文件框架
通过简单的模型训练,对于YOLO的理解更加透彻了。
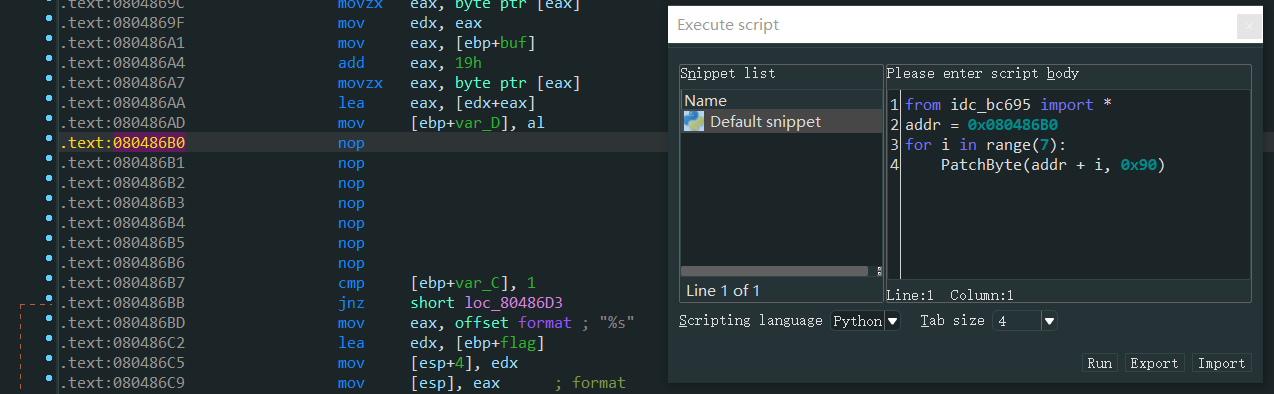
detect.py文件

如上图所示,weights表示权重。source表示识别图像的位置。
train.py文件
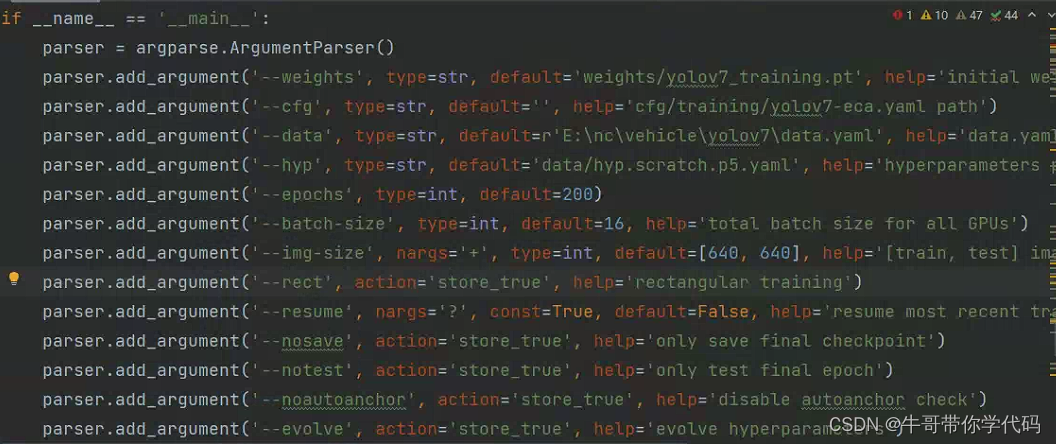
如上图所示,weights是权重,我们通常使用YOLO提供的训练权重进行训练。data是训练数据。
之前我一直存在一个疑惑,通过本次项目训练有了很清楚的解答
问题:为什么训练里面没有写数据集的具体文件,具体文件在哪里?
解答: 具体文件就是data.yaml文件,由于这个文件后缀比较奇特,原来一直没见过,所以就一直没有太在意。
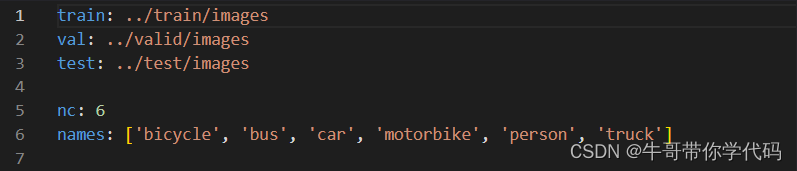
如上图所示,对应的train、val、test,链接到了三个具体位置,(有时候这里链接的是三个txt文件,里面对应的txt文件是具体的YOLO数据标注格式(一种txt,里面包含了图片的一些参数)的一个列表),下面的nc对应了类型数,下面的names对应了识别的物体类型有哪些种类。
附赠代码
XML数据标注类型文件转YOLO数据标注txt文件
import copy
from lxml.etree import Element, SubElement, tostring, ElementTree
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
# 类别
classes = ["auto", "bus", "tempo", "tractor", "truck"]
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('./XML_annotation/truck\%s.xml' % (image_id), encoding='UTF-8')
out_file = open('./XML_annotation/truck\%s.txt' % (image_id), 'w') # 生成txt格式文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
# print(cls)
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " +
" ".join([str(a) for a in bb]) + '\n')
xml_path = os.path.join(CURRENT_DIR, 'XML_annotation\\truck')
print(xml_path)
# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:
# print(img_xml)
label_name = img_xml.split('.')[0]
print(label_name)
convert_annotation(label_name)