本文重点介绍了如何从零训练一个BERT模型的过程,包括整体上BERT模型架构、数据集如何做预处理、MASK替换策略、训练模型和保存、加载模型和测试等。
一.BERT架构
BERT设计初衷是作为一个通用的backbone,然后在下游接入各种任务,包括翻译任务、分类任务、回归任务等。BERT模型架构如下所示:
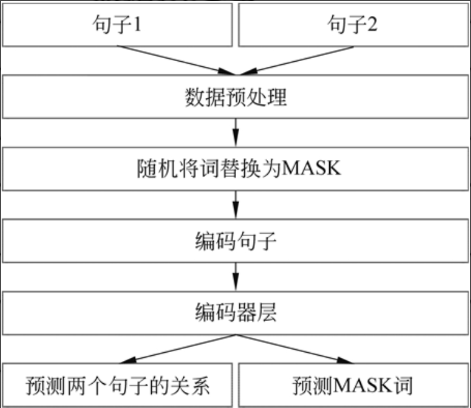
1.输入层
BERT每次计算时输入两句话。
2.数据预处理
包括移除不能识别的字符、将所有字母小写、多余的空格等。

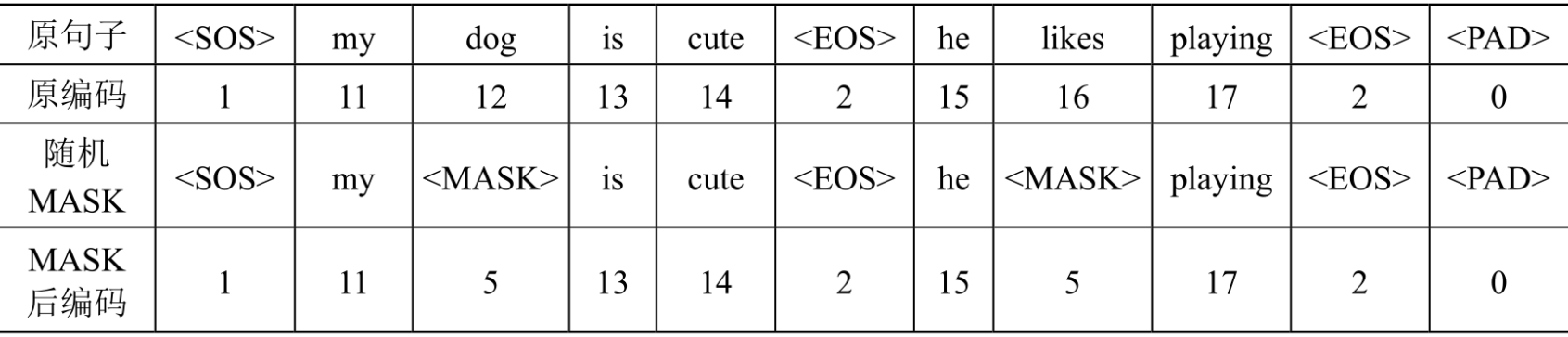
3.随机将一些词替换为MASK
BERT模型的训练过程包括两个子任务,其中一个即为预测被遮掩的词的原本的词,所以在计算之前,需要把句子中的一些词替换为MASK交给BERT预测。

4.编码句子
