'Nicaragua', 'Panama', 'Peru', 'St Pierre and Miquelon',
'Puerto Rico', 'Paraguay', 'Suriname', 'El Salvador', 'St Maarten',
'Turks and Caicos', 'Trinidad and Tobago',
'US Minor Outlying Islands', 'USA', 'Uruguay',
'St Vincent and the Grenadines', 'Venezuela',
'British Virgin Islands', 'US Virgin Islands',
'Africa and the Middle East', 'UAE', 'Angola', 'Burkina Faso',
'Bahrain', 'Burundi', 'Benin', 'Botswana',
'Democratic Republic of the Congo', 'Central African Republic',
'Congo', "Cote d'Ivoire", 'Cameroon', 'Cape Verde', 'Djibouti',
'Algeria', 'Egypt', 'Western Sahara', 'Eritrea', 'Ethiopia',
'Gabon', 'Ghana', 'Gambia', 'Guinea', 'Equatorial Guinea',
'Guinea-Bissau', 'Israel', 'British Indian Ocean Territory', 'Iraq',
'Iran', 'Jordan', 'Kenya', 'Comoros', 'Kuwait', 'Lebanon',
'Liberia', 'Lesotho', 'Libya', 'Morocco', 'Madagascar', 'Mali',
'Mauritania', 'Mauritius', 'Malawi', 'Mozambique', 'Namibia',
'Niger', 'Nigeria', 'Oman', 'Palestine', 'Qatar', 'Reunion',
'Rwanda', 'Saudi Arabia', 'Seychelles', 'Sudan', 'St Helena',
'Sierra Leone', 'Senegal', 'Somalia', 'South Sudan',
'Sao Tome and Principe', 'Syria', 'Swaziland', 'Chad', 'Togo',
'Tunisia', 'Turkey', 'Tanzania', 'Uganda', 'South Yemen', 'Yemen',
'Mayotte', 'South Africa', 'Zambia', 'Zimbabwe', 'Not stated',
'All countries'], dtype=object)现在我们需要为每个唯一的字符串值分配其唯一的整数值:
data['CountryID'] = pd.factorize(data.Country)[0]
data['CitID'] = pd.factorize(data.Citizenship)[0]
现在,让我们看看是否一切正常:
现在,让我们看看是否一切正常:
data['CountryID'].unique()array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12,
13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25,
26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38,
39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64,
65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77,
78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90,
91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103,
104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116,
117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129,
130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142,
143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155,
156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168,
169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181,
182, 183, 184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194,
195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207,
208, 209, 210, 211, 212, 213, 214, 215, 216, 217, 218, 219, 220,
221, 222, 223, 224, 225, 226, 227, 228, 229, 230, 231, 232, 233,
234, 235, 236, 237, 238, 239, 240, 241, 242, 243, 244, 245, 246,
247, 248, 249, 250, 251, 252])另一个问题是我们有一些缺失值,让我们看看它们的数量和位置:
data.isnull().sum()Measure 0 Country 0 Citizenship 0 Year 0 Value 72 CountryID 0 CitID 0 dtype: int64
现在,我将简单地用中值填充这些缺失值:
data["Value"].fillna(data["Value"].median(),inplace=True)现在,让我们看看到目前为止是否一切正常:
data.isnull().sum()Measure 0 Country 0 Citizenship 0 Year 0 Value 0 CountryID 0 CitID 0 dtype: int64
将数据拆分为训练集和测试集
现在,我将把数据分成 70% 的训练集和 30% 的测试集:
data.drop('Country', axis=1, inplace=True)
data.drop('Citizenship', axis=1, inplace=True)
from sklearn.cross_validation import train_test_split
X= data[['CountryID','Measure','Year','CitID']].as_matrix()
Y= data['Value'].as_matrix()
X_train, X_test, y_train, y_test = train_test_split(
X, Y, test_size=0.3, random_state=9)预测迁移
现在,让我们使用我们的机器学习算法预测迁移并可视化结果:
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(n_estimators=70,max_features = 3,max_depth=5,n_jobs=-1)
rf.fit(X_train ,y_train)
rf.score(X_test, y_test)0.73654599831394985X = data[['CountryID','Measure','Year','CitID']]
Y = data['Value']
X_train, X_test, y_train, y_test = train_test_split(
X, Y, test_size=0.3, random_state=9)
grouped = data.groupby(['Year']).aggregate({'Value' : 'sum'})
#Growth of migration to New-Zeland by year
grouped.plot(kind='line');plt.axhline(0, color='g')
sns.plt.show()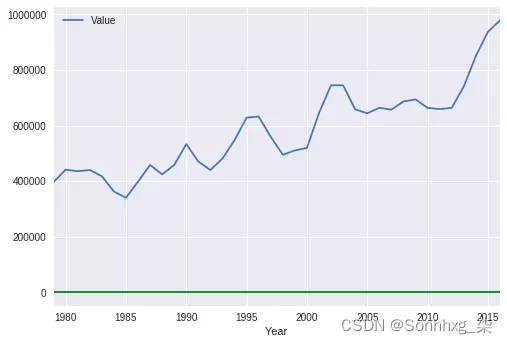
grouped.plot(kind='bar');plt.axhline(0, color='g')
sns.plt.show() 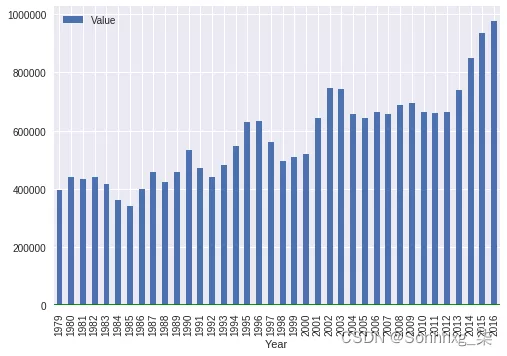
import seaborn as sns
corr = data.corr()
sns.heatmap(corr,
xticklabels=corr.columns.values,
yticklabels=corr.columns.values)
sns.plt.show()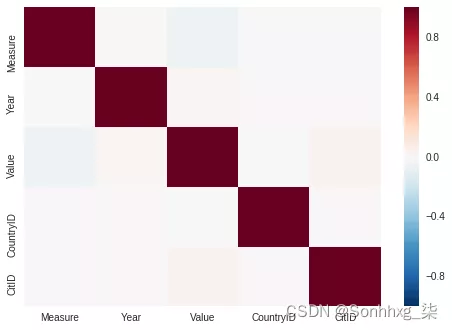
我希望您喜欢这篇基于如何预测国家间人类迁移的简单现实世界任务的文章。我希望您喜欢这篇关于使用机器学习预测迁移的文章。请随时在下面的评论部分提出您宝贵的问题。