把句子编码成向量,BERT同样也有位置编码层,以让处于不同位置的相同的词有不同的向量表示。与Transformer位置编码固定常量不同,BERT位置编码是一个可学习的参数。

5.编码器
此处的编码器即为Transformer中的编码器,BERT使用了Transformer中的编码器来抽取文本特征。
6.预测两个句子的关系
BERT的计算包括两个子任务,预测两个句子的关系为其中一个子任务,BERT要计算出输入的两个句子的关系,这一般是二分类任务。
7.预测MASK词
这是BERT的另外一个子任务,要预测出句子中的MASK原本的词。
二.数据集介绍和预处理
1.数据集介绍
数据集使用微软提供的MSR Paraphrase数据集进行训练,第1列的数字表示了这2个句子的意思是否相同,2列ID对于训练BERT模型没有用处,只需关注第1列和另外2列String。部分样例如下所示:
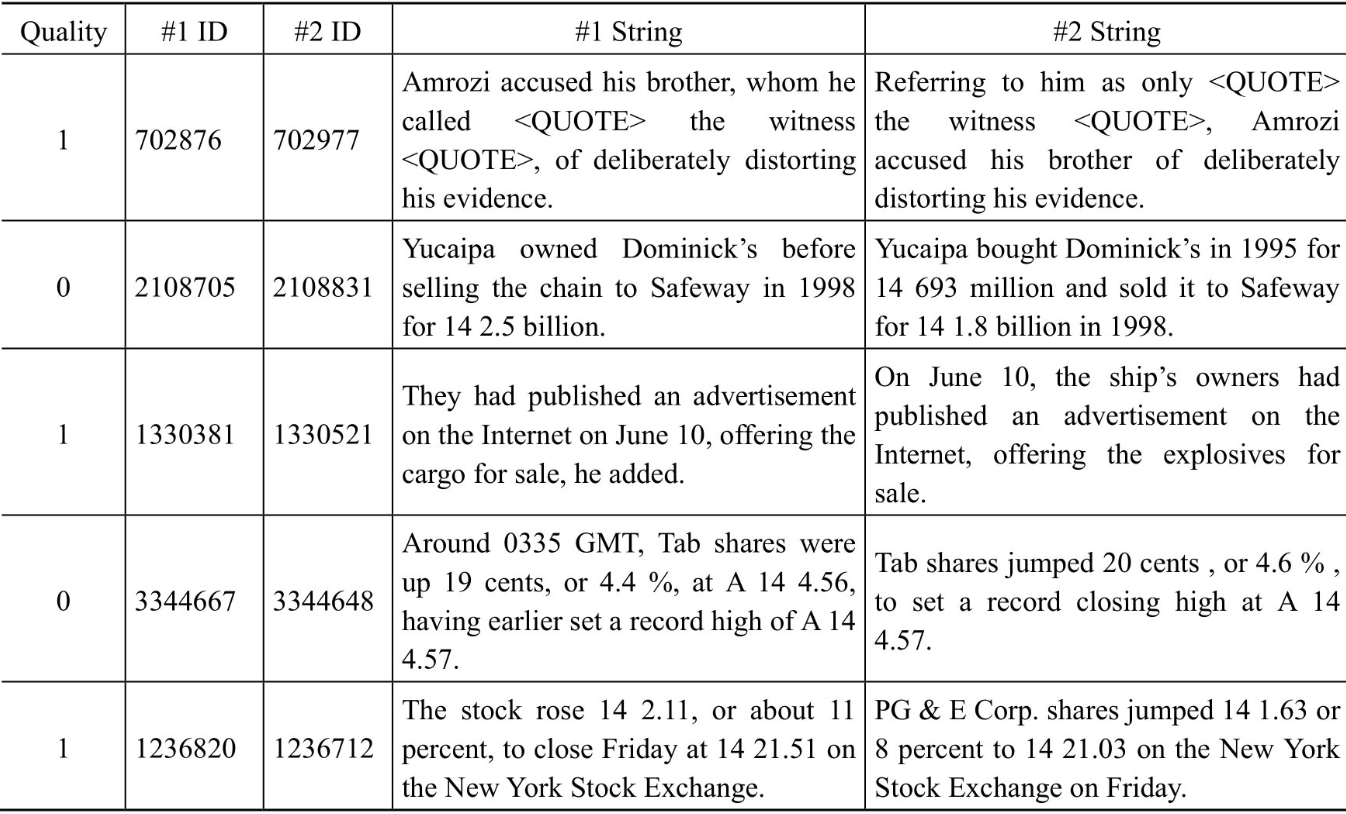
2.数据集预处理
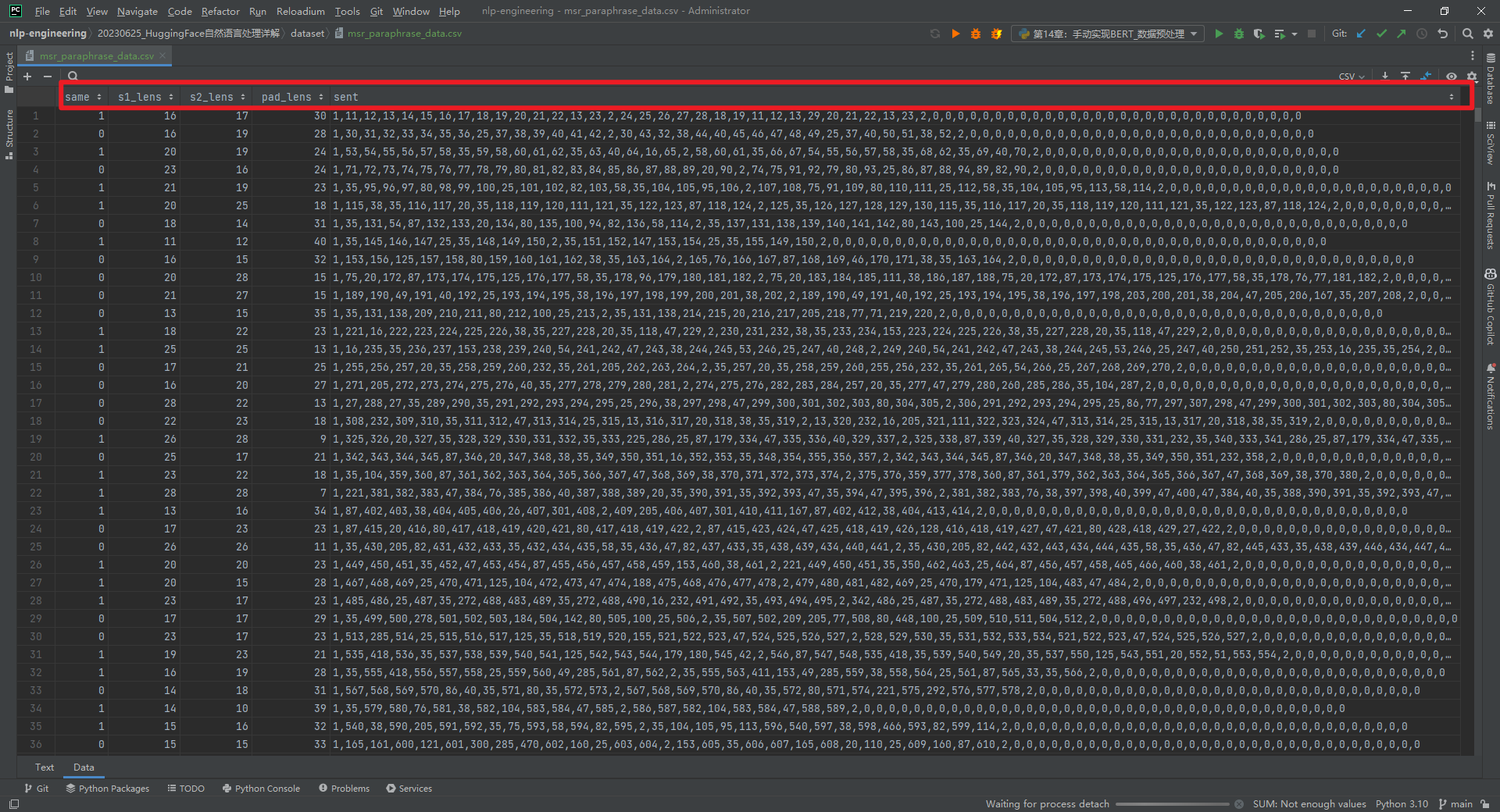
数据集预处理代码参考文献[2],处理后包括msr_paraphrase_data.csv和msr_paraphrase_vocab.csv这2个文件,样例数据如下所示:

三.PyTorch中的Transformer工具层
本部分不再手工实现Transformer编解码器,更多的使用PyTorch中已实现的Transformer工具层,从而专注于BERT模型的构建。
1.定义测试数据
模拟虚拟了2句话,每句话8个词,每句话的末尾有一些PAD,如下所示:
# 虚拟数据
import torch
# 假设有两句话,8个词
x = torch.ones(2, 8)
# 两句话中各有一些PAD
x[0, 6:] = 0
x[1, 7:] = 0
print(x)
输出结果如下所示:
tensor([[1., 1., 1., 1., 1., 1., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 0.]])
2.各个MASK的含义解释
key_padding_mask作用是遮挡数据中的PAD位置,减少计算量;encode_attn_mask定义是否要忽略输入语句中某些词与词间的注意力,在编码器中是不需要的;decode_attn_mask定义是否忽略输出语句中某些词与词之间的注意力,在解码器中是需要的。如下所示:
# 2.各个MASK的含义解释
# 定义key_padding_mask
# key_padding_mask的定义方式,就是x中是pad的为True,否则是False
key_padding_mask = x == 0
print(key_padding_mask)
# 定义encode_attn_mask
# 在encode阶段不需要定义encode_attn_mask
# 定义为None或者全False都可以
encode_attn_mask = torch.ones(8, 8) == 0
print(encode_attn_mask)
# 定义decode_attn_mask
# 在decode阶段需要定义decode_attn_mask
# decode_attn_mask的定义方式是对角线以上为True的上三角矩阵
decode_attn_mask = torch.tril(torch.ones(8, 8)) == 0
print(decode_attn_mask)
输出结果如下所示:
tensor([[False, False, False, False, False, False, True, True],
[False, False, False, False, False, False, False, True]])
tensor([[False, False, False, False, False, False, False, False],
[False, False, False, False, False, False, False, False],
[False, False, False, False, False, False, False, False],
[False, False, False, False, False, False, False, False],
[False, False, False, False, False, False, False, False],
[False, False, False, False, False, False, False, False],
[False, False, False, False, False, False, False, False],
[False, False, False, False, False, False, False, False]])
tensor([[False, True, True, True, True, True, True, True],
[False, False, True, True, True, True, True, True],
[False, False, False, True, True, True, True, True],
[False, False, False, False, True, True, True, True],
[False, False, False, False, False, True, True, True],
[False, False, False, False, False, False, True, True],
[False, False, False, False, False, False, False, True],
[False, False, False, False, False, False, False, False]])
3.编码数据
将x编码为2×8×12,表示2句话、每句话8个词、每个词用12维的Embedding向量表示:
# 编码x
x = x.unsqueeze(2) # 在第2维增加一个维度
x = x.expand(-1, -1, 12) # 在第2维复制12份
print(x, x.shape)
输出结果如下所示:
tensor([[[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]],
[[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]]]) torch.Size([2, 8, 12])
4.多头注意力计算函数
在计算多头注意力机制市需要做2次线性变化,一次是对入参的Q、K和V矩阵分别做线性变换,另一次是对注意力分数做线性变换,2次线性变换分别需要2组weight合bias参数,如下所示:
# 定义multi_head_attention_forward()所需要的参数
# in_proj就是Q、K、V线性变换的参数
in_proj_weight = torch.nn.Parameter(torch.randn(3 * 12, 12))
in_proj_bias = torch.nn.Parameter(torch.zeros((3 * 12)))
# out_proj就是输出时做线性变换的参数
out_proj_weight = torch.nn.Parameter(torch.randn(12, 12))
out_proj_bias = torch.nn.Parameter(torch.zeros(12))
print(in_proj_weight.shape, in_proj_bias.shape)
print(out_proj_weight.shape, out_proj_bias.shape)
# 使用工具函数计算多头注意力
data = {
# 因为不是batch_first的,所以需要进行变形
'query': x.permute(1, 0, 2), # x原始为[2, 8, 12],x.permute为[8, 2, 12]
'key': x.permute(1, 0, 2),
'value': x.permute(1, 0, 2),
'embed_dim_to_check': 12, # 用于检查维度是否正确
'num_heads': 2, # 多头注意力的头数
'in_proj_weight': in_proj_weight, # Q、K、V线性变换的参数
'in_proj_bias': in_proj_bias, # Q、K、V线性变换的参数
'bias_k': None,
'bias_v': None,
'add_zero_attn': False,
'dropout_p': 0.2, # dropout的概率
'out_proj_weight': out_proj_weight, # 输出时做线性变换的参数
'out_proj_bias': out_proj_bias, # 输出时做线性变换的参数
'key_padding_mask': key_padding_mask,
'attn_mask': encode_attn_mask,
}
score, attn = torch.nn.functional.multi_head_attention_forward(**data)
print(score.shape, attn, attn.shape)
(1)bias_k、bias_v:是否要对K和V矩阵单独添加bias,一般设置为None。
(2)add_zero_attn:如果设置为True,那么会在Q、K的注意力结果中单独加一列0,一般设置为默认值False。
(3)key_padding_mask:是否要忽略语句中的某些位置,一般只需忽略PAD的位置。
(4)attn_mask:是否要忽略每个词之间的注意力,在编码器中一般只用全False的矩阵,在解码器中一般使用对角线以上全True的矩阵。
输出结果如下所示:
torch.Size([36, 12]) torch.Size([36])
torch.Size([12, 12]) torch.Size([12])
torch.Size([8, 2, 12]) tensor([[[0.2083, 0.2083, 0.2083, 0.1042, 0.2083, 0.0000, 0.0000, 0.0000],
[0.2083, 0.2083, 0.1042, 0.2083, 0.2083, 0.2083, 0.0000, 0.0000],
[0.2083, 0.1042, 0.1042, 0.1042, 0.2083, 0.2083, 0.0000, 0.0000],
[0.2083, 0.1042, 0.1042, 0.2083, 0.2083, 0.1042, 0.0000, 0.0000],
[0.2083, 0.2083, 0.2083, 0.1042, 0.2083, 0.2083, 0.0000, 0.0000],
[0.2083, 0.1042, 0.2083, 0.2083, 0.1042, 0.2083, 0.0000, 0.0000],
[0.2083, 0.2083, 0.2083, 0.1042, 0.2083, 0.2083, 0.0000, 0.0000],
[0.2083, 0.1042, 0.2083, 0.1042, 0.1042, 0.2083, 0.0000, 0.0000]],
[[0.0893, 0.1786, 0.0893, 0.1786, 0.1786, 0.1786, 0.1786, 0.0000],
[0.1786, 0.1786, 0.1786, 0.1786, 0.1786, 0.1786, 0.1786, 0.0000],
[0.1786, 0.0000, 0.1786, 0.1786, 0.1786, 0.1786, 0.0893, 0.0000],
[0.1786, 0.1786, 0.1786, 0.1786, 0.0893, 0.1786, 0.0893, 0.0000],
[0.1786, 0.1786, 0.1786, 0.0000, 0.1786, 0.0893, 0.1786, 0.0000],
[0.1786, 0.1786, 0.1786, 0.1786, 0.1786, 0.1786, 0.0893, 0.0000],
[0.1786, 0.0893, 0.0893, 0.1786, 0.1786, 0.0893, 0.0000, 0.0000],
[0.1786, 0.1786, 0.0893, 0.0893, 0.1786, 0.1786, 0.1786, 0.0000]]],
grad_fn=<MeanBackward1>) torch.Size([2, 8, 8])
5.多头注意力层
封装程度更高的多头注意力层实现方式如下所示:
# 使用多头注意力工具层
multihead_attention = torch.nn.MultiheadAttention(embed_dim=12, num_heads=2, dropout=0.2, batch_first=True)
data = {
'query': x,
'key': x,
'value': x,
'key_padding_mask': key_padding_mask,
'attn_mask': encode_attn_mask,
}
score, attn = multihead_attention(**data)
print(score.shape, attn, attn.shape)
输出结果如下所示:
torch.Size([2, 8, 12]) tensor([[[0.1042, 0.2083, 0.0000, 0.1042, 0.1042, 0.2083, 0.0000, 0.0000],
[0.2083, 0.2083, 0.1042, 0.2083, 0.0000, 0.2083, 0.0000, 0.0000],
[0.2083, 0.2083, 0.2083, 0.2083, 0.0000, 0.2083, 0.0000, 0.0000],
[0.1042, 0.2083, 0.2083, 0.1042, 0.2083, 0.2083, 0.0000, 0.0000],
[0.2083, 0.2083, 0.2083, 0.1042, 0.1042, 0.2083, 0.0000, 0.0000],
[0.2083, 0.2083, 0.2083, 0.1042, 0.2083, 0.1042, 0.0000, 0.0000],
[0.1042, 0.0000, 0.2083, 0.1042, 0.2083, 0.2083, 0.0000, 0.0000],
[0.2083, 0.2083, 0.2083, 0.1042, 0.2083, 0.2083, 0.0000, 0.0000]],
[[0.1786, 0.1786, 0.0893, 0.0000, 0.1786, 0.1786, 0.1786, 0.0000],
[0.1786, 0.1786, 0.1786, 0.0893, 0.1786, 0.0893, 0.0893, 0.0000],
[0.0893, 0.0893, 0.0893, 0.0893, 0.1786, 0.1786, 0.1786, 0.0000],
[0.1786, 0.0893, 0.0893, 0.1786, 0.1786, 0.1786, 0.0893, 0.0000],
[0.1786, 0.0893, 0.1786, 0.1786, 0.0893, 0.0893, 0.0000, 0.0000],
[0.1786, 0.1786, 0.1786, 0.1786, 0.0000, 0.1786, 0.0893, 0.0000],
[0.1786, 0.0000, 0.1786, 0.0893, 0.1786, 0.0893, 0.1786, 0.0000],
[0.1786, 0.0893, 0.0893, 0.0893, 0.0893, 0.1786, 0.0893, 0.0000]]],
grad_fn=<MeanBackward1>) torch.Size([2, 8, 8])
其中,batch_first=True,表示input和output张量的shape为(batch, seq, feature)。默认为False,input和output张量的shape为(seq, batch, feature)。
6.编码器层
编码器包含多个编码器层,其中batch_first表示输入的第1维度是否是batch_size,norm_first通过该参数指定是否将标准化层前置计算。如下所示:
# 使用单层编码器工具层
encoder_layer = torch.nn.TransformerEncoderLayer(
d_model=12, # 词向量的维度
nhead=2, # 多头注意力的头数
dim_feedforward=24, # 前馈神经网络的隐层维度
dropout=0.2, # dropout的概率
activation=torch.nn.functional.relu, # 激活函数
batch_first=True, # 输入数据的第一维是batch
norm_first=True) # 归一化层在前
data = {
'src': x, # 输入数据
'src_mask': encode_attn_mask, # 输入数据的mask
'src_key_padding_mask': key_padding_mask, # 输入数据的key_padding_mask
}
out = encoder_layer(**data)
print(out.shape) #torch.Size([2, 8, 12])
# 使用编码器工具层
encoder = torch.nn.TransformerEncoder(
encoder_layer=encoder_layer, # 编码器层
num_layers=3, # 编码器层数
norm=torch.nn.LayerNorm(normalized_shape=12)) # 归一化层
data = {
'src': x, # 输入数据
'mask': encode_attn_mask, # 输入数据的mask
'src_key_padding_mask': key_padding_mask, # 输入数据的key_padding_mask
}
out = encoder(**data)
print(out.shape) #torch.Size([2, 8, 12])
7.解码器层
BERT当中不会用到Transformer的解码器,解码器包含多个解码器层,如下所示:
# 7.解码器层
# 使用单层解码器工具层
decoder_layer = torch.nn.TransformerDecoderLayer( # 解码器层
d_model=12, # 词向量的维度
nhead=2, # 多头注意力的头数
dim_feedforward=24, # 前馈神经网络的隐层维度
dropout=0.2, # dropout的概率
activation=torch.nn.functional.relu, # 激活函数
batch_first=True, # 输入数据的第一维是batch
norm_first=True) # 归一化层在前
data = {
'tgt': x, # 解码输出的目标语句,即target
'memory': x, # 编码器的编码结果,即解码器解码时的根据数据
'tgt_mask': decode_attn_mask, # 定义是否要忽略词与词之间的注意力,即decode_attn_mask
'memory_mask': encode_attn_mask, # 定义是否要忽略memory内的部分词与词之间的注意力,一般不需要要忽略
'tgt_key_padding_mask': key_padding_mask, # 定义target内哪些位置是PAD,以忽略对PAD的注意力
'memory_key_padding_mask': key_padding_mask, # 定义memory内哪些位置是PAD,以忽略对PAD的注意力
}
out = decoder_layer(**data)
print(out.shape) #(2,8,12)
# 使用编码器工具层
decoder = torch.nn.TransformerDecoder( # 解码器层
decoder_layer=decoder_layer, # 解码器层
num_layers=3, # 解码器层数
norm=torch.nn.LayerNorm(normalized_shape=12))
data = {
'tgt': x,
'memory': x,
'tgt_mask': decode_attn_mask,
'memory_mask': encode_attn_mask,
'tgt_key_padding_mask': key_padding_mask,
'memory_key_padding_mask': key_padding_mask,
}
out = decoder(**data)
print(out.shape) #(2,8,12)
8.完整的Transformer模型
Transformer主模型由编码器和解码器组成,如下所示:
# 使用Transformer工具模型
transformer = torch.nn.Transformer(d_model=12, # 词向量的维度
nhead=2, # 多头注意力的头数
num_encoder_layers=3, # 编码器层数
num_decoder_layers=3, # 解码器层数
dim_feedforward=24, # 前馈神经网络的隐层维度
dropout=0.2, # dropout的概率
activation=torch.nn.functional.relu, # 激活函数
custom_encoder=encoder, # 自定义编码器,如果指定为None,那么会使用默认的编码器层堆叠num_encoder_layers层组成编码器
custom_decoder=decoder, # 自定义解码器,如果指定为None,那么会使用默认的解码器层堆叠num_decoder_layers层组成解码器
batch_first=True, # 输入数据的第一维是batch
norm_first=True) # 归一化层在前
data = {
'src': x,
'tgt': x,
'src_mask': encode_attn_mask,
'tgt_mask': decode_attn_mask,
'memory_mask': encode_attn_mask,
'src_key_padding_mask': key_padding_mask,
'tgt_key_padding_mask': key_padding_mask,
'memory_key_padding_mask': key_padding_mask,
}
out = transformer(**data)
print(out.shape) #torch.Size([2, 8, 12])
四.手动实现BERT模型
因为这部分代码较长,就不放出来了,详细参考文献[4]。需要说明的是BERT在训练阶段有两个子任务,分别为预测两句话的意思是否一致,以及被遮掩的词的原本的词。把编码器抽取的文本特征分别输入两个线性神经网络,并且以此计算这两个输出。重点说下random_replace()函数对所有句子的替换策略,如下所示:
# 定义随机替换函数
def random_replace(sent):
# sent = [b,63]
# 不影响原来的sent
sent = sent.clone()
# 替换矩阵,形状和sent一样,被替换过的位置是True,其他位置是False
replace = sent == -1
# 遍历所有的词
for i in range(len(sent)):
for j in range(len(sent[i])):
# 如果是符号就不操作了,只替换词
if sent[i, j] <= 10:
continue
# 以0.15的概率进行操作
if random.random() > 0.15:
pass
# 对被操作过的位置进行标记,这里的操作包括什么也不做
replace[i, j] = True
# 分概率做不同的操作
p = random.random()
# 以O.8的概率替换为MASK
if p < 0.8:
sent[i, j] = vocab.loc['<MASK>'].token
# 以0.1的概率不替换
elif p < 0.9:
continue
# 以0.1的概率替换成随机词
else:
# 随机生成一个不是符号的词
rand_word = 0
while rand_word <= 10:
rand_word = random.randint(0, len(vocab) - 1)
sent[i, j] = rand_word
return sent, replace
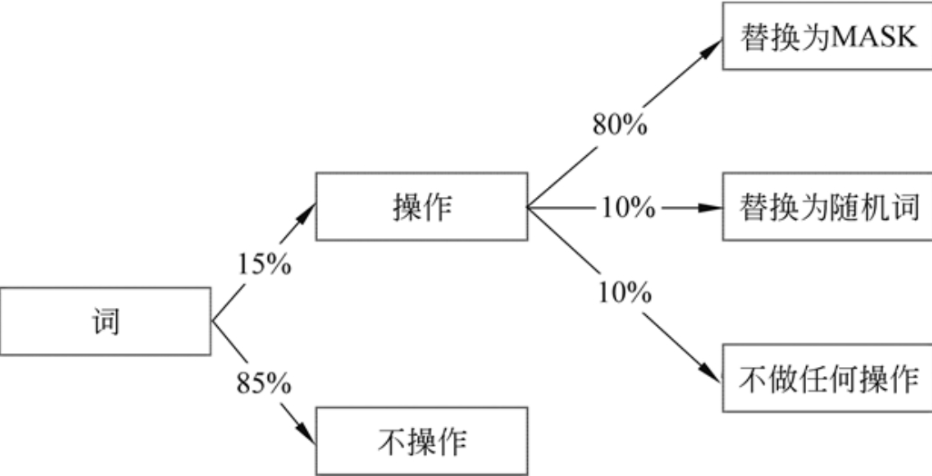
每个句子中的每个词都有15%的概率被替换,而替换也不仅有替换为MASK这一种情况。在被判定为当前词要替换后,该词有80%的概率被替换为MASK,有10%的概率被替换为一个随机词,有10%的概率不替换为任何词。如下所示:
参考文献:
[1]《HuggingFace自然语言处理详解:基于BERT中文模型的任务实战》
[2]https://github.com/ai408/nlp-engineering/blob/main/20230625_HuggingFace自然语言处理详解/第14章:手动实现BERT_数据预处理.py
[3]https://github.com/ai408/nlp-engineering/blob/main/20230625_HuggingFace自然语言处理详解/第14章:手动实现BERT_PyTorch中的Transformer工具层.py
[4]https://github.com/ai408/nlp-engineering/blob/main/20230625_HuggingFace自然语言处理详解/第14章:手动实现BERT_训练和测试.py
[5]Bert模型的细节到底是怎么样的:https://www.zhihu.com/question/534763354
[6]BERT模型参数量:https://zhuanlan.zhihu.com/p/452267359
[7]HuggingFace Transformers最新版本源码解读:https://zhuanlan.zhihu.com/p/360988428
[8]NLP Course:https://huggingface.co/learn/nlp-course/zh-CN/chapter1/1


![web:[极客大挑战 2019]BabySQL](https://img-blog.csdnimg.cn/d1fbf28b01da4d7aa60be045892e8e0b.png